区间问题是另⼀种⽐较经典的贪⼼问题。题⽬⾯对的对象是⼀个⼀个的区间,让我们在每个区间上做出取舍。
这种题⽬的解决⽅式⼀般就是按照区间的左端点或者是右端点排序,然后在排序之后的区间上,根据题⽬要求,制定出相应的贪⼼策略,进⽽得到最优解。
具体是根据左端点还是右端点排序?升序还是降序?⼀般是假设⼀种排序⽅式,并且制定贪⼼策略,当没有明显的反例时,就可以尝试去写代码。
P1803 凌乱的yyy / 线段覆盖 - 洛谷
按照区间左端点从⼩到⼤排序,当两个区间「重叠」的时候,我们必须要舍弃⼀个。为了能够「在移除某个区间后,保留更多的区间」,我们应该把「区间范围较⼤」的区间移除。
因此以第⼀个区间为基准,遍历所有的区间:
- 如果重叠,选择「最⼩的右端点」作为新的基准;
- 如果不重叠,那么我们就能多选⼀个区间,以「新区间为基准」继续向后遍历。
可以⽤「交换论证法」证明我们的贪⼼策略是最优解:
在从前往后扫描的过程中,当贪⼼解和最优解第⼀次出现不同决策时,关于两个区间a,b(其中a在左,b在右)的取舍,有下⾯两种情况:
- a, b两个区间不重叠:
- 贪⼼解会将a 区间保留,然后以b 区间为基准,继续向后对⽐别的区间;
- 最优解的选择有下⾯⼏种情况:
a. 舍弃⼀个区间,那么必定不如贪⼼解,⽭盾。
b. 以a区间为基准,向后对⽐。那更夸张了,我们已经按照区间左端点从⼩到⼤排好序了,如果a,b不重叠,那么a与后⾯的所有区间都不重叠,⽤a作为基准没有⼀点意义。还会选出与b重叠的区间。
综上,如果「不重叠」的话,贪⼼解和最优解的决策应该是「⼀致」的。
- a, b 两个区间重叠,那么⽆论什么解,都需要「舍弃」⼀个区间:
- 贪⼼解会保留两者「右端点较⼩」的区间,舍弃「右端点较⼤」的区间;
- 最优解的选择就是,保留「右端点较⼤」的区间,舍弃「右端点较⼩」的区间。
如果第⼆种决策能在此基础上得到最优解,那么我们把「右端点较⼤」区间换成「右端点较⼩」的区间是不受影响的。
因为「较⼤区间」都和后续选择的区间「没有重叠」,这个较⼩的区间也必定「没有重叠」。因此,最优解可以调整成贪⼼解。
c++
#include <bits/stdc++.h>
using namespace std;
const int N = 1e6 + 10;
int n;
struct node
{
int l, r;
}a[N];
bool cmp(node& x, node& y)
{
return x.l < y.l;
}
int main()
{
ios::sync_with_stdio(false);
cin.tie(0);
cin >> n;
for (int i = 1; i <= n; i++) cin >> a[i].l >> a[i].r;
sort(a+1, a+1+n, cmp);
int ret = 1;
int r = a[1].r; //以第一个区间为基准
for (int i = 2; i <= n; i++)
{
int left = a[i].l, right = a[i].r;
if (left < r) //有重叠
{
r = min(r, right);
}
else
{
ret++;
r = right;
}
}
cout << ret << endl;
return 0;
}UVA1193 Radar Installation - 洛谷
如图所⽰,当⼀个岛屿的「坐标」已知,其实可以计算出:当雷达放在x轴的「哪段区间」时,可以覆盖到这个岛屿
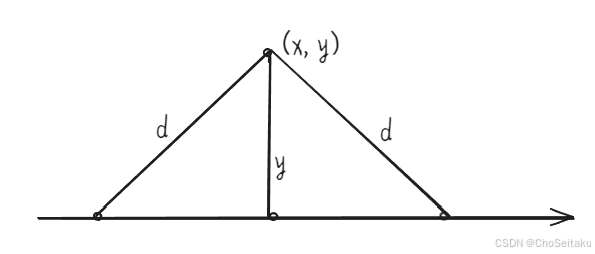
根据「勾股定理」得:ax的⻓度为 l = d 2 − y 2 l=\sqrt{ d^{2}-y^2 } l=d2−y2 ,那么雷达所处的范围就是 x − l , x + l x-l,x+l x−l,x+l。因此,针对每⼀个岛屿,我们都可以算出⼀个「能够覆盖它的区间」。
