学习汇编随手记
前言
本笔记是关于王爽汇编的笔记,覆盖不全,到了内中断就完结了,听从学长建议,我跑去学xv6了,x86告辞。
1. 寄存器
1.1 寄存器初步
(A,B,C,D)X是通用寄存器,通常存放一般性数据,而形似A(H,L)则是为了向下兼容,而由AX分裂的八位寄存器。
这里值得注意的是,dosbox不支持debug模式直接用r直接修改AH或者AL,但是可以通过a来直接进入汇编指令模式,这种情况下是支持的。
字的概念:一个字由两个字节组成,一个字节由8bit组成,而在ax中,分为高位字节和低位字节,对应了我们的兼容性的考虑。
debug模式下,通过输入a可以直接进入汇编代码模式,我们可以输入mov ah, 15来改变ax的高八位,这里的15是16进制,无论你输入什么,都会默认是16进制的数字,而你如果在debug模式下,直接在后面加上H,是会报错的,位数多了会报错,但是如果位数少了不会。
如果加法出现溢出,懂得都懂,会无视溢出,该进位进位,如果对AL和BL进行加减,进位不会波及到AH或者BH,因为此时采取的是八位运算。
8086 :他的cpu是16位的,而有20位的地址总线,这就产生了木桶效应,而计算机总是神奇 的,他给出了两个16位地址合成的方法形成了20位的物理地址,采用的是物理地址=段地址×16(二进制左移四位) + 偏移地址 ,这是我们在计组中学过的概念,这就使得,即便cpu只能提供16位的地址,但是cpu可以通过提供两个相关的部件来提供两个16位的地址,从而在地址加法器中计算出物理地址,提高寻址能力。ps:原书这里对于段地址+偏移地址的解释非常好,强烈推荐去看看!
段地址:之前有了解过os的同学可能会搞混地址分段和段地址的概念,但是他们是不一样的东西,段地址是具体地址的表示方式,而地址分段我还没深入学,这里就不介绍了,
段寄存器 :这里不得不提到段寄存器的概念,我们在dosbox里面输入r,然后输入a,可以清晰的发现,汇编代码模式下的左侧num:num的数字和两个寄存器的数值一模一样!他们就是CS(代码段寄存器)和IP(指令指针寄存器),而我们输入t的时候,我们可以很轻易的发现,我们的IP会发生偏移,这也就意味着,随着我们IP的一次次偏移,我们输入的指令也会一步一步执行!!读到这里,一直困惑我的一些内容也得到了解决,比如,程序的代码是如何运行?答案显而易见。
一个实例,清晰了解:
- CS和IP通过加法器计算出当前应当执行的指令的地址,通过地址总线,发出读命令。
- 指令通过数据总线被送入CPU。
- 输入输出控制电路将指令送入指令缓冲器。
- 读取一条指令后,IP自增,使得可以读取下一条命令。
- 而在送入指令缓冲器之后,会送入执行控制器,执行这条指令。
- 此处省略一些步骤,最终ax变成了我们相应的数值。
这样,我们的一条指令就执行完毕了。
那么我们回过头来,我们在编程中可以轻易地改变这些寄存器的数值,从而掌控全局。
但是 ,事实上,我们的mov指令并不能直接操作CS:IP这两个寄存器,除此之外,我们可以通过jmp CS:IP这个指令来移动CS:IP的位置,另外,像jmp ax,就相当于是mov ip, ax但是实际上这个指令是不存在的,这里仅仅是比喻,另外我们在debug模式中,通过r命令也可以修改CS:IP的数值。
在debug模式中,有这些命令:
r命令,查看cpu相关寄存器,可以修改寄存器值
d命令,查看指定CS:IP的机器码
e命令,修改执行CS:IP的机器码
t命令,执行一条指令
u命令,查看机器码对应的汇编命令
a命令,进入汇编模式,通过这样以汇编的形式讲机器码写入内存
q命令,退出debug模式
1.2 内存访问
字单元:存放一个16位字节的字型数据的内存单元,分高位内存单元和低位内存单元,分别存放数据,以N位起始地址的字单元称为N地址字单元。
我们提过mov和add指令,但是实际上,我们的数据是存储在那里的?这就需要引入DS这个寄存器,存放要访问的段地址,而偏移地址通过[偏移地址]的格式来表示,但是我们的dosbox不支持直接mov ds, 1000来修改段寄存器,所以我们需要一个中转的寄存器,比如说
assembly
mov bx, 1000
mov ds, bx
mov al, [0]这样,可以讲2000:0000位置的值赋给al,也就是说...表示一个偏移地址!而ds寄存器则是我们的段地址。
我们也可以通过mov [0], al将寄存器的值送入内存,这里还有另一个知识点,就是1000:1存储的是字型数据的高八位,而0存储的是低八位
sub,add,mov:mov可以通过中间寄存器去操作段寄存器等,但是sub和add均不能操作段寄存器/指令指针寄存器
stack栈 :在汇编中也有栈的概念,我们通过pop [to]和push [from]来完成栈的操作,他们是通过SS:SP这两个寄存器来管理的,SS是段寄存器,而SP是偏移量,任意时刻指向栈顶元素,甚至,我们可以通过改变栈指针,来实现改变这个栈本身,太恐怖了,同时,在dosbox里面并不能自己检测栈顶是否越界,需要我们手动管理,本质上,pop和push是一种内存传送指令。
此处需要注意,栈是向下增长的,所以弹出元素,SP会增加,推入元素,SP会减少。
2.编写程序
2.1 概述
首先看汇编代码:
assembly
assume cs:ciallo ;将cs段寄存器和ciallo关联
ciallo segment ;ciallo是段名,表示段的开始
mov ax, 1155
add bx, ax
mov ax, 4c00H ;实现函数的返回
int 21H
ciallo ends ; 一个段的结束
