1. 执行摘要
挑战: 传统数据仓库在处理现代数据需求时面临诸多限制,包括高昂的存储和计算成本、处理海量多样化数据的能力不足、以及数据从产生到可供分析的端到端延迟过高。同时,虽然数据湖提供了低成本、灵活的存储,但往往缺乏数据可靠性、治理能力和查询性能,导致所谓的"数据沼泽"问题。这种两层架构(数据湖 + 数据仓库)导致了数据冗余、架构复杂和运维成本增加。
传统数据架构问题 高成本 数据延迟高 数据沼泽问题 架构复杂 湖仓一体解决方案 低成本云存储 开放表格式 统一平台 Delta Lake Apache Iceberg
解决方案: 湖仓一体(Lakehouse)架构应运而生,旨在结合数据湖的灵活性、可扩展性和成本效益,以及数据仓库的数据管理、可靠性和性能优势。这种新范式建立在低成本的云对象存储之上,通过引入开放表格式(如 Delta Lake 和 Apache Iceberg)来为数据湖带来可靠性和高性能。
关键赋能技术: Delta Lake 和 Apache Iceberg 等开源表格式是实现湖仓一体的核心。它们直接在数据湖存储(如 Parquet 文件)之上提供 ACID 事务、模式演进、时间旅行和并发控制等关键功能,确保数据湖的可靠性和可管理性,使其能够支持传统数仓的分析负载。
核心优势: 本报告将详细阐述基于 Delta Lake 或 Iceberg 构建湖仓一体平台的核心优势:
- 显著降低延迟: 通过支持实时或近实时数据写入,并允许直接在湖上进行高性能查询和处理,极大地缩短了数据分析的端到端时间。
- 大幅降低成本: 利用廉价的云对象存储和开放表格式,替代昂贵的专有数仓存储和计算资源,同时简化架构,减少数据冗余和 ETL 成本。
- 统一分析平台: 在单一数据副本上支持多样化的分析工作负载,包括BI报表、SQL 分析、数据科学和机器学习。
文章路线图: 本文将深入探讨 Delta Lake 和 Iceberg 的核心特性,阐述湖仓一体架构的概念与优势,研究实时数据摄入和湖上数据处理的技术与模式,分析其在降低延迟和成本方面的效益,总结构建此类平台的关键组件和技术栈,并探讨与下游分析工具的集成实践。
2. 基石:为可靠数据湖设计的开放表格式
引言: 传统数据湖虽然提供了低成本、大容量的存储能力,但其核心问题在于缺乏对存储文件的有效管理机制。直接操作 HDFS 或对象存储上的原始文件(如 Parquet、ORC)难以保证数据的一致性、可靠性和查询性能,这正是导致需要额外构建数据仓库进行分析的主要原因。开放表格式(Open Table Formats, OTF)如 Delta Lake 和 Apache Iceberg 的出现,旨在解决这一核心痛点。它们在数据湖的原始文件之上增加了一个元数据层,带来了事务管理、模式约束和性能优化等关键能力,使得直接在数据湖上构建可靠、高性能的分析平台成为可能。
原始数据文件 元数据层 Delta Lake Apache Iceberg ACID事务 模式演进 时间旅行 ACID事务 模式演进 时间旅行 分区演进
Delta Lake:
- 核心概念: Delta Lake 是一个开源存储层,它通过在 Parquet 数据文件 基础上增加一个基于文件的事务日志 (_delta_log),为数据湖带来了 ACID 事务能力和可扩展的元数据处理。它与 Apache Spark API 完全兼容,并与 Spark Structured Streaming 紧密集成,使得批处理和流处理可以无缝地操作同一份数据副本。Delta Lake 最初由 Databricks 开发并持续贡献。
Delta Lake架构 Parquet数据文件 事务日志_delta_log JSON日志文件 Parquet检查点文件 应用程序 批处理 流处理
-
ACID 事务: Delta Lake 实现 ACID 事务的核心在于其事务日志。该日志存储在表目录下的 _delta_log 子目录中,由一系列按顺序编号的 JSON 文件(记录单次提交的原子操作,如添加/删除文件、更新元数据)和定期的 Parquet 格式检查点文件(Checkpoint,用于加速状态重建)组成。
- 原子性 (Atomicity): 每个写操作(如 INSERT, UPDATE, DELETE, MERGE)对应日志中的一个原子提交。操作要么完全成功记录在日志中,要么失败回滚,不会产生部分写入的数据。
- 一致性 (Consistency): 事务日志是表状态的唯一真实来源。任何读取操作都会首先查询日志以确定当前有效的表版本包含哪些数据文件,确保数据视图的一致性。
- 隔离性 (Isolation): Delta Lake 采用乐观并发控制(Optimistic Concurrency Control, OCC)。它允许多个写入者并发操作,但在提交时进行冲突检测。通过尝试原子性地创建下一个序号的日志文件(利用某些对象存储的 put-if-absent 操作或协调服务),只有一个写入者能成功提交,从而实现写入隔离。读取操作通常基于日志中的某个快照版本进行,提供快照隔离。
- 持久性 (Durability): 数据文件(Parquet)和事务日志都存储在可靠的云对象存储中,确保所有已提交的更改都是持久的。 事务日志不仅是实现 ACID 的基础,更是 Delta Lake 许多高级功能(如时间旅行、流处理集成)的核心机制。这种设计将可靠性保证与底层存储分离,虽然与 Spark 的集成最为深入和优化,但其开放的日志协议 也允许其他系统(如 Presto, Trino, Hive)访问 Delta 表,尽管可能功能或性能受限。
-
模式演进与强制: Delta Lake 允许用户在不重写现有数据的情况下演进表模式,例如添加新列或更改列类型。这些模式变更作为元数据更新记录在事务日志中。写入时,Delta Lake 会强制执行当前模式(Schema Enforcement),确保写入数据符合表定义,防止脏数据污染。此外,通过列映射(Column Mapping),可以支持重命名或删除列,而无需重写数据文件,进一步增强了模式管理的灵活性。需要注意,某些高级功能可能依赖于特定的 Delta Lake 或 Databricks Runtime 版本,且与 Iceberg 不同,Delta Lake 文档中未明确提及支持分区结构的演进(Partition Evolution)。这种无需重写数据的模式演进能力,相比传统数仓模式变更可能涉及的昂贵且耗时的操作,是一个显著的运营优势。
-
时间旅行 (数据版本控制): Delta Lake 的每次写入操作都会创建一个新的表版本,这些版本信息被完整地记录在事务日志中。用户可以通过指定版本号或时间戳来查询表的历史快照,或者回滚到之前的某个状态。这对于数据审计、错误恢复、复现实验等场景非常有用。
-
并发控制: 如前所述,Delta Lake 使用乐观并发控制。其基本流程是:记录起始表版本 -> 记录读写操作 -> 尝试提交(原子性创建日志文件) -> 如果提交失败(别人先提交),检查读取的数据是否发生冲突 -> 如果无冲突,则重试提交(通常只需更新版本号并重试日志写入,无需重新处理数据)。这种机制在大多数并发写入冲突不频繁的场景下,避免了传统悲观锁带来的开销。
-
其他特性: Delta Lake 还提供可扩展的元数据处理(利用 Spark 处理大规模表的元数据),统一的批处理和流处理接口,以及一系列性能优化手段,如数据跳过(Data Skipping,利用文件统计信息跳过不相关文件)、Z-Ordering(多维聚类优化查询性能)、文件压缩(Compaction)和清理(Vacuum)。同时,它原生支持 MERGE(Upsert)、UPDATE 和 DELETE 等 DML 操作。
Apache Iceberg:
- 核心概念: Apache Iceberg 是一个为大型分析数据集设计的开放表格式 。其设计目标之一是引擎互操作性,使得 Spark、Trino、Flink、Presto、Hive 等多种计算引擎可以安全地并发读写同一个 Iceberg 表。Iceberg 在数据文件(支持 Parquet, Avro, ORC 等格式)之上构建了一个元数据层,该层包含指向当前有效元数据文件的指针(存储在 Catalog 中)、元数据文件(Metadata files,包含 schema、partition spec、snapshot 信息)、清单列表(Manifest lists,指向构成快照的清单文件)和清单文件(Manifest files,跟踪数据文件及其统计信息)。Iceberg 最初由 Netflix 开发。
Apache Iceberg架构 数据文件层 Parquet Avro ORC 元数据层 元数据文件 清单列表 清单文件 Catalog 指向最新元数据 计算引擎 Spark Flink Trino Presto
Apache Iceberg 示例代码:
java
// 使用 Java API 创建 Iceberg 表并执行操作
import org.apache.iceberg.Table;
import org.apache.iceberg.catalog.TableIdentifier;
import org.apache.iceberg.spark.SparkCatalog;
import org.apache.iceberg.Schema;
import org.apache.iceberg.types.Types;
// 定义模式
Schema schema = new Schema(
Types.NestedField.required(1, "id", Types.LongType.get()),
Types.NestedField.optional(2, "data", Types.StringType.get()),
Types.NestedField.optional(3, "ts", Types.TimestampType.withZone())
);
// 创建表
catalog.createTable(TableIdentifier.of("db", "sample"), schema);
// 使用 Spark SQL 操作 Iceberg 表
spark.sql("INSERT INTO db.sample VALUES (1, 'a', current_timestamp())");
// 时间旅行查询
spark.sql("SELECT * FROM db.sample FOR VERSION AS OF 1");
// 动态分区演进
spark.sql("ALTER TABLE db.sample REPLACE PARTITION FIELD ts WITH days(ts)");
// 添加新列
spark.sql("ALTER TABLE db.sample ADD COLUMN new_col string");- ACID 事务: Iceberg 通过在 Catalog 中原子性地更新指向最新元数据文件的指针来实现 ACID 事务。每个元数据文件定义了一个表的完整、一致的快照(snapshot)。当写入完成时,会生成一个新的元数据文件,并通过 Catalog 的原子操作(如 compare-and-swap)将表的引用指向这个新文件。这确保了读取操作总是看到一个一致的快照,并且写入操作是原子性的。这种机制提供了快照隔离。Iceberg 对 Catalog 的依赖是其实现原子提交的关键,这与 Delta Lake 基于文件系统原子写入日志文件的方式不同。这种基于 Catalog 的设计天然地促进了引擎的互操作性,因为不同的引擎可以通过标准的 Catalog API 与 Iceberg 表交互,而无需理解底层文件日志的细节。
- 模式演进: Iceberg 提供了全面的模式演进能力,支持添加、删除、重命名列,更新列类型(拓宽),以及重排序列序。这些变更都仅仅是元数据操作,无需重写任何数据文件。Iceberg 通过为每个列分配唯一的 ID 来实现这一点。即使列被重命名或其在文件中的物理位置改变,查询引擎也能通过 ID 正确地找到并读取数据。这种基于 ID 的跟踪避免了基于名称或位置跟踪可能出现的副作用(如意外取消删除列或因删除列导致后续列名改变)。
