循环神经网络在学习过程中的主要问题是由于梯度消失或爆炸问题,很难建模长时间间隔(Long Range)的状态之间的依赖关系。
本文我们来学习长程依赖问题及其对应的改进方案,在这部分知识的学习过程中,我建议大家着重理解,对于数学公式的推导,可以辅助我们理解即可,当然有兴趣可以研究的更深一些。
一、梯度消失或爆炸问题的产生原理
在 BPTT 算法中,误差项公式为:

将上述公式展开得到(根据求导链式法则):
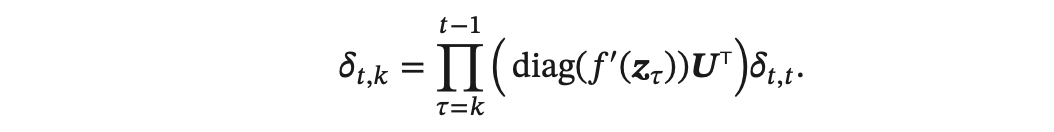
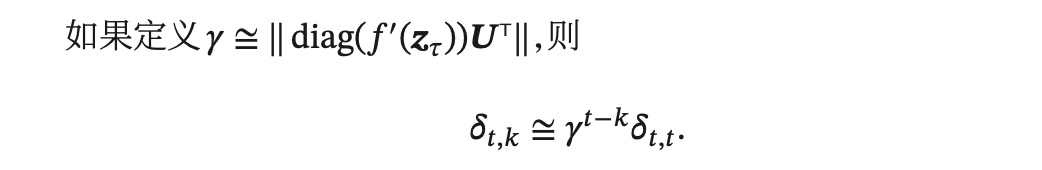
若𝛾 > 1,当𝑡−𝑘 → ∞时,𝛾𝑡−𝑘 → ∞。当间隔𝑡−𝑘比较大时,梯度也变得很 大,会造成系统不稳定,称为梯度爆炸问题(Gradient Exploding Problem)。
相反,若𝛾 < 1,当𝑡 − 𝑘 → ∞时,𝛾𝑡−𝑘 → 0。当间隔𝑡 − 𝑘比较大时,梯 度也变得非常小,会出现和深层前馈神经网络类似的梯度消失问题(Vanishing Gradient Problem)。
上面提到的间隔t-k,可以理解成是指第 𝑡 时刻的损失对第 𝑘 时刻隐藏神经层的净输入 𝒛𝑘 的导数的层数。
因此需要注意的是,在循环神经网络中的梯度消失不是说 𝜕L𝑡/𝜕𝑼 的梯度消失了,而是 𝜕L𝑡/𝜕𝒉𝑘 的梯度消失了(当间隔 𝑡 − 𝑘 比较大时)。也就是说,参数 𝑼 的更新主要靠当前时刻 𝑡 的几个相邻状态 𝒉𝑘 来更新,长距离的状态对参数 𝑼 没 有影响。
由于循环神经网络经常使用非线性激活函数为 Logistic 函数或 Tanh 函数作 为非线性激活函数,其导数值都小于 1,并且权重矩阵 ‖𝑼‖ 也不会太大,因此如果时间间隔 𝑡 − 𝑘 过大,𝛿𝑡,𝑘 会趋向于 0,因而经常会出现梯度消失问题。
虽然简单循环网络理论上可以建立长时间间隔的状态之间的依赖关系,但是由于梯度爆炸或消失问题,实际上只能学习到短期的依赖关系。
这样,如果时刻 𝑡 的输出 𝑦𝑡 依赖于时刻 𝑘 的输入 𝒙𝑘,当间隔 𝑡 − 𝑘 比较大时,简单神经网络很 难建模这种长距离的依赖关系,称为长程依赖问题(Long-Term Dependencies Problem)。
二、进一步理解长程依赖问题
循环神经网络(RNN)在处理长序列数据时面临长程依赖(Long-Term Dependencies)问题 ,即模型难以捕捉时间步相距较远的信息关联。这一问题的本质源于RNN的梯度传播机制和参数学习过程。
(一)长程依赖问题的本质
1. 什么是长程依赖?