end ;整个程序的结束虽然我们可以在在dosbox里面使用edit模式来进行写代码,但是感觉不太好用。
步骤:
masm xxx.asmlink xxx.objxxx执行
3. bx和loop
3.1 概述
bx和0有些类似,都表示内存单元,而0作为偏移地址可以随便指定,而bx也表示偏移地址,但是他的偏移地址就是寄存器bx中的数值,他们的段地址都是ds。
loop,就是循环
如下所示,cx代表循环的次数,每执行一次循环,cx--,直到为0,停止循环。
assembly
assume cs:ciallo
ciallo segment
mov ax, 2
mov cx, 11
s:
add ax, ax
loop s
mov ax, 4c00H
int 21H
ciallo ends
end另外,虽然我们在debug模式下,可以直接使用num表示偏移地址,但是在源代码中,我们需要使用段寄存器:[num]来表示,否则,你的num就会被解释成为num,当然,如果直接将num传送到bx寄存器上,然后直接通过[bx]访问也是可行的。
段前缀(包括cs:\[\] /ss:\[\] /ds:\[\] /es:\[\])咋用?我们可以通过段地址来实现内存复制,比方说:
assembly
code segment
mov ax, 0FFFFh ; 设置 DS = 0FFFFh
mov ds, ax
mov ax, 0020h ; 设置 ES = 0020h
mov es, ax
mov bx, 0 ; BX = 0(偏移地址)
mov cx, 12 ; CX = 12(循环次数)
s:
mov dl, [bx] ; 从 DS:BX 读取字节到 DL
mov es:[bx], dl ; 将 DL 写入 ES:BX
inc bx ; BX +1(移动到下一个字节)
loop s ; CX - 1,若不为 0 则跳转到 s 继续执行
mov ax, 4C00h ; 退出程序
int 21h ; DOS 终止程序中断
code ends
end我们可以通过额外段地址来存放需要复制的另一块区域,从而便利的实现内存的复制!
4. 包含多个段(segment)的程序
当我们希望能够同时相加多个数字,同时希望能够使用循环的方式,这和我们使用的数组很相似,我们可以通过这样来实现:
assembly
assume cs:ciallo
ciallo segment
dw 0123h, 0456h, 0789h, 0abch, 0defh ;定义字型数据,由于在代码段中,并且定义与最开始所以能够从cs:[0]开始找到他们
start: ;start表示程序的入口
mov bx, 0
mov ax, 0
mov cx, 5
s:
add ax, cs:[bx]
add bx,2
loop s
mov ax, 4c00h
int 21h
ciallo ends
end start ;表示程序的结束!根据新引入的start标志,我们可以将程序设计为以下结构
assembly
assume cs:ciallo
ciallo segment
数据
...
start:
我们要执行的程序
...
ciallo ends
end start ;程序的结束那么,回到我们的主题,如何将代码分段管理?
assembly
assume cs:ciallo, ds:data, ss:stack ; 假设代码段 (cs) 为 ciallo,数据段 (ds) 为 data,堆栈段 (ss) 为 stack
data segment ; 数据段开始
dw 0123h, 0456h, 0789h, 0abch, 0defh, 0fedh, 0cbah, 0987h ; 定义了 8 个 16 位数据
data ends ; 数据段结束
stack segment ; 堆栈段开始
dw 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0 ; 为堆栈分配 16 个 16 位单元,并初始化为 0
stack ends ; 堆栈段结束
ciallo segment ; 代码段开始
start: ; 代码段入口
mov ax, stack ; 将堆栈段的地址加载到 AX 寄存器
mov ss, ax ; 将 AX 的值赋给堆栈段寄存器 SS,设置堆栈段
mov sp, 20h ; 设置堆栈指针 SP 为 20h,堆栈从 20h 开始
mov ax, data ; 将数据段的地址加载到 AX 寄存器
mov ds, ax ; 将 AX 的值赋给数据段寄存器 DS,设置数据段
mov bx, 0 ; 将 BX 寄存器清零,用作数据索引
mov cx, 8 ; 将 CX 寄存器设置为 8,用作循环计数
s:
push [bx] ; 将数据段中 BX 地址指向的值压入堆栈
add bx, 2 ; 增加 BX,指向下一个数据项(每个数据项是 2 字节)
loop s ; 循环执行,直到 CX 变为 0
s0:
pop [bx] ; 将堆栈顶的值弹出并存储到数据段中,BX 指向的位置
add bx, 2 ; 增加 BX,指向下一个数据项
loop s0 ; 循环执行,直到 CX 变为 0
mov ax, 4c00h ; 设置结束程序的返回代码
int 21h ; 调用 DOS 中断,终止程序并返回代码 4C00h
ciallo ends ; 代码段结束
end start ; 程序结束总体来看,这段代码还是比较简单的,就是将data数据段中的数据压入栈中,然后再弹出来,同时尽管我们设置了堆栈段,但是我们还需要再start中根据段地址来初始化我们的ss和ds寄存器,以实现栈段和数据段匹配!
