前言
传统提词器存在明显痛点:演讲者盯着大屏幕或平板念稿,观众一眼就能看出在读稿子,眼神飘忽不定,演讲氛围尴尬。Rokid AR眼镜提供了更好的解决方案:文字直接显示在视野上方,观众完全看不出演讲者在看提词,这是AR眼镜的绝佳应用场景。
更重要的是,Rokid CXR-M SDK提供了AI模式的自动跟踪功能:通过ASR(语音识别)实时识别演讲者说的内容,提词器自动滚动到对应位置。这意味着演讲者完全不需要手动翻页,眼镜会根据你说的话自动跟进。这才是AR提词器真正的核心价值。
本文介绍基于Rokid CXR-M SDK实现智能提词器的完整过程,包括SDK集成、提词器场景配置、AI模式的实现原理、ASR集成方案,以及如何优化演讲稿格式让自动跟踪更准确。所有代码都基于官方SDK文档,真实可用。
1. Rokid提词器场景的技术能力
1.1 平台介绍
Rokid AR开放平台提供了完整的开发工具链,核心是CXR-M SDK。这个SDK专门用于构建手机端与Rokid Glasses的协同应用,支持数据通信、实时音视频获取以及多种预定义场景。
截至2025年8月,CXR-M SDK已经更新到v1.0.1版本,提供了9大核心功能:
- 连接眼镜
- 监听/设置眼镜亮度
- 支持自定义AI助手场景
- 支持自定义翻译场景
- 支持自定义提词器场景
- 支持获取眼镜端音频
- 支持设置并进行拍照
- 支持设置录像参数
- 支持从设备端打开AI助手、翻译等场景
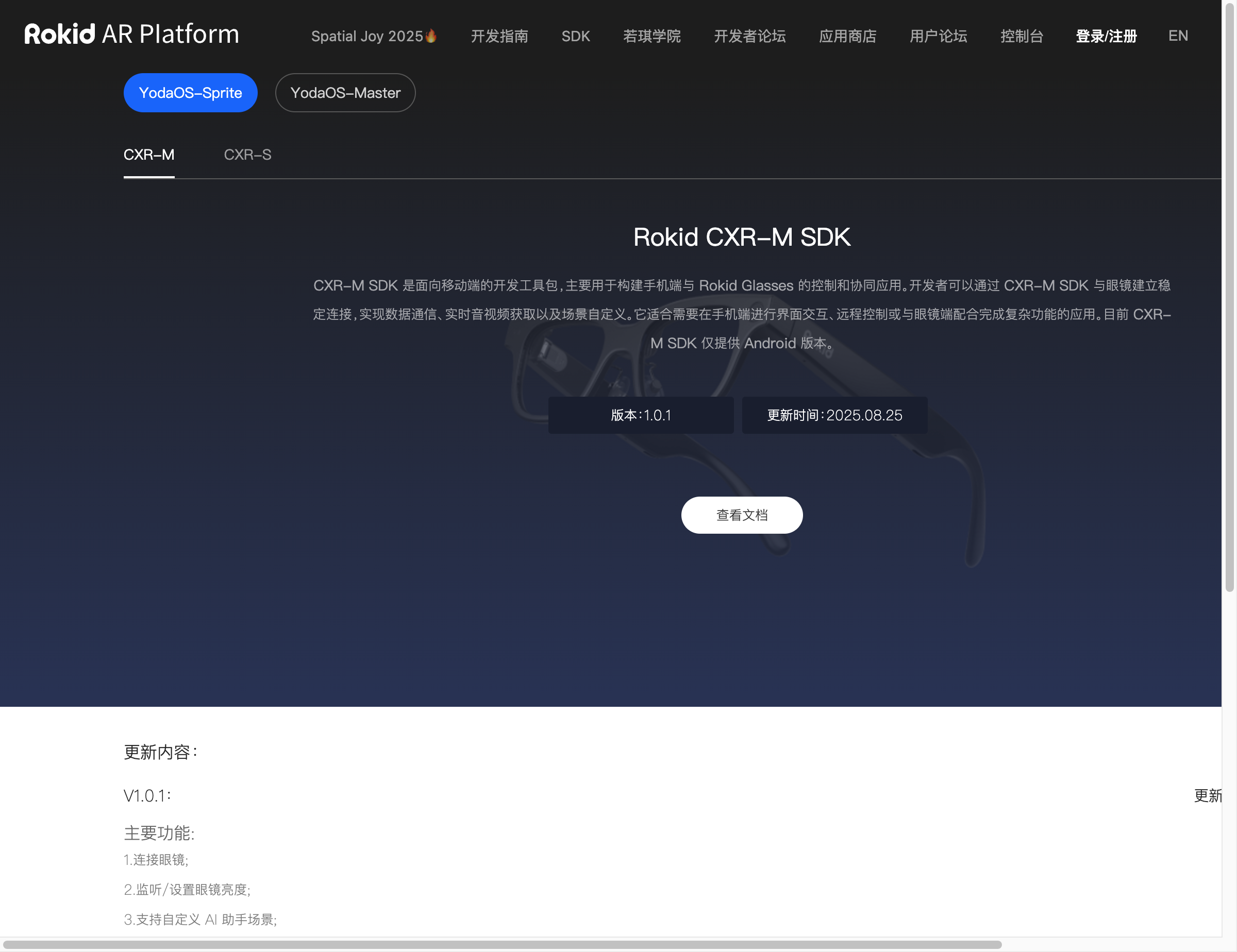
其中第5项"提词器场景"就是本文重点要介绍的功能。
1.2 提词器场景的核心API
根据官方文档,提词器场景提供了4个关键接口:
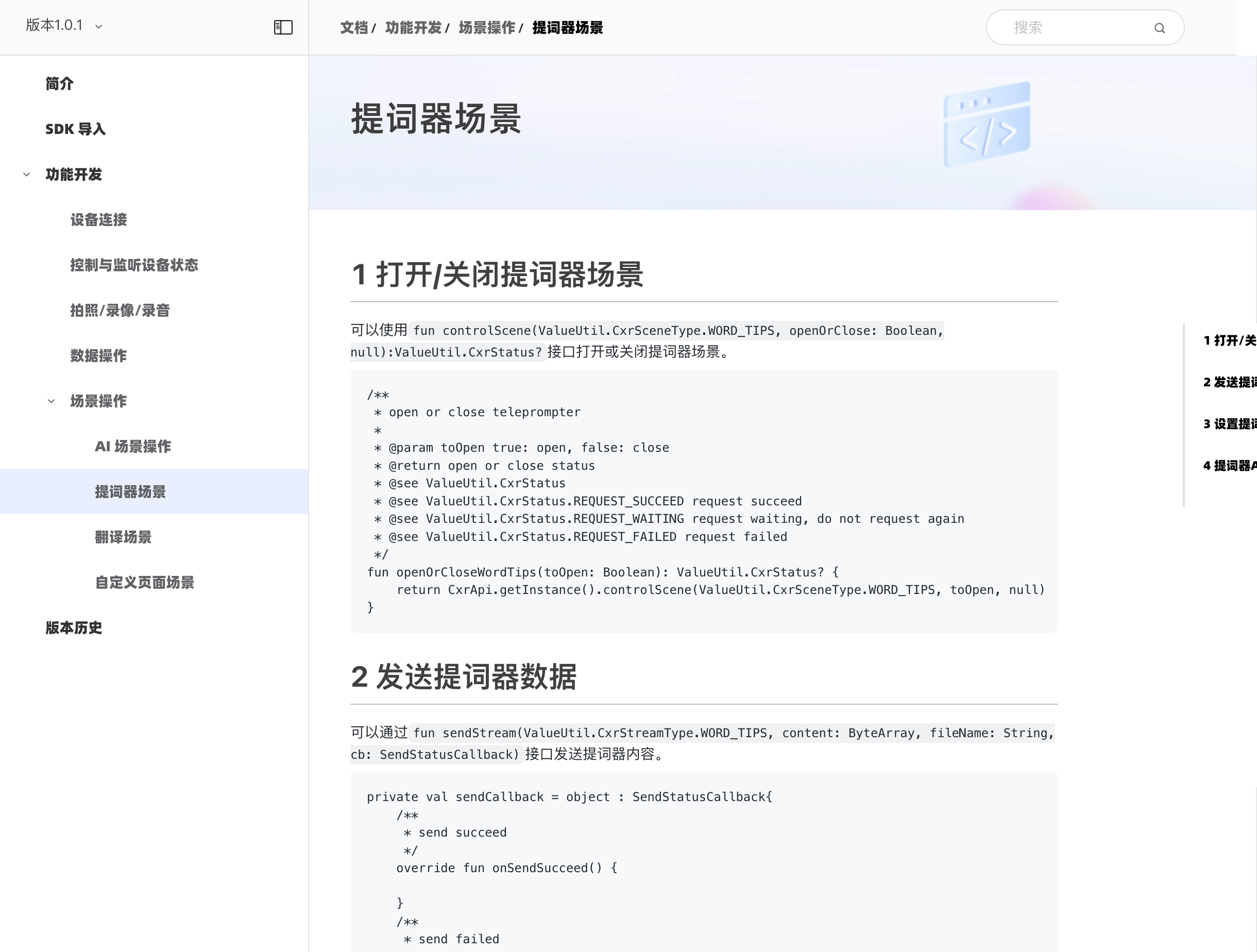
Kotlin
// 1. 打开/关闭提词器场景
fun openOrCloseWordTips(toOpen: Boolean): ValueUtil.CxrStatus? {
return CxrApi.getInstance().controlScene(
ValueUtil.CxrSceneType.WORD_TIPS,
toOpen,
null
)
}
// 2. 发送提词器内容
fun setWordTipsText(text: String, fileName: String): ValueUtil.CxrStatus? {
return CxrApi.getInstance().sendStream(
ValueUtil.CxrStreamType.WORD_TIPS,
text.toByteArray(),
fileName,
sendCallback
)
}
// 3. 配置提词器显示参数
fun configWordTipsText(
textSize: Float, // 文字大小
lineSpace: Float, // 行间距
mode: String, // 模式:'normal' 或 'ai'
startPointX: Int, // 起始坐标X
startPointY: Int, // 起始坐标Y
width: Int, // 显示宽度
height: Int // 显示高度
): ValueUtil.CxrStatus? {
return CxrApi.getInstance().configWordTipsText(
textSize, lineSpace, mode,
