目录
[PyTorch 池化 API](#PyTorch 池化 API)
[CIFAR10 数据集](#CIFAR10 数据集)
一、图像基础知识
图像基本概念
图像是由像素点组成的,每个像素点的取值范围为: 0, 255 。像素值越接近于0,颜色越暗,接近于黑色;像素值越接近于255,颜色越亮,接近于白色。
在深度学习中,我们使用的图像大多是彩色图,彩色图由RGB3个通道组成,如下图所示
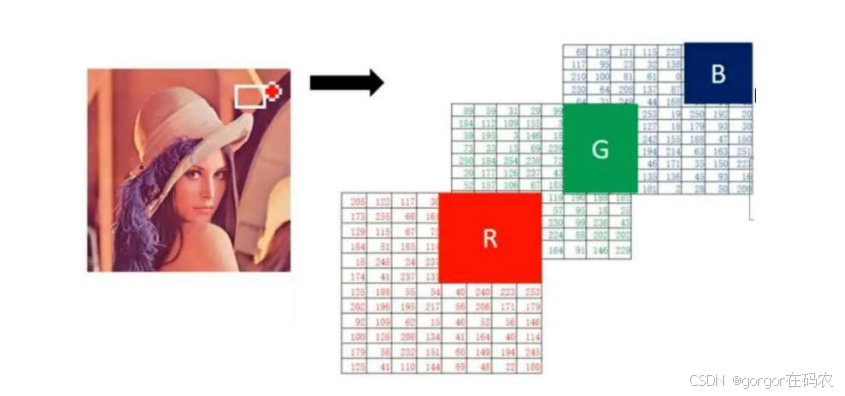
图像的加载
使用 matplotlib 库来实际理解下上面讲解的图像知识。
python
import numpy as np
import matplotlib.pyplot as plt
# 像素值的理解
def test01():
# 全0数组是黑色的图像
img = np.zeros([200, 200, 3])
# 展示图像
plt.imshow(img)
plt.show()
# 全255数组是白色的图像
img = np.full([200, 200, 3], 255)
# 展示图像
plt.imshow(img)
plt.show()
test01()
python
# 图像的加载
def test02():
# 读取图像
img = plt.imread("data/yy.jpg")
# 图像形状 高,宽,通道
print("图像的形状(H, W, C):\n", img.shape)
# 展示图像
plt.imshow(img)
plt.axis("off")
plt.show()
test02()
二、CNN概述
CNN概述