事实上,某一个段是栈段还是数据段,并不是在创建这个段时决定的,事实上,和他的名字没啥关系,而是和管理这个段的寄存器有关系,我们可以在代码段中将栈段寄存器的指针指向这个段,这样,才算成为一个完整的段。
5. 地址定位
5.1 技巧类
and,都为1才为1,否则为0
or,有一个为1,那么结果就是1
根据这两个,我们可以用已经学过的指令和ASCII码的性质实现字符大小写转换:
assembly
codesg segment
datasg segment
db 'BaSic'
db 'iNfoRmAtion'
start:
mov ax, datasg ; 加载数据段地址到 AX
mov ds, ax ; 设置 DS 指向数据段
mov bx, 0 ; 初始化 BX = 0,作为地址偏移
mov cx, 5 ; 计数器 CX = 5
s:
mov al, [bx] ; 读取数据段中偏移 BX 处的字节
and al, 11011111B ; 将 AL 转换为大写(清除第 5 位)
mov [bx], al ; 存回修改后的数据
inc bx ; BX 递增
loop s ; 继续循环,直到 CX 变为 0
mov bx, 5 ; 继续处理剩余部分,从偏移 5 开始
mov cx, 11 ; 计数器 CX = 11
s0:
mov al, [bx] ; 读取数据段中偏移 BX 处的字节
or al, 00100000B ; 将 AL 转换为小写(设置第 5 位,因为ASCII码小写字符的第五位总是1,所以根据这个可以实现大小写转换)
mov [bx], al ; 存回修改后的数据
inc bx ; BX 递增
loop s0 ; 继续循环,直到 CX 变为 0
mov ax, 4C00h ; 终止程序
int 21h ; 调用 DOS 中断
codesg ends
end start同时,为了更灵活的定位,我们的bx甚至可以采取bx + idata的形式,来实现更灵活的寻址。
另外,si(source index)和di(destination index)寄存器和bx的功能类似,完全可以相互替换使用
在我们需要往字符串后面追加字符串的时候,就可以将这几个寄存器搭配使用,使得效率更高。
我们也可以利用这几个寄存器执行更灵活的寻址操作,这里可以看原书,比如bx + si + idata的形式,这里有很多种写法
assembly
mov ax, [bx+200+si]
mov ax, [200+bx+si]
mov ax,200 [bx] [si]
mov ax, [bx].200[si]
mov ax,[bx][si].200当我们遇到使用这种寻址方式的时候,也难免会遇见要使用多重循环的情况,但是我们实际上只有一个cx,咋办?我们可以通过dx将这个cx保存起来,比如说:
assembly
datasg segment
; 数据段的定义可以在此处进行,例如:
; c db 10 ; 例如,如果 c 是一个常量或数据
datasg ends
code segment
start:
mov ax, datasg ; 加载数据段的地址到 AX
mov ds, ax ; 设置 DS 寄存器指向数据段
mov bx, 0 ; BX = 0,初始化偏移
mov cx, 4 ; CX = 4,循环计数器
s0:
mov dx, c ; 将 c 的值加载到 DX(假设 c 是数据段中的一个变量)
s:
..... ;你的逻辑
inc bx ; BX 增加,指向下一个数据位置
loop s ; 循环,直到 CX 为 0
mov cx, dx ; 将 DX 的值复制到 CX(恢复 CX 的计数)
loop s0 ; 循环 s0,直到 CX 为 0
mov ax, 4C00h ; DOS 中断 4C00h 结束程序
int 21h ; 调用 DOS 中断退出程序
code ends
end start当然,这种方法并不是通用的,我们可以将其保存到内存之中,需要使用的时候,再从内存中恢复,像这种保存状态,恢复状态,我们肯定会使用栈!
比如:
assembly
mov cx, 4
s0:
push cx ; 先保存外层循环计数器 CX
.... ; 执行某些操作
mov cx, 5
s1:
push cx ; 先保存内层循环计数器 CX
...
loop s1 ; 依靠 CX 自动递减
pop cx ; 恢复 CX(内层循环完成后恢复外层循环的 CX)
....
