原文地址:
2502.09980![]() https://arxiv.org/pdf/2502.09980
https://arxiv.org/pdf/2502.09980
论文翻译:
V2V-LLM: Vehicle-to-Vehicle Cooperative Autonomous Driving with
Multi-Modal Large Language Models
V2V-LLM:采用多模式大型语言模型的车对车协同自动驾驶
摘要:
当前的自动驾驶车辆主要依赖于其各个传感器来了解周围场景并规划未来的轨迹,而当传感器发生故障或被遮挡时,这可能是不可靠的。为了解决这个问题,人们提出了通过车对车(V2V)通信的协作感知方法,但它们往往专注于检测或跟踪等感知任务。这些方法如何有助于整体合作规划绩效仍然没有得到充分的研究。受到使用大型语言模型(LLM)构建自动驾驶系统的最新进展的启发,我们提出了一种新颖的问题设置,将多模式LLM集成到协作式自动驾驶中,并提出了车对车调度服务(V2V-QA)数据集和基准。我们还提出了我们的基线方法车对车多模式大型语言模型(V2V-LLM),该模型使用LLM来融合来自多个连接的自动驾驶车辆(CAB)的感知信息,并回答各种类型的驾驶相关问题:接地、显着物体识别和规划。实验结果表明,我们提出的V2V-LLM可以成为一种有前途的统一模型架构,用于在协作自动驾驶中执行各种任务,并且优于使用不同融合方法的其他基线方法。我们的工作还开辟了一个新的研究方向,可以提高未来自动驾驶系统的安全性。代码和数据将向公众发布,以促进该领域的开源研究。
1 介绍
由于深度学习算法、计算基础设施的发展以及大规模现实世界驾驶数据集和基准的发布,自动驾驶技术取得了显着进步3,13,38。然而,自动驾驶汽车的感知和规划系统在日常操作中,主要依靠当地的LiDAR传感器和相机来检测附近的显著物体并规划未来的轨迹。当传感器被附近的大型物体遮挡时,这种方法可能会遇到安全关键问题。在这种情况下,自动驾驶车辆无法准确地检测到附近所有值得注意的物体,使得后续的规划结果不可靠。
为了解决这个安全关键问题,最近的研究提出了通过车对车(V2 V)通信的合作感知算法6,9,44,50-52。在协作驾驶场景中,多个彼此附近行驶的互联自动驾驶汽车(CAB)通过V2 V通信共享其感知信息。然后,将从多个CV接收到的感知数据进行融合,以生成更好的整体检测或跟踪结果。许多协作自动驾驶数据集已向公众发布,包括模拟数据10、24、51、52和真实数据48、53、59、60。这些数据集还建立了评估合作感知算法性能的基准。然而,迄今为止,合作驾驶研究和数据集主要集中在感知任务上。这些最先进的合作感知模型如何与下游规划模型相连接以产生良好的合作规划结果仍然没有得到充分的探索。
最近的其他研究尝试使用基于LLM的方法来为个人自动驾驶车辆构建端到端感知和规划算法,因为它们具有来自大规模预训练数据的常识推理和概括能力。这些基于LLM的模型将原始传感器输入编码为视觉特征,然后执行视觉理解并回答各种与驾驶相关的感知和规划问题。这些方法已经显示出一些希望,但尚未探索合作感知和规划的好处。当单个车辆的感觉能力有限时,没有合作感知的基于LLM的驾驶算法也可能面临安全关键问题。