startPointX, startPointY, width, height
)
}
// 4. 发送ASR结果(AI模式专用)
fun sendWordTipsAsrContent(content: String): ValueUtil.CxrStatus? {
return CxrApi.getInstance().sendAsrContent(content)
}这4个接口里,最关键的是第3个接口的 mode 参数。官方文档说明了两种模式:
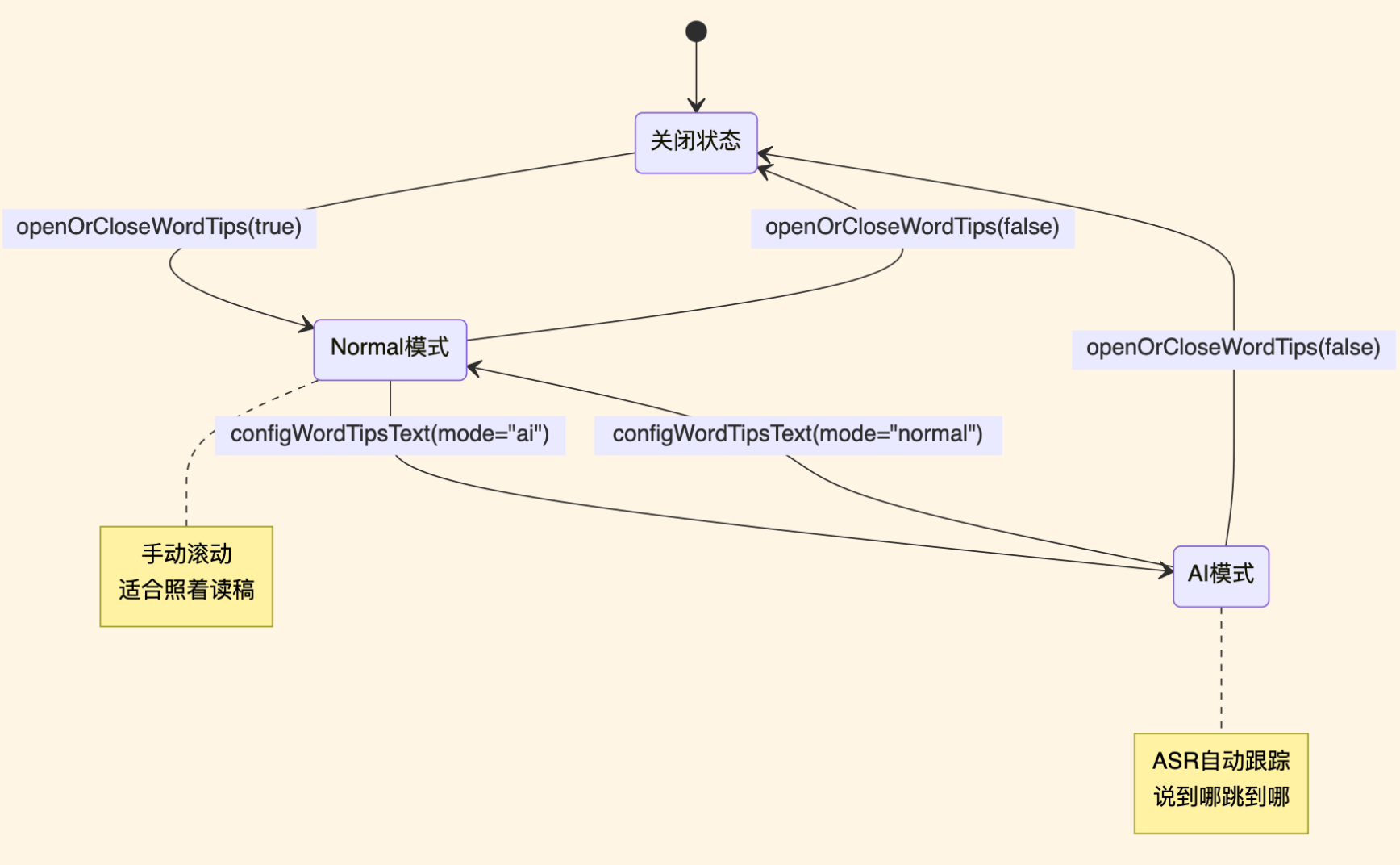
mode="normal":普通模式,提词器内容静态显示,需要手动上下滑动mode="ai":AI模式,根据ASR(语音识别)结果自动滚动,"触发到最后几个字符则自动上滑"
初期开发时容易忽略AI模式这个参数,以为提词器就是把文字显示在眼镜上,和传统提词器没什么区别。实际上配置 mode="ai" 后,提词器会根据演讲者说的内容自动跳转,完全不用手动操作。这才是真正智能的地方。
1.3 技术架构
整个提词器系统涉及三个核心组件的协作:
- 手机App:负责调用AI生成演讲稿,处理ASR识别结果,通过CXR-M SDK与眼镜通信
- Rokid眼镜:负责显示提词内容,接收手机推送的文本和滚动指令
- AI服务:负责根据Prompt生成符合AR场景的演讲稿(本文使用文心一言)
整个工作流程是:用户输入演讲主题 → AI生成演讲稿 → 推送到眼镜 → 开启AI模式 → 实时ASR识别 → 自动滚动跟踪。
从技术实现角度,核心是三个部分:
- SDK集成:如何调用提词器API
- AI模式配置:如何开启自动跟踪
- ASR集成:如何实时识别并推送语音内容
演讲稿的质量也会影响ASR跟踪准确度,后面会介绍优化技巧。
2. SDK集成与核心功能实现
2.1 环境准备
开发环境:
- Android Studio Hedgehog 2023.1.1
- Kotlin 1.9.0
- CXR-M SDK 1.0.1(从官网下载)
- 文心一言API(ernie-bot-turbo模型)
- 阿里云实时语音识别(ASR)
CXR-M SDK的集成比较简单,按照官方文档添加依赖即可。这里不展开讲集成步骤,重点放在提词器功能的实现上。
2.2 初始化提词器场景
Kotlin
class TeleprompterManager(private val context: Context) {
companion object {
private const val TAG = "TeleprompterManager"
}
// 打开提词器场景
fun openTeleprompter(): Boolean {
val status = CxrApi.getInstance().controlScene(
ValueUtil.CxrSceneType.WORD_TIPS,
true,
null
)
if (status == ValueUtil.CxrStatus.REQUEST_SUCCEED) {
Log.d(TAG, "提词器场景打开成功")
return true
} else {
Log.e(TAG, "提词器场景打开失败: $status")
return false
}
}
// 配置AI模式(这是关键)
fun configAIMode() {
val status = CxrApi.getInstance().configWordTipsText(