loop s0 ; 依靠 CX 自动递减这里有几个计组的概念:直接寻址/寄存器间接寻址/寄存器相对寻址/基址变址寻址/相对基址变址寻址,他们都是基于之前说的多个索引类寄存器来寻找地址,而事实上,在面对更多维度的数组的时候,寄存器的数量是有限的,我们可以通过计算之前几个维度的长度的乘积来获取索引,也就是说,多维数组实际上是连续的!这也就解释了go语言里面的切片等等的扩容机制为什么会重新开辟新的空间,而不是原地扩容了。
5.2 指令类
有时候,我们需要针对于访问的内存做一些标准,比如mov数字1的时候,我们可能不知道希望mov1个字节单元还是一个字单元,这时候就需要用到:
assembly
mov byte ptr [1000H], 1 ;修改一个字节单元。
mov word ptr [1000H], 1 ;修改一个字单元,也就是两个字节单元div:情况有点多...这里看8位和16位就行了
| 操作数位数 | 被除数寄存器 | 除数 | 商存储寄存器 | 余数存储寄存器 |
|---|---|---|---|---|
| 8 位 | AX (高8位AH,低8位AL) | 8位寄存器/内存 | AL | AH |
| 16 位 | DX:AX (高16位DX,低16位AX) | 16位寄存器/内存 | AX | DX |
| 32 位 | EDX:EAX (高32位EDX,低32位EAX) | 32位寄存器/内存 | EAX | EDX |
| 64 位(仅64位模式) | RDX:RAX (高64位RDX,低64位RAX) | 64位寄存器/内存 | RAX | RDX |
事实上,在我们的div中,被除数是由ax和dx联合起来用的
语法为div [寄存器/内存]但是不能直接给出数字!被除数默认已经确定了。
定义数据的时候,有以下三种:
- db,占一个字节
- dw,占一个字,两个字节
- dd,占两个字,四个字节
但是像之前那样,一次定义很多空间的时候,非要去一个一个输入吗?而且数起来也很麻烦,这个时候,有一个操作符dup ,可以实现批量重复数据,开辟空间:db 7 dup (0)就相当于开辟了7个字节的长度,数据均为0,同时也可以这样定义:db 3 dup ('abc', 'ABC')来实现重复开辟多个abcABC的空间。
在这里,推荐一下lab7,巩固一下还是很有帮助的。
6. 转移指令
offset是啥?一段代码看懂!
assembly
assume cs:code
code segment
s:
mov ax, bx
mov si, offset s
mov di, offset s0
mov ax, cs:[si]
mov cs:[di], ax
s0:
nop
nop
code end
ends这里主要是讲我们的s中的第一段代码拷贝到了s0中,这就是offset的作用了!
jmp,是一个无条件转移指令,可以修改CS:IP,也可以只修改IP
值得注意的是,jmp short指令转换成机器码,竟然是不包含目标地址的!但是CPU不是神仙,他是如何找到需要跳转的地址的?答案就是jmp short转换成机器码,虽然没有直接包含目标地址,但是却包含了目标地址的偏移量,从而节省空间,也就是说------jmp short的功能是IP ± 偏移量
- jmp short:短跳转,后跟标签等,范围128,超出会报错。
- jmp near ptr:段内跳转,跟段内地址。
- jmp far ptr:长跳转,后跟详细地址
- jmp word ptr:类似near,后接字,实现的是段内跳转
- jmp dword ptr:类似far,后接两个字,实现的是段间跳转。
jcxz:当cx为0的时候执行跳转,否则不执行
loop:和上面相反,当cx!=0的时候执行跳转,并且cx--,否则不执行任何操作,与此同时,这俩都是实施的短跳转,转换成机器码的时候,后跟的是偏移量。