原问题就变成给定⼀些区间,所有互相重叠的区间⼀共有多少组。
按照区间「左端点从⼩到⼤」排序,当两个区间「重叠」的时候,为了后⾯能够「尽可能多的选出互相重叠的区间」,我们应该把「区间范围较⼤」的区间移除,因为选择较⼤区间会造成选出来的区间「不是互相重叠」的。
因此以第⼀个区间为基准,遍历所有的区间:
- 如果重叠,选择「最⼩的右端点」作为新的基准;
- 如果不重叠,那么我们就能多选⼀个区间,以「新区间为基准」继续向后遍历。
可以⽤「反证法」证明,所有区间按照按照「左端点」排序之后,「互相重叠的区间」都是「相邻」的:
假设所有区间按照左端点排序之后,存在互相重叠的区间,它们是不相邻的。也就是存在a,b,c,d四个区间,其中a,b,d互相重叠,但是a,b,c与它们三个不是互相重叠。
设a, b, d区间重叠部分的范围是[x, y],那么c 的位置有两种情况: - c 在
[x, y]的左侧,与实际不符:
因为如果c在左侧,⼜要与a,b不是互相重叠,那么c的右端点必须要⼩于b的左端点,那就与所有线段按照左端点排序不符; - c 在
[x, y]的右侧,也与实际不符:
因为如果c在右侧,⼜要与a,b不是互相重叠,那么c的左端点必须要⼤于a,b的右端点的最⼩值;⼜因为d与a,b互相重叠,d的左端点就要⼩于a,b的右端点的最⼩值,与所有区间按照左端点排序不符。
综上所述,所有区间按照按照「左端点」排序之后,「互相重叠的区间」都是「相邻」的
c++
#include <bits/stdc++.h>
using namespace std;
const int N = 1010;
int n;
double d;
struct node
{
double l, r;
}a[N];
bool cmp(node& x, node& y)
{
return x.l < y.l;
}
int main()
{
int cnt = 0;
while (cin >> n >> d, n && d)
{
cnt++;
bool flg = false;
for (int i = 1; i <= n; i++)
{
double x, y; cin >> x >> y;
if (y > d) flg = true;
double l = sqrt(d * d - y * y);
a[i].l = x - l, a[i].r = x + l;
}
cout << "Case " << cnt << ": ";
if (flg) cout << -1 << endl;
else
{
sort(a+1, a+n+1, cmp);
int ret = 1;
double r = a[1].r;
for (int i = 2; i <= n; i++)
{
double left = a[i].l, right = a[i].r;
if (left <= r)
{
r = min(r, right);
}
else
{
ret++;
r = right;
}
}
cout << ret << endl;
}
}
return 0;
}P2887 USACO07NOV Sunscreen G - 洛谷
思考具体解法,从下⾯的情况中,筛选出没有特别明显的反例的组合:
- 区间按照左端点从⼩到⼤+防晒霜从⼩到⼤(优先选⼩);
- 区间按照左端点从⼩到⼤+防晒霜从⼤到⼩(优先选⼤);
- 区间按照左端点从⼤到⼩+防晒霜从⼩到⼤(优先选⼩);
- 区间按照左端点从⼤到⼩+防晒霜从⼤到⼩(优先选⼤);
- 区间按照右端点从⼩到⼤+防晒霜从⼩到⼤(优先选⼩);
- 区间按照右端点从⼩到⼤+防晒霜从⼤到⼩(优先选⼤)。
