从MySQL快速上手大数据Hive
Hive简介
hive是基于Hadoop构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式(DML)来分析存储在Hadoop分布式文件系统中的数据: 可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能;可以将SQL语句转换为MapReduce任务运行,通过自己的SQL查询分析需要的内容,这套SQL简称Hive SQL,使不熟悉mapreduce的用户可以很方便地利用SQL语言查询、汇总和分析数据。
hive不适合用于联机(online)事务处理,也不提供实时查询功能。
它最适合应用在基于大量不可变数据的批处理作业。
下图展示了大数据中数据查询的整个过程
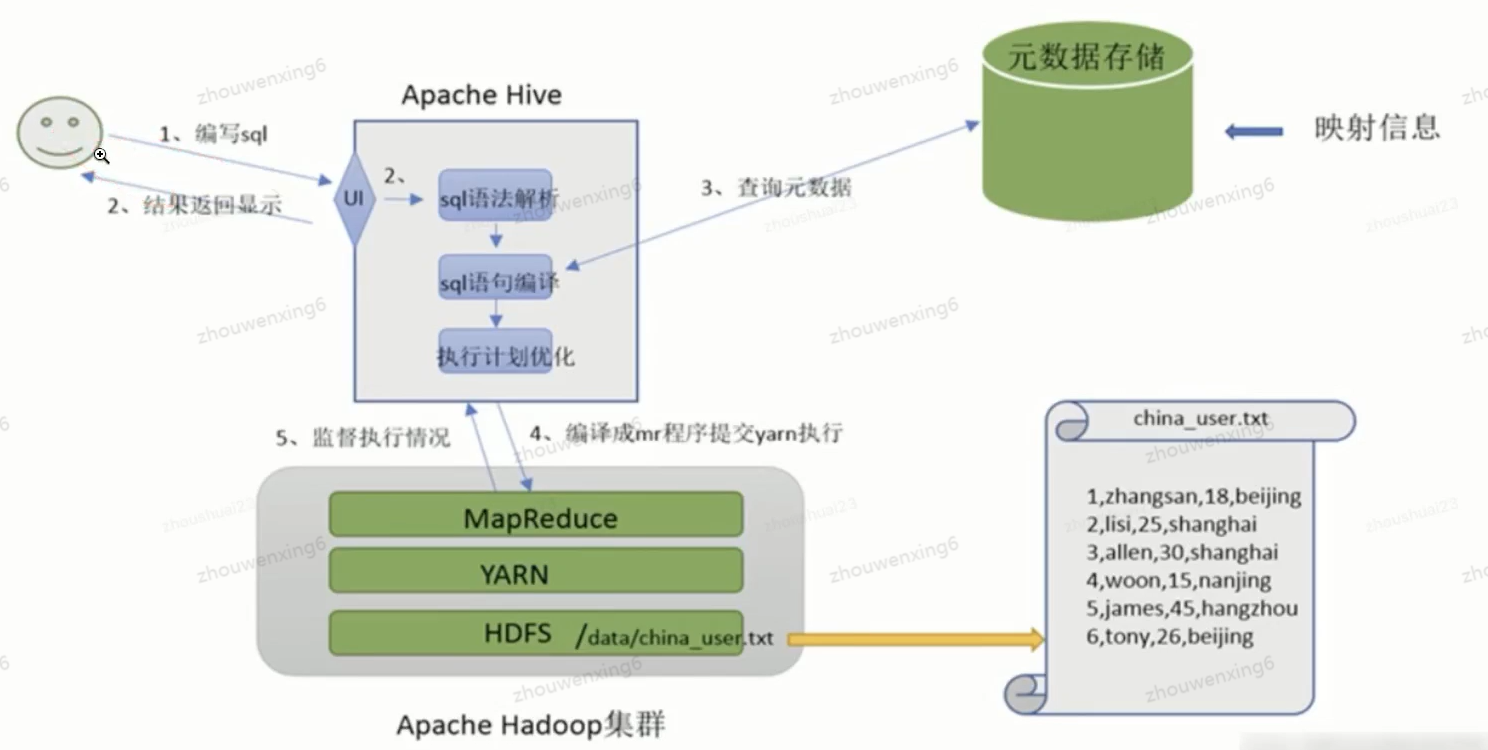
MapReduce原理
Map就是映射,负责数据过滤分割,将原始数据转化为键值对;Reduce是合并,将具有相同key值的value进行处理后再输出新的键值对,最后存储到HDFS。为了让Reduce可以并行处理Map的结果,必须对Map的输出进行一定的排序与分割,然后再交给对应的Reduce,而这个将Map输出进行进一步整理并交给Reduce的过程就是Shuffle。整个MR的大致过程如下:

Hive使用
Hive表类型
内表:建表时不需要指定location。删除内表时,对应的HDFS文件一并删除。非分区表所有文件放在表location下,非压缩表。
外表:外表用EXTERNAL关键字来创建。外表需要指定location。删除外表时,不删除对应的HDFS文件。数据以ORC文件存储,用SNAPPY算法压缩


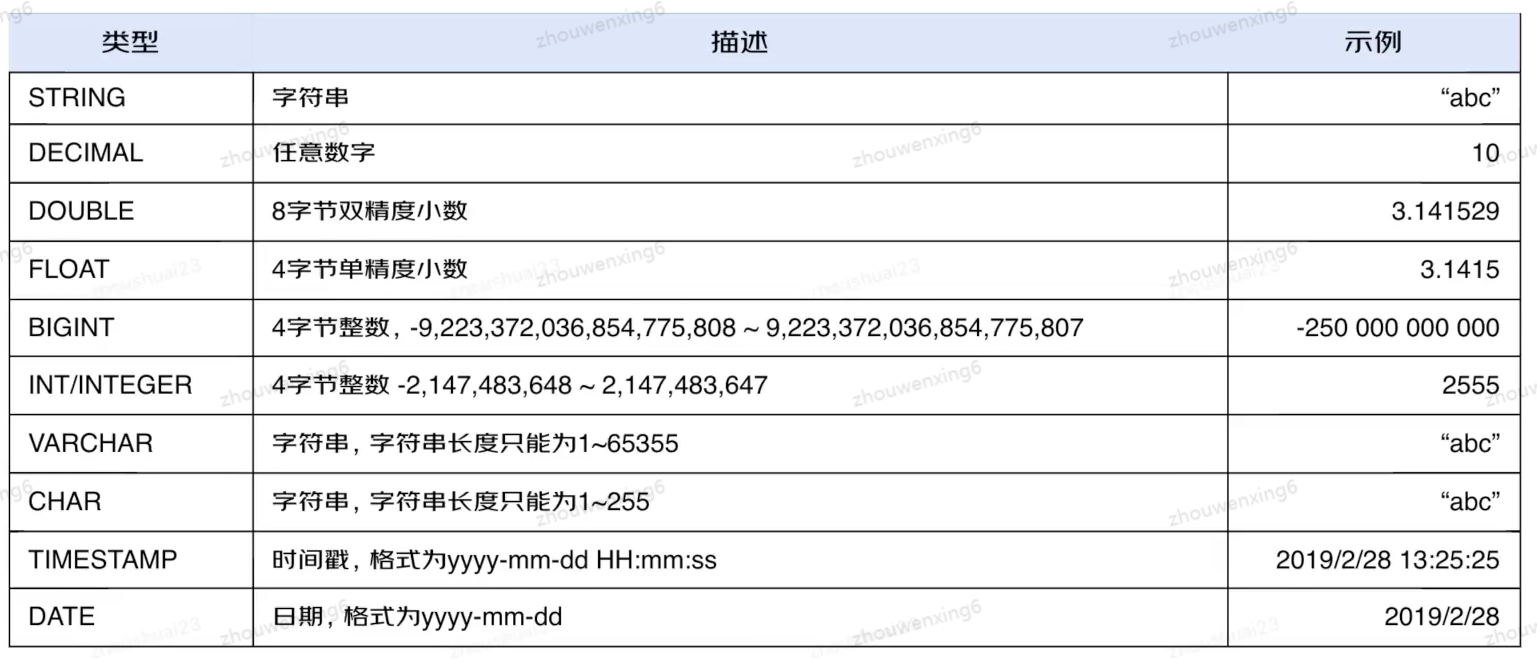
Hive常见数据类型
与Mysql基本保持一致。
使用CAST函数进行类型转换。
sql
# sku_id是varchar
# 但需要转成INT为了方便后面做数值运算
# 此时就需要使用到CAST函数
SELECT CAST(sku id AS INT) FROM sku sale listHive常用函数
主要跟Mysql中常用函数一致
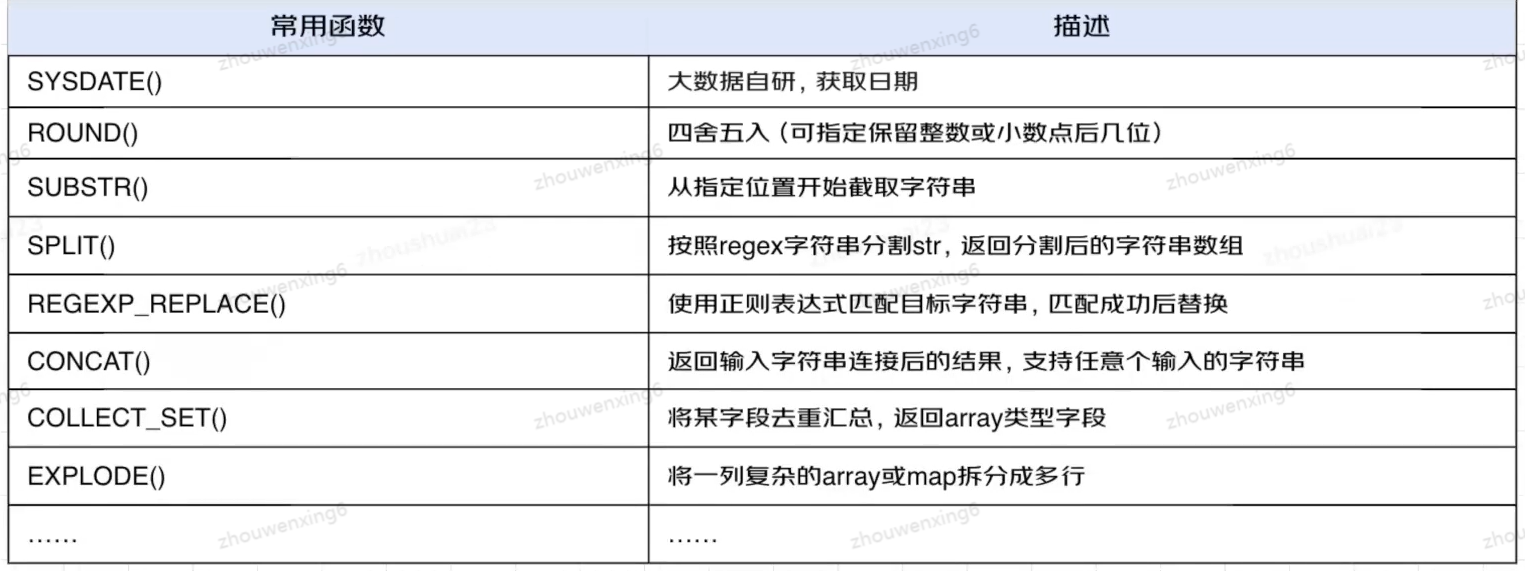
SYSDATE()函数是自研函数,用法如下
sql
sysdate()
# 获取当天数据
SELECT sysdate()
-- 结果:2025-03-02
# 获取昨天数据
SELECT sysdate(-1)
-- 结果:2025-03-01
# 获取明天数据
SELECT sysdate(1)
-- 结果:2025-03-03其他函数举例如下,都跟Mysql中用法一致
sql
round()
SELECT round(6.28); -- 结果:6
SELECT round(6.58); -- 结果:7
SELECT round(6.58410834,2); -- 结果:6.58
SELECT round(6.58470834,3); -- 结果:6.585
SELECT round(6.5,3); -- 结果:6.500
sql
substr() 字符串截取