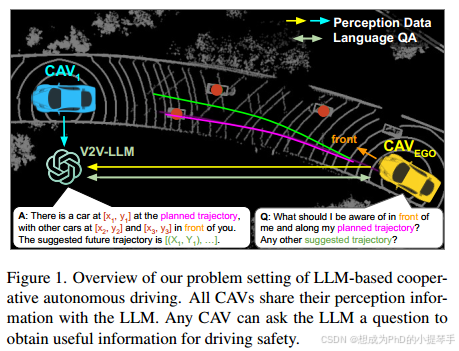
图1.概述我们基于LLM的协作自动驾驶的问题设置。所有CAB都与LLM共享他们的感知信息。任何卡韦都可以向LLM提出问题,以获取对驾驶安全有用的信息。
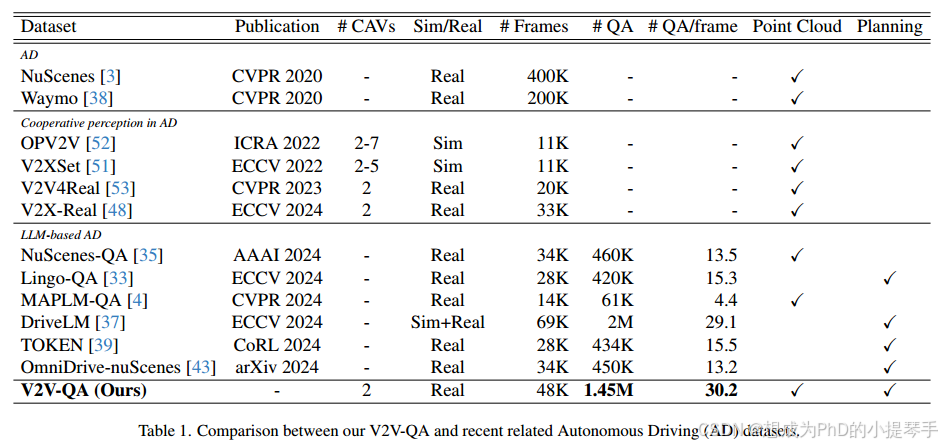
在本文中,我们提出并探索了一种新的问题设置,其中基于LLM的方法用于构建协作自动驾驶的端到端感知和规划算法,如图1所示。在这个问题设置中,我们假设有多个CAV和一个集中式LLM计算节点。所有CAV都与LLM共享其个人感知信息。任何CAV都可以用自然语言向LLM提出问题,以获得对驾驶安全有用的信息。为了研究这个问题,我们首先创建了V2V-QA数据集,该数据集基于V2V4 Real 53和V2X-Real 48用于自动驾驶的协作感知数据集。我们的V2 VQA包括接地(图图2a至图2c)、显著对象识别(图2d)和规划(图2 e)问答对。我们的新问题设置和其他现有的基于LLM的驾驶研究之间存在一些差异4,33,35,37,39,43。首先,我们的LLM可以融合来自不同卡韦的多个感知信息,并为任何卡韦的不同问题提供答案,而不仅仅为单个自动驾驶汽车提供服务。其次,我们的基础问题是专门设计的,旨在关注每个单独的卡韦的潜在遮挡区域。Tab1中总结了我们的V2V-QA与其他相关数据集之间的更多差异。
为了建立V2V-QA数据集的基准,我们首先提出了一种强基线方法:用于协作自动驾驶的车到车多模式大型语言模型(V2 V-LLM),如图3所示。每个卡韦提取自己的感知特征并与V2 V-LLM共享。V2 V-LLM融合场景级特征图和对象级特征载体,然后进行视觉和语言理解,为V2 V-QA中的输入驱动相关问题提供答案。我们还将V2V-LLM与对应于不同特征融合方法的其他基线方法进行比较:无融合、早期融合和中间融合48,50-53。结果表明,V2 V-LLM在更重要的显着物体识别和规划任务中实现了最佳性能,并在接地任务中实现了竞争性能,为整个自动驾驶系统实现了强劲的性能。
我们的贡献可以总结如下:
- 我们创建并引入V2V-QA数据集,以支持基于LLM的端到端协作自动驾驶方法的开发和评估。V2V-QA包括基础、显着对象识别和规划问答任务。
- 我们提出了一种用于协作自动驾驶的基线方法V2 V-LLM,为V2 V-QA提供初始基准。该方法融合了多个卡韦提供的场景级特征地图和对象级特征载体,回答不同卡韦与驾驶相关的问题。
- 我们为V2V-QA创建了一个基准,并表明V2V-LLM在显着物体识别和规划任务方面优于其他基线融合方法,并在接地任务方面实现了有竞争力的结果,这表明V2V-LLM有潜力成为协作自动驾驶的基础模型。
2 相关工作
2.1.自动驾驶中的合作感知
提出了合作感知算法来解决个人自主车辆中潜在的遮挡问题。开创性工作F-Cooper提出了第一种中间融合方法,该方法合并特征图以实现良好的协作检测性能。V2VNet构建用于合作感知的图神经网络。DiscoNet采用知识提炼方法。最近的工作Attendix、V2X-ViT和CoBEVT集成了基于注意力的模型来聚合特征。另一组作品的重点是开发有效的沟通方法。