dec,inc:自增自减,不必多说。
这里书上有一个lab8,奇怪的程序可以分析一下,就是我们之前讲过的jmp的应用。
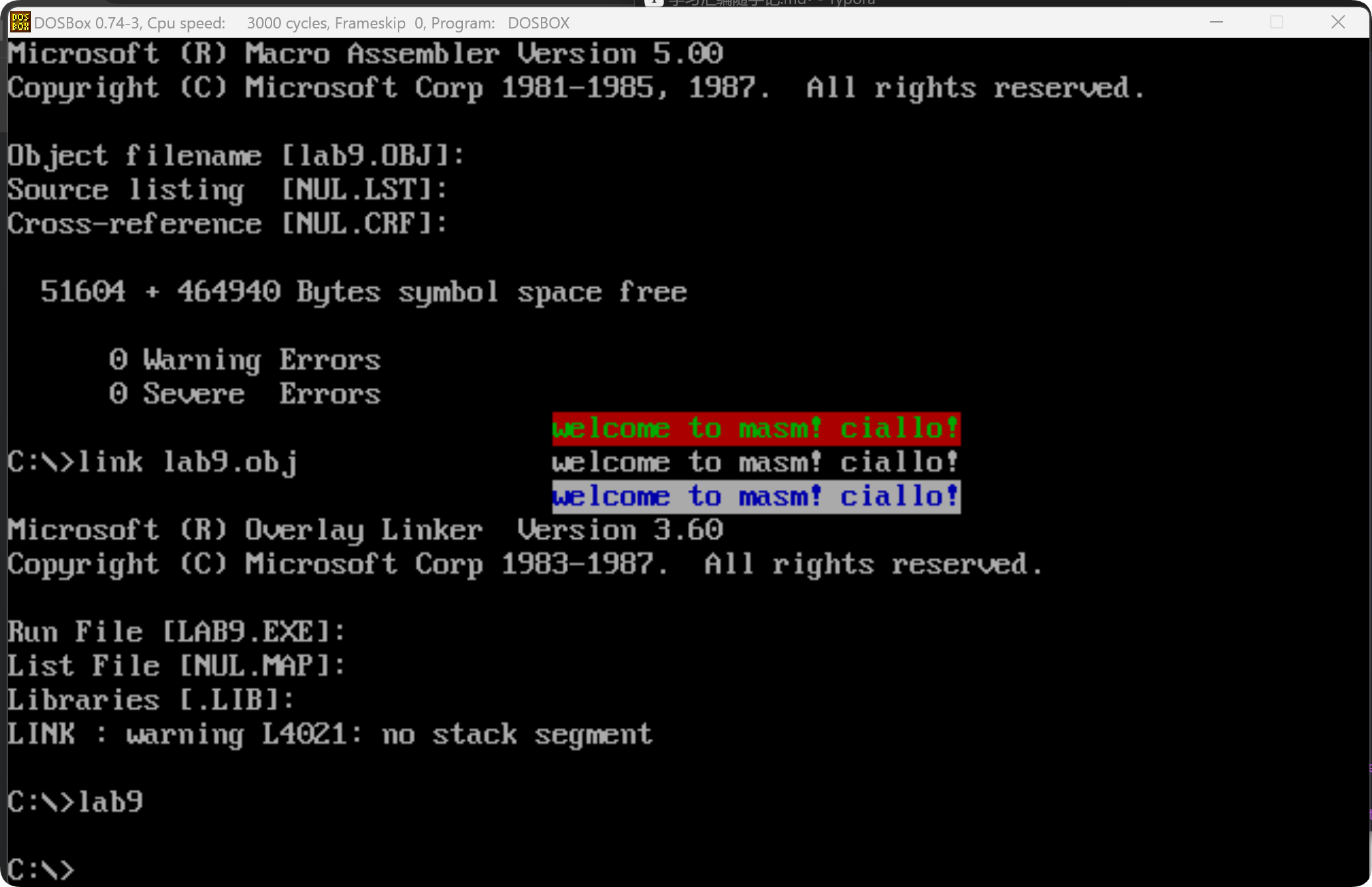
lab9:
assembly
assume ds:data, cs:code ; 声明数据段和代码段
data segment
db 'welcome to masm! ciallo!' ; 要显示的字符串
db 01000010B, 00000111B, 01110001B ; 颜色属性字节
data ends
stack segment
dw 0,0,0 ; 定义 3 个字节的栈空间
stack ends
code segment
start:
; 设置显存段
mov ax, 0B800H ; 文本模式下,显存起始地址是 0xB8000
mov es, ax ; ES 指向显存段
; 设置数据段
mov ax, data ; 让 DS 指向数据段
mov ds, ax
; 初始化寄存器
mov bx, 0000H ; BX 指向字符串的起始位置
mov si, 07C0H ; SI 指向显存目标位置
mov di, 0018H ; DI 指向颜色数据的起始位置
mov cx, 0003H ; CX = 3,控制外层循环
; 外层循环(控制行数)
s:
push cx ; 备份 CX,因为内层循环会修改它
mov cx, 0018H ; 内层循环次数(显示 24 个字符)
; 内层循环(控制列数)
s0:
mov al, ds:[bx] ; 读取字符串中的一个字符
mov es:[si], al ; 存入显存中(字符数据)
inc si ; SI 递增,指向显存的下一个位置(颜色字节)
mov al, ds:[di] ; 读取颜色数据
mov es:[si], al ; 存入显存(颜色数据)
inc bx ; BX 递增,读取下一个字符
inc si ; SI 递增,指向显存的下一个字符位置
loop s0 ; 内层循环继续执行,直到 CX=0
pop cx ; 恢复 CX
mov bx, 0000H ; 重置 BX 指向字符串起始位置
inc di ; DI 递增,切换颜色数据
add si, 70h ; 类似换行操作
loop s ; 继续外层循环,直到 CX=0(3 行)
mov ax, 4c00H
int 21H
code ends
end start有点意思,做到这里让我想到一句话,计算机的世界里没有魔法。
7. call and ret
ret:利用栈中数据,修改IP的内容,实现近跳转
retf:利用栈中数据实现far跳转,修改CS:IP
可以等价于对CS和IP进行pop
call:call,相信很多人对这个指令很熟悉,但是,call是跳转指令,也是修改CS:IP的,并且需要将相对应的CS:IP压入栈中,call也有几种不同的类型:
- call near ptr:将IP压入栈中
- call far ptr:CS:IP压入栈中
这里值得注意的是,call并不能实现短转移,并且其转移的原理和jmp相同,但是加了一个把地址压入栈中
这两个指令常用来形成函数,书上叫做子程序,这也是模块化程序设计的基础。
mul:八位乘法,放在ax中,16位乘法,高位DX,低位AX,同时,其中一个乘数固定是ax,只需要给定一个数字即可
当我们需要传入过多数据,寄存器不够用时,我们可以传递一个存放这一堆数据的指针,在传递一个长度,比方说,需要将一串字符串的所有字符转换成大写,传递一个指针,然后loop执行,或者说,在传入的数据末尾,加上一个0,使用jcxz判断数据最后是否为0即可。
但如果想要将一个字符串数组全部转换成大写的,就会使用到两层循环,这个时候如何函数体内使用cx的话,就会导致错误,解决方法就是在进入函数之前,将子程序用到的所有寄存器压入栈中,子程序返回后再恢复状态!