SELECT substr('字符串'从哪开始截[,截几个])
SELECT substr('abcdefghijk',3); --结果:cdefghijk
SELECT substr('abcdefghijk',3,2); -- 结果:cd
SELECT substr('abcdefghijk',-3); -- 结果:ijk
SELECT substr('abcdefghijk',-3,2); --结果:ij
sql
split() 字符串切割
SELECT
split('中国,美国,英国,法国',',') name #以,来切割'中国,美国,英国,法国'字符串
FROM test3;
-- 结果:[中国"'美国''英国''法国']
SELECT
split('中国,美国,英国,法国'',')[0]name
FROM test3;
-- 结果:中国
SELECT
split('中国,美国,英国,法国...')[1] name
FROM test3;
-- 结果:美国
sql
concat() 字符串拼接
SELECT concat("123","aaa"); -- 结果:123aaa
SELECT concat("123""aaa",'张三'); --结果:123aaa张三
sql
collect set()/collect_... 行转列 列转行
name
tom
marry
peter
tom
tom
marry
SELECT collect_set(name) FROM test2;
-- 结果:["tom","marry","peter"]
SELECT collect_list(name) FROM test2;
-- 结果:["tom","marry","peter","tom","tom","marry"]HiveDML操作
Hive提供了类SQL的数据操作语言DML,用于操作数据表中的数据,例如数据的加载、查询和插入等操作。
sql
插入数据 语法如下:
INSERT INTO table name [PARTITION(partition column = partition value)]
VALUES(value1,value2,...);
--示例:直接插入固定数据:
INSERT INTO employees VALUES(1001,'John Doe',!5000);
--示例:插入查询结果数据:
INSERT INTO table_name [PARTITION(partition_column = partition_value)]
SELECT column_list FROM source_table WHERE condition;
sql
更新数据
在默认情况下,Hive不支持使用UPDATE更新操作。可以用以下方式。
--示例1:将original_table表中数据更新
CREATE TABLE temp_table AS SELECT * FROM original_table;
DROP TABLE original_table;
ALTER TABLE temp_table RENAME To original_table;
--示例2:
INSERT OVERWFITE TABLE temp_table SELECT * FROM original_table;
SQL
删除数据
Hive不支持使用DELETE语句来删除数据,如果您希望删除整个分区及其所有数据,可以使用 ALTER TABLE 命令
--示例: 删除分区数据
ALTER TABLE employees DROP PARTITION(department='IT');
--示例:删除整表数据
DROP TABLE employees;
SQL
查询数据 与MySQL中一致
-- 检索所有列
SELECT * FROM employees;
-- 检索特定列
SELECT erp,salary,age FROM employees;
-- 检索薪资大于5000的员工
SELECT erp,salary,age FROM employees WHERE salary > 5000
-- 汇总薪资大于5000的员工的总薪资
SELECT SUM(salary) FROM employees WHERE salary > 5000;
sql
关联查询数据 与MySQL中一致
-- 内连接:返回两表id能匹配上的记录
SELECT t1.name,
t2.city
FROM employees t1
JOIN city t2
ON t1.id = t2.id
-- 左连接:返回左表全量数据
SELECT t1.name,
t2.city
FROM employees t1
LEFT JOIN city t2
ON t1.id=t2.id
-- 右连接:返回右表全量数据
SELECT t1.name,
t2.city
FROM employees t1
RIGHT JOIN city t2
ON t1.id=t2.id
-- 全连接:返回左表和右表全量数据
SELECT t1.name
t2.city
FROM employees t1
FULL JOIN city t2
ON t1.id =t2.idHive优化和案例讲解
核心优化思想
- 尽早过滤不需要的数据,减少每个阶段输出数据量
- 减少 job 数量
- 尽量让map阶段均衡读取数据,减少数据倾斜
过滤不需要数据
sql
----列裁剪(尽量避免使用*)
table1:a、b、c、d、e、f
table2:a、g、h、i、k
SELECT t1.a,t1.b,t1.c,t2.g
FROM ( SELECT a,b,c FROM table1 WHEREe < 40 ) t1
JOIN ( SELECT a,g FROM table2 WHERE k = '北京' ) t2
ON t1.a = t2.a
----分区裁剪
--在查询的过程中 分区越精确越好
oper_erp oper_type dt ht
zhangsan create_file 2024-08-01 02
lisi delete file 2024-08-01 03
wangwu create file 2024-08-01 04
SELECT erp, path, oper_type,oper_time
FROM system_audit_log
WHERE dt = '2024-08-01'
AND ht = 03
----在join前过滤掉不需要的数据