- 分区演进与隐藏分区: Iceberg 的一个显著特性是隐藏分区(Hidden Partitioning)。Iceberg 可以根据列值自动生成分区值(例如,将时间戳转换为年月),而用户在编写查询时无需了解底层分区结构,也无需在查询中添加额外的分区过滤条件。Iceberg 会利用元数据中的分区信息自动进行分区裁剪。更进一步,Iceberg 支持分区演进(Partition Evolution)。当数据量或查询模式发生变化时,可以更改表的分区策略(Partition Spec)。旧数据将保留其原始分区布局,新数据则按照新的分区策略写入。查询时,Iceberg 可以同时处理不同分区策略下的数据。这些变更同样是元数据操作,无需重写历史数据。隐藏分区和分区演进的结合,为表的长期维护提供了极大的灵活性,能够适应不断变化的需求,避免了传统分区方案(如 Hive 风格分区)僵化且难以修改的痛点。
- 时间旅行与回滚: Iceberg 通过维护历史快照(由历代元数据文件定义)来实现时间旅行。用户可以查询特定时间点或特定快照 ID 的数据。同时,可以轻松地将表回滚到之前的某个快照状态,用于快速纠正错误。
- 并发控制: Iceberg 通常采用乐观并发控制策略。并发写入操作会各自准备新的元数据文件和数据文件。在提交时,它们会尝试通过 Catalog 的原子操作(如对元数据指针的 compare-and-swap)来更新表的当前状态。只有一个操作能够成功,失败的操作通常需要重试。
- 其他特性: Iceberg 支持丰富的 SQL DML 操作,包括 MERGE INTO, UPDATE, DELETE。它提供了内置的数据压缩(Compaction)机制来优化文件大小和布局。支持多种底层数据文件格式(Parquet, Avro, ORC)23,并具有可扩展的元数据管理能力。
对比分析:Delta Lake vs. Apache Iceberg
为了帮助在具体场景下选择合适的表格式,下表总结了 Delta Lake 和 Apache Iceberg 的关键特性对比:
| 特性 | Delta Lake | Apache Iceberg |
|---|---|---|
| ACID 实现 | 基于文件系统的事务日志 (_delta_log) | 基于 Catalog 原子更新元数据指针 |
| 主要文件格式 | Parquet | Parquet, Avro, ORC |
| 模式演进 | 支持(添加、更新类型、列映射支持重命名/删除) | 全面支持(添加、删除、重命名、更新类型、重排序),基于唯一列 ID |
| 分区演进 | 不直接支持3 | 支持,无需重写数据 |
| 隐藏分区 | 不支持 | 支持 |
| 时间旅行 | 支持,基于事务日志版本 | 支持,基于快照(元数据文件) |
| 并发控制 | 乐观并发控制(OCC),基于日志文件原子创建 | 乐观并发控制(OCC),通常基于 Catalog 原子操作 |
| 元数据存储 | 事务日志文件(JSON, Parquet Checkpoints) | 元数据文件、清单列表、清单文件 + Catalog |
| 主要生态系统 | 与 Apache Spark 和 Databricks 紧密集成 | 设计强调引擎互操作性(Spark, Flink, Trino, Presto 等) |
| 引擎兼容性 | Spark 最佳,提供与其他引擎的连接器 | 广泛兼容多种查询引擎 |
| 社区/治理 | 由 Linux 基金会托管,Databricks 是主要贡献者 | Apache 软件基金会顶级项目,社区驱动 |
讨论:
选择 Delta Lake 还是 Iceberg 取决于具体的应用场景和技术栈偏好。
Spark/Databricks 多引擎环境 是 否 是 否 选择表格式 主要技术栈? 考虑Delta Lake 考虑Iceberg 需要分区演进? 权衡偏向Iceberg 可使用Delta Lake 需要供应商独立性? 强烈建议Iceberg 可根据其他因素选择
- 如果组织深度使用 Apache Spark 和 Databricks 生态系统,Delta Lake 提供了无缝的集成和优化体验。其基于文件日志的事务机制在 Spark 环境中表现良好。
- 如果需要与多种计算引擎(如 Flink, Trino/Presto)交互 ,或者希望避免供应商锁定,Iceberg 的开放性和广泛的引擎兼容性更具优势。其基于 Catalog 的设计使得集成新引擎更为方便。
- 对于需要灵活调整分区策略 以适应数据增长或查询模式变化的场景,Iceberg 的分区演进能力是一个重要的加分项。
- Iceberg 对多种文件格式的原生支持提供了更大的灵活性。
- 近年来,两者也在相互借鉴和融合。例如,Delta Lake 推出了 UniForm 功能,旨在生成 Iceberg 元数据以提高兼容性,但这通常是只读兼容,并且可能存在元数据同步延迟和功能限制。
最终决策应综合考虑现有技术栈、未来发展方向、团队熟悉度以及对特定功能(如分区演进、多引擎写入)的需求。
3. 湖仓一体范式:融合数据湖与数据仓库
定义湖仓一体架构:
湖仓一体(Lakehouse)是一种现代数据管理架构,它旨在将数据湖的低成本、灵活性和可扩展性与数据仓库的数据管理、可靠性和性能特性相结合。其核心思想是直接在数据湖(通常是云对象存储)上实现传统数据仓库的功能,而不是维护两个独立的系统。这得益于开放数据格式(如 Parquet, ORC) 和开放表格式(如 Delta Lake, Apache Iceberg) 的发展,这些技术为存储在数据湖中的数据带来了结构、事务和治理能力。湖仓一体的目标是提供一个统一的平台,支持从原始数据到结构化数据的全生命周期管理,并能同时服务于 BI、SQL 分析、数据科学和机器学习等多种分析工作负载。
原始数据源 数据摄入层 存储层 - 云对象存储 元数据层 - Delta Lake/Iceberg SQL分析 BI报表 数据科学 机器学习 流处理
架构对比:湖仓一体 vs. 传统数据仓库 vs. 数据湖
| 特性 | 传统数据仓库 (DW) | 传统数据湖 (Data Lake) | 湖仓一体 (Lakehouse) |
|---|---|---|---|
| 主要用途 | BI报表, SQL 分析 | 原始数据存储, 数据科学, ML | 统一平台,支持 BI, SQL, DS, ML, Streaming |
| 支持数据类型 | 结构化数据为主 | 结构化, 半结构化, 非结构化 | 结构化, 半结构化, 非结构化 |
| 存储成本 | 高 (通常使用专有存储) | 低 (基于廉价对象存储) | 低 (基于廉价对象存储) |
| 数据可靠性/ACID | 支持 ACID 事务 | 通常不支持 ACID, 可靠性差 | 通过表格式 (Delta/Iceberg) 支持 ACID 事务 |
| 模式处理 | Schema-on-Write (写入时强制模式) | Schema-on-Read (读取时解释模式) | 支持 Schema Enforcement 和 Evolution |
| BI 查询性能 | 高 | 通常较差 | 通过表格式优化和查询引擎可达高性能 |
| ML/AI 支持 | 有限, 通常需导出数据 | 良好, 可直接访问原始/多样化数据 | 良好, 可直接在统一数据上进行 ML/AI |
| 治理 | 强治理 | 治理困难, 易成数据沼泽 | 通过表格式和目录服务实现改进的治理 |
| 灵活性 | 较低, 模式僵化 | 高 | 高, 支持多种数据类型和工作负载 |
| 关键技术 | 专有数据库技术 (e.g., Teradata, Oracle Exadata), 云数仓 (Snowflake, Redshift, BigQuery) | HDFS, 云对象存储 (S3, ADLS, GCS), 文件格式 (Parquet, ORC) | 云对象存储 + 开放表格式 (Delta Lake, Iceberg) + 查询引擎 (Spark, Trino, Flink) |
湖仓一体方法的关键优势:
- 成本效益 (Cost-Effectiveness): 这是湖仓一体最核心的吸引力之一。通过将数据存储在低成本的云对象存储(如 AWS S3, Azure ADLS, Google Cloud Storage)上,并利用开源的表格式和计算引擎,可以显著降低相比传统数据仓库所需的昂贵专有存储和计算许可费用。同时,统一的架构减少了在数据湖和数据仓库之间进行复杂且昂贵的 ETL 操作的需求,进一步节省了开发和运维成本。
- 可扩展性与灵活性 (Scalability & Flexibility): 湖仓一体架构天然支持存储和计算资源的分离与独立扩展。组织可以根据实际工作负载的需求,弹性地调整计算资源,而存储可以近乎无限地扩展。它能够原生处理结构化、半结构化和非结构化数据,满足现代多样化的数据分析需求。采用开放标准(如 Parquet, Delta, Iceberg)也避免了供应商锁定,提供了更大的技术选型自由度。
- 简化的架构与减少的数据冗余 (Simplified Architecture & Reduced Redundancy): 湖仓一体通过消除数据湖和数据仓库这两个独立的层级,显著简化了数据架构。数据不再需要在多个系统之间复制和移动,从而减少了数据冗余和由此带来的存储成本及数据一致性问题。这有助于建立一个单一、可信的数据源。
- 改进的数据质量与可靠性 (Improved Data Quality & Reliability): 借助于 Delta Lake 或 Iceberg 提供的 ACID 事务能力,湖仓一体确保了对数据湖中数据的并发读写操作的原子性、一致性、隔离性和持久性。模式强制(Schema Enforcement)功能确保了写入数据的质量和一致性。时间旅行功能则为数据审计和错误恢复提供了保障。
- 增强的治理能力 (Enhanced Governance): 虽然治理仍然是数据湖环境中的一个挑战,但湖仓一体通过表格式提供的元数据管理、事务日志以及与数据目录(如 AWS Glue Data Catalog, Project Nessie, Unity Catalog)的集成,使得实施数据访问控制、审计跟踪、数据血缘追踪等治理措施更为容易。例如,表格式支持的 DML 操作(UPDATE, DELETE)使得满足 GDPR 等合规性要求(如数据删除权)变得可行。
- 统一的分析能力 (Unified Analytics): 湖仓一体的核心价值在于打破了传统 BI/数仓和 AI/数据科学之间的壁垒。数据分析师、数据科学家和机器学习工程师可以在同一个数据副本上,使用各自偏好的工具(SQL, Python, R 等)和引擎(Trino, Spark, Flink 等)进行工作,无需移动或复制数据。
- 更快获得洞察 (Faster Time-to-Insights): 数据的实时或近实时摄入,加上简化的 ETL 流程和直接在湖上进行查询的能力,显著缩短了数据从产生到可用于分析和决策的时间。对流处理的原生支持进一步赋能了实时分析应用。
湖仓一体架构并非简单地将数据湖和数据仓库的功能叠加,它代表了一种向开放性 和统一性的根本转变。正是这种基于开放标准(开放文件格式、开放表格式、开放计算引擎)的统一架构,打破了过去由专有技术和数据孤岛造成的壁垒,从而实现了前所未有的灵活性和成本效益。
4. 实现实时能力
引言: 传统的数据仓库通常依赖于周期性的批量 ETL 作业来加载数据,这导致数据分析的延迟往往以小时甚至天为单位。现代业务场景,如实时监控、欺诈检测、个性化推荐等,对数据的时效性提出了更高的要求。湖仓一体架构结合流处理技术,能够支持实时或近实时的数据摄入和处理,从而显著降低端到端的数据延迟。
数据源 消息队列/Kafka Spark Structured Streaming Apache Flink Kafka Connect 湖仓一体存储
Delta Lake/Iceberg 实时分析 实时监控 机器学习预测
实时与近实时摄入技术:
将数据实时或近实时地摄入到基于 Delta Lake 或 Iceberg 的湖仓一体平台中,常用的技术和模式包括:
- Apache Spark Structured Streaming:
- 概念: 这是 Apache Spark 提供的用于流处理的、可扩展且容错的引擎。它以微批(Micro-batch)的方式处理流数据,提供了与 Spark SQL 和 DataFrame API 一致的编程模型。Spark Structured Streaming 与 Delta Lake 具有非常紧密的集成,同时也良好地支持 Iceberg。
- 从 Delta/Iceberg 读取流: 可以将 Delta 表或 Iceberg 表配置为流式数据源。在读取时,可以配置多种选项来控制流的行为:
- 速率限制: 通过 maxFilesPerTrigger(限制每个微批处理的新文件数)或 maxBytesPerTrigger(限制每个微批处理的数据量)来控制处理速率,平衡延迟和成本1。
- 处理源表变更 (Delta): 对于 Delta 源,可以使用 ignoreDeletes 忽略分区边界的删除,或使用 ignoreChanges 重新处理因 UPDATE, MERGE, DELETE 等操作导致文件重写的更新(需要下游处理可能出现的重复数据)。
- 指定起始位置: 通过 startingVersion 或 startingTimestamp 选项,可以指定流处理从表的哪个历史版本或时间点开始,而不是从头处理整个表。startingVersion: "latest" 可用于仅处理最新变更。
- 处理初始快照顺序 (Delta): 对于需要按事件时间处理的有状态流(如带水印的聚合),可以使用 withEventTimeOrder 选项确保初始快照数据按事件时间顺序处理,避免晚到数据被错误丢弃。
- 向 Delta/Iceberg 写入流: 可以将流数据写入Delta或Iceberg表。支持两种主要模式:
- Append Mode (默认): 仅将每个微批中新产生的数据追加到目标表中。
- Complete Mode: 将每个微批的完整输出结果覆盖写入目标表,适用于流式聚合场景。 对于 Delta Lake,还可以使用 foreachBatch 结合 txnAppId 和 txnVersion 选项来实现幂等写入,这在需要在一个微批内执行更复杂逻辑或写入多个表的场景中非常有用。
- 示例 (Kafka 到 Delta): 一个常见的模式是从 Kafka 读取 JSON 流,进行转换,然后使用 trigger(availableNow=True) 将数据写入 Delta 表。availableNow=True 触发器会处理自上次触发以来 Kafka 中所有可用的新数据,然后停止,这是一种近实时处理模式,相比连续流处理可以节省计算资源。代码结构通常包括:使用 spark.readStream 读取 Kafka 源 -> 定义 JSON 数据的 schema -> 使用 from_json 和其他 Spark SQL 函数进行数据转换 -> 使用 writeStream 将转换后的 DataFrame 写入 Delta 表,并指定检查点位置 (checkpointLocation)。
python
# Spark Structured Streaming:从Kafka读取数据写入Delta Lake示例
from pyspark.sql import SparkSession
from pyspark.sql.functions import from_json, col
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, TimestampType
# 创建SparkSession
spark = SparkSession.builder \
.appName("Kafka to Delta") \
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog") \
.getOrCreate()
# 定义JSON数据的Schema
schema = StructType([
StructField("id", StringType(), True),
StructField("timestamp", TimestampType(), True),
StructField("user_id", StringType(), True),
StructField("product_id", StringType(), True),
StructField("quantity", IntegerType(), True),
StructField("price", IntegerType(), True)
])
# 从Kafka读取流数据
df = spark.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "broker1:9092,broker2:9092") \
.option("subscribe", "orders") \
.option("startingOffsets", "latest") \
.load()
# 解析JSON数据
parsed_df = df.select(
from_json(col("value").cast("string"), schema).alias("data")
).select("data.*")
# 写入Delta表
query = parsed_df.writeStream \
.format("delta") \
.outputMode("append") \
.option("checkpointLocation", "/path/to/checkpoint/dir") \
.trigger(availableNow=True) \
.start("/path/to/delta/table")
query.awaitTermination()- 示例 (Kafka 到 Iceberg): 类似地,可以使用 Spark Structured Streaming 将 Kafka 数据写入 Iceberg 表。需要确保 Spark Session 配置了正确的 Iceberg 扩展和 JAR 包。流程包括:读取 Kafka 流 -> 解析和转换数据 -> 使用 writeStream 以 iceberg 格式写入目标表,同样需要指定检查点位置。
python
# Spark Structured Streaming:从Kafka读取数据写入Iceberg表示例
from pyspark.sql import SparkSession
from pyspark.sql.functions import from_json, col
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, TimestampType
# 创建SparkSession,配置Iceberg支持
spark = SparkSession.builder \
.appName("Kafka to Iceberg") \
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \
.config("spark.sql.catalog.iceberg_catalog", "org.apache.iceberg.spark.SparkCatalog") \
.config("spark.sql.catalog.iceberg_catalog.type", "hive") \
.config("spark.sql.catalog.iceberg_catalog.warehouse", "s3a://bucket/warehouse") \
.getOrCreate()
# 定义JSON数据的Schema
schema = StructType([
StructField("id", StringType(), True),
StructField("timestamp", TimestampType(), True),
StructField("user_id", StringType(), True),
StructField("event_type", StringType(), True),
StructField("data", StringType(), True)
])
# 从Kafka读取流数据
df = spark.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "broker1:9092,broker2:9092") \
.option("subscribe", "events") \
.option("startingOffsets", "latest") \
.load()
# 解析JSON数据
parsed_df = df.select(
from_json(col("value").cast("string"), schema).alias("data")
).select("data.*")
# 写入Iceberg表
query = parsed_df.writeStream \
.format("iceberg") \
.outputMode("append") \
.option("path", "iceberg_catalog.db.events_table") \
.option("checkpointLocation", "/path/to/checkpoint/dir") \
.start()
query.awaitTermination()- Apache Flink:
- 概念: Flink 是一个业界领先的分布式流处理引擎,以其低延迟和强大的状态管理能力而闻名,通常被认为是实现真正实时处理的首选框架。Flink 提供了对 Iceberg 的良好支持,并且也有针对 Delta Lake 的连接器。
- 集成模式:
- 直接写入: Flink 作业可以直接将处理后的数据写入 Delta Lake 或 Iceberg 表。
- 间接写入 (通过 Kafka): 在某些对延迟要求极高或需要进一步解耦的场景下,Flink 作业可以将结果写入 Kafka 等消息队列,然后由另一个独立的作业(如 Spark Streaming 或 Flink 作业)负责从 Kafka 读取并写入 Delta/Iceberg 表。
- 示例 (Flink SQL: Kafka 到 Iceberg): 使用 Flink SQL 可以简洁地实现从 Kafka 到 Iceberg 的流式数据管道。首先,使用 CREATE TABLE 语句定义 Kafka 源表,指定连接器信息、Topic、服务器地址和数据格式 (如 JSON),并明确列名和数据类型。然后,同样使用 CREATE TABLE 定义 Iceberg 目标表,指定 Iceberg 连接器、Catalog 类型(如 Hive, REST)、Catalog 名称、仓库路径 (Warehouse Location) 等 Iceberg 特定属性。最后,通过 INSERT INTO <iceberg_table> SELECT... FROM <kafka_table> 语句启动一个持续运行的 Flink 作业,将数据从 Kafka 源源不断地流向 Iceberg 表。在这个过程中,可以在 SELECT 语句中进行数据转换和过滤。Flink 的检查点机制(通过 SET 'execution.checkpointing.interval' =... 设置)确保了端到端的精确一次(exactly-once)语义。
sql
-- Flink SQL:从Kafka读取数据写入Iceberg表示例
-- 设置检查点间隔为30秒,确保精确一次语义
SET 'execution.checkpointing.interval' = '30s';
-- 创建Kafka源表
CREATE TABLE kafka_source (
id STRING,
timestamp TIMESTAMP(3),
user_id STRING,
event_type STRING,
data STRING
) WITH (
'connector' = 'kafka',
'topic' = 'events',
'properties.bootstrap.servers' = 'broker1:9092,broker2:9092',
'properties.group.id' = 'flink-iceberg-group',
'scan.startup.mode' = 'latest-offset',
'format' = 'json'
);
-- 创建Iceberg目标表
CREATE TABLE iceberg_sink (
id STRING,
event_time TIMESTAMP(3),
user_id STRING,
event_type STRING,
data STRING,
processing_time TIMESTAMP(3)