比如:
assembly
capital: ; 函数入口标签
push cx ; 保存 CX 寄存器的值到栈中,避免后续修改
push si ; 保存 SI 寄存器的值到栈中,避免后续修改
change: ; 变更标签,开始转换过程
mov cl, [si] ; 将 SI 指向的内存中的字节(字符)加载到 CL 寄存器
mov ch, 0 ; 清空 CH 寄存器,保证高位为 0
and byte ptr [si], 11011111B ; 对 SI 指向的字节执行按位与操作,将字符的第 5 位清零
; 这样可以将大写字母转换为小写字母(ASCII 中大写和小写字母的差异就在第 5 位)
inc si ; SI 寄存器加 1,指向下一个字节(字符)
jmp short change ; 跳转到 change 标签,继续处理下一个字符
ok: ; 结束标签
pop si ; 恢复之前保存的 SI 寄存器的值
pop cx ; 恢复之前保存的 CX 寄存器的值
ret ; 返回,结束当前的过程lab10-1:
assembly
assume ds:data, cs:code ; 假设数据段使用 DS,代码段使用 CS
;--------------------------
; 数据段 (data segment)
;--------------------------
data segment
db 'Welcome to masm!', 0 ; 定义一个字符串 "Welcome to masm!",以 0 结尾(字符串结束符)
data ends
;--------------------------
; 栈段 (stack segment)
;--------------------------
stack segment
dw 8 dup(0) ; 定义一个栈空间,包含 8 个字(16 字节),初始化为 0
stack ends
;--------------------------
; 代码段 (code segment)
;--------------------------
code segment
start:
mov dh, 8 ; 设置显示文本的行号为 8
mov dl, 3 ; 设置显示文本的列号为 3
mov cl, 2 ; 设置字符颜色为 2(绿色),但在此代码中没有使用该值
mov ax, data ; 将数据段的地址加载到 AX 寄存器
mov ds, ax ; 将 AX 中的地址加载到 DS 寄存器,设置数据段指针
mov si, 0 ; 将 SI 设置为 0,指向字符串的起始位置(即 "Welcome to masm!")
mov ax, stack ; 将栈段的地址加载到 AX
mov ss, ax ; 将 AX 中的值(即栈段地址)加载到 SS 寄存器,设置栈段指针
mov sp, 10H ; 设置栈指针 SP 为 0x10,即栈的顶部位置
call show_str ; 调用 show_str 子程序,显示字符串到屏幕
mov ax, 4c00h ; 设置退出程序的 DOS 中断代码(int 21h)
int 21h ; 调用 DOS 中断 21h 退出程序
;--------------------------
; show_str 子程序: 用于显示字符串
;--------------------------
show_str:
push dx ; 保存 DX 寄存器
push si ; 保存 SI 寄存器(字符串指针)
push ax ; 保存 AX 寄存器
push bx ; 保存 BX 寄存器(显存偏移地址)
push es ; 保存 ES 寄存器(显存段)
mov ax, 0b800h ; 将 0xB800h 加载到 AX,B800h 是显示器的显存段地址
mov es, ax ; 将显存段地址加载到 ES 寄存器,ES 指向显存
mov ax, 00a0h ; 每行 160 字节(80 列,每个字符占 2 字节)
mul dh ; AX = 160 * 行号(dh),计算该行的偏移
mov dh, 0 ; 清空 DH(行号)
add ax, dx ; 将列号(dx)加到 AX 中,得到最终的偏移地址
add ax, dx ; 再次加上列号,进一步调整偏移,因为每个字符实际上是由字符+颜色组成的
mov bx, ax ; 将最终的显存偏移地址存储在 BX 寄存器中
mov al, cl ; 将颜色值(cl)加载到 AL 寄存器中(此处未使用)
mov ch, 0 ; 清空 CH
mov si, 0 ; 将 SI 设置为 0,指向字符串的起始位置
s:
mov cl, ds:[si] ; 从 DS 段的 [SI] 位置读取字符到 CL
jcxz ok ; 如果 CL 为 0(字符串结束符),跳转到 ok 结束
mov es:[bx], cl ; 将字符 CL 存储到显存 [BX] 位置
inc bx ; 移动 BX 到下一个显存位置
mov es:[bx], al ; 将颜色值 AL 存储到显存的下一个字节(给字符添加颜色)
inc bx ; 移动 BX 到下一个显存位置
inc si ; 移动 SI 到下一个字符
jmp short s ; 继续循环处理下一个字符
ok:
pop es ; 恢复 ES 寄存器
pop bx ; 恢复 BX 寄存器
pop ax ; 恢复 AX 寄存器
pop si ; 恢复 SI 寄存器
pop dx ; 恢复 DX 寄存器
ret ; 返回调用位置
code ends
end start ; 程序的结束,指定程序入口剩下两个lab真懒得写了,next
8. 标志寄存器
这是我们将要学习的最后一个寄存器了
作用:
- 用来存储相关指令的某些执行结果。
- 用来为CPU 执行相关指令提供行为依据。
- 用来控制 CPU的相关工作方式。
ZF标志(zero):记录相关指令执行后的结果是否为0,如果是0,那么zf=1,否则zf=1,一般来说,像add,sub,mul等逻辑运算,是会影响zf的,但是mov,push等传送指令不会
PF标志(parity):记录奇偶性,偶1积0
SF标志(sign):符号标志位正0负1.