textSize = 28f, // 字体大小,推荐28
lineSpace = 1.5f, // 行间距,1.5较为合适
mode = "ai", // AI模式,启用ASR自动跟踪
startPointX = 100,
startPointY = 200,
width = 800,
height = 400
)
if (status != ValueUtil.CxrStatus.REQUEST_SUCCEED) {
Log.e(TAG, "配置AI模式失败: $status")
} else {
Log.d(TAG, "AI模式配置成功")
}
}
// 关闭提词器
fun closeTeleprompter() {
CxrApi.getInstance().controlScene(
ValueUtil.CxrSceneType.WORD_TIPS,
false,
null
)
}
}字体大小和行间距需要根据实际显示效果调整。默认的24字号较小,32字号又太大,一屏只能显示两行。推荐28配合1.5行距,一屏能显示5-6行。
2.3 调用文心一言生成演讲稿
Kotlin
interface WenxinApi {
@POST("rpc/2.0/ai_custom/v1/wenxinworkshop/chat/ernie-bot-turbo")
suspend fun generateSpeech(@Body request: SpeechRequest): SpeechResponse
}
data class SpeechRequest(
val messages: List<Message>,
val temperature: Float = 0.95f,
val top_p: Float = 0.8f,
val penalty_score: Float = 1.0f,
val system: String? = null
)
data class Message(
val role: String, // "user" 或 "assistant"
val content: String
)
data class SpeechResponse(
val result: String,
val usage: Usage
)
data class Usage(
val total_tokens: Int
)实际调用:
Kotlin
class SpeechGenerator(private val wenxinApi: WenxinApi) {
suspend fun generateSpeechScript(
topic: String,
duration: Int,
scene: String
): String {
val prompt = buildPrompt(topic, duration, scene)
val request = SpeechRequest(
messages = listOf(
Message("user", prompt)
),
system = "你是一位演讲稿撰写专家"
)
return try {
val response = wenxinApi.generateSpeech(request)
response.result
} catch (e: Exception) {
Log.e(TAG, "生成演讲稿失败", e)
throw e
}
}