- 区间按照右端点从⼤到⼩+防晒霜从⼩到⼤(优先选⼩);
- 区间按照右端点从⼤到⼩+防晒霜从⼤到⼩(优先选⼤)。
虽然看似很多,但是很容易在错误的策略中举出「反例」。
- 区间按照左端点从小到大,优先选较小的点:
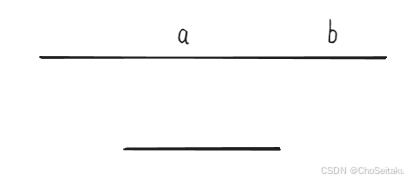
第一个区间选了a之后,b这个点就没办法分配了
实际上应该把a给第二个区间,b给第一个区间
- 区间按照左端点从小到大,优先选较大的点:
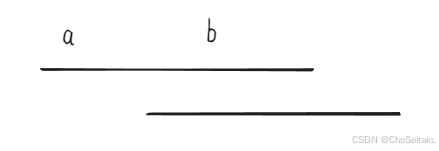
第一个区间选了b之后,a这个点就没办法分配了
实际上应该把b给第二个区间,a给第一个区间
- 区间按左端点从大到小,优先选较小的点:

第一个区间选了a之后,b这个点就没办法分配了
实际上应该把a给第二个区间,b给第一个区间
- 区间按左端点从大到小,优先选较大的点:
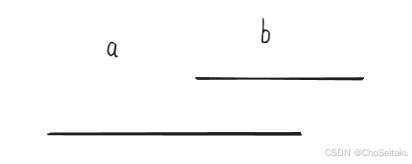
较小的点能够更好地被后面的区间选择
- 区间按右端点从小到大,优先选较小的点:
较大的点能够更好地被后面的区间选择 - 区间按照右端点从小到大,优先选较大的点:

第一个区间选了b之后,a这个点就没办法分配了
实际上应该把b给第二个区间,a给第一个区间
- 区间按右端点从大到小,优先选较小的点:
把a给了第一个区间以后,b就没办法分配了
实际上应该把b给第一个区间,a给第二个区间
- 区间按右端点从大到小,优先选较大的点:
第一个区间选了b之后,a这个点就没办法分配了
实际上应该把b给第二个区间,a给第一个区间
综上所述,有两种组合没有明显的反例,分别是:
- 区间按照「左端点从⼤到⼩」排序,防晒霜从⼤到⼩排序,「优先选择较⼤」的防晒霜;
- 区间按照「右端点从⼩到⼤」排序,防晒霜从⼩到⼤排序,「优先选择较⼩」的防晒霜。
实际上两种情况都是正确的,我们取其⼀证明⼀下,另⼀种证明⽅式类似。
可以⽤「交换论证法」证明⽅式⼆的正确性:
从前往后依次⽐较「贪⼼解」和「最优解」针对每⼀个区间的决策,当找到第⼀个区间,它们的「分配决策不同」时:设贪⼼解⽤的是a防晒霜,最优解⽤的是b防晒霜,因为贪⼼解选的是最⼩的,所以有 a ≤ b a \le b a≤b。
此时关于a 防晒霜的使⽤情况,可以分以下⼏种情况:
- a防晒霜在「最优解中没有使⽤」,那么我们可以直接⽤a防晒霜替换b防晒霜,此时最优解的「最优性」并没有损失,那么贪⼼解就和最优解决策⼀致;
- a防晒霜在「最优解的后续决策中使⽤了」,设b使⽤的区间是 x b , y b x_{b},y_{b} xb,yb,a使⽤的区间是 x a , y a x_{a},y_{a} xa,ya:
易得:
x b ≤ b ≤ y b , x a ≤ a ≤ y a x_{b} \le b \le y_{b}, x_{a} \le a \le y_{a} xb≤b≤yb,xa≤a≤ya
因为我们是按照右端点从⼩到⼤排序的,所以 y a ≥ y b y_{a} \ge y_{b} ya≥yb;
综上:
x a ≤ a ≤ b ≤ y b ≤ y a x_{a} \le a \le b \le y_{b} \le y_{a} xa≤a≤b≤yb≤ya
所以b也可以作⽤于「a作⽤的区间」,也就是在最优解中「a,b可以互换」,进⽽就转换成贪⼼解。
因此,针对每⼀个位置,我们都可以把最优解在「不失去其最优性的前提下」,转化成「贪⼼解」
c++
#include <bits/stdc++.h>
using namespace std;
const int N = 2510;
int n, m;
struct node
{
int x;
int y;
}a[N], b[N];