从数据集的角度,模拟数据集OPV2V、V2X-Sim和V2 XSet首先是为合作感知研究而生成的。最近,收集了真实的数据集。V2V4Real是全球第一个具有感知基准的真实车对车合作感知数据集。V2X-Real、DAIR-V2X和TUMTraf-V2X还包括来自路边基础设施的传感器数据。
与这组研究不同的是,我们的问题设置和拟议的V2 V-QA数据集包括多个CAB的感知和规划问答任务。我们提出的V2 V-LLM还采用了一种新颖的基于LLM的融合方法。
2.2 基于LLM的自动驾驶
基于图像的规划模型首先将驾驶场景,物体检测结果,车辆自身状态转换为LLM的文本输入。然后LLM生成文本输出,包括建议的驾驶动作或计划的未来轨迹。最近的方法使用多模式大型语言模型(MLLM)将点云或图像编码为视觉特征。然后,将视觉特征投影到语言嵌入空间,供LLM执行视觉理解和问答任务。
从数据集的角度来看,几个基于LLM的自动驾驶数据集是在现有自动驾驶数据集的基础上构建的。例如,Talk 2Car 11、NuPromote 47、NuScenes-QA 35、NuDirecct 49和Reason 2Drive 34基于NuScenes 3数据集创建字幕、感知、预测和规划QA对。BDD-X 18由BDD 100 K 58扩展而来。DriveLM 37采用NuScenes 3的真实数据和CARLA 12的模拟数据,以实现更大规模、更多样化的驾驶QA。独立策划的其他数据集专注于不同类型的QA任务。HAD 19包含人与车辆的建议数据。戏剧30引入了联合风险定位和字幕。Lingo-QA 33提出了反事实问答任务。MAPLMQA 4强调地图和交通场景的理解。
与那些仅支持个人自动驾驶汽车的基于LLM的驾驶研究不同,我们的问题设置和拟议的V2 V-QA数据集是为具有多个CAE的协作驾驶场景而设计的。在我们的问题设置中,LLM可以聚合多个Cavv的感知特征,并为不同Cavv的问题提供答案。我们的V2 V-QA还旨在关注潜在的遮挡区域。此外,我们的V2VQA包含高速公路和城市合作驾驶场景,使我们的规划任务比之前基于NuScenes 3数据集的作品更具挑战性。
3 V2V-QA数据集
为了在我们提出的新颖问题设置(基于LLM的协作自动驾驶)中进行研究,我们创建了车对车调度服务(V2VQA)数据集,以基准测试不同模型在融合感知信息和回答安全关键驾驶相关问题方面的性能。
3.1 问题设置
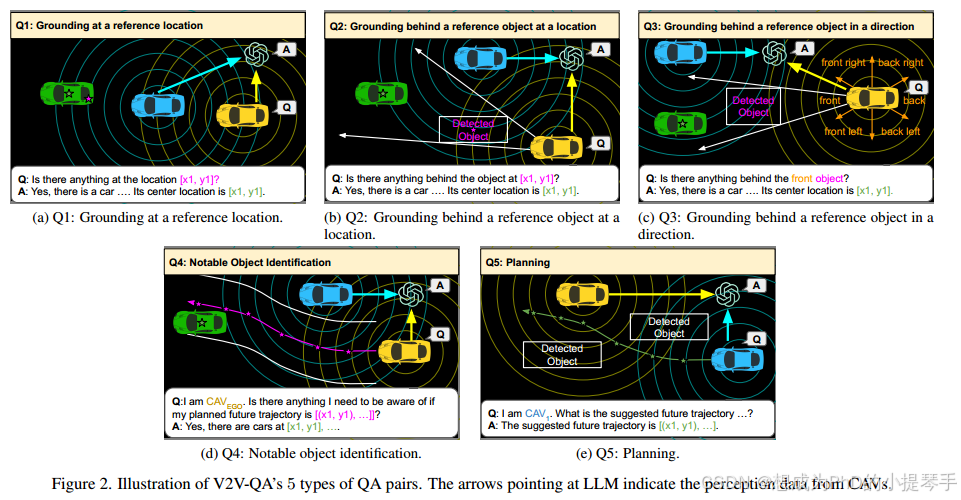
我们提出的具有LLM问题的V2V协作自动驾驶如图1所示。在此设置中,我们假设有多个互联自动驾驶车辆(Cavs)和一个集中式LLM计算节点。所有CAV都与集中式LLM共享其各自的感知信息,例如场景级或对象级特征。任何CAV都可以用自然语言向LLM提出问题,以获取驾驶安全信息。LLM汇总从多个CAE接收的感知信息,并为CAE问题提供自然语言答案。在这项研究中,问题和答案包括基础(Q1-3)、显着物体识别(Q4)和规划(Q5),如图2所示。
3.2 数据集细节
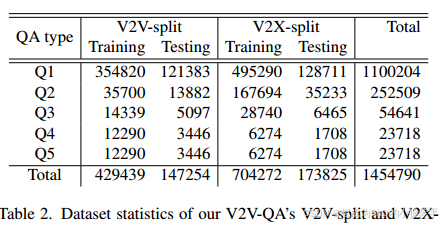
