概述
在目标检测领域,有一个指标被广泛认为是衡量模型性能的"黄金标准",它就是 mAP(Mean Average Precision,平均精确率均值)。如果你曾经接触过目标检测模型(如 YOLO、Faster R-CNN 或 SSD),那么你一定听说过 mAP。但你是否真正理解 mAP 背后的含义?为什么研究人员如此信赖它?mAP@0.5 和 mAP@0.95 又有什么区别?本文将为你揭开 mAP 的神秘面纱。

1. 目标检测比分类更难
在分类任务中,只需要预测一个标签。而在目标检测中,需要完成两项任务:
- 找到目标的位置(定位:绘制边界框)。
- 确定目标是什么(分类)。
那么,我们如何衡量成功呢?准确率在这里并不适用。我们需要更全面的指标,而 精确率 、召回率 和它们的"老板":mAP,正是为此而生。
2. 精确率与召回率
精确率 :
衡量你的模型猜测有多准确。
- 在模型检测到的所有目标中,有多少是正确的?
公式: T r u e P o s i t i v e s / ( T r u e P o s i t i v e s + F a l s e P o s i t i v e s ) True Positives / (True Positives + False Positives) TruePositives/(TruePositives+FalsePositives)
召回率 :
衡量你的模型有多全面。
- 在所有实际存在的目标中,模型找到了多少?
公式: T r u e P o s i t i v e s / ( T r u e P o s i t i v e s + F a l s e N e g a t i v e s ) True Positives / (True Positives + False Negatives) TruePositives/(TruePositives+FalseNegatives)
但仅靠精确率和召回率并不能说明全部问题。如果模型在找到目标方面表现出色,但在绘制边界框方面却很糟糕怎么办?
这就是交并比(IoU)的作用所在。
3. IoU:检测质量的把关者
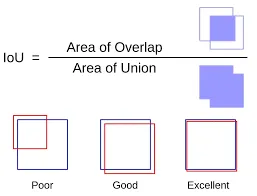
交并比(IoU) 是一个关键指标,用于衡量预测边界框与真实边界框(实际目标位置)的对齐程度。它的计算方法如下:
如何计算 IoU?
- 交集:预测框与真实框之间的重叠区域。
- 并集 :两个框覆盖的总面积。
公式 :IoU = 交集面积 / 并集面积
举例说明:
- 如果模型预测的框与真实框完全重叠,IoU = 1.0。
- 如果没有重叠,IoU = 0.0。
- 如果预测框覆盖了真实框的一半,IoU ≈ 0.5。
为什么 IoU 阈值很重要?
i. IoU 阈值(例如 0.5)作为检测的及格标准:
- 真正例(TP):IoU ≥ 阈值(例如 ≥0.5)。
- 假正例(FP):IoU < 阈值(例如预测框偏差过大)。
ii. 更高的阈值要求更好的定位精度:
- mAP@0.5 是宽松的(框只需要 50% 的重叠)。
- mAP@0.75 要求精确的定位(75% 的重叠)。
- mAP@0.95 是非常严格的(用于医疗影像等安全关键任务)。
让我们用一个现实世界的类比来理解 IoU 阈值:
- 阈值为 0.5 就像考试中 50 分及格(适用于大多数情况)。
- 阈值为 0.9 就像需要 90 分才能及格(仅适用于精英表现)。
那么,现在我们该如何解读模型的性能呢?我们有精确率、召回率和 IoU,但该如何利用它们呢?