卷积神经网络(Convolutional Neural Network)是含有卷积层的神经网络. 卷积层的作用就是用来自动学习、提取图像的特征。
CNN网络主要由三部分构成:卷积层、池化层和全连接层构成:
- 卷积层负责提取图像中的局部特征;
- 池化层用来大幅降低参数量级(降维);
- 全连接层用来输出想要的结果。

三、卷积层
卷积计算
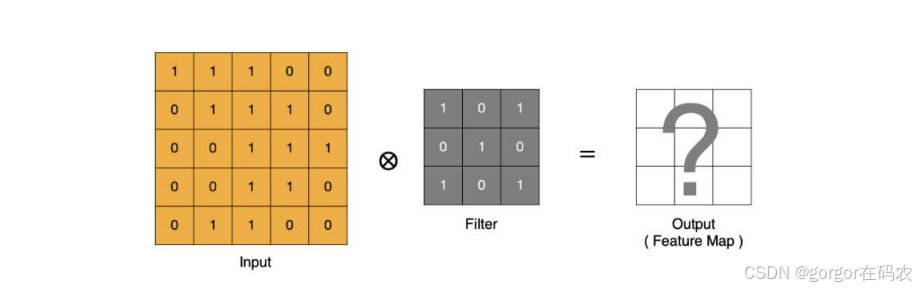
- input 表示输入的图像
- filter 表示卷积核, 也叫做卷积核(滤波矩阵)
- input 经过 filter 得到输出为最右侧的图像,该图叫做特征图
卷积运算本质上就是在卷积核和输入数据的局部区域间做点积。
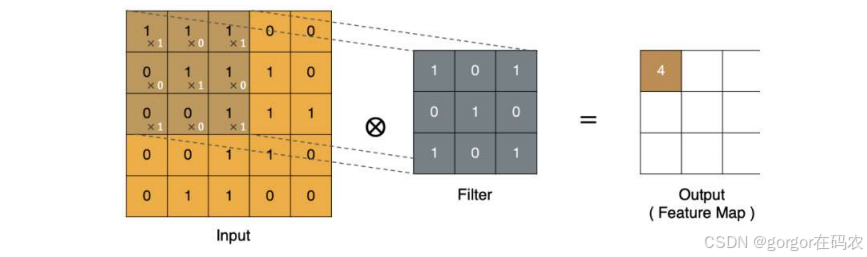
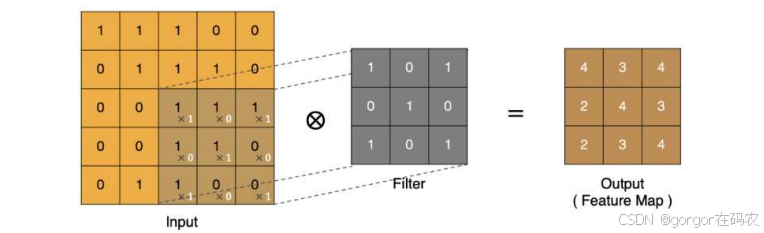
最终的特征图结果为 :
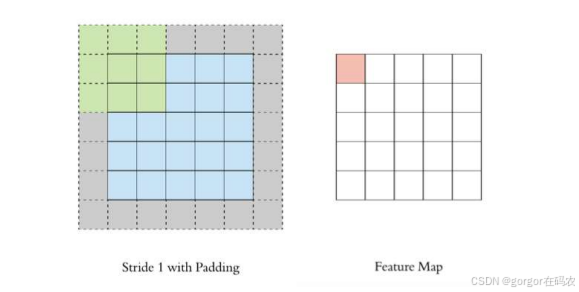
Padding
通过上面的卷积计算过程,最终的特征图比原始图像小很多,如果想要保持经过卷积后的图像大小不变, 可以在原图周围添加 padding 来实现.
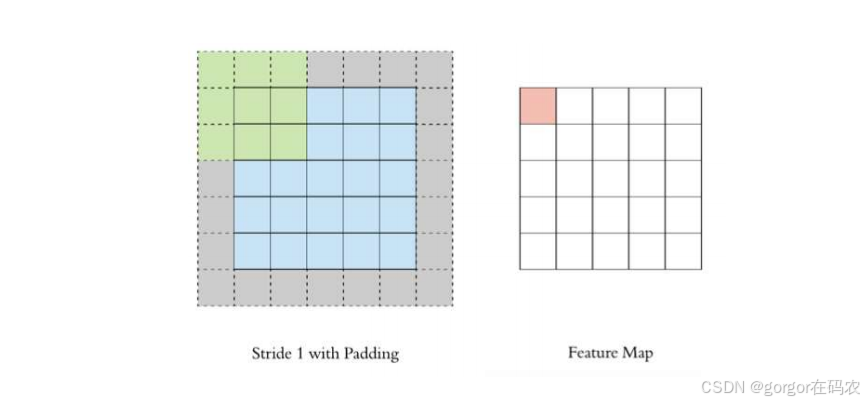
Stride
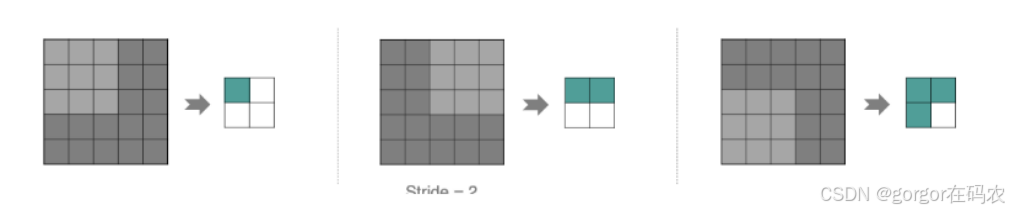
按照步长为 1 来移动卷积核,计算特征图如下所示:

如果把 Stride 增大为 2 ,也是可以提取特征图的,如下图所示:
多通道卷积计算
实际中的图像都是多个通道组成的,我们怎么计算卷积呢?