我们的V2 V-QA数据集包含两个拆分:V2 V-split和V2 X-split,它们分别构建在V2 V4 Real 53和V2 X-Real 48数据集之上。这些基本数据集是通过驾驶两辆配备LiDART传感器的车辆同时靠近彼此收集的。这些数据集还包括表2中其他对象的3D边界框注释我们的V2 V-QA的V2 V-split和V2 Xsplit的数据集统计。Q1:在参考位置接地。Q2:在某个位置的参考物体后面接地。Q3:以一个方向落在参考物体后面。Q4:著名物体识别。Q5:规划。驾驶场景。在V2 V4 Real 53中,训练集具有32个驱动序列,每个卡韦总共有7105帧数据,测试集具有9个驱动序列,每个卡韦总共有1993帧数据。在V2X-Real 48中,训练集有43个驱动序列,每个CAV总共有5772帧数据,测试集有9个驱动序列,每个CAV总共有1253帧数据。帧率为10 Hz。在V2X-Real 48中,一些驾驶场景还提供来自路边基础设施的激光雷达点云。在我们的V2X分割中,我们还将它们作为LLM的感知输入,方法与使用CAV的激光雷达点云回答CAV的问题相同。在构建V2 V-split和V2Xsplit时,我们遵循V2 V4 Real 53和V2X-Real 48中相同的训练和测试设置。
表2总结了我们提出的V2 V-QA的V2 V-分裂和V2X-分裂中QA对的数量。我们总共有1.45 M QA对,平均每帧30.2 QA对。更多详情请参阅补充材料。
3.3 问答配对节目
对于V2 V4 Real 53和V2X-Real 48数据集的每个帧,我们创建了5种不同类型的QA对,包括3种类型的基础问题,1种类型的显着对象识别问题和1种类型的规划问题。这些QA是为合作驾驶场景而设计的。为了生成这些QA对的实例,我们使用V2 V4 Real 53和V2X-Real 48的地面实况边界框注释,每个CAV的地面实况轨迹和单个检测结果作为源信息。然后,我们使用不同的手动设计的规则的基础上,上述实体和文本模板之间的几何关系,以产生我们的QA对。文本模板可以在图1A和1B中看到。5和6.每个QA类型的生成规则如下所述。
Q1.在参考位置接地(图2a):在这种类型的问题中,我们要求LLM识别是否存在占据特定查询2D位置的对象。如果是,则LLM被期望提供对象的中心位置。否则,LLM应指示在参考位置处没有任何东西。我们使用地面真值框和每个卡韦的单个检测结果框的中心位置作为问题中的查询位置。通过这样做,我们可以更多地专注于评估每个模型对潜在假阳性和假阴性检测结果的合作基础能力。
Q2.在某个位置的参考物体后面接地(图2b):当卡韦的视野被附近检测到的大型物体遮挡时,该卡韦可能想要要求集中式LLM确定在遮挡的大型物体后面是否存在任何物体给定来自所有卡韦的融合感知信息。如果是这样,LLM预计将返回物体的位置,而提出请求的CAE可能需要更具防御性地驾驶或调整其规划。否则,LLM应该指示引用对象后面没有任何内容。我们使用每个检测结果框的中心位置作为这些问题中的查询位置。我们根据提出请求的卡韦和参考物体的相对姿态绘制一个扇形区域,并选择该区域中最近的地面真相物体作为答案。
Q3.以方向上的参考对象为基础(图2c):我们通过用参考方向关键字替换Q2的参考2D位置,进一步挑战LLM的语言和空间理解能力。我们首先获得作为参考对象的卡韦6个方向中每个方向上最接近的检测结果框。然后我们在第二季度遵循相同的方法,以获得相应部门区域中最近的地面真值框作为答案。