答案是 平均精确率(AP)。
4. 平均精确率(AP)
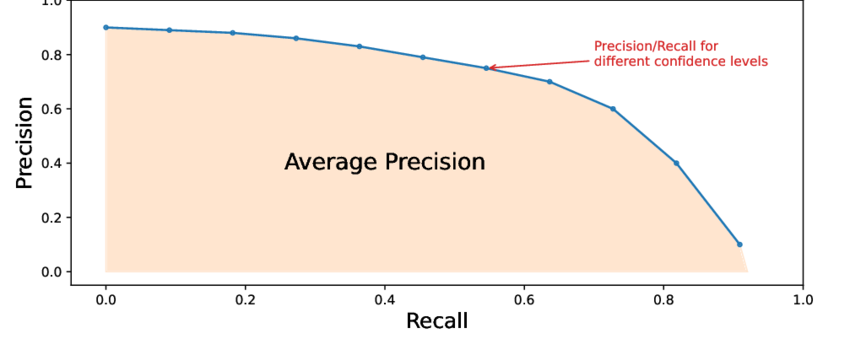
对于单一类别(例如"猫"),可以通过以下步骤计算 AP(Precision Recall 曲线下的面积):
i. 按置信度排序检测结果:从模型最自信的预测开始。
ii. 在每一步计算精确率和召回率:随着置信度阈值的降低,你:
- 增加召回率(找到更多目标,但可能会引入更多假正例)。
- 降低精确率(检测数量增加,但其中一些可能是错误的)。
iii. 绘制精确率-召回率(PR)曲线:
- X轴 = 召回率(0 到 1)。
- Y轴 = 精确率(0 到 1)。
- 完美模型的 PR 曲线会紧贴右上角。
iv. 计算 AP(PR 曲线下的面积):
- AP 将整个 PR 曲线总结为一个数字(0 到 1)。
对于平均精确率,AUC 的计算方法如下:
- PR 曲线通过在固定召回率水平上插值精确率进行"平滑"。
- AP = 在 11 个等间距的召回率点(0.0, 0.1, ..., 1.0)处的精确率值的平均值。
- 更简单的方法:使用原始 PR 曲线下的积分(面积)。
完美的 PR 曲线下的面积 = AP = 1.0(在所有召回率水平上都达到 100% 的精确率)。
5.为什么 AP 如此重要
i. 平衡精确率和召回率:高 AP 意味着你的模型:
- 能够检测到大多数目标(高召回率)。
- 很少犯错(高精确率)。
ii. 针对特定类别的洞察:AP 是按类别计算的。如果"猫"的 AP 很低,说明你的模型在检测猫方面存在困难。
iii. 与阈值无关:与固定阈值指标(例如准确率)不同,AP 在所有置信度水平上评估性能。
举例说明:
高平均精确率(例如 0.9):
- 在每个召回率水平上,精确率都保持很高。
- 如果模型检测到 90% 的目标(召回率 = 0.9),精确率仍然为 90%。
低平均精确率(例如 0.3):
- 随着召回率的增加,精确率急剧下降。
- 检测到 80% 的目标(召回率 = 0.8)可能意味着精确率下降到 20%。
mAP(Mean Average Precision) 仅仅是所有类别 AP 的平均值。
- 例如:如果你的模型可以检测猫、狗和汽车, m A P = ( A P c a t + A P d o g + A P c a r ) / 3 mAP = (AP_{cat} + AP_{dog} + AP_{car}) / 3 mAP=(APcat+APdog+APcar)/3。
mAP@0.5 与 mAP@0.95
mAP@0.5:
- 使用宽松的 IoU 阈值(50% 的重叠)。
- 常用于通用目标检测(例如 PASCAL VOC 数据集)。
- 倾向于检测到目标的模型,即使边界框有些偏差。
mAP@0.95:
- 使用严格的 IoU 阈值(95% 的重叠)。
- 倾向于具有近乎完美定位的模型。
- 用于高风险应用(例如医疗影像、机器人技术)。
COCO mAP:在 IoU 阈值从 0.5 到 0.95(以 0.05 为增量)的范围内计算 mAP 的平均值。这平衡了严格性和宽松性。
为什么 mAP 是最终的信任指标?
- 平衡精确率与召回率:与准确率不同,mAP 会惩罚那些错过目标(低召回率)或产生大量误检测(低精确率)的模型。
- 定位很重要:通过使用 IoU,mAP 确保边界框不仅仅是"足够好",而是达到你设定的阈值精度。
- 类别无关:适用于多类别检测,不会偏向频繁出现的类别。
对于 YOLO 模型(既注重速度又注重精度),mAP 可以告诉你:
- 检测的可靠性(精确率)。
- 漏掉的目标数量(召回率)。
- 边界框的紧密程度(IoU)。
结论
目标检测是一项复杂的任务,评估其性能需要一个能够平衡精确率、召回率和定位精度的指标。这就是 mAP 的闪光点。它不仅仅是一个数字,而是衡量你的模型检测目标、绘制边界框以及处理多类别能力的综合指标。
无论你使用的是 YOLO、Faster R-CNN 还是其他任何目标检测框架,mAP 都为你提供了一个单一且可靠的指标,用于比较模型、调整超参数并将性能提升到更高水平。有了 mAP@0.5 和 mAP@0.95 等变体,你可以根据特定应用的精度要求定制评估。
所以,下次你训练目标检测模型时,不要只看 mAP 分数 ------ 要理解它。因为当涉及到衡量检测性能时,mAP 不仅仅是一个指标;它就是那个指标。