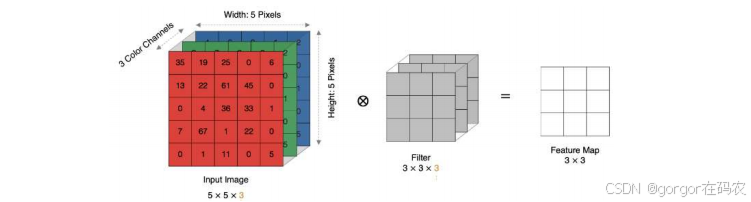
如下图所示:

当使用多个卷积核时 , 应该怎么进行特征提取呢 ?
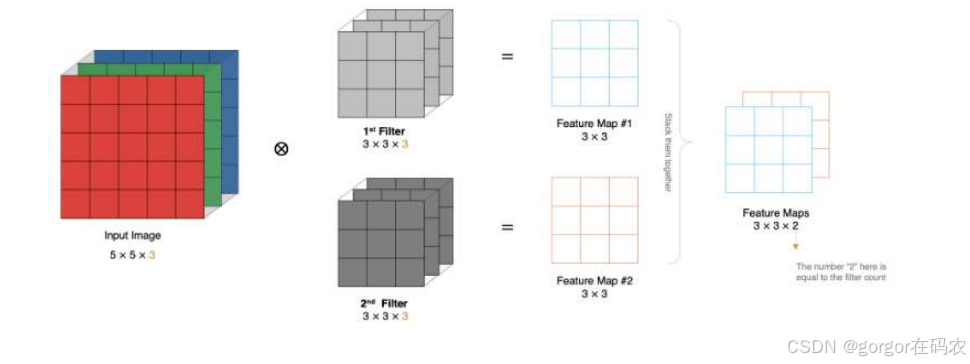
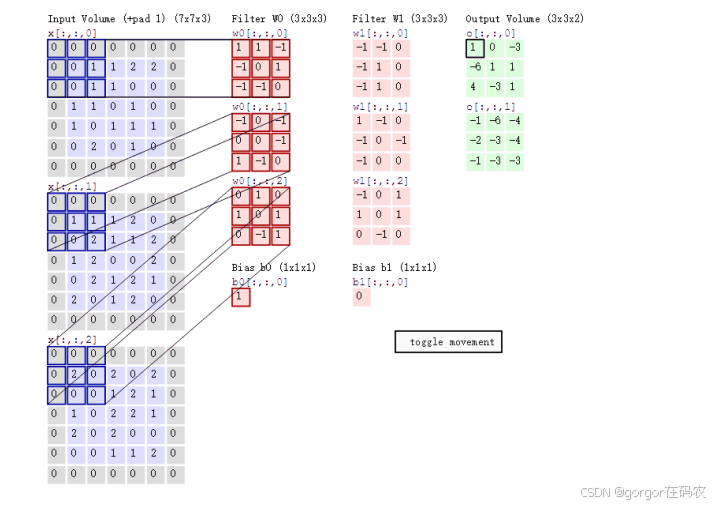
特征图大小
输出特征图的大小与以下参数息息相关 :
- size: 卷积核/过滤器大小,一般会选择为奇数,比如有 1*1 、3*3、5*5
- Padding: 零填充的方式
- Stride: 步长
那计算方法如下图所示 :
- 输入图像大小: W x W
- 卷积核大小: F x F
- Stride: S
- Padding: P
- 输出图像大小: N x N
特征图大小计算方法
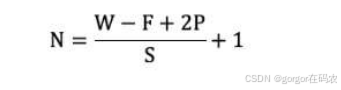
以下图为例 :
- 图像大小: 5 x 5
- 卷积核大小: 3 x 3
- Stride: 1
- Padding: 1
- (5 - 3 + 2) / 1 + 1 = 5, 即得到的特征图大小为: 5 x 5
PyTorch卷积层API
conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
"""
参数说明:
in_channels: 输入通道数,
out_channels: 输出通道,也可以理解为卷积核 kernel 的数量
kernel_size :卷积核的高和宽设置,一般为 3,5,7...