) WITH (
'connector' = 'iceberg',
'catalog-name' = 'hadoop_catalog',
'catalog-type' = 'hive',
'warehouse' = 's3a://bucket/warehouse',
'database-name' = 'events_db',
'table-name' = 'events_table'
);
-- 启动持续查询,将数据从Kafka流向Iceberg
INSERT INTO iceberg_sink
SELECT
id,
timestamp AS event_time,
user_id,
event_type,
data,
CURRENT_TIMESTAMP AS processing_time
FROM kafka_source;- Kafka Connect 及其他工具:
- Kafka Connect: 是 Apache Kafka 的一个组件,用于在 Kafka 与其他系统之间可靠地流式传输数据。社区提供了 Iceberg Sink Connector,可以将 Kafka Topic 中的数据直接写入Iceberg表。这对于不需要复杂流式转换的直接摄入场景是一个简单高效的选择。Kafka Connect 通常也支持精确一次语义和多表分发(multi-table fan-out)等特性。针对Delta Lake 的 Kafka Connect连接器也可能存在,但在此次研究材料中提及较少。
json
{
"name": "iceberg-sink-connector",
"config": {
"connector.class": "org.apache.iceberg.kafka.connect.IcebergSinkConnector",
"topics": "events",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": "false",
"catalog-name": "hadoop_catalog",
"catalog-impl": "org.apache.iceberg.hive.HiveCatalog",
"warehouse": "s3a://bucket/warehouse",
"database": "events_db",
"table": "events_table",
"flush.size": "100",
"flush.interval.ms": "60000"
}
}- 专用数据集成工具: 市场上也存在一些商业或开源的数据集成工具,如 Estuary Flow、Upsolver、Fivetran等,它们提供了可视化界面或更简化的配置方式,用于将来自各种源(包括流式源)的数据摄入到 Delta Lake 或 Iceberg 表中。
- dbt: 虽然 dbt 本身不是流处理工具,但它可以与流式摄入结合使用。数据可以通过 Spark Streaming 或 Flink 实时摄入到湖仓的原始层(例如 Delta/Iceberg 表),然后 dbt 可以定期运行(例如通过 Airflow 调度),对这些表中新增的数据执行批处理式的转换,构建下游的聚合或分析模型3。
流式摄入的最佳实践:
| 最佳实践 | 描述 | 示例/建议 |
|---|---|---|
| 模式管理 | 在流式摄入开始前定义好目标表的初始模式 | 使用Delta Lake的schemaTrackingLocation选项跟踪模式变更 |
| 精确一次语义 | 确保端到端的精确一次处理 | 配置恰当的检查点机制,使用事务性写入 |
| 小文件问题与压缩 | 处理流式写入产生的小文件问题 | 定期执行OPTIMIZE命令压缩小文件 |
| 延迟与成本权衡 | 根据需求平衡实时性和成本 | 低延迟场景使用Flink,近实时场景考虑Spark微批 |
| 处理更新与删除 | 合理处理源数据的变更操作 | 使用Delta CDF或Iceberg的MERGE INTO语句 |
| 监控 | 建立完善的监控机制 | 跟踪延迟、吞吐量、资源使用和失败情况 |
将实时或近实时数据摄入湖仓一体平台的核心挑战在于,既要保证数据的时效性,又要维持表格式带来的数据可靠性(ACID 事务、模式一致性)。选择 Spark Streaming、Flink 还是 Kafka Connect,很大程度上取决于对延迟的要求、数据转换的复杂度以及团队现有的技术栈和运维能力。
5. 直接在湖仓上处理数据
ETL vs ELT 策略
| 特性 | 传统ETL | 湖仓一体ELT |
|---|---|---|
| 处理顺序 | 先转换后加载 | 先加载后转换 |
| 数据存储位置 | 在专门ETL工具中处理 | 直接在湖仓平台处理 |
| 计算能力 | 依赖专用ETL工具 | 利用湖仓平台计算引擎 |
| 数据可访问性 | 仅最终状态可访问 | 原始和各阶段数据均可访问 |
| 灵活性 | 较低,固定管道 | 较高,多引擎处理 |
在数据仓库领域,传统的做法是 ETL(Extract, Transform, Load):先从源系统抽取数据,在专门的 ETL 工具或中间层进行转换和清洗,最后加载到目标数据仓库中。而在湖仓一体架构中,更常见的模式是 ELT(Extract, Load, Transform)。数据首先被抽取(Extract)并加载(Load)到湖仓的原始存储层(通常是 Delta Lake 或 Iceberg 表),保持其原始或接近原始的格式。然后,利用湖仓平台上的计算引擎直接对这些表进行转换(Transform),生成清洗、整合或聚合后的数据,存储在湖仓的不同层级中。
这种转变的主要原因是湖仓平台本身具备了强大的、可扩展的计算能力,并且可以直接操作存储在廉价对象存储上的数据。ELT 模式减少了数据在系统间移动的次数,简化了数据管道,并允许数据科学家和分析师在需要时访问更原始的数据。
多跳(Medallion)架构
数据源系统 铜牌层 Bronze/Raw 银牌层 Silver/Cleansed 金牌层 Gold/Aggregated BI工具/ML平台
一个在湖仓一体中广泛采用的数据组织和处理模式是多跳(Multi-hop)或奖牌(Medallion)架构。这种架构通常包含三个逻辑层级:
- 铜牌层 (Bronze / Raw): 存储从源系统摄入的原始数据,通常格式与源系统保持一致,仅做最少的处理(如格式转换)。这一层是历史数据的存档,可以用于重新处理。
- 银牌层 (Silver / Cleansed / Enriched): 存储经过清洗、过滤、标准化和丰富化的数据。来自不同源的数据可能在这一层被整合。这一层的数据通常是可信的,可供下游的BI和 ML 应用使用。
- 金牌层 (Gold / Aggregated / Curated): 存储为特定业务需求或分析场景(如BI报表、特征工程)而聚合或转换的数据。通常包含业务级别的聚合指标、维度模型等。
数据在这些层级之间通过一系列的ELT作业(使用Spark, Flink, Trino, Dremio等引擎)进行处理和转换,每一层都存储为Delta Lake或Iceberg表。
铜牌到银牌层SQL示例:
sql
-- 铜牌层数据加载
CREATE TABLE bronze.sales_raw
USING DELTA
LOCATION 's3://data-lake/bronze/sales_raw'
AS SELECT * FROM kafka_source;
-- 转换到银牌层
CREATE TABLE silver.sales_cleaned
USING DELTA
LOCATION 's3://data-lake/silver/sales_cleaned'
AS SELECT
id,
CAST(NULLIF(trim(customer_id), '') AS INT) AS customer_id,
CAST(amount AS DECIMAL(10,2)) AS amount,
TO_DATE(transaction_date, 'yyyy-MM-dd') AS transaction_date,
region
FROM bronze.sales_raw
WHERE id IS NOT NULL;利用计算引擎进行处理:
湖仓一体架构的核心优势之一是其开放性,允许用户选择最适合其工作负载的计算引擎来处理存储在 Delta Lake 或 Iceberg 表中的数据。
- Apache Spark: 是目前湖仓一体生态系统中最常用、功能最全面的计算引擎,尤其与Delta Lake紧密集成。Spark 提供了强大的DataFrame API和Spark SQL接口,支持批处理、流处理和机器学习。它可以高效地读写 Delta Lake 和 Iceberg 表,执行复杂的转换逻辑,是构建 ELT 管道和进行大规模数据处理的首选工具。例如,可以使用 Spark 读取一个 Iceberg 表,进行聚合操作,然后将结果写回另一个 Iceberg 表。
Spark读写Iceberg表示例:
python
# PySpark示例 - 读取Iceberg表并进行聚合操作
from pyspark.sql import SparkSession
from pyspark.sql.functions import sum, avg, month
# 创建Spark会话
spark = SparkSession.builder \
.appName("Iceberg Processing") \
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \
.config("spark.sql.catalog.iceberg", "org.apache.iceberg.spark.SparkCatalog") \
.config("spark.sql.catalog.iceberg.type", "hive") \
.getOrCreate()
# 读取银牌层销售数据
sales_df = spark.read.format("iceberg").load("iceberg.silver.sales_cleaned")
# 进行月度聚合分析
monthly_sales = sales_df \
.groupBy(month("transaction_date").alias("month"), "region") \
.agg(
sum("amount").alias("total_sales"),
avg("amount").alias("avg_sale_value")
)
# 将结果写入金牌层表
monthly_sales.writeTo("iceberg.gold.monthly_sales_by_region") \
.tableProperty("format-version", "2") \
.createOrReplace()- Trino (原 PrestoSQL): 是一个高性能的分布式 SQL 查询引擎,专注于快速的交互式分析。Trino 可以连接多种数据源,包括Delta Lake和Iceberg。它非常适合BI分析师直接在湖仓数据上运行 SQL 查询,为BI工具提供后端支持。
Trino查询示例:
sql
-- Trino上查询Iceberg表
SELECT
r.region_name,
SUM(s.total_sales) AS total_regional_sales,
AVG(s.avg_sale_value) AS avg_regional_sale
FROM iceberg.gold.monthly_sales_by_region s
JOIN iceberg.silver.region_dim r ON s.region = r.region_id
WHERE month BETWEEN 1 AND 3
GROUP BY r.region_name
ORDER BY total_regional_sales DESC;- Dremio: Dremio 是一个集成了数据目录、查询加速和SQL查询引擎的湖仓一体平台。它对 Apache Iceberg 提供了深度支持,也能查询Delta Lake。Dremio 提供了语义层、数据反射(通过预计算聚合或排序来加速查询)等特性,旨在简化数据访问并提升BI查询性能。Dremio 也支持通过 SQL(如 CREATE TABLE AS SELECT (CTAS), INSERT INTO SELECT)执行 ELT 任务,从其他数据源或湖仓内的表中读取数据并写入新的 Iceberg 表。