CF标志(carry):无符号运算的进位或者借位标志位,即便是在两个比较大的数字相加,产生进位导致溢出,这个进位也会存储在CD中,减法当然也一样。
OF标志(overflow):记录有符号运算中中产生的溢出
abc 指令:abc是带进位的加法指令,功能为ax = ax + bx + cf。
sbb 指令:带借位的减法指令,实现的是ax = ax - bx - cf。
cmp指令:相当于减法,但是不保存结果,仅仅根据计算结果对标志位进行设置,通过这样,可以实现各种比较运算,很多人第一直觉是只通过sf来进行比较大小,但是真的假的?如果计算发生溢出,那么就会产生错误,所以还需要判断of溢出位来进行判断。
当然,通过比较之后,我们可以通过条件转移指令来修改IP,除了jcxz,常见的有:
- je(jump equal):相等则跳转(检测zf=1)
- jne(jump not equal):不相等则跳转(检测zf=0)
- jb(jump below):低于则跳转(检测cf=1)
- jnb(jump not below):大于等于,即不低于跳转(检测cf=0)
- ja(jump above):大于则跳转(cf=0以及zf=0)
- jna(jump not above):不大于,小于等于则跳转(cf=1且zf=1)
这样,就比较好记忆了。
DF标志位:在串处理指令中,如果df为1,每次操作后,si和di递减,否则递增。
串传送指令movsb ,相当于将源地址(ds:si)指向的字节复制到目标地址(es:di),并且根据df的标志位,让di和si自增或自减,还可以通过movsw来传送一个字,也就是byte和word。
而一般来说,这两个指令都和rep 配合进行使用,如rep movsb相当于
assembly
s:
movsb
loop s这样就可以快速的实现cx个字符的传送,而我们可以通过cld 将df置为0,通过std将df置为1
另外,还有一种指令可以实现快速的保存寄存器,就是popf 和pushf他们可以实现快速的将标志寄存器压入栈中,并且一次性弹出。
9. 内中断
cpu内部有什么事情发生的时候,就会产生需要处理的终端信息,有以下几种:
除法错误:0
单步执行:1
执行into指令:4
执行int指令:指令格式为
int n,n就是提供给cpu的终端类型码
通过不同的类型码,我们cpu可以定位到不同的处理位置,来进行不同的处理,如何根据类型码来定位到相应的CS:IP地址?事实上,cpu是通过中断向量表来定位的,通过这样的方式来找到不同中断类型的不同的处理位置,而中断向量表则存放在内存中。
终端过程是咋样的?
- 收到中断信息,拿到中断类型码
- 将标志寄存器的值入栈
- 设置标志寄存器的第八位的TF和第九位的IF为0
- CS内容入栈
- IP内容入栈
- 从内存地址中相应位置的两个字单元读取程序的入口地址,设置CS:IP
可以简单表示为:
assembly
;拿到了中断类型码N
pushf
TF=0, IF=0
push CS
push IP
(IP)=(N*4), (CS)=(N*4+2)随后,便会执行由我们自己编写的中断程序。(我去,真的是执行自己写的中断程序啊,看到这里,总感觉莫名的兴奋,真的是掌控全局!ps:虽然感觉有点麻烦)
这里还需要引入一个iret指令,它通常和硬件自动完成的中断过程配合使用,用于中断返回,用汇编可以描述成下面的样子:
assembly
pop IP
pop CS
popf可以发现,出栈入栈顺序相互对应,计算机的世界里没有魔法!!!,iret执行之后,就会回到中断程序前的执行点继续执行程序。
以除法溢出为例,当发生除法溢出时,我们通过在debug模式下编写:
assembly
mov ax, 1000
mov bh, 1
div bh通过不断执行代码,我们会发现最终CS:IP会跳转到另一个位置,我这里是dosbox环境,并没有产生对应的divide overflow的信息,但是此时确确实实时跳转了,我觉得此时应该是还没有放任何中断程序,而需要我们自己去编写。
下面我们将进行伟大的一步------编写自定义中断程序
我们将我们需要编写的这段程序成为do0,毫无疑问,他需要被放在内存中,但是放在哪个位置成为了我们需要考虑的点,尽管我们能够去向操作系统申请内存,但是我们毕竟是汇编er,操作系统?大可不必理会。
书中说,我们将程序放在向量表中就可以了,这样能够简化布局,虽然感觉有点怪怪的,但是还是实践一下吧。
我们需要做的事情:
- 编写中断程序
- 将do0送入0000:0200
- 将do0入口地址存储在中断向量表的0号表项中
大体的代码框架如下,接下来,由我们去完善它!