stride :卷积核移动的步长
padding :在四周加入 padding 的数量,默认补 0
"""
python
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
def test():
# 读取图像, 形状: (640, 640, 3)
img = plt.imread('data/yy.jpg')
plt.imshow(img)
plt.axis('off')
plt.show()
# 构建卷积层
# out_channels表示卷积核个数
# 修改out_channels,stride,padding观察特征图的变化情况
conv = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3, stride=2, padding=0)
# 输入形状: (BatchSize, Channel, Height, Width)
# mg形状: torch.Size([3, 640, 640])
img = torch.tensor(img).permute(2, 0, 1)
# img 形状: torch.Size([1, 3, 640, 640])
img = img.unsqueeze(0)
# 将图像送入卷积层中
feature_map_img = conv(img.to(torch.float32))
# 打印特征图的形状
print(feature_map_img.shape)
if __name__ == '__main__':
test()四、池化层
池化层计算
池化层 (Pooling) 降低维度 , 缩减模型大小,提高计算速度。
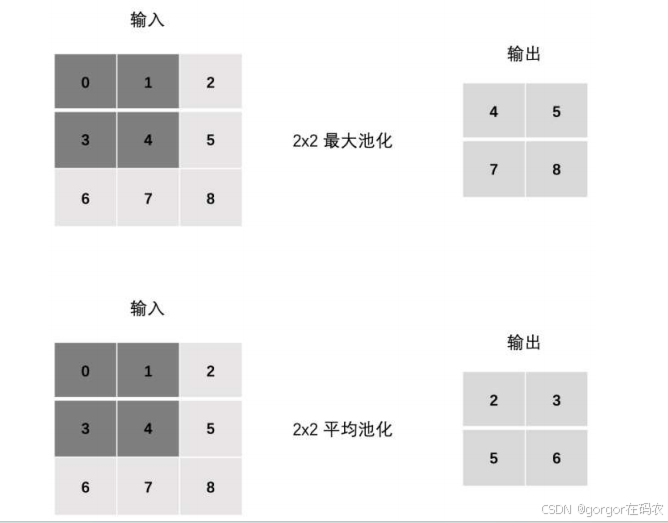
Stride
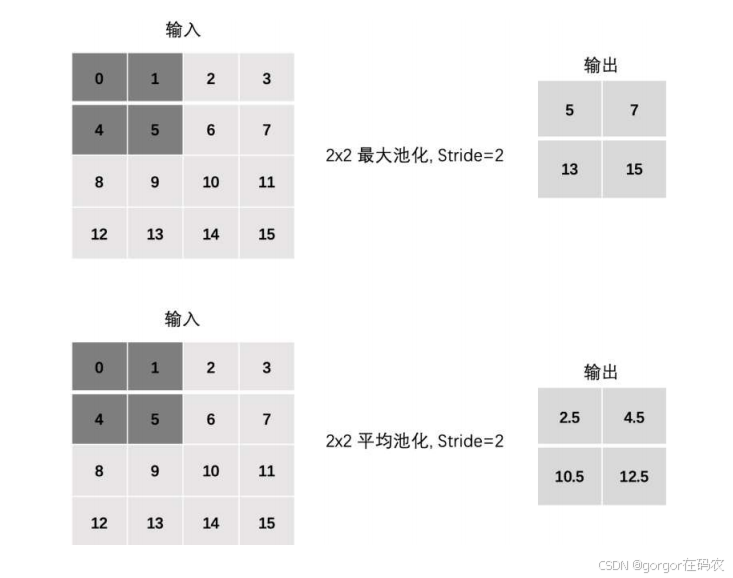
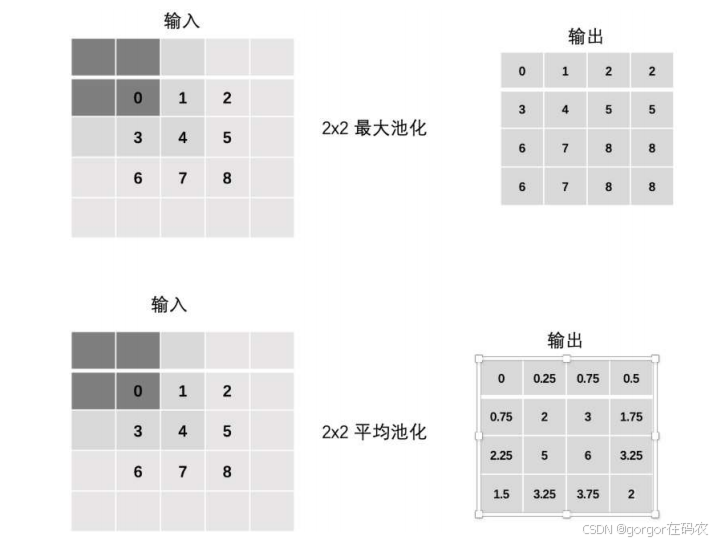
Padding
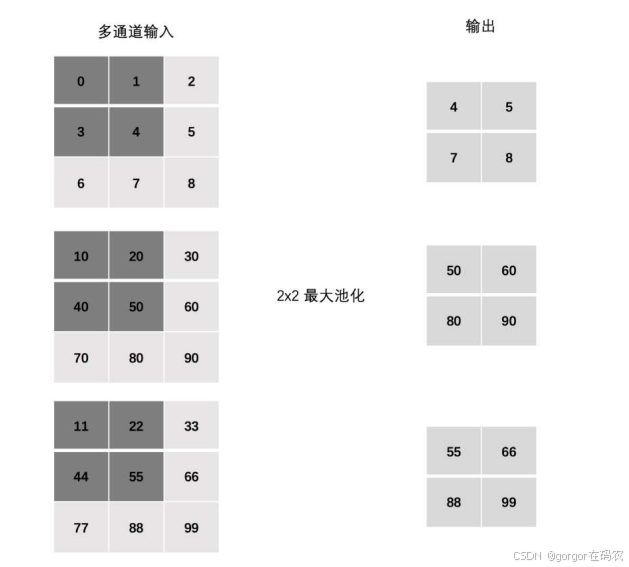
多通道池化层计算
PyTorch池化API