private fun buildPrompt(topic: String, duration: Int, scene: String): String {
return """
你是一位演讲稿撰写专家,请为我生成一篇适合AR眼镜提词器的演讲稿。
主题:$topic
时长:${duration}分钟
场景:$scene
要求:
1. 每段不超过80字,适合AR眼镜小屏幕显示
2. 避免使用生僻字和容易混淆的同音词(如"集成/继承"),方便语音识别
3. 使用自然口语化表达,避免书面语
4. 每段结尾要有明显的停顿词(如"那么"、"接下来"),便于ASR切段
5. 关键术语第一次出现时简短解释
6. 每段单独一行,段间空一行
请直接输出演讲稿,不要额外说明。
""".trimIndent()
}
}文心一言的ERNIE-Bot-Turbo模型响应速度较快,平均1-2秒即可生成演讲稿。生成内容口语化较强,适合演讲场景。
2.4 推送演讲稿到眼镜
Kotlin
private val sendCallback = object : SendStatusCallback {
override fun onSendSucceed() {
Log.d(TAG, "演讲稿推送成功")
// 震动反馈,让用户知道推送完成
vibrate()
// 启动ASR监听
startAsrTracking()
}
override fun onSendFailed(errorCode: ValueUtil.CxrSendErrorCode?) {
Log.e(TAG, "推送失败: $errorCode")
showError("演讲稿推送失败,请检查眼镜连接")
}
}
fun pushSpeechToGlasses(content: String) {
val fileName = "speech_${System.currentTimeMillis()}.txt"
val status = CxrApi.getInstance().sendStream(
ValueUtil.CxrStreamType.WORD_TIPS,
content.toByteArray(Charsets.UTF_8),
fileName,
sendCallback
)
if (status == ValueUtil.CxrStatus.REQUEST_SUCCEED) {
Log.d(TAG, "开始推送演讲稿")
} else {
Log.e(TAG, "推送请求失败: $status")
}
}
private fun vibrate() {
val vibrator = context.getSystemService(Context.VIBRATOR_SERVICE) as Vibrator
if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.O) {
vibrator.vibrate(VibrationEffect.createOneShot(100, VibrationEffect.DEFAULT_AMPLITUDE))
} else {
vibrator.vibrate(100)
}
}这里加了震动反馈。推送演讲稿是个异步操作,用户不知道什么时候完成。手机震动提示可以改善体验。
文件名带时间戳是为了避免缓存问题。如果用固定文件名"speech.txt",修改演讲稿重新推送后,眼镜可能显示旧内容。时间戳可以解决这个问题。