--先关联,后过滤(不推荐)
SELECT a.val,b.val
FROM a
LEFT OUTER JOIN b
ON a.key = b.key
WHERE a.ds = 2024-08-14 AND b.ds = 2024-08-14
--先过滤,后关联(推荐)
SELECT x.val,y.val FROM
(SELECT key,val FROM a WHERE a.ds=2024-08-14) x
LEFT OUTER JOIN
(SELECT key,val FROM b WHERE b.ds=2024-08-14) y
ON x.key=y.key减少job数
-- 多表关联时尽量选择同一个key:无论内关联还是外关联,如果join的key相同的话,不管关联多少个表只生成一个job。下面以a,b,c 三表举例
--- 被翻译成 1 个 JOB
SELECT a.val, b.val, c.val
FROM a
JOIN b ON (a.key = b.key1)
JOIN c ON (b.key1 = c.key)
--- 被翻译成 2 个 JOB
SELECT a.val, b.val, c.val
FROM a
JOIN b ON (a.key = b.key1)
JOIN c ON (b.key2 = c.key)
--- union all 中的 job 优化
-- 2个job
SELECT * FROM
(select c1, c2 from A group by c1, c2) t1
union all
(select c1, c2 from B group by c1, c2) t2
-- 1个job
SELECT * FROM
(select c1, c2 from A union all select c1, c2 from B) t
group by c1, c2查询结果复用
使用 with as 将查询的结果保持下来,供后面的sql使用
sql
-- 查询 a 表两次
INSERT OVERWRITE TABLE tmp1
SELECT ... FROM a WHERE 条件1;
INSERT OVERWRITE TABLE tmp2
SELECT ... FROM a WHERE 条件1;
-- 查询 a 表一次
WITH AS tmp_a (SELECT ... From a )
INSERT OVERWRITE TABLE tmp1
SELECT ... FROM tmp_a WHERE 条件1;
INSERT OVERWRITE TABLE tmp2
SELECT ... FROM tmp_a WHERE 条件1; 行转列
若一行中有一个字段有多个值则给拆除来,单独成几行。
用 explode 关键字来拆分。explode入参是必须是一个列表,故用 split 对all_city关键字进行逗号分割成一个列表
sql
id user name all_citys
id1 user1 name1 北京,天津
id2 user2 name2 上海,河北
SELECT id, user, name, city From myTable LATERAL VIEW explode(split(all_city, ',')) adTable AS city