最大池化
nn.MaxPool2d(kernel_size=2, stride=2, padding=1)
平均池化
nn.AvgPool2d(kernel_size=2, stride=1, padding=0)
python
import torch
import torch.nn as nn
"""
1. 单通道池化
"""
def test01():
# 定义输入输数据 【1,3,3 】
inputs = torch.tensor([[[0, 1, 2], [3, 4, 5], [6, 7, 8]]]).float()
# 修改stride,padding观察效果
# 1. 最大池化
polling = nn.MaxPool2d(kernel_size=2, stride=1, padding=0)
output = polling(inputs)
print("最大池化:\n", output)
# 2. 平均池化
polling = nn.AvgPool2d(kernel_size=2, stride=1, padding=0)
output = polling(inputs)
print("平均池化:\n", output)
"""
2. 多通道池化
"""
def test02():
# 定义输入输数据 【3,3,3 】
inputs = torch.tensor([[[0, 1, 2], [3, 4, 5], [6, 7, 8]],
[[10, 20, 30], [40, 50, 60], [70, 80, 90]],
[[11, 22, 33], [44, 55, 66], [77, 88, 99]]]).float()
# 最大池化
polling = nn.MaxPool2d(kernel_size=2, stride=1, padding=0)
output = polling(inputs)
print("多通道池化:\n", output)
if __name__ == '__main__':
test01()
test02()输出结果
最大池化:
tensor(\[\[4., 5.,
7., 8.]])