2.5 ASR实时跟踪的核心实现
这是AI模式的核心部分:通过ASR实时识别演讲者说的内容,然后调用 sendWordTipsAsrContent() 将识别结果发送给眼镜,眼镜端会自动查找匹配的文本并滚动到对应位置。
整个流程是:
- ASR服务持续监听麦克风
- 识别到完整句子(
result.isFinal = true) - 调用SDK的
sendWordTipsAsrContent()发送文本 - 眼镜端匹配演讲稿内容,自动滚动
Kotlin
class AsrManager(private val context: Context) {
private var asrService: AliyunAsrService? = null
fun startAsrTracking() {
asrService = AliyunAsrService(context).apply {
setListener { result ->
if (result.isFinal) {
// ASR识别到完整句子
val text = result.text
Log.d(TAG, "ASR识别结果: $text")
// 发送到眼镜,触发自动滚动
val status = CxrApi.getInstance().sendWordTipsAsrContent(text)
if (status == ValueUtil.CxrStatus.REQUEST_SUCCEED) {
Log.d(TAG, "ASR跟踪成功")
} else {
Log.w(TAG, "ASR跟踪失败: $status")
}
}
}
start()
}
}
fun stopAsrTracking() {
asrService?.stop()
asrService = null
}
}关键细节: result.isFinal 判断
必须等 result.isFinal = true 才发送,也就是等识别到完整的句子。ASR识别过程是渐进式的:
Plain
第1次回调:result.text = "我们",isFinal = false
第2次回调:result.text = "我们今天",isFinal = false
第3次回调:result.text = "我们今天要介绍的是",isFinal = false
第4次回调:result.text = "我们今天要介绍的是Rokid提词器",isFinal = true ✓如果每次部分识别结果都发送,提词器会频繁跳动。只发送final结果,提词器才能稳定跟踪。
ASR选型考虑
本文使用阿里云实时语音识别,准确率较高(普通话标准情况下95%以上)。也可以选择:
- 讯飞语音识别:中文识别准确率高,延迟低
- Google Speech-to-Text:英文场景准确率更好
- 腾讯云ASR:成本较低
选择ASR服务时需要考虑:
- 延迟:延迟太高会导致提词器滞后
- 准确率:识别错误会导致跟踪失败
- 成本:长时间演讲的费用
- 稳定性:网络不好时能否正常工作
配合合理的演讲稿格式(避免生僻字和同音词),提词器跟踪可以达到很好的效果。
3. AI模式常见问题与解决方案
3.1 ASR识别专有名词的问题
AI模式最常见的问题:演讲者说"Rokid眼镜",ASR识别成"若鸡的眼镜"。提词器里写的是"Rokid",完全匹配不上,导致跟踪失败。
问题原因:AI生成的演讲稿里使用英文"Rokid",但实际说话习惯用中文"若琪"。