bool cmp(node& x, node& y)
{
return x.x > y.x;
}
int main()
{
cin >> n >> m;
for (int i = 1; i <= n; i++) cin >> a[i].x >> a[i].y;
for (int i = 1; i <= m; i++) cin >> b[i].x >> b[i].y;
sort(a+1, a+1+n, cmp); //按左端点从大到小排序
sort(b+1, b+1+m, cmp); //按阳光强度从大到小排序
int ret = 0;
for (int i = 1; i <= n; i++)
{
int l = a[i].x, r = a[i].y;
for (int j = 1; j <= m; j++)
{
int w = b[j].x, &cnt = b[j].y;
if (cnt == 0) continue;
if (w < l) break;
if (w > r) continue;
ret++;
cnt--;
break;
}
}
cout << ret << endl;
return 0;
}P2859 USACO06FEB Stall Reservations S - 洛谷
按照「起始时间」对所有奶⽜「从⼩到⼤」排序,然后「从前往后」依次安排每⼀头奶⽜,设这头奶⽜的产奶的时间区间是[a, b] :
- 在已经有⽜的所有⽜棚⾥,如果「结束时间⼩于a」,就可以把这头奶⽜放在这个⽜棚⾥⾯;如果有很多符合要求的,可以随便找⼀个。因为我们是按照起始时间从⼩到⼤排序,只要这些⽜棚都符合要求,对于后⾯的奶⽜⽽⾔也都符合要求。不妨找结束时间最早的,⽅便判断。
- 如果所有已经有⽜的⽜棚的「结束时间都⼤于a 」,那么这头⽜只能⾃⼰单独开⼀个⽜棚。
这个贪⼼策略是⽐较符合我们「常识」的,尽量优的安排每⼀头⽜
c++
#include <bits/stdc++.h>
using namespace std;
const int N = 5e4 + 10;
int n;
struct node
{
int x; //起始时间 / 结束时间
int y; //终止时间 / 牛棚编号
int z; //排序之前的编号
bool operator<(const node& a) const
{
return x > a.x;
}
}a[N];
int ret[N]; //存最终结果
bool cmp(node& x, node& y)
{
return x.x < y.x;
}
int main()
{
cin >> n;
for (int i = 1; i <= n; i++)
{
cin >> a[i].x >> a[i].y;
a[i].z = i;
}
sort(a+1, a+1+n, cmp);
int num = 1;
priority_queue<node> heap;
ret[a[1].z] = 1;
heap.push({a[1].y, 1});
for (int i = 2; i <= n; i++)
{
int l = a[i].x, r = a[i].y;
if (l <= heap.top().x) //无法放在已经分配的牛棚里
{
num++;
ret[a[i].z] = num;
heap.push({r, num});
}
else
{
node t = heap.top(); heap.pop();
ret[a[i].z] = t.y;
heap.push({r, t.y});
}
}
cout << num << endl;
for (int i = 1; i <= n; i++) cout << ret[i] << endl;
return 0;
}