- 其他引擎: 湖仓一体的开放性意味着 Delta Lake 和 Iceberg 可以被越来越多的引擎所支持。例如,Apache Flink 可用于流式 ETL;传统的 Hive 引擎也可以通过连接器访问这些表格式;云服务商的查询服务如 Amazon Athena、Google BigQuery、Azure Synapse Analytics以及 Snowflake等也都在不断增强对Delta Lake和Iceberg的支持。这种互操作性,特别是对于Iceberg而言,是其核心价值主张之一。
执行转换操作:
在湖仓一体平台上,数据转换通常使用所选计算引擎提供的SQL或DataFrame API来完成。例如,使用Spark SQL或Trino SQL,可以直接在 Delta Lake 或 Iceberg 表上执行 SELECT 语句进行过滤、连接(JOIN)、聚合(GROUP BY)、窗口函数等操作。转换结果可以写入新的表(例如,从银牌层创建金牌层聚合表),或者使用MERGE INTO、UPDATE、DELETE 等 DML 语句修改现有表。
Delta Lake MERGE示例:
sql
-- 使用MERGE INTO实现变更数据捕获(CDC)处理
MERGE INTO silver.customers t
USING bronze.customer_updates s
ON t.customer_id = s.customer_id
WHEN MATCHED AND s.operation = 'DELETE' THEN
DELETE
WHEN MATCHED AND s.operation = 'UPDATE' THEN
UPDATE SET
t.name = s.name,
t.email = s.email,
t.address = s.address,
t.updated_at = CURRENT_TIMESTAMP
WHEN NOT MATCHED AND s.operation = 'INSERT' THEN
INSERT (customer_id, name, email, address, created_at, updated_at)
VALUES (s.customer_id, s.name, s.email, s.address, CURRENT_TIMESTAMP, CURRENT_TIMESTAMP);Delta Lake和Iceberg的模式演进能力 在此过程中也扮演了重要角色。当业务需求变化导致需要修改表结构(如添加新维度、更改指标计算方式)时,模式演进允许在不中断现有数据或进行昂贵的数据迁移的情况下更新表定义,从而简化了长期维护 ELT 管道的复杂性。
模式演进示例:
sql
-- Iceberg表模式演进
ALTER TABLE silver.customers
ADD COLUMN loyalty_tier STRING COMMENT '客户忠诚度等级';
-- 回滚到某个时间点的数据(时间旅行功能)
SELECT * FROM silver.customers FOR TIMESTAMP AS OF '2023-06-01 00:00:00';湖仓一体架构的核心理念在于,数据存储在一个开放、可靠的平台上,而计算则可以通过多种专门优化的引擎来完成。这种架构使得不同的团队------BI 分析师使用 SQL 通过 Trino 或 Dremio 进行交互式查询,数据工程师使用 Spark 或 Flink 构建批处理或流式 ETL 管道,数据科学家使用 Python 和 Spark 进行模型训练------都能够高效地在统一、最新的数据副本上协作,而无需将数据在不同的专用系统之间移动,从而打破了数据孤岛。
6. 核心架构组件
湖仓一体架构分层图
数据源 存储层: S3/ADLS/GCS 表格式层: Delta Lake/Iceberg 元数据管理层: Catalog 计算引擎层 查询接口/API层 治理与安全层 Apache Spark Trino Dremio Apache Flink Hive Metastore AWS Glue Project Nessie SQL接口 DataFrame API BI工具连接器 REST API IAM 访问控制 数据血缘 数据质量规则
构建一个基于 Delta Lake 或 Iceberg 的湖仓一体数据分析平台,需要整合一系列关键的技术组件,形成一个分层架构。
- 存储层 (Storage Layer):
- 云对象存储: 这是湖仓一体架构的基础。利用公有云提供的低成本、高持久性、高可扩展性的对象存储服务,如 Amazon S3、Azure Data Lake Storage (ADLS)或Google Cloud Storage (GCS) ,作为数据的主要存储库。这种存储与计算分离的模式是实现弹性和成本效益的关键。
- 数据文件: 实际的数据记录存储在这些对象存储中,通常采用开放的、面向列的(Columnar)文件格式,如 Apache Parquet(Delta Lake 的默认格式,也是 Iceberg 的常用格式)。列式存储能够有效压缩数据并提高分析查询的 I/O 效率。Iceberg 还支持 Apache Avro 和 Apache ORC 等格式。
云存储配置示例 (AWS):
python
# 使用boto3配置S3存储
import boto3
# 创建S3客户端
s3_client = boto3.client(
's3',
aws_access_key_id='YOUR_ACCESS_KEY',
aws_secret_access_key='YOUR_SECRET_KEY',
region_name='us-west-2'
)
# 创建数据湖存储桶和目录结构
buckets = ['data-lake-bronze', 'data-lake-silver', 'data-lake-gold']
for bucket in buckets:
try:
s3_client.create_bucket(
Bucket=bucket,
CreateBucketConfiguration={'LocationConstraint': 'us-west-2'}
)
print(f"存储桶 {bucket} 创建成功")
except Exception as e:
print(f"存储桶 {bucket} 创建错误: {e}")- 表格式层 (Table Format Layer):
- 这是湖仓一体架构的核心创新所在,位于原始数据文件之上,提供了关键的数据管理能力。
- Delta Lake 或 Apache Iceberg: 选择其中一种表格式来组织和管理数据湖中的文件。它们通过引入事务日志(Delta)或元数据文件和 Catalog(Iceberg)来提供 ACID 事务、模式演进、时间旅行、数据版本控制等功能,将不可靠的数据湖转变为可靠的数据存储。选择哪种格式取决于具体需求,如前文(第2节)的对比分析所述。
- 元数据管理层 (Metadata Management Layer / Catalog):
- 角色: Catalog 对于湖仓一体至关重要,特别是对于 Iceberg 架构。它负责跟踪表的元数据信息,如表的 Schema、分区规范、数据文件的位置、快照历史等。计算引擎通过 Catalog 来发现表、理解表结构并规划查询执行。对于 Iceberg,Catalog 还需要支持原子操作以保证事务性。
- Hive Metastore (HMS): 源自 Hadoop 生态的传统元数据存储服务。它可以被 Delta Lake 和 Iceberg 使用。优点是广泛兼容现有工具,缺点是需要自行部署和维护(包括后端关系数据库),且在大规模或云原生环境中可能存在性能和集成方面的挑战。
- AWS Glue Data Catalog: AWS 提供的云原生、完全托管的元数据目录服务。它与 AWS 生态系统(如 Athena, EMR, Lake Formation)深度集成,提供无服务器体验和自动化的 Schema 发现(Crawlers)。对于重度 AWS 用户来说非常方便,但可能在极高分区数量下的性能表现不如精心调优的HMS,并且是 AWS 平台绑定的。它支持Iceberg和Delta Lake表。
- Project Nessie: 一个专为现代数据湖和表格式(尤其是 Iceberg)设计的开源事务性Catalog。其核心特性是提供了类似 Git 的版本控制能力,允许对数据和元数据进行分支(Branching)、提交(Commits)和合并(Merging)操作。这极大地促进了数据协作、CI/CD for Data、数据质量保证和多表事务处理,代表了元数据管理的一种新范式,即"数据即代码"(Data-as-Code)。Nessie 需要自行部署和管理。
- 其他 Catalog: 还存在一些其他的 Catalog 选项,包括:
- 特定于平台的 Catalog: 如 Databricks Unity Catalog,它提供了统一的治理和元数据管理,并通过 UniForm 功能可以暴露 Iceberg 元数据。
- 数据库 Catalog: 如 JDBC Catalog,可以使用关系数据库来存储 Iceberg 元数据。
- 文件系统 Catalog: 如 Hadoop Catalog,直接在文件系统(如HDFS或S3)上存储元数据指针,适用于简单场景1。
- 新兴 Catalog: 如 Snowflake 推出的 Polaris Catalog。
下表对比了主要的元数据 Catalog 选项:
| 特性 | Hive Metastore (HMS) | AWS Glue Data Catalog | Project Nessie |
|---|---|---|---|
| 类型 | 开源,独立服务 | AWS 托管服务 | 开源,事务性 Catalog |
| 管理 | 自行部署和维护 (服务 + RDBMS) | 完全托管,无服务器 | 自行部署和维护 |
| 云原生? | 否 | 是 (AWS) | 否 (但可在云上部署) |
| 关键特性 | 广泛兼容,支持统计信息/约束 (非强制)2 | AWS 集成,Crawlers | Git 式版本控制 (分支/提交/合并)3 |
| 事务性 (Catalog层面) | 有限 (依赖后端 RDBMS) | 有限 | 支持事务性元数据操作 |
| 版本控制 (Git式) | 不支持 | 不支持 | 核心特性 |
| 主要格式焦点 | 通用 (Hive, Spark SQL 表) | 通用 (AWS 服务集成) | Iceberg (主要), Delta Lake (有限支持) |
| 扩展性考虑 | 高分区数下性能依赖RDBMS调优 | 高分区数下可能有性能瓶颈 | 针对大规模元数据设计 |
| 生态系统 | Hadoop, Spark, Presto/Trino | AWS | Iceberg, Dremio, Spark, Flink |
Nessie使用示例:
python
# 使用PyNessie操作分支和提交
from pynessie import init_nessie
from pynessie.conf import make_config
from pynessie.model import CommitMeta
# 连接到Nessie服务
conf = make_config(endpoint="http://localhost:19120/api/v1")
client = init_nessie(conf)
# 创建新的开发分支
client.create_branch("dev", reference="main")
# 切换到开发分支
client.set_reference("dev")
# 提交更改
commit_message = "更新销售数据模型"
author = "data_engineer@example.com"
client.commit(
CommitMeta(message=commit_message, author=author)
)
# 最终将开发分支合并回主分支
client.merge("dev", "main")Catalog 的选择对湖仓平台的运维模式和高级功能(如 Nessie 的数据版本控制)有显著影响。云原生 Catalog (Glue) 简化了运维但可能牺牲部分功能或带来平台绑定 。开源选项 (HMS, Nessie) 提供了灵活性但需要管理成本。Nessie 代表了一种更现代的、面向数据开发流程优化的方法。