-
定义 :在序列任务中,当前时刻的输出可能依赖于遥远过去时刻的输入 。
示例:-
句子补全:"天空布满乌云,远处传来雷声,突然......(预测:下起了雨)"。
-
模型需记住"乌云"和"雷声"(早期时间步)的信息,才能正确预测"雨"。
-
2. RNN的局限性
- 短期记忆特性 :普通RNN(如简单循环单元)的隐藏状态通过时间步递归更新,但梯度在反向传播时会发生指数级衰减或爆炸,导致远距离时间步的信息无法有效传递。
(二)数学视角:梯度传播的脆弱性
1. 梯度消失与爆炸的根源
考虑RNN的隐藏状态更新公式:
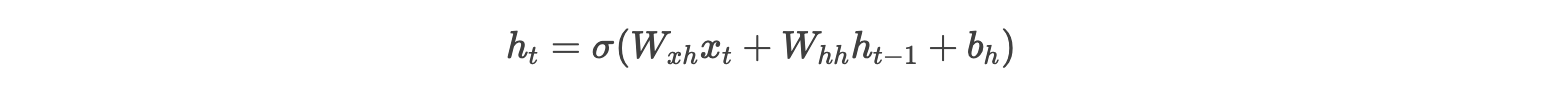
假设损失函数对 ht 的梯度为 ∂L/∂ht,则损失对初始隐藏状态 h0 的梯度为:
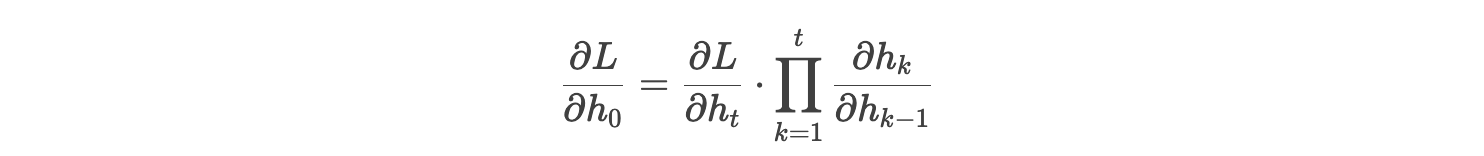
其中,每个Jacobian矩阵 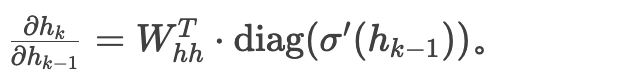
-
梯度消失:若矩阵的最大特征值 ∣λ∣<1,连乘导致梯度趋近于零。
-
梯度爆炸:若 ∣λ∣>1,梯度迅速增大,引发数值不稳定。
-
关于矩阵的特征值,可以翻看之前的博文来理解机器学习 - 初学者需要弄懂的一些线性代数的概念_矩阵线性相关与其子式相关区别-CSDN博客
请大家注意,以上的推导,和第一部分介绍的梯度小时或爆炸问题的产生原理,是一致的,只是数学推导的形式不同,但是容易理解一些。
2. 具体示例
假设使用tanh激活函数(导数值最大为1),权重矩阵 Whh 的特征值为0.9:
-
经过50个时间步后,梯度衰减为 0.9^50≈0.005,几乎消失。
-
若特征值为1.1,梯度爆炸为 1.150≈117,远超合理范围。
(三)长程依赖对参数学习的影响
1. 参数更新失效
-
梯度消失:远离当前时间步的参数(如 Whh)几乎无法更新,导致模型无法学习早期时间步的关键模式。
-
梯度爆炸:参数更新步长过大,跳过最优解,甚至导致数值溢出(NaN)。
2. 实际任务中的表现
-
文本生成:模型可能重复局部模式(如连续输出相同词语),无法保持长段落逻辑一致。
-
时间序列预测:对早期关键趋势(如经济周期拐点)的响应延迟或遗漏。
-
机器翻译:长句子中主语与谓语的跨多词依赖难以捕捉,导致语法错误。
三、长程依赖问题的改进方案
为了避免梯度爆炸或消失问题,一种最直接的方式就是选取合适的参数,同时使用非饱和的激活函数,尽量使得 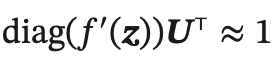 ,这种方式需要足够的人 工调参经验,限制了模型的广泛应用。比较有效的方式是通过改进模型或优化方法来缓解循环网络的梯度爆炸和梯度消失问题。
,这种方式需要足够的人 工调参经验,限制了模型的广泛应用。比较有效的方式是通过改进模型或优化方法来缓解循环网络的梯度爆炸和梯度消失问题。
(一)对于梯度爆炸
一般而言,循环网络的梯度爆炸问题比较容易解决,一般通过权重衰减或梯度截断来避免。
权重衰减是通过给参数增加 l1 或 l2 范数的正则化项来限制参数的取值范围,从而使得 𝛾 ≤ 1。梯度截断是另一种有效的启发式方法,当梯度的模大于一定阈值时,就将它截断成为一个较小的数。
(二)对于梯度消失
梯度消失是循环网络的主要问题.除了使用一些优化技巧外,更有效 的方式就是改变模型,比如让𝑼=𝑰,同时令 𝜕𝒉𝑡/𝜕𝒉𝑡−1 =𝑰为单位矩阵,即