Q4. 显著物体识别(图 2d): 上述接地任务是自动驾驶流程中的中间任务。自动驾驶车辆更关键的能力包括识别计划未来轨迹附近的显著物体,以及调整未来规划以避免潜在碰撞。我们从未来 3 秒的地面实况轨迹中提取 6 个航点,作为问题中的未来参考航点。然后,我们最多会得到距离参考未来轨迹 10 米以内的 3 个最近的地面实况物体作为答案。
Q5. 规划(图 2e): 规划非常重要,因为自动驾驶车辆的最终目标是在复杂环境中安全导航,避免未来可能发生的任何碰撞。为了生成规划 QA,我们从每辆 CAV 的地面实况未来轨迹中提取了 6 个未来航点作为答案,这些航点在未来 3 秒内均匀分布。我们的 V2V-QA 规划任务比其他基于 NuScenes 3 的 LLM 驾驶相关工作更具挑战性,原因有以下几点。首先,我们在合作驾驶场景中支持多辆 CAV。LLM 模型需要根据提出问题的 CAV 提供不同的答案,而之前的工作只需要为单个自动驾驶车辆生成规划结果。其次,我们的 V2VQA 地面实况规划轨迹更加多样化。V2V-QA 包含城市和高速公路两种驾驶场景,而 NuScenes 3 仅包含城市驾驶场景。详细的数据集统计和比较见补充材料。
3.4 评估指标
我们沿用之前的研究成果 39, 43 来评估模型性能。对于接地问题(Q1、Q2、Q3)和显著物体识别问题(Q4),评价指标是 F1 分数、精确度和召回率。地面实况答案和模型输出包含对象的中心位置。如果地面实况答案与模型输出之间的中心距离小于阈值,则该输出被视为真阳性。我们将阈值设定为 4 米,这是车辆的典型长度。
对于规划问题(问题 5),评估指标是 L2 误差和碰撞率。地面实况答案和模型输出包含 6 个未来航点,因此我们计算这些航点的 L2 误差。在计算碰撞率时,我们假设每个 CAV 的边界框尺寸为长 4 米、宽 2 米、高 1.5 米。我们将每个 CAV 的边界框放置在模型输出的未来航点上,并计算这些未来帧中 CAV 边界框与每个地面实况对象注释边界框之间的 "联合交叉"(Intersection-over-Union,IOU)。如果 IOU 大于 0,则视为碰撞。
4 V2V-LLM
我们还针对这一基于 LLM 的协同驾驶问题提出了一个有竞争力的基准模型 V2VLLM,如图 3 所示。我们的模型是一种多模态 LLM(MLLM),它将每个 CAV 的单个感知特征作为视觉输入,将问题作为语言输入,并生成答案作为语言输出。
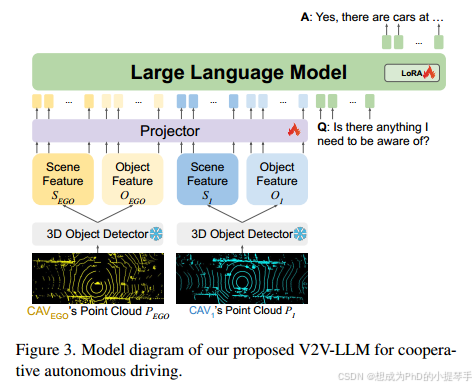
4.1 基于激光雷达的输入特征
为了提取感知输入特征,每个 CAV 都会对其各自的激光雷达点云应用三维物体检测模型: PEGO和P1。我们从三维物体检测模型中提取场景级特征图 SEGO 和 S1,并将三维物体检测结果转换为物体级特征向量 OEGO 和 O1。根据之前的 V2V4Real 53 和 V2X-Real 48,我们使用 PointPillars 20 作为三维物体检测器进行公平比较。
4.2. 基于激光雷达的多模态 LLM 模型架构