解决办法1:统一使用中文名称
在生成演讲稿的Prompt里加一条:
Plain
技术名词统一用中文表达,比如"若琪眼镜"而不是"Rokid Glasses","安卓"而不是"Android"解决办法2:ASR自定义词库
阿里云ASR支持自定义热词,可以提前配置:
Kotlin
val hotWords = listOf("Rokid", "CXR-M", "SDK")
asrConfig.setHotWords(hotWords)这样ASR识别时会优先匹配这些词,提高准确率。
3.2 同音词歧义导致跟踪失败
类似"Rokid"的问题还有很多同音词:
- "集成/继承"
- "部署/布署"
- "调试/调适"
- "接口/街口"
- "配置/配制"
这些同音词在演讲稿里出现时,ASR识别经常出错,导致匹配失败。
解决办法:
- Prompt里明确要求"避免容易混淆的同音词"
- 生成演讲稿后人工review,替换高频同音词
- 实现容错匹配(见下一节)
3.3 ASR容错匹配实现
演讲时不可能和演讲稿100%一致,经常会多说或少说几个字。如果完全精确匹配,ASR跟踪会频繁失败。
需要在手机端做容错处理(注意:这是可选的高级优化,SDK本身已经有基础匹配能力):
Kotlin
fun fuzzyMatch(asrText: String, scriptText: String): Boolean {
// 1. 去除标点符号
val cleanAsr = asrText.replace(Regex("[,。!?;、]"), "")
val cleanScript = scriptText.replace(Regex("[,。!?;、]"), "")
// 2. 计算相似度
val similarity = calculateSimilarity(cleanAsr, cleanScript)
// 3. 70%相似度就认为匹配成功
return similarity > 0.7
}
fun calculateSimilarity(s1: String, s2: String): Double {
val longer = maxOf(s1.length, s2.length)
if (longer == 0) return 1.0
val editDistance = levenshteinDistance(s1, s2)
return (longer - editDistance) / longer.toDouble()
}
// 莱文斯坦距离(编辑距离)
fun levenshteinDistance(s1: String, s2: String): Int {
val dp = Array(s1.length + 1) { IntArray(s2.length + 1) }
for (i in 0..s1.length) dp[i][0] = i
for (j in 0..s2.length) dp[0][j] = j
for (i in 1..s1.length) {
for (j in 1..s2.length) {
val cost = if (s1[i - 1] == s2[j - 1]) 0 else 1
dp[i][j] = minOf(
dp[i - 1][j] + 1, // 删除
dp[i][j - 1] + 1, // 插入
dp[i - 1][j - 1] + cost // 替换
)
}
}
