机器学习-线性回归模型
- 线性模型笔记
-
- 1、向量化
- 2、线性回归模型公式
- 3、损失函数(代价函数)
- 4、梯度下降法
- [5、Python 实现示例](#5、Python 实现示例)
- [6、使用 sklearn 实现线性回归模型](#6、使用 sklearn 实现线性回归模型)
-
-
- [✅ 基本步骤如下:](#✅ 基本步骤如下:)
- [📦 示例代码:](#📦 示例代码:)
- 7、numpy中的切片
-
- Xn,:是取第1维中下标为n的元素的所有值
- X1,:即取第一维中下标为1的元素的所有值
- X:,0就是取所有行的第0个数据,
- [X:,1 就是取所有行的第1个数据](#X[:,1] 就是取所有行的第1个数据)
- [X:, m:n,即取所有数据的第m到n-1列数据,含左不含右](#X[:, m:n],即取所有数据的第m到n-1列数据,含左不含右)
- [8、特征缩放(Feature Scaling)](#8、特征缩放(Feature Scaling))
-
- [✅ 解决方法:标准化(Z-score Normalization)](#✅ 解决方法:标准化(Z-score Normalization))
- [📦 sklearn 实现:](#📦 sklearn 实现:)
- 8、使用面积和卧室数量的多项式回归
-
- [✅ 目标:](#✅ 目标:)
- [📦 代码实现:](#📦 代码实现:)
- 代码运行结果
-
线性模型笔记
文章使用的数据集:ex1data2.txt
1、向量化
在线性回归中,我们希望通过向量化来高效计算预测值:
传统公式(单个样本):
y ^ = θ 0 + θ 1 x 1 + θ 2 x 2 + ⋯ + θ n x n \hat{y} = \theta_0 + \theta_1 x_1 + \theta_2 x_2 + \cdots + \theta_n x_n y^=θ0+θ1x1+θ2x2+⋯+θnxn
向量表示:
y ^ = θ T x \hat{y} = \theta^T x y^=θTx
通常我们在输入 x x x 中添加一个 x 0 = 1 x_0 = 1 x0=1,来统一表示偏置项。
2、线性回归模型公式
假设有 m m m 个样本、 n n n 个特征:
- 特征矩阵: X ∈ R m × n X \in \mathbb{R}^{m \times n} X∈Rm×n
- 参数向量: θ ∈ R n × 1 \theta \in \mathbb{R}^{n \times 1} θ∈Rn×1
- 标签向量: y ∈ R m × 1 y \in \mathbb{R}^{m \times 1} y∈Rm×1
模型预测公式:
y ^ = X θ \hat{y} = X \theta y^=Xθ
3、损失函数(代价函数)
使用 均方误差(MSE) 作为损失函数:
J ( θ ) = 1 2 m ∑ i = 1 m ( y ^ ( i ) − y ( i ) ) 2 J(\theta) = \frac{1}{2m} \sum_{i=1}^{m} (\hat{y}^{(i)} - y^{(i)})^2 J(θ)=2m1i=1∑m(y^(i)−y(i))2
向量化表达式:
J ( θ ) = 1 2 m ( X θ − y ) T ( X θ − y ) J(\theta) = \frac{1}{2m} (X\theta - y)^T (X\theta - y) J(θ)=2m1(Xθ−y)T(Xθ−y)
4、梯度下降法
使用梯度下降法更新参数 θ \theta θ:
θ : = θ − α ⋅ 1 m X T ( X θ − y ) \theta := \theta - \alpha \cdot \frac{1}{m} X^T (X\theta - y) θ:=θ−α⋅m1XT(Xθ−y)
其中:
- α \alpha α 是学习率
- X T X^T XT 是特征矩阵的转置
- ( X θ − y ) (X\theta - y) (Xθ−y) 是预测误差
5、Python 实现示例
python
import numpy as np
def computerCost(X,y,theta):
inner=np.power(((X*theta.T)-y),2)
return np.sum(inner)/(2*len(X))
def gradientDescent(X, y, theta, alpha, iters):
temp = np.matrix(np.zeros(theta.shape))