- 计算引擎层 (Compute Engine Layer):
- 提供执行数据处理和查询任务的计算资源。如前文(第5节)所述,包括 Apache Spark, Apache Flink, Trino, Dremio 等。关键在于这些引擎与存储层是解耦的,可以独立扩展和选择。
- 查询接口/API 层 (Query Interface / API Layer):
- 用户和应用程序与湖仓平台交互的接口。这包括:
- SQL 接口: 通过 Trino, Spark SQL, Dremio, Athena, BigQuery 等引擎提供的标准 SQL 查询能力。
- DataFrame API: 如 Spark DataFrame API 或 Flink DataStream/Table API,用于更复杂的编程逻辑。
- 专用库: 如 pyiceberg,允许通过 Python 直接操作 Iceberg 表。
- BI 工具连接器: 允许 Tableau, PowerBI等工具连接到湖仓平台(通常通过计算引擎或专用连接器)。
- REST API: 例如,Iceberg 定义了 REST Catalog 协议,允许通过 HTTP API 进行元数据交互。
- 用户和应用程序与湖仓平台交互的接口。这包括:
PyIceberg示例:
python
# 使用PyIceberg直接操作Iceberg表
from pyiceberg.catalog import load_catalog
# 加载目录
catalog = load_catalog(
"my_catalog",
**{
"uri": "https://my-rest-catalog/api",
"credential": "token123"
}
)
# 获取表引用
table = catalog.load_table("sales.transactions")
# 获取表元数据
print(f"表名: {table.name}")
print(f"表结构: {table.schema()}")
print(f"分区规范: {table.partition_spec()}")
# 扫描数据
from pyiceberg.expressions import GreaterThan, col
# 过滤大于1000元的交易
results = table.scan(row_filter=GreaterThan(col("amount"), 1000.0))
# 读取数据到Pandas
with results.to_pandas() as df:
print(df.head())- 治理与安全层 (Governance & Security Layer):
- 负责数据安全、访问控制、合规性和数据质量。这可能涉及:
- 身份与访问管理 (IAM): 控制谁可以访问哪些资源。
- 访问控制策略: 在 Catalog 层面(如 AWS Lake Formation, Unity Catalog)或表格式层面实施细粒度的权限控制。
- 数据加密: 对静态存储和传输中的数据进行加密。
- 审计日志: 记录对数据的访问和修改操作。
- 数据质量规则: 定义和监控数据质量。
- 数据血缘: 追踪数据的来源和转换过程。
- 数据目录与业务元数据: 工具如AWS DataZone或Microsoft Purview用于添加业务上下文和促进数据发现。
- 负责数据安全、访问控制、合规性和数据质量。这可能涉及:
AWS Lake Formation权限配置示例:
sql
-- 使用AWS Lake Formation数据权限语法
GRANT SELECT
ON DATABASE lakehouse
TO IAM_USER 'arn:aws:iam::123456789012:user/analyst';
GRANT INSERT, DELETE
ON TABLE lakehouse.gold.sales_mart
TO IAM_ROLE 'arn:aws:iam::123456789012:role/data_engineer';
-- 列级别权限
GRANT SELECT (customer_id, region, total_sales)
ON TABLE lakehouse.gold.sales_mart
TO IAM_ROLE 'arn:aws:iam::123456789012:role/marketing_analyst';参考技术栈示例
| 层级 | 技术选项 |
|---|---|
| 存储层 | AWS S3 / Azure ADLS / Google GCS |
| 表格式层 | Apache Iceberg / Delta Lake |
| 元数据管理层 | Project Nessie / AWS Glue / Hive Metastore |
| 摄入引擎 | Apache Flink / Kafka Connect / Spark Structured Streaming |
| 处理/查询引擎 | Apache Spark / Trino / Dremio |
| 治理层 | AWS Lake Formation / 自定义策略+Nessie审计 / Unity Catalog |
| 消费接口 | Tableau / Power BI / SQL客户端 / Python APIs |
一个典型的基于Iceberg的湖仓一体技术栈可能如下所示:
- **存储层:**AWS S3 / Azure ADLS / Google GCS
- 表格式层: Apache Iceberg
- 元数据管理层: Project Nessie (提供版本控制) 或 AWS Glue Data Catalog (简化云上运维)
- 摄入引擎: Apache Flink (低延迟流) / Kafka Connect (简单流) / Apache Spark Structured Streaming (批流一体)
- 处理/查询引擎: Apache Spark (批处理/ML), Trino (交互式 SQL), Dremio (BI 加速/语义层)
- 治理层: AWS Lake Formation (如果使用 Glue Catalog) / 自定义策略 + Nessie 审计 / Unity Catalog (如果使用 Databricks)
- ** 消费接口: ** BI工具 (Tableau, Power BI) 通过 Trino/Dremio 连接, ML 平台 (SageMaker, Vertex AI) 通过 Spark 或直接读取, SQL客户端, 应用程序通过 API。
7. 效益分析:延迟与成本
构建基于 Delta Lake 或 Iceberg 的湖仓一体平台,其核心驱动力在于解决传统数据架构在延迟 和成本方面的痛点。
传统数据架构 高延迟问题 高成本问题 批处理模式 多阶段数据流转 存储与计算耦合 复杂ETL开销 湖仓一体架构 低延迟优势 成本效益 实时/近实时摄入 消除ETL瓶颈 直接查询能力 存储成本节约 计算成本优化 运维成本降低
降低端到端数据延迟:
- 传统数据仓库的延迟: 传统数据仓库通常采用批处理模式进行数据加载和转换。数据需要经过多个阶段(源系统 -> ETL -> Staging -> Data Lake (可选) -> ETL -> Data Warehouse),每个阶段都可能引入延迟。ETL 作业通常按小时、天甚至更长的周期运行,导致业务用户或分析应用获取到的数据往往不是最新的,延迟可能高达数小时或数天。这对于需要快速响应市场变化或实时决策的场景是不可接受的。
- 湖仓一体的低延迟优势: 湖仓一体架构通过以下方式显著缩短了数据从产生到可供分析的端到端延迟:
- 实时/近实时摄入: 如第 节所述,利用 Spark Structured Streaming, Flink, Kafka Connect 等技术,可以将数据流式地直接写入湖仓中的 Delta Lake 或 Iceberg 表,使得数据在产生后的几秒或几分钟内即可用。
- 消除 ETL 瓶颈: ELT 模式和简化的架构减少了数据在不同系统间冗长、耗时的移动和转换过程0。转换可以直接在湖仓上进行,无需等待数据加载到单独的仓库系统。
- **直接查询:**BI工具、数据科学平台和应用程序可以直接查询湖仓中的数据,无需等待数据被加载到数据仓库。这意味着分析师和模型可以使用更新鲜的数据。
- 性能优化: Delta Lake和Iceberg内建的性能优化机制(如数据跳过、索引、文件布局优化、缓存)以及高性能查询引擎(如 Trino, Dremio, Photon)的应用,使得在数据湖上直接进行大规模数据分析的性能得以保障,甚至可以媲美传统数仓。
- 延迟量级转变: 湖仓一体架构使得数据可用性的延迟从传统的**批处理周期(小时/天)转变为 近实时(分钟/秒)甚至实时(秒级/亚秒级,取决于流处理引擎和配置)**成为可能。
| 延迟比较 | 传统数据仓库 | 湖仓一体平台 |
|---|---|---|
| 数据摄入 | 批处理(小时/天) | 实时/近实时(秒/分钟) |
| ETL处理 | 多阶段ETL(小时) | 简化ELT流程(分钟) |
| 查询延迟 | 复杂的数据同步 | 直接查询源数据 |
| 端到端延迟 | 小时到天级别 | 秒到分钟级别 |
python
# 示例:使用Spark Structured Streaming实现实时数据摄入到Delta Lake
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
# 初始化Spark会话
spark = SparkSession.builder \
.appName("RealTimeIngestion") \
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog") \
.getOrCreate()
# 从Kafka流中读取数据
kafka_stream = spark.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "kafka:9092") \
.option("subscribe", "transactions") \
.load()
# 处理数据
parsed_stream = kafka_stream.selectExpr("CAST(value AS STRING)") \
.select(from_json(col("value"), schema).alias("data")) \
.select("data.*")
# 将数据流式写入Delta表
query = parsed_stream.writeStream \
.format("delta") \
.outputMode("append") \
.option("checkpointLocation", "/delta/checkpoints/transactions") \
.start("/delta/tables/transactions")实现显著的成本效益:
- 存储成本: 这是最显著的成本节约来源。湖仓一体架构将数据存储在成本极低的云对象存储上,其单位存储成本远低于传统数据仓库通常使用的、与计算紧耦合的专有存储系统。虽然像 Snowflake 这样的云数仓也利用了对象存储,但其整体架构和定价模型可能与基于开放格式的湖仓有所不同,后者通常提供更高的存储成本效益和数据所有权。
- 计算成本:
- 存算分离: 存储和计算资源的解耦允许根据实际需求独立扩展计算能力,避免了传统仓库中计算资源可能因存储需求而被动扩展或闲置的情况,从而优化了计算成本。
- 查询效率: 表格式提供的元数据优化(如分区裁剪、文件统计信息)和查询引擎的优化(如 Dremio 的反射、向量化执行)可以减少查询所需扫描的数据量和计算时间,从而降低按需计算的费用。
- 基础设施与运维成本:
- 架构简化: 消除独立的、需要分别管理和维护的数据湖和数据仓库系统,降低了整体基础设施的复杂性和运维成本。
- 减少 ETL: 简化的ELT流程意味着更少的 ETL 作业开发、调度和维护工作量。