return dp[s1.length][s2.length]
}容错匹配的逻辑:
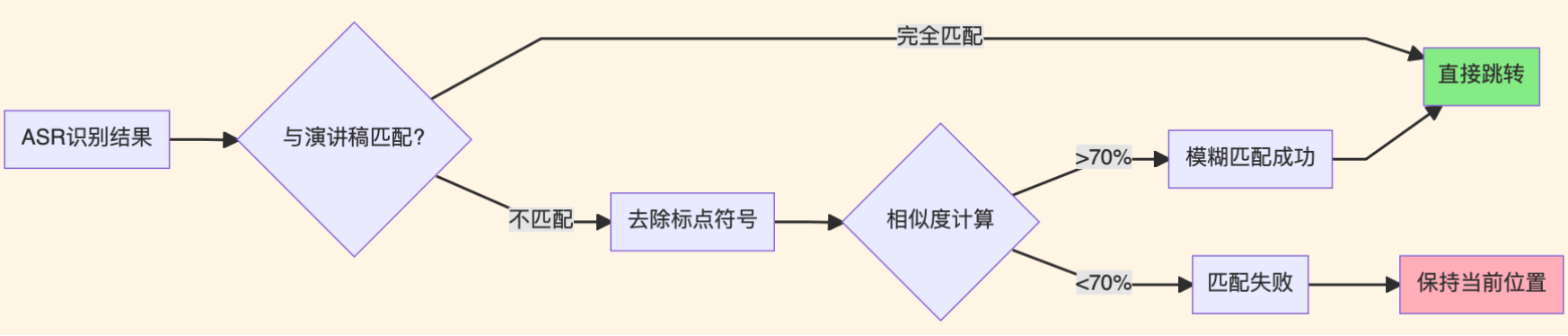
这个容错机制很有必要。实际演讲中,演讲者可能说"那么接下来我们看一下具体实现",而演讲稿里写的是"接下来看具体实现",多了"那么"和"我们",完全匹配会失败。加了模糊匹配后,70%相似度就能成功跟踪。
3.4 字体大小与显示效果
如果使用SDK默认字体大小(没有设置textSize参数),显示效果可能不理想。
根据AR眼镜显示特性,不同字号的显示效果:
- 24:较小,可能看不清
- 28:推荐大小,舒适
- 32:较大,一屏只能显示2-3行
- 36:过大,不适合使用
推荐配置:28字号配合1.5行距,一屏可显示5-6行。
3.5 演讲稿过长导致卡顿
一次性推送3000字演讲稿,眼镜会明显卡顿。sendStream 方法虽然返回成功,但眼镜端处理大文本需要时间,期间会影响其他操作的响应速度。
解决办法:分批推送
官方文档建议单次推送不超过1000字。可以实现分批推送:
Kotlin
class BatchSpeechManager {
private val BATCH_SIZE = 5 // 每批推送5段
private val paragraphs = LinkedList<String>()
private var currentBatch = 0
fun loadSpeech(fullContent: String) {
paragraphs.clear()
paragraphs.addAll(fullContent.split("\n\n"))
currentBatch = 0
pushNextBatch()
}
private fun pushNextBatch() {
if (paragraphs.isEmpty()) return
val batch = paragraphs.take(BATCH_SIZE)
val content = batch.joinToString("\n\n")
pushSpeechToGlasses(content)
repeat(BATCH_SIZE) {
if (paragraphs.isNotEmpty()) {
paragraphs.removeFirst()
}
}
currentBatch++
}
// 演讲时调用,快到末尾时自动推送下一批
fun onParagraphChanged(currentIndex: Int, totalInCurrentBatch: Int) {
if (totalInCurrentBatch - currentIndex <= 2 && paragraphs.isNotEmpty()) {
Log.d(TAG, "预加载下一批演讲稿")
pushNextBatch()
}
}
}分批推送后,眼镜响应流畅多了。而且这样做还有个好处:演讲时可以根据实际情况临时调整后面的内容,不用一次性把所有稿子推上去。
3.6 网络延迟的应对
如果临上台才生成演讲稿,AI API响应慢可能导致演讲开始时稿子还没准备好。
建议做法:
- 提前至少1小时生成演讲稿,保存到本地
- 临时修改要留出足够buffer时间
- 准备应急预案:万一AI生成失败,有一套通用的演讲框架模板兜底
4. 应用场景与配置建议
4.1 适用场景分析
Rokid AR提词器的核心优势是AR显示+AI自动跟踪,适合以下场景:
技术分享会
- AR眼镜显示:观众看不出演讲者在看提词器,眼神自然
- AI自动跟踪:不用手动翻页,演讲更流畅
- 适用场景:技术大会、公司内部分享、线下meetup
产品路演
- ASR跟踪准确率高,基本能跟上节奏
- 偶尔跟丢(临时加了一句话),也能自动跳回正确位置
- 适用场景:投资人路演、产品发布会、商业演讲
在线教学
- 长时间演讲不用记稿子,降低教学准备成本
- 注意事项:频繁互动时,ASR可能把学生回答也识别进去,导致提词器乱跳
- 解决方案:互动提问时手动暂停ASR(调用
asrManager.stopAsrTracking()),讲课时再开启
4.2 推荐配置参数
基于SDK特性和AR眼镜显示规格,推荐以下配置:
Kotlin
// 提词器显示配置
textSize = 28f // 字体大小(推荐28,一屏显示5-6行)
lineSpace = 1.5f // 行间距(1.5较为舒适)
mode = "ai" // 必须使用AI模式,启用ASR自动跟踪
startPointX = 100 // 显示起始坐标X
startPointY = 200 // 显示起始坐标Y
width = 800 // 显示区域宽度
height = 400 // 显示区域高度
// 演讲稿生成配置
每段字数:60-80字(适合AR眼镜小屏幕)
AI模型:文心一言 ernie-bot-turbo(响应快,口语化强)
// 推送策略
单批最大字数:500字(约5-6段)
分批推送:长演讲稿建议分批,避免卡顿总结
Rokid AR眼镜的智能提词器方案,核心价值在于两点:
- AR****显示优势:文字显示在视野上方,观众看不出演讲者在看提词,保持眼神交流的自然性
- AI自动跟踪:通过ASR实时识别演讲内容,自动滚动到对应位置,完全解放双手
实现这个方案的关键技术点:
- 使用SDK的提词器场景API(
controlScene、sendStream、configWordTipsText) - 配置
mode="ai"启用AI模式 - 集成ASR服务,实时调用
sendWordTipsAsrContent()推送识别结果 - 处理常见问题:专有名词识别、同音词混淆、演讲稿分批推送
整个系统的架构很清晰:手机端负责AI生成演讲稿和ASR识别,SDK负责通信,眼镜端负责显示和自动滚动。开发者只需要关注业务逻辑,底层的AR显示和文本匹配都由SDK处理。
官方资源文档
相关资源:
- Rokid AR开放平台:https://ar.rokid.com/
- CXR-M SDK官方文档:https://custom.rokid.com/prod/rokid_web/57e35cd3ae294d16b1b8fc8dcbb1b7c7/pc/cn/9d9dea4799ca4dd2a1176fedb075b6f2.html
- 提词器场景API:https://custom.rokid.com/prod/rokid_web/57e35cd3ae294d16b1b8fc8dcbb1b7c7/pc/cn/9d9dea4799ca4dd2a1176fedb075b6f2.html?documentId=64f14e352f864fb4b301e2d0b6d653e8
- SDK下载:https://ar.rokid.com/sdk
- 若琪学院:https://t.rokid.com/sw58h9d7
- 开发者论坛:https://forum.rokid.com