assembly
assume cs:code
code segment
start:
; do0的安装程序
; 设置中断向量表
mov ax, 4c00h
inr 21h
do0:
; 显示字符串'overflow'
mov ax 4c00h
int 21h
code ends
end start现在先说一下,之前为什么要把TF位设置为0,因为我们每执行一条指令,我们的cpu如果检测到TF值为1,那么就会产生单步中断,中断类型码为1,也就是我们之前提过的单步执行。
知道了这个,先回想一下,为什么我们在使用Debug命令的时候,输入t命令,能够使得我们的代码一步一步执行,事实上,是不会由任何程序能够让cpu在执行一条指令后停止的,这里Debug是利用了cpu提供的这一中断功能从而实现的t命令展现出来的功能。
而如果我们在进入中断的时候,如果此时的TF=1,那么就会出现无限循环地去中断,那么我们就需要在进入中断的程序之前将TF置为0。而事实上,我们在输入t命令的时候,就会将TF置为1,然后会引发单步中断,但是事实上会在进入中断之前将TF置为0,以此来避免在执行中断处理程序的时候发生单步中断。
这里我其实思考了一下,为什么中断能够暂停程序?为什么有的中断不需要暂停,这个t到底是如何实现的直接把程序暂停了?我觉得,这跟输入输出有关,如果一个中断程序只需要输出,而不需要用户的交互,直接一步一步执行即可,在这种情况下,这个中断实际上也是一个子程序,但是如果需要用户的交互,比如说等待输入字符,那么此时就会产生中断就是在等待的错觉,事实上,他是在等待用户的操作,使得程序能够进一步执行。
risc-v
1. 环境搭建
半路去学risc-v了,准备去学xv6
索性就一次性把环境搭建起来了!我看网上的环境搭建版本大多是2020年,或者ubuntu20版本的,我也跟着很久没有搭建好,在下载工具链之前,我最开始直接用git去拉取哪个工具链,但是好多东西都拉不下来,后面我直接把压缩包下载下来用finalshell传上去了,后面有用sudo apt去安装,如果不行就直接下那个压缩包吧
下载工具链
bash
sudo apt install git build-essential gdb-multiarch qemu-system-misc gcc-riscv64-linux-gnu binutils-riscv64-linux-gnu libglib2.0-dev libpixman-1-dev gcc-riscv64-unknown-elf下载qemu
bash
wget https://download.qemu.org/qemu-5.1.0.tar.xz
tar -xf qemu-5.1.0.tar.xz
cd qemu-5.1.0
./configure --disable-kvm --disable-werror --prefix=/usr/local --target-list=riscv64-softmmu
make
sudo make install拉取xv6源码
bash
git clone git://g.csail.mit.edu/xv6-labs-2024
cd xv6-labs-2024
git checkout util
## 拉取特定分支到本地
git clone -b pgtbl git://g.csail.mit.edu/xv6-labs-2024然后:
bash
make
make qemu此时如果出现
bash
xv6 kernel is booting
hart 1 starting
hart 2 starting
init: starting sh则说明成功了。
那么还需要进一步验证
检查工具链:
bash
riscv64-unknown-elf-gcc --version检查调试工具(xv6源码目录下):
一个终端输入:
bash
make qemu-gdb
sed "s/:1234/:26000/" < .gdbinit.tmpl-riscv > .gdbinit
*** Now run 'gdb' in another window.
qemu-system-riscv64 -machine virt -bios none -kernel kernel/kernel -m 128M -smp 3 -nographic -drive file=fs.img,if=none,format=raw,id=x0 -device virtio-blk-device,drive=x0,bus=virtio-mmio-bus.0 -S -gdb tcp::26000另一个终端:
bash
gdb-multiarch -q kernel/kernel此时如果进入了gdb,这便是没有问题了!
softmmu
make
sudo make install
拉取xv6源码
```bash
git clone git://g.csail.mit.edu/xv6-labs-2024
cd xv6-labs-2024
git checkout util
## 拉取特定分支到本地
git clone -b pgtbl git://g.csail.mit.edu/xv6-labs-2024然后:
bash
make
make qemu此时如果出现
bash
xv6 kernel is booting
hart 1 starting
hart 2 starting
init: starting sh则说明成功了。
那么还需要进一步验证
检查工具链:
bash
riscv64-unknown-elf-gcc --version检查调试工具(xv6源码目录下):
一个终端输入:
bash
make qemu-gdb
sed "s/:1234/:26000/" < .gdbinit.tmpl-riscv > .gdbinit
*** Now run 'gdb' in another window.
qemu-system-riscv64 -machine virt -bios none -kernel kernel/kernel -m 128M -smp 3 -nographic -drive file=fs.img,if=none,format=raw,id=x0 -device virtio-blk-device,drive=x0,bus=virtio-mmio-bus.0 -S -gdb tcp::26000另一个终端:
bash
gdb-multiarch -q kernel/kernel此时如果进入了gdb,这便是没有问题了!
说点想说的,本来自己寒假开始很想学os的,但是由于对汇编不够重视,就只看了速成课,导致哈工大一点没看懂,包括寒假去看jyy的os课,也是云里雾里的,近期看了看ostep,然后重新把汇编捡起来,然后被建议去学mit的6.S081,虽然让我大受打击,但是从汇编里面也能学到不少的思想,也不算0收获,然后昨天早上午配完了环境,看了看课的文档和相关介绍,倒是感觉质量很不错,就是这样,希望自己不要放弃,我先润了~