平均池化:
tensor(\[\[2., 3.,
5., 6.]])
多通道池化:
tensor(\[\[ 4., 5.,
7., 8.],
\[50., 60.,
80., 90.],
\[55., 66.,
88., 99.]])
五、图像分类案例
首先我们导入一下工具包 :
python
import torch
import torch.nn as nn
from torchvision.datasets import CIFAR10
from torchvision.transforms import ToTensor
from torchvision.transforms import Compose
import torch.optim as optim
from torch.utils.data import DataLoader
import time
import matplotlib.pyplot as plt
from torchsummary import summary
BATCH_SIZE = 8CIFAR10****数据集
CIFAR-10数据集 5 万张训练图像、 1 万张测试图像、 10 个类别、每个类别有 6k 个图像,图像大小 32 × 32 × 3 。下图列举了10 个类,每一类随机展示了 10 张图片:

PyTorch 中的 torchvision.datasets 计算机视觉模块封装了 CIFAR10 数据集 , 使用方法如下 :
python
# 1. 数据集基本信息
def create_dataset():
# 加载数据集:训练集数据和测试数据
train = CIFAR10(root='data', train=True, transform=Compose([ToTensor()]), download=True)
valid = CIFAR10(root='data', train=False, transform=Compose([ToTensor()]), download=True)
# 返回数据集结果
return train, valid
if __name__ == '__main__':
# 数据集加载
train_dataset, valid_dataset = create_dataset()
# 数据集类别
print("数据集类别:", train_dataset.class_to_idx)
# 数据集中的图像数据
print("训练集数据集:", train_dataset.data.shape)
print("测试集数据集:", valid_dataset.data.shape)
# 图像展示
plt.figure(figsize=(2, 2))
plt.imshow(train_dataset.data[1])
plt.title(train_dataset.targets[1])
plt.show()搭建图像分类网络
我们要搭建的网络结构如下 :
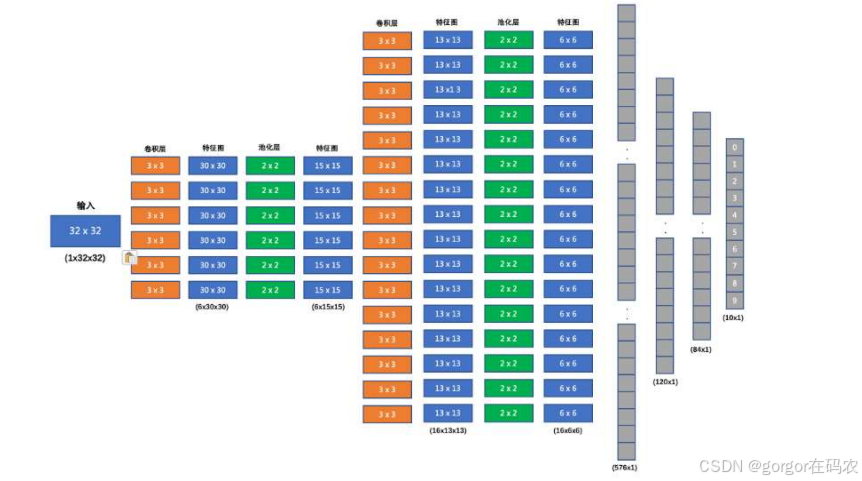
我们要搭建的网络结构如下 :
- 输入形状: 32x32
- 第一个卷积层输入 3 个 Channel, 输出 6 个 Channel, Kernel Size 为: 3x3
- 第一个池化层输入 30x30, 输出 15x15, Kernel Size 为: 2x2, Stride 为: 2
- 第二个卷积层输入 6 个 Channel, 输出 16 个 Channel, Kernel Size 为 3x3
- 第二个池化层输入 13x13, 输出 6x6, Kernel Size 为: 2x2, Stride 为: 2
- 第一个全连接层输入 576 维, 输出 120 维
- 第二个全连接层输入 120 维, 输出 84 维
- 最后的输出层输入 84 维, 输出 10 维
我们在每个卷积计算之后应用 relu 激活函数来给网络增加非线性因素。
构建网络代码实现如下:
python
# 2.模型构建
class ImageClassification(nn.Module):
# 定义网络结构
def __init__(self):
super(ImageClassification, self).__init__()
# 定义网络层:卷积层+池化层
self.conv1 = nn.Conv2d(3, 6, stride=1, kernel_size=3)
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2 = nn.Conv2d(6, 16, stride=1, kernel_size=3)