- 开源与避免锁定: 广泛采用开源表格式(Delta, Iceberg)和开源计算引擎(Spark, Trino, Flink)可以避免与专有数据仓库供应商相关的昂贵许可费用和供应商锁定风险。这为组织提供了更大的技术选择自由度和议价能力。
| 成本类别 | 传统数据架构 | 湖仓一体架构 | 节约潜力 |
|---|---|---|---|
| 存储成本 | 专有存储系统(高成本) | 云对象存储(低成本) | 60-80% |
| 计算成本 | 存算耦合,资源浪费 | 存算分离,按需扩展 | 30-50% |
| 运维成本 | 多系统管理,复杂ETL | 架构简化,减少ETL | 40-60% |
| 许可费用 | 专有软件高额许可 | 开源技术栈降低授权费 | 50-70% |
湖仓一体的成本优势是多维度的,它不仅仅来自于更便宜的存储介质,更源于架构的简化、运维效率的提升以及开放标准带来的灵活性。这种经济上的吸引力使得湖仓一体成为处理当今海量、多样化数据的极具竞争力的解决方案。
8. 与分析生态系统集成
构建湖仓一体平台的目的最终是为了服务于下游的分析应用,包括商业智能(BI)报表和机器学习(ML)平台。因此,确保平台与这些工具的顺畅集成至关重要。
湖仓一体平台 商业智能工具集成 机器学习平台集成 平台原生连接器 查询引擎连接 平台特性利用 数据访问 MLflow集成 云服务集成 SageMaker Vertex AI
连接商业智能工具 (如 Power BI, Tableau):
- 目标: 使BI用户能够方便、高效地连接到湖仓平台,直接对存储在 Delta Lake 或 Iceberg 表中的数据进行可视化和探索分析。
- 集成方法:
- 平台原生连接器: 许多BI工具提供了针对主流数据平台或引擎的连接器。例如,Power BI提供了专门的 Databricks连接器,支持使用个人访问令牌(PAT)或OAuth进行身份验证,并可以选择 Import(导入数据到 Power BI)或 DirectQuery(直接查询 Databricks)模式。PowerBI甚至还有一个独立的 Delta Lake 连接器,可以直接读取存储中的Delta文件。
- 通过查询引擎连接: 更通用的方法是让BI工具连接到一个能够查询湖仓数据的 SQL 查询引擎,如 Trino, Dremio, Spark SQL, Snowflake, BigQuery等。这些引擎充当了BI工具和底层 Delta/Iceberg 表之间的桥梁。例如,Dremio 提供了优化的 Tableau 和Power BI连接器,并利用其反射(Reflections)功能加速BI查询,实现直接在湖仓上进行高性能交互式分析7。
- 利用平台特性: 某些湖仓平台提供了简化的集成功能。例如,Databricks 允许用户直接从其 UI 将 Unity Catalog 中的表或 Schema 发布为 Power BI数据集,或者可以通过其 SQL Endpoint 连接。Snowflake 也可以查询外部的 Iceberg 表,然后通过 Snowflake 的BI连接器进行访问。
- 关键考虑因素:
- 身份验证: 需要配置安全的身份验证机制,如OAuth或PAT。
- 连接模式 (Import vs. DirectQuery): Import 模式通常性能更好,但数据有延迟且受内存限制;DirectQuery 模式提供实时数据,但对后端查询引擎的性能要求很高。对于 DirectQuery,使用高性能引擎(如 Trino, Dremio, Databricks SQL Warehouse)和优化技术(如 Dremio 反射)至关重要。
- 性能: 确保查询引擎和表格式本身经过优化(如分区、压缩、统计信息),以提供可接受的BI查询响应时间。
- 安全与访问控制: 必须在连接层或底层数据平台实施恰当的访问控制策略,确保用户只能看到他们有权限访问的数据。
sql
-- 示例:在Trino中优化Delta表查询性能的SQL
-- 1. 创建优化的表布局
CREATE TABLE sales_optimized
WITH (
partitioning = ARRAY['year', 'month'],
bucketed_by = ARRAY['customer_id'],
bucket_count = 32
)
AS SELECT * FROM sales;
-- 2. 在Trino中使用分区裁剪查询
SELECT
customer_id,
SUM(amount) as total_sales
FROM
sales_optimized
WHERE
year = 2023 AND
month = 6 AND
region = 'APAC'
GROUP BY
customer_id
ORDER BY
total_sales DESC
LIMIT 10;集成机器学习平台 (如 MLflow, SageMaker, Vertex AI):
- 目标: 使数据科学家能够轻松地从湖仓中访问数据进行模型训练,并利用MLOps平台(如MLflow)进行实验跟踪、模型管理,最终将模型部署到生产环境(如SageMaker, Vertex AI)。
- 数据访问: 湖仓一体架构极大地简化了 ML 的数据访问。由于数据通常存储在开放格式(如Parquet)中,主流的 ML 框架(如 TensorFlow, PyTorch, scikit-learn)和库(如 Pandas)通常可以直接读取这些文件。Apache Spark 的集成(尤其是对于 Delta Lake)也为大规模数据预处理和特征工程提供了便利。
- MLflow 集成: MLflow 是一个流行的开源 MLOps 平台。
- 实验跟踪: 可以在 Databricks 等环境中训练模型(使用 Delta Lake 数据),并使用 MLflow 自动或手动跟踪实验参数、指标和模型构件。
- 模型部署: MLflow 提供了将已注册模型部署到云平台的功能:
- 部署到 Amazon SageMaker: 使用 mlflow sagemaker build-and-push-container 和 mlflow deployments create 命令,可以构建兼容 SageMaker 的 Docker 镜像,推送到 ECR,并创建 SageMaker Endpoint 来托管模型。这需要预先配置好 AWS IAM 角色、ECR仓库和S3存储桶的权限。
- 部署到 Google Cloud Vertex AI: 通过安装 google-cloud-mlflow 插件,可以将 MLflow 中(可能在 Databricks 上训练)的模型部署到 Vertex AI Endpoint。这同样需要配置Google Cloud服务账号权限,并将模型构件存储在Google Cloud Storage中。
- Amazon SageMaker 集成:
- 数据处理: SageMaker Studio 可以连接到运行 Spark 的 EMR 集群,以处理存储在S3上的 Delta Lake 数据。
- 模型训练与托管: SageMaker 提供了丰富的内置算法,支持主流 ML 框架,并提供模型训练和托管服务。
- SageMaker Lakehouse: 这是 SageMaker 的一项新功能,允许通过 AWS Glue Iceberg REST Catalog 访问S3上的 Iceberg 表,并利用 AWS Lake Formation 进行权限管理。这使得 SageMaker 可以更原生、安全地与 Iceberg 数据湖集成。
- MLflow on SageMaker: 可以在 SageMaker Unified Studio 中创建和管理MLflow Tracking Server,用于跟踪在 SageMaker 环境中进行的实验。
- Google Cloud Vertex AI集成:
- 模型部署: 如前所述,通过google-cloud-mlflow插件,可以将来自Databricks/MLflow的模型部署到 Vertex AI 进行托管和在线预测。Vertex AI提供统一的AI平台,涵盖数据准备、训练、部署和监控。
| 集成平台 | 集成方式 | 主要优势 | 挑战 |
|---|---|---|---|
| BI工具 | 原生连接器/查询引擎 | 直接可视化湖仓数据 | 查询性能、身份验证 |
| MLflow | 实验跟踪/模型管理 | 统一ML生命周期管理 | 跨平台部署复杂性 |
| SageMaker | API集成/Lakehouse功能 | 强大的训练托管能力 | AWS生态系统锁定 |
| Vertex AI | 插件集成/API | 全面AI平台能力 | GCP生态系统锁定 |
python
# 示例:从Delta Lake读取数据并训练模型,使用MLflow跟踪实验
import mlflow
from pyspark.sql import SparkSession
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# 初始化Spark会话
spark = SparkSession.builder \
.appName("ML-DeltaLake-Integration") \
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog") \
.getOrCreate()
# 从Delta Lake读取特征数据
delta_table_path = "/delta/tables/features"
features_df = spark.read.format("delta").load(delta_table_path)
pandas_df = features_df.toPandas()
# 准备训练数据
X = pandas_df.drop("target", axis=1)
y = pandas_df["target"]
# 使用MLflow跟踪实验
mlflow.set_experiment("delta-lake-ml-experiment")
with mlflow.start_run():
# 记录数据来源
mlflow.log_param("data_source", delta_table_path)
# 训练模型
rf = RandomForestClassifier(n_estimators=100, random_state=42)
rf.fit(X, y)
# 评估模型
y_pred = rf.predict(X)
accuracy = accuracy_score(y, y_pred)
mlflow.log_metric("accuracy", accuracy)
# 记录模型
mlflow.sklearn.log_model(rf, "random_forest_model")
print(f"模型训练完成,准确率: {accuracy:.4f}")
# 部署到SageMaker的示例命令
# mlflow sagemaker build-and-push-container
# mlflow deployments create -t sagemaker://<region>/model-name \
# --name my-model-deployment \
# --model-uri models:/random_forest_model/1湖仓一体架构,特别是其对开放数据格式的支持,显著简化了机器学习流程中的数据准备和访问环节。集成的挑战更多地转向了 MLOps 层面:如何在湖仓环境(通常是模型训练发生的地方)与云端托管的 ML 服务(用于模型部署和推理)之间建立顺畅的工作流。MLflow 及其相关的部署工具和插件在弥合这一差距方面发挥着越来越重要的作用。
集成最佳实践:
湖仓一体分析平台集成最佳实践 BI集成路径 ML集成路径 安全治理层 实时/批量 原生连接器
首选 性能需求高 优化连接 数据准备 实验管理 模型注册 部署工具 插件集成 决策支持 模型服务 模型服务 业务数据源 业务分析师 应用系统 统一身份管理 数据访问控制 特征工程
Spark/Python MLflow
实验跟踪 模型仓库 AWS SageMaker Google Vertex AI 商业智能工具
Power BI/Tableau 湖仓一体平台
Delta Lake/Iceberg 高性能SQL引擎
Trino/Dremio
- 优先使用平台或引擎提供的原生连接器(如 Databricks-PowerBI连接器),因为它们通常经过优化且易于配置。