parameters = int(theta.ravel().shape[1])
cost = np.zeros(iters)
for i in range(iters):
error = (X * theta.T) - y
for j in range(parameters):
term = np.multiply(error, X[:,j])
temp[0,j] = theta[0,j] - ((alpha / len(X)) * np.sum(term))
theta = temp
cost[i] = computerCost(X, y, theta)
return theta, cost6、使用 sklearn 实现线性回归模型
scikit-learn 是 Python 中最常用的机器学习库,使用它可以非常方便地实现线性回归。
✅ 基本步骤如下:
- 导入模型类
LinearRegression - 拆分特征和标签
- 拟合模型
- 查看参数 / 进行预测 / 评估模型
📦 示例代码:
假设有一个ex1data1.txt文件,里面包含了房屋的面积,卧室数
python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
# 解决plt中文乱码问题
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体为黑体
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
#加载数据
df=pd.read_csv("C:\\Users\\s1597\\Desktop\\Python\\Machine Learning\\Linear_regression\\ex1data2.txt")
#分离特征和标签
X=df.iloc[:,0:2].values # 特征:前两列
y=df.iloc[:,2].values # 标签:第三列
#df.iloc[:,0:2]表示取出前两列数据,df.iloc[:,2]表示取出第三列数据,
# iloc是pandas中用于按位置索引的函数,:表示取所有行,
# 0:2表示取第0列到第2列(不包括第2列),2表示取第2列数据
#创建模型
model=LinearRegression()
model.fit(X,y)
#输出模型参数
print("截距:", model.intercept_)
print("系数:", model.coef_)
#进行预测
y_pred=model.predict(X)
# 预测值与实际值对比散点图
plt.figure(figsize=(8, 6))
plt.scatter(y, y_pred, color='blue', label='预测 vs 实际')
plt.plot([y.min(), y.max()], [y.min(), y.max()], color='red', linestyle='--', label='理想预测线')
plt.xlabel('实际房价')
plt.ylabel('预测房价')
plt.title('线性回归预测效果对比图')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()7、numpy中的切片
Xn,:是取第1维中下标为n的元素的所有值
X1,:即取第一维中下标为1的元素的所有值
X:,0就是取所有行的第0个数据,
X:,1 就是取所有行的第1个数据
X:, m:n,即取所有数据的第m到n-1列数据,含左不含右
8、特征缩放(Feature Scaling)
在机器学习中,不同特征的数值范围差异过大(如面积 vs 卧室数量)时,容易导致模型训练缓慢或收敛不稳定。
✅ 解决方法:标准化(Z-score Normalization)
将所有特征缩放为均值为 0、标准差为 1 的数据:
x ′ = x − μ σ x' = \frac{x - \mu}{\sigma} x′=σx−μ
其中:
- x x x 是原始值
- μ \mu μ 是该特征的均值
- σ \sigma σ 是该特征的标准差
📦 sklearn 实现:
python
from sklearn.preprocessing import StandardScaler
# 初始化缩放器
scaler = StandardScaler()
# 对特征进行缩放
X_scaled = scaler.fit_transform(X)
# 使用缩放后的数据训练模型
model_scaled = LinearRegression()