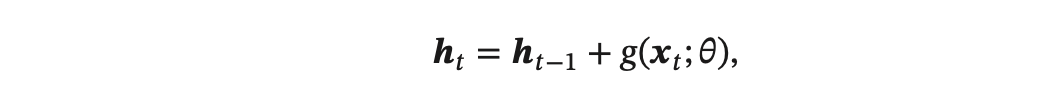
其中 𝑔(⋅) 是一个非线性函数,𝜃 为参数。
上述公式中,
𝒉𝑡 和 𝒉𝑡−1 之间为线性依赖关系,且权重系数为 1,这样就不存在梯度爆炸或消失问题。
但是,这种改变也丢失了神经元在反馈边上的非线性激活的性质,因此也降低了模型的表示能力。
为了避免这个缺点,我们可以采用一种更加有效的改进策略:
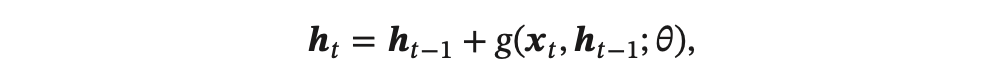
这样 𝒉𝑡 和 𝒉𝑡−1 之间为既有线性关系,也有非线性关系,并且可以缓解梯度消失问题。
但这种改进依然存在两个问题:

为了解决这两个问题,可以通过引入门控机制来进一步改进模型。后面的博文中,我们会学习各种基于门控的循环神经网络:长短期记忆网络LSTM及其各种变体,和门控循环单元网络GRU。
四、从结构设计到训练技巧解决长程依赖问题
1. 改进网络结构
(1) 门控机制(LSTM/GRU)(上面提到的 引入门控机制来进一步改进模型**)**
-
核心思想:通过门控单元(输入门、遗忘门、输出门)控制信息的保留与遗忘。
-
LSTM的隐藏状态更新:
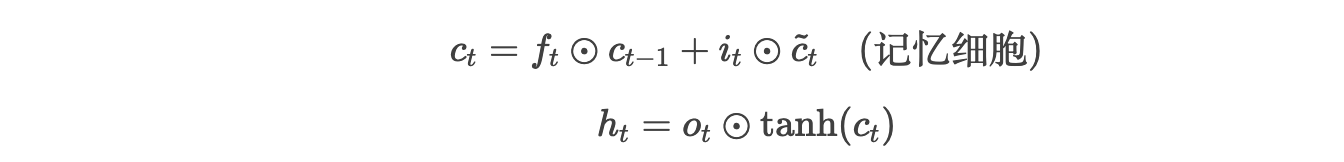
-
遗忘门 ft 决定保留多少旧记忆,输入门 it 控制新信息流入。
-
优势:梯度通过记忆细胞 ctct 直接传递,避免连乘权重矩阵(图1)。
-
(2) 跳跃连接(Skip Connections)
-
残差网络(ResNet)思想:添加跨时间步的直连路径,使梯度可绕过非线性变换。
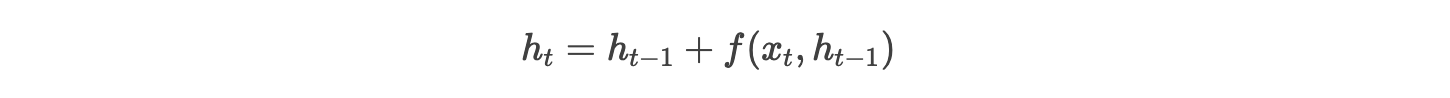
- 梯度传播路径缩短,缓解衰减。
2. 优化训练过程
(1) 梯度裁剪(Gradient Clipping)
限制梯度最大值,防止爆炸:

(2) 截断BPTT(Truncated BPTT)
仅反向传播有限时间步(如10步),降低长程梯度计算负担。
(3) 初始化策略
使用正交初始化(Orthogonal Initialization)权重矩阵,保持特征值模长为1,减缓梯度衰减。
3. 替代架构
-
Transformer:完全抛弃循环结构,通过自注意力机制直接建模任意距离的依赖。
-
TCN(时序卷积网络):使用膨胀卷积扩大感受野,捕捉长程模式。
五、实例对比:普通RNN vs LSTM
任务:生成一段连贯的故事(依赖长期上下文)
-
普通RNN:
-
生成:"男孩走进森林,树木高大,阳光透过枝叶,鸟儿在唱歌,树叶沙沙作响,男孩......树叶沙沙作响,树叶沙沙作响......"
-
问题:无法记住"男孩"这一主语,陷入局部重复。
-
-
LSTM:
-
生成:"男孩走进森林,树木高大,阳光透过枝叶,鸟儿在唱歌。他忽然听到远处传来狼嚎,于是加快脚步,最终找到一条小溪......"
-
优势:通过遗忘门保留"男孩"信息,输入门引入新事件(狼嚎、小溪)。
-
六、总结
长程依赖问题的本质是梯度传播的指数衰减/爆炸导致模型难以学习远距离关联。通过门控机制(LSTM/GRU)、结构优化(残差连接)和训练技巧(梯度裁剪)可显著缓解这一问题。理解这一机制有助于:
-
模型选择:根据任务序列长度选择RNN变体或Transformer。
-
调参指导:合理设置梯度裁剪阈值、初始化方法。
-
问题诊断:当模型无法捕捉长期模式时,优先排查梯度传播路径。
最终目标是让模型既能捕捉局部细节,又能维护全局一致性,从而提升对复杂序列数据的建模能力。