鉴于 LLaVA 25 在视觉问题解答任务中的卓越表现,我们利用 LLaVA 开发了 MLLM。不过,由于我们合作驾驶任务的感知特征是基于激光雷达的,而不是 LLaVA 25 使用的 RGB 图像,因此我们使用基于激光雷达的 3D 物体检测器作为点云特征编码器(如上一节所述),而不是 LLaVA 25 的 CLIP 36 图像特征编码器。然后,我们将得到的特征输入基于多层感知器的投影仪网络,进行从点云嵌入空间到语言嵌入空间的特征对齐。对齐后的感知特征就是 LLM 所消化的输入感知标记和问题中的输入语言标记。最后,LLM 会汇总来自所有 CAV 的感知信息,并根据问题返回答案。
**训练:**我们使用 8 个英伟达 A100-80GB GPU 训练模型。我们的 V2V-LLM 使用 LLaVA-v1.5-7b 25 的 Vicuna 7 作为 LLM 骨干。为了训练模型,我们通过加载预训练的 LLaVA-v1.5-7b 25 的检查点来初始化模型。我们冻结 LLM 和点云特征编码器,并对模型的投影仪和 LoRA 14 部分进行微调。在训练过程中,我们使用的批次大小为 32。采用 Adam 优化器进行训练,起始学习率为 2e-5,余弦学习率调度器的热身率为 3%。所有其他训练设置和超参数均沿用 LLaVA-v1.5-7b 25。
5 实验
5.1 基线方法
我们沿用 V2V4Real 53 和 V2X-Real 48,为我们提出的 V2V-QA 数据集建立基准,使用不同的融合方法对基线方法进行实验:无融合、早期融合、中期融合和我们提出的基线 LLM 融合(图 3)。基线方法也采用了与 V2V-LLM 相同的投影仪和 LLM 架构,但点云特征编码器不同,如图 4 所示。在 V2X-split 的一些驾驶序列中,如果有来自路边基础设施的点云,我们也将其作为感知输入,与使用 CAV 点云的方法相同。
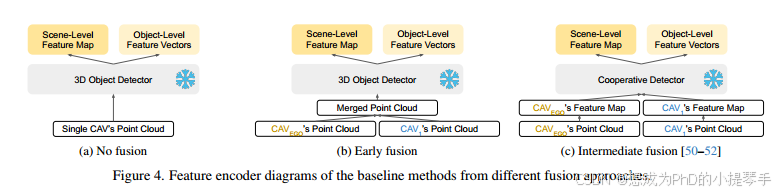
无融合: 只将单个 CAV 的激光雷达点云输入单个 3D 物体检测器,以提取场景级和物体级特征,作为 LLM 的视觉输入。预计这种方法的性能比所有其他合作感知方法都要差。
**早期融合:**首先合并来自两个 CAV 的激光雷达点云。然后将合并后的点云作为三维物体检测器的输入,提取视觉特征作为 LLM 的视觉输入。这种方法需要更高的通信成本,在现实世界的自动驾驶车辆上部署不太实用。
**中间融合:**先前的工作 CoBEVT 50、V2XViT 51 和 AttFuse 52提出了合作检测模型,通过注意机制合并来自多个 CAV 的特征图。这些方法所需的通信成本较低,但仍能实现良好的性能。在我们的基准中,我们从这些合作检测模型中提取特征作为 LLM 的输入标记。
LLM 融合: 我们将所提出的 V2V-LLM 归类为一种新型融合方法--LLM 融合,即让每个 CAV 执行单独的 3D 物体检测,以提取场景级特征图和物体级特征向量,并使用多模式 LLM 融合多个 CAV 的特征。这种方法与传统的后期融合方法有关,后者先进行单独的三维物体检测,然后通过非最大抑制(NMS)对结果进行聚合。我们的方法不使用 NMS,而是采用 LLM 来执行更多任务,而不仅仅是检测。
5.2 实验结果
5.2.1 基础