- 当原生连接器性能不足或功能受限时,考虑使用高性能 SQL 查询引擎 (如 Trino, Dremio)作为BI工具的中间层。利用这些引擎的查询加速功能(如 Dremio Reflections)。
- 对于 ML 工作流,使用 MLflow 进行标准化的实验跟踪和模型管理 。利用MLflow提供的部署工具或插件 实现与 SageMaker 或 Vertex AI 等云 ML 平台的集成。
- 在所有集成点上,务必仔细配置安全和治理。确保身份验证安全,权限控制到位(例如,使用 Lake Formation 控制 SageMaker 对 Iceberg 数据的访问,配置 IAM 角色进行模型部署)。
9. 结论与战略建议
总结:
本报告深入探讨了如何利用 Delta Lake 和 Apache Iceberg 等开放表格式构建支持实时写入、融合数据湖与数据仓库优势的湖仓一体(Lakehouse)数据分析平台。分析表明,湖仓一体架构通过在低成本的云对象存储之上实现 ACID 事务、模式管理、时间旅行和高性能查询,有效克服了传统数据仓库的高成本、高延迟和灵活性差的缺点,以及传统数据湖在可靠性、治理和性能方面的不足。
湖仓一体架构流程图
计算引擎 数据摄入工具 实时数据 批量数据 SQL Python/Scala Streaming Spark Trino Dremio Presto Flink Spark Streaming Kafka Connect 数据源 数据摄入层 开放表格式存储层
Delta Lake/Iceberg 统一元数据层
Catalog服务 计算引擎层 BI分析 AI/ML应用 实时应用
价值主张:
基于 Delta Lake 或 Iceberg 的湖仓一体平台的核心价值在于:
- 统一数据管理: 在单一平台上管理从原始数据到聚合数据的全生命周期,打破BI和 AI/ML 的数据孤岛。
- 降低总拥有成本: 通过利用廉价存储、存算分离和开源技术显著降低成本。
- 提升数据时效性: 支持实时/近实时数据摄入和处理,大幅缩短数据洞察时间。
- 增强灵活性与可扩展性: 轻松处理多样化数据类型,独立扩展存储和计算资源,避免供应商锁定。
- 提高数据可靠性与治理: 保证数据事务一致性,实施模式强制,简化治理和合规任务。
Delta Lake与Iceberg功能对比表
| 功能特性 | Delta Lake | Apache Iceberg |
|---|---|---|
| 开源许可 | Apache 2.0 | Apache 2.0 |
| 主要贡献者 | Databricks | Netflix, Apple, Adobe |
| ACID事务 | ✅ | ✅ |
| 时间旅行 | ✅ | ✅ |
| 模式演进 | ✅ | ✅ |
| 分区演进 | 有限支持 | ✅ 完全支持 |
| 数据跳过 | Z-Order | 分区+位置索引 |
| 兼容引擎 | Spark, Flink(有限) | Spark, Flink, Trino, Dremio等 |
| SQL DML支持 | MERGE, UPDATE, DELETE | MERGE, UPDATE, DELETE |
| 行级安全 | ✅ (Databricks付费版) | 有限支持 |
| 云平台集成 | 所有主流云 | 所有主流云 |
战略建议:
- 选择 Delta Lake vs. Apache Iceberg:
- 评估现有生态: 若深度绑定 Databricks/Spark 生态,Delta Lake提供无缝集成。若追求多引擎互操作性(Flink, Trino等)或希望最大程度避免供应商影响,Iceberg的开放性和广泛兼容性更优。
- 考虑特定功能: 如果灵活的分区演进是关键需求,Iceberg 是明确的选择。
- 探索融合方案: 对于已有Delta Lake但希望提高与其他Iceberg兼容工具互操作性的场景,可评估Delta UniForm,但需注意其限制(如只读、异步元数据、不支持所有Delta特性)。
数据操作代码示例
Delta Lake (使用Spark SQL)
sql
-- 创建Delta表
CREATE TABLE sales_delta (
id BIGINT,
product STRING,
category STRING,
amount DOUBLE,
ts TIMESTAMP
) USING DELTA
PARTITIONED BY (category)
LOCATION 's3://lakehouse-demo/sales_delta';
-- 执行MERGE操作
MERGE INTO sales_delta AS target
USING sales_updates AS source
ON target.id = source.id
WHEN MATCHED THEN
UPDATE SET target.amount = source.amount, target.ts = source.ts
WHEN NOT MATCHED THEN
INSERT (id, product, category, amount, ts)
VALUES (source.id, source.product, source.category, source.amount, source.ts);
-- 时间旅行查询
SELECT * FROM sales_delta VERSION AS OF 123
WHERE category = 'Electronics';Iceberg (使用Spark SQL)
sql
-- 创建Iceberg表
CREATE TABLE sales_iceberg (
id BIGINT,
product STRING,
category STRING,
amount DOUBLE,
ts TIMESTAMP
) USING ICEBERG
PARTITIONED BY (category)
LOCATION 's3://lakehouse-demo/sales_iceberg';
-- 执行UPDATE操作
UPDATE sales_iceberg
SET amount = amount * 1.1
WHERE category = 'Electronics';
-- 执行时间旅行查询
SELECT * FROM sales_iceberg FOR TIMESTAMP AS OF '2023-01-01 12:00:00';- 选择合适的工具:
- 数据摄入: 根据延迟要求和转换复杂度选择:Flink (最低延迟), Spark Streaming (批流一体), Kafka Connect (简单摄入)。
- 数据处理/查询: Spark (通用批处理/ML), Trino (交互式SQL/BI) , Dremio (BI加速/语义层)。
- 元数据管理: AWS Glue (简化AWS运维), Project Nessie (需要 Git 式数据版本控制), HMS (兼容旧系统)。
使用Spark Streaming摄入数据示例
python
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
# 创建SparkSession
spark = SparkSession.builder \
.appName("KafkaToLakehouse") \
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog") \
.getOrCreate()
# 从Kafka读取流数据
df = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "kafka:9092") \
.option("subscribe", "sales_events") \
.load()
# 解析JSON数据
parsed_df = df.select(
from_json(col("value").cast("string"), schema).alias("data")
).select("data.*")
# 写入Delta Lake表
query = parsed_df \
.writeStream \
.format("delta") \
.outputMode("append") \
.option("checkpointLocation", "s3://lakehouse-demo/checkpoints/sales") \
.table("sales_delta")
query.awaitTermination()湖仓一体平台实施路线图
2025-01-01 2025-02-01 2025-03-01 2025-04-01 2025-05-01 2025-06-01 云存储设置 元数据服务部署 计算资源配置 优先业务场景识别 数据模型设计 批量数据迁移 实时管道构建 BI仪表盘开发 数据科学环境搭建 ML模型部署流程 安全框架实施 监控告警系统 数据质量框架 基础设施 数据迁移 应用开发 治理与运维 湖仓一体平台实施计划
- 实施规划:
- 从小处着手: 从特定的业务用例开始,逐步扩展湖仓平台的应用范围。
- 设计先行: 仔细规划初始的 Schema 设计、分区策略,并考虑未来的演进需求。
- 关注数据质量: 在数据管道中尽早实施数据质量检查和验证规则。
- 建立治理框架: 在平台建设初期就考虑数据安全、访问控制和合规性要求。
- 分阶段迁移: 如果从现有系统迁移,制定详细的、分阶段的迁移计划。
- 拥抱开放标准: 尽可能利用开放文件格式、开放表格式和开源计算引擎,以保持长期的灵活性和成本效益。
- 投资技能培养: 确保团队具备分布式计算(Spark, Flink)、SQL-on-Lake 引擎、所选表格式和 Catalog 的专业知识。
数据质量检查示例 (使用Python与Great Expectations)
python
import great_expectations as ge
from pyspark.sql import SparkSession
# 初始化Spark会话
spark = SparkSession.builder \
.appName("DataQualityChecks") \
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \
.getOrCreate()
# 读取Delta表数据
df = spark.read.format("delta").load("s3://lakehouse-demo/sales_delta")
ge_df = ge.dataset.SparkDFDataset(df)
# 定义期望并验证
results = ge_df.expect_column_values_to_not_be_null("id")
print(f"ID列非空检查: {'通过' if results.success else '失败'}")
results = ge_df.expect_column_values_to_be_between("amount", min_value=0, max_value=1000000)
print(f"金额范围检查: {'通过' if results.success else '失败'}")
results = ge_df.expect_column_values_to_be_in_set("category",
["Electronics", "Clothing", "Food", "Home", "Sports"])
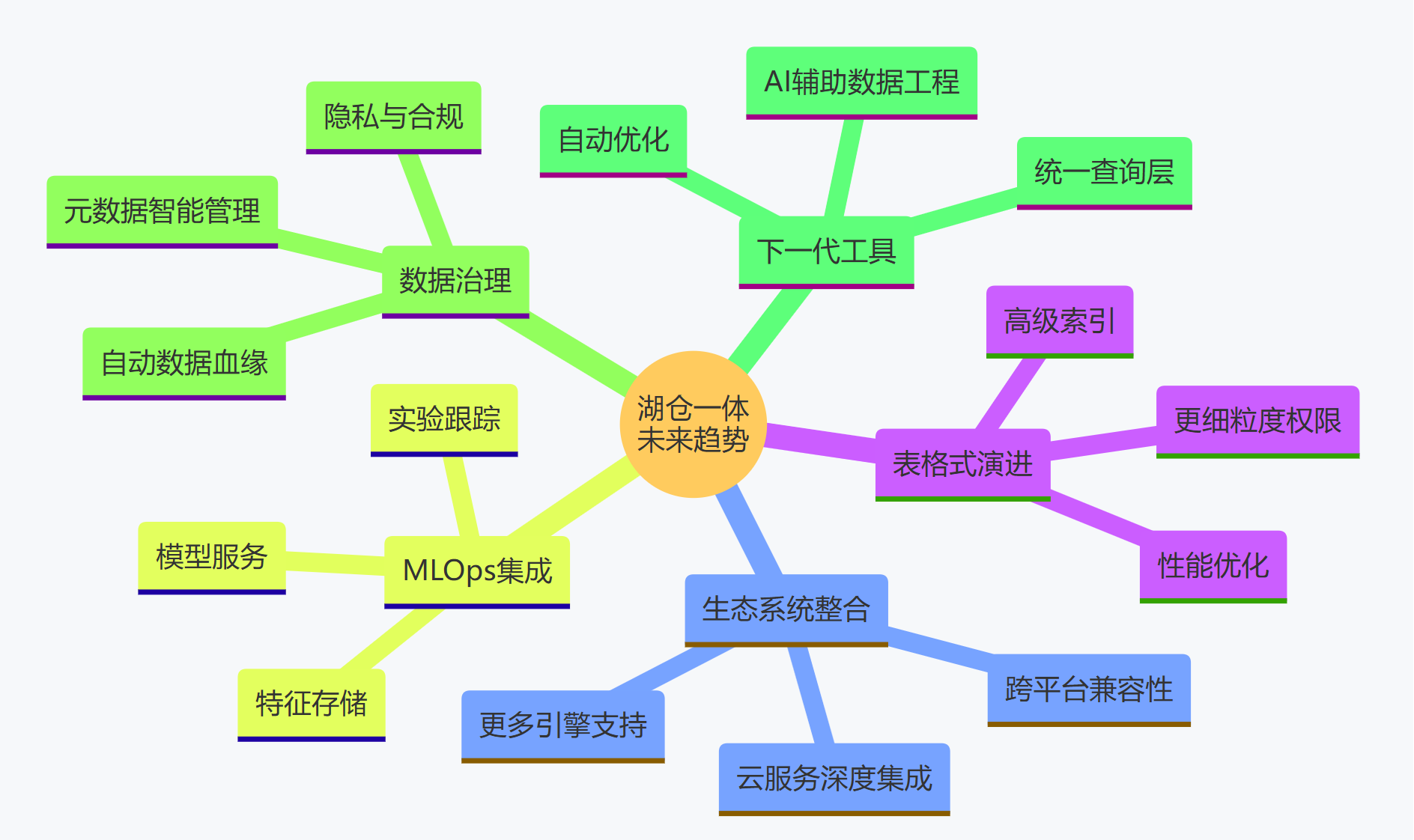
print(f"分类值检查: {'通过' if results.success else '失败'}")未来展望:
湖仓一体技术仍在快速发展中。我们可以预期看到表格式功能的持续增强、更多计算引擎的集成、以及更成熟的治理和 MLOps 工具的出现。Delta Lake 和 Iceberg 之间的竞争与融合(如 Delta UniForm、Snowflake 对 Iceberg 的支持)将进一步推动生态系统的发展,为用户提供更多选择和更强大的能力。采用湖仓一体架构,特别是基于 Delta Lake 或 Iceberg 这样的开放技术,将是企业构建面向未来的、敏捷、高效、可扩展的数据分析平台的关键战略方向。
未来技术趋势预测