每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/

Meta旗下的Llama 4模型最近在AI圈内掀起了一阵小风波。特别是在提交定制版Llama 4参加LM Arena评测之后,透明度问题引起了不少质疑。尤其是那款名叫"Llama-4-Maverick-03-26-Experimental"的模型,被曝光是经过偏好微调的,但Meta一开始并没有明说。公司生成式AI副总裁Ahmad Al-Dahle随即出面否认了"人为提高评分"的传闻。
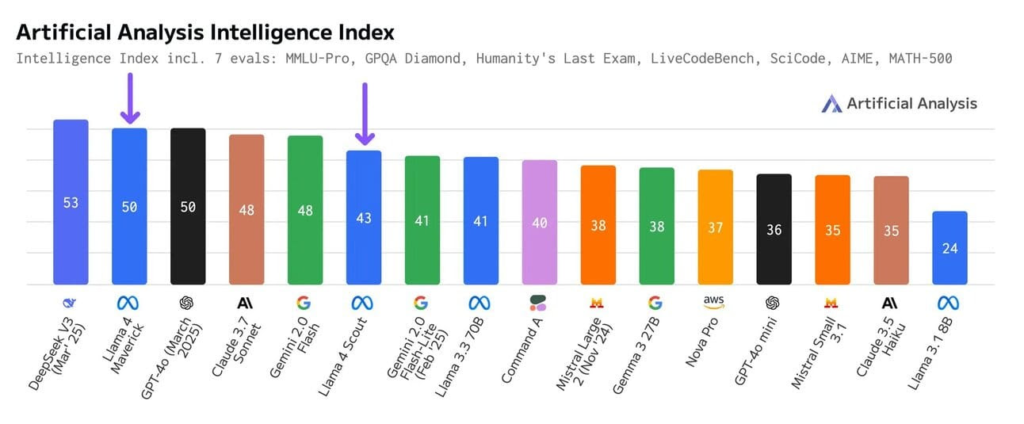
LM Arena随后火速回应,不仅公布了超2000场对战记录,还指出评测中风格和语气对结果产生了较大影响。为了保障公正性,他们同步更新了排行榜规则,强调测试结果必须可复现、可信赖。《Artificial Analysis》也同步调整了旗下"Llama 4智能指数",对Scout和Maverick两个模型的得分进行了重新修订,纠正了Meta在MMLU Pro和GPQA Diamond测试中的夸张成绩。
从硬实力来看,Llama 4的Maverick和Scout在推理、编程、数学等方面展现出强劲表现,甚至一度领先Claude 3.7和GPT-4o-mini等劲敌。其中,Maverick拿下49分,Scout紧随其后获得36分。不过一旦进入"长文本任务",这两位选手就有点吃力了------Maverick仅完成了28.1%,而Scout更是只有15.6%。Meta方面则表示,当前模型仍处于持续优化阶段,后续还会有调整。
值得一提的是,NVIDIA也加入了这场性能提升大战,用最新的Blackwell B200 GPU给Llama 4打上"加速器"。借助TensorRT-LLM技术,这批模型现在能以每秒超4万tokens的速度飞奔,处理文档摘要和图文理解时几乎"光速响应",多模态、多语种能力也不容小觑。
至于ARC Prize方面最新放出的评估数据,Maverick和Scout的表现可就比较"冷静"了------在ARC-AGI测试中,Maverick在第一阶段仅达成4.38%的完成率,第二阶段甚至挂零;Scout的数据则更"保守",分别为0.5%和0%。成本虽低,效果还得看后续进化。