V2V-LLM 和基线方法在 V2V-QA 的 3 种接地问题上的性能见表 3。表 3 分别列出了 V2V-split 和 V2X-split。V2X-split 的结果不包括 CoBEVT 50,因为 V2X-Real 48 没有发布其 CoBEVT 50 基线模型。平均而言,V2V-LLM 在 V2V-split 中取得了相似的性能,而在 V2X-split 中则优于所有其他基线方法。这些结果表明,我们的 V2VLLM 在融合多个 CAV 的感知特征来回答接地问题方面具有良好的能力。
5.2.2. 著名物体识别
表 3 显示了显著物体识别任务(Q4)的成绩。表 3 显示了在显著物体识别任务(Q4)上的性能。在 V2V 分路和 V2X 分路中,我们提出的 V2V-LLM 性能优于所有其他方法。与上述接地任务相比,这项值得注意的物体识别任务需要更强的空间理解能力,以识别靠近计划中未来航点的物体。对于这样的任务,我们的 V2V-LLM 让多模态 LLM 同时执行感知特征融合和问题解答,取得了最佳效果。
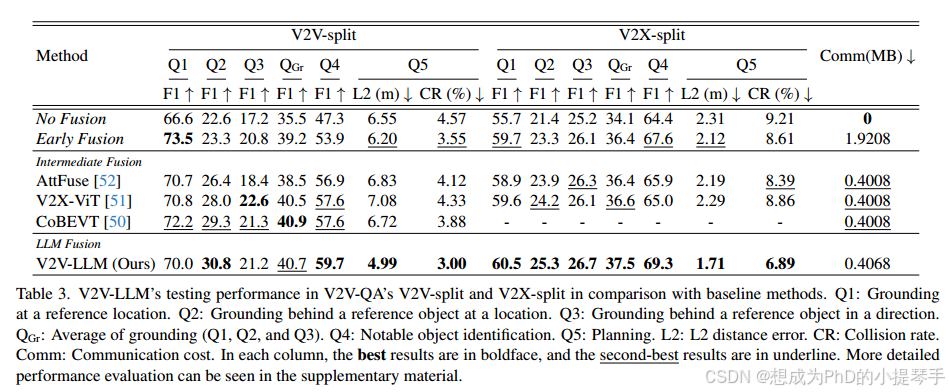
表 3. V2V-LLM 在 V2V-QA 的 V2V-split 和 V2X-split 测试中与基准方法的性能对比。Q1: 在参考位置接地。Q2: 在参考位置的参考物体后面接地。Q3:参考物体后方按方向接地。QGr: 接地(Q1、Q2 和 Q3)的平均值。Q4: 显著物体识别。Q5: 规划。L2: L2 距离误差。CR: 碰撞率Comm:通信 通信成本。每列中,最佳结果以黑体显示,次佳结果以下划线显示。更详细的性能评估见补充材料。
5.2.3. 规划
表 3 分别显示了 V2V 分路和 V2X 分路的规划任务(Q5)性能。表 3 分别显示了 V2V-split 和 V2X-split 的规划任务 (Q5) 的性能。我们提出的 V2VLLM 在这项对安全至关重要的任务中表现优于其他方法,它可以生成旨在避免潜在碰撞的未来轨迹。更多规划性能评估见补充材料。
5.2.4 通信成本和规模分析
在我们的集中式设置中,每个 CAV 在每个时间步向 LLM 计算节点发送一个场景级特征图(≤ 0.2MB)、一组单个物体检测结果参数(≤ 0.003MB)和一个问题(≤ 0.0002MB),并接收一个答案(≤ 0.0002MB)。如果有 Nv 个 CAV,每个 CAV 提出 Nq 个问题,则每个 CAV 的通信成本为 (0.2 + 0.003 + (0.0002 + 0.0002)Nq) = (0.203 + 0.0004Nq) MB,LLM 的成本为 (0.2 + 0.003 + (0.0002 + 0.0002)Nq)Nv = (0.203Nv + 0.0004NqNv) MB,如表 4 所示。4. 请注意,每个 CAV 在每个时间步只需向 LLM 计算节点发送一次相同的特征,因为 LLM 节点可以保存并重复使用这些特征,以便在同一时间步回答来自相同或不同 CAV 的多个问题。详细的缩放分析见补充材料。
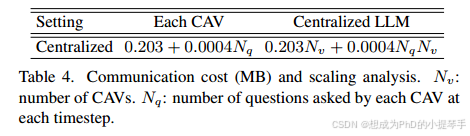
表 4. 通信成本(MB)和扩展分析。Nv:CAV 数量。Nq:每个 CAV 在每个时间步所提问题的数量。
5.2.5 结论