model_scaled.fit(X_scaled, y)
# 预测 & 评估
y_pred_scaled = model_scaled.predict(X_scaled)
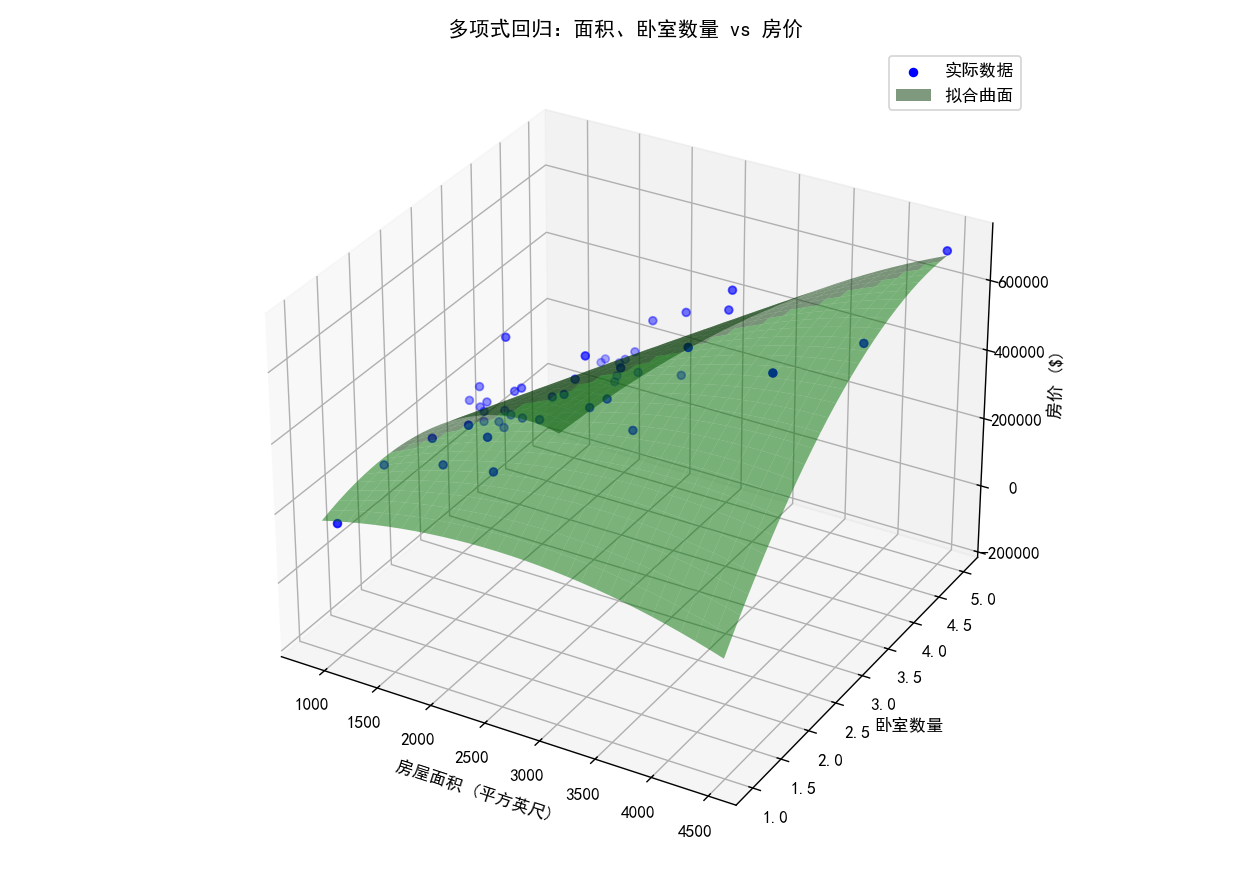
print("缩放后 MSE:", mean_squared_error(y, y_pred_scaled))8、使用面积和卧室数量的多项式回归
在本节中,我们将使用 房屋面积 和 卧室数量 作为特征,构造一个 多项式回归模型,以捕捉更复杂的房价趋势。
✅ 目标:
- 使用 房屋面积 和 卧室数量 作为输入特征,构建一个多项式回归模型。
- 使用
PolynomialFeatures类来扩展特征,并加入更高次方的特征。
📦 代码实现:
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler, PolynomialFeatures
from sklearn.linear_model import LinearRegression
# 解决plt中文乱码问题
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体为黑体
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
# 1. 加载数据集
data = np.loadtxt("C:\\Users\\s1597\\Desktop\\Python\\Machine Learning\\Linear_regression\\ex1data2.txt", delimiter=",")
X = data[:, 0:2] # 面积和卧室数量
y = data[:, 2] # 房价
# 2. 特征缩放
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 3. 多项式特征构造(如:x1^2, x2^2, x1*x2)
poly = PolynomialFeatures(degree=2, include_bias=False)
X_poly = poly.fit_transform(X_scaled)
# 4. 拟合线性回归模型
model = LinearRegression()
model.fit(X_poly, y)
# 5. 预测房价
y_pred = model.predict(X_poly)
# 6. 可视化:真实值 vs 预测值的三维图
# 创建网格数据用于绘制预测的表面
x_range = np.linspace(X[:, 0].min(), X[:, 0].max(), 30)
y_range = np.linspace(X[:, 1].min(), X[:, 1].max(), 30)
x_grid, y_grid = np.meshgrid(x_range, y_range)
# 转换网格数据为多项式特征
grid_points = np.column_stack([x_grid.ravel(), y_grid.ravel()])
grid_scaled = scaler.transform(grid_points) # 缩放网格数据
grid_poly = poly.transform(grid_scaled) # 转换为多项式特征
# 使用模型对网格数据进行预测
z_grid = model.predict(grid_poly).reshape(x_grid.shape)
# 绘制三维图
fig = plt.figure(figsize=(10, 7))
ax = fig.add_subplot(111, projection='3d')
# 绘制实际数据点
ax.scatter(X[:, 0], X[:, 1], y, color='blue', label='实际数据')
# 绘制预测表面
ax.plot_surface(x_grid, y_grid, z_grid, color='green', alpha=0.5, label='拟合曲面')
# 设置轴标签
ax.set_xlabel('房屋面积 (平方英尺)')
ax.set_ylabel('卧室数量')
ax.set_zlabel('房价 ($)')
ax.set_title('多项式回归:面积、卧室数量 vs 房价')
# 显示图例
ax.legend()
# 显示图像
plt.tight_layout()
plt.show()代码运行结果