id user name city
id1 user1 name1 北京
id1 user1 name1 天津
id2 user2 name2 上海
id2 user2 name2 河北去重优化
由于 COUNT DISTINCT 操作需要用一个 Reduce Task 来完成,这一个 Reduce 需要处理的数据量太大,就会导致整个 Job 很难完成。
一般 COUNT DISTINCT 先用 GRUOP BY 再COUNT
对于大数据用GRUOP BY的效率远大于 COUNT DISTINCT
-- 会比较慢 不推荐
SELECT COUNT(DISTINCT id) FROM bigtable;
-- 对比大数据集,用GROUP BY的效率明显高于DISTINCT 推荐
SELECT COUNT(id) FROM (SELECT id FROM bigtable GROUP BY id) a;mapjoin
在查询过程中,将小表放前面,大表放后面
sql
-- mapjoin中小表被作为驱动表直接加载到内存中,每个map都会拿另一个表的数据与内存中的小表数据做匹配,由于每个map处理的数据量大致相同,因此解决了数据倾斜问题
-- 启动mapjoin需先设置以下参数
SET hive.auto.convert.join=TRUE
SET hive.mapjoin.smalltable.filesize=25000000; -- 设置小表最大为25MB
-- 执行查询语句 /*+ mapjoin(a)*/ 就是将small_table加载进内存
SELECT /*+ mapjoin(a)*/ a.id, b.col
FROM small_table a
JOIN big_table b
ON a.id = b.id减少数据倾斜
数据倾斜指的是 在map-reduce 执行中, 单个map或单个reduce处理的数据量明显大于其他task处理的数据量。比如,空值数据占比大,爆单商品sku数据 就可能会导致数据倾斜。
具体表现:作业经常卡在Reduce=99%处,最后1%要跑很久
#假设有用户表,日志表两张表
1 空值数据倾斜处理:赋予空值或其他异常值新的key值
-- 将空值key赋值为一个字符串+随机数,用于把倾斜的数据分布在不同的reducer上
select *
from log a
left outer join user b
on case
when a.user_id is null then concat('hive', rand())
else a.user_id end ) = b.user_id
2 key值不均产生的数据倾斜
-- 大量重复key产生的数据倾斜:通过调整参数实现负载均衡
-- 基本思路:先做一次部分聚合,再做最终聚合
-- 方法1 map端部分聚合(按大小切片,保证每个map数据量差不多)
set hive.map.aggr = true; -- 默认为true
-- 方法2 前面设为true时,生产的查询计划会有两个MR job
set hive.groupby.skewindata = true; -- 默认为false当然应急的时候,可以对空值,特殊值的过滤来解决数据倾斜。