总体而言,V2V-LLM 在显著的物体识别和规划任务中取得了最佳效果,而这两项任务在自动驾驶应用中至关重要。V2V-LLM 在接地任务中还实现了有竞争力的结果。在通信成本方面,与其他中间融合基线方法相比,V2V-LLM 只增加了 1.5% 的通信成本。更详细的评估和分析见补充材料。
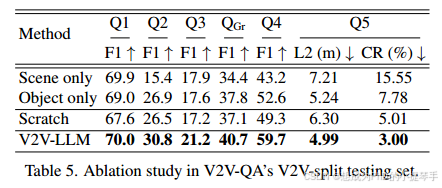
5.3 消融实验
输入特征: 我们对 V2VLLM 模型的变体进行了试验,将场景级特征图或物体级特征向量作为视觉输入。消融结果见表 5。5. 在所有质量保证任务中,这两种类型的特征都有助于提高最终性能。一般来说,纯对象级模型优于纯场景级模型。这意味着对象级特征更容易被 LLM 消化,这与之前使用 TOKEN 模型的研究结果一致39。
从零开始的培训:表 5 显示,从头开始训练的性能更差。表 5 显示,从头开始训练的性能更差,这意味着使用 LLaVA 的 VQA 任务进行预训练可以提高我们的 V2VLLM 在 V2V-QA 中的性能。更详细的消融结果见补充材料。
5.4 定量分析
图 5 显示了 V2V-LLM 的接地结果和 V2V-QA 测试集上的可视化地面实况。我们可以观察到,我们的 V2V-LLM 在 3 种类型的接地问题中都能根据所提供的参考信息找到对象。图 6 左侧显示了 V2V-LLM 的显著物体识别结果。V2V-LLM 展示了其在每个 CAV 的问题中指定的计划未来轨迹附近识别多个物体的能力。图 6 的右侧显示了 V2VLLM 的规划结果。我们的模型能够提出避免与附近物体发生潜在碰撞的未来轨迹。总体而言,在所有问题类型中,我们模型的输出结果都与地面实况的答案非常吻合,这表明我们的模型在合作式自动驾驶任务中具有很强的鲁棒性。

图 5. V2V-LLM 在 V2V-QA 测试集上的接地结果。洋红色 ◦:问题中的参考位置。黄色 +:模型输出位置。绿色 ◦:地面实况答案。
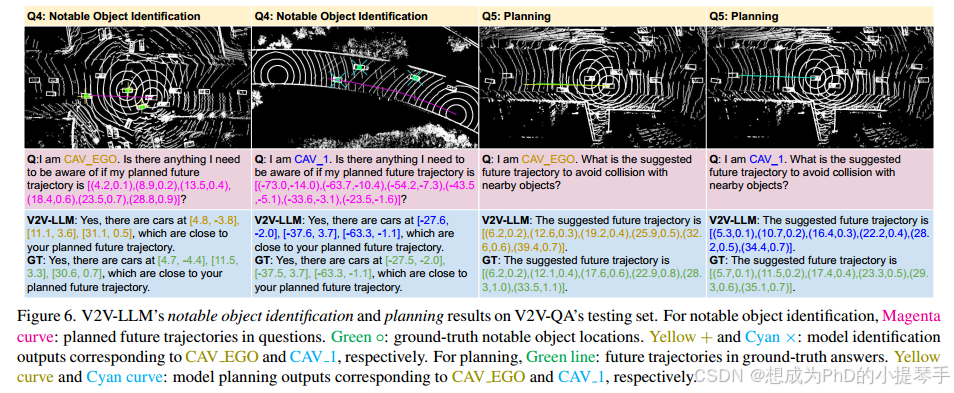
图 6. V2V-LLM 在 V2V-QA 测试集上的显著物体识别和规划结果。对于显著物体识别,洋红色曲线:问题中规划的未来轨迹。绿色 ◦:地面实况中的显著物体位置。黄色 + 和青色 ×:分别对应 CAV EGO 和 CAV 1 的模型识别输出。对于规划,绿线:地面实况答案中的未来轨迹。黄色曲线和青色曲线:分别对应 CAV EGO 和 CAV 1 的模型规划输出。
6 结论
在这项工作中,我们通过整合使用基于多模态 LLM 的方法,拓展了合作式自动驾驶的研究范围,旨在提高未来自动驾驶系统的安全性。我们提出了一个新的问题设置,并创建了一个新颖的 V2V-QA 数据集和基准,其中包括针对各种合作驾驶场景设计的接地、显著物体识别和规划问题解答任务。我们提出了一个基线模型 V2V-LLM,该模型可融合每辆 CAV 的单独感知信息,并执行视觉和语言理解,以回答来自任何 CAV 的与驾驶相关的问题。我们提出的 V2V-LLM 在显著的目标识别和规划任务中优于所有其他采用最先进合作感知算法的基线模型,并在接地任务中取得了具有竞争力的性能。这些实验结果表明,V2V-LLM 作为一种统一的多模式基础模型很有前途,它能有效地执行合作式自动驾驶的感知和规划任务。我们将公开发布我们的 V2V-QA 数据集和代码,以促进开源研究,并相信它将把合作驾驶研究带入下一个阶段。