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
# 全连接层
self.linear1 = nn.Linear(576, 120)
self.linear2 = nn.Linear(120, 84)
self.out = nn.Linear(84, 10)
# 定义前向传播
def forward(self, x):
# 卷积+relu+池化
x = torch.relu(self.conv1(x))
x = self.pool1(x)
# 卷积+relu+池化
x = torch.relu(self.conv2(x))
x = self.pool2(x)
# 将特征图做成以为向量的形式:相当于特征向量
x = x.reshape(x.size(0), -1)
# 全连接层
x = torch.relu(self.linear1(x))
x = torch.relu(self.linear2(x))
# 返回输出结果
return self.out(x)模型结构为:
python
if __name__ == '__main__':
# 模型实例化
model = ImageClassification()
summary(model,input_size=(3,32,32),batch_size=1)编写训练函数
在训练时,使用多分类交叉熵损失函数, Adam 优化器 . 具体实现代码如下 :
python
# 3.训练模型
def train(model,train_dataset):
criterion = nn.CrossEntropyLoss() # 构建损失函数
optimizer = optim.Adam(model.parameters(), lr=1e-3) # 构建优化方法
epoch = 100 # 训练轮数
for epoch_idx in range(epoch):
# 构建数据加载器
dataloader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
sam_num = 0 # 样本数量
total_loss = 0.0 # 损失总和
start = time.time() # 开始时间
# 遍历数据进行网络训练
for x, y in dataloader:
output = model(x)
loss = criterion(output, y) # 计算损失
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播
optimizer.step() # 参数更新
total_loss += loss.item() # 统计损失和
sam_num += 1
print('epoch:%2s loss:%.5f time:%.2fs' %(epoch_idx + 1,total_loss / sam_num,time.time() - start))
# 模型保存
torch.save(model.state_dict(), 'data/image_classification.pth')调用训练方法进行模型训练如下 :
python
if __name__ == '__main__':
# 数据集加载
train_dataset, valid_dataset = create_dataset()
# 模型实例化
model = ImageClassification()
# 模型训练
train(model,train_dataset)编写预测函数
加载训练好的模型,对测试集中的 1 万条样本进行预测,查看模型在测试集上的准确率 .
python
def test(valid_dataset):
# 构建数据加载器
dataloader = DataLoader(valid_dataset, batch_size=BATCH_SIZE, shuffle=True)
# 加载模型并加载训练好的权重
model = ImageClassification()
model.load_state_dict(torch.load('data/image_classification.pth'))
model.eval()
# 计算精度
total_correct = 0
total_samples = 0
# 遍历每个batch的数据,获取预测结果,计算精度
for x, y in dataloader:
output = model(x)
total_correct += (torch.argmax(output, dim=-1) == y).sum()
total_samples += len(y)
# 打印精度
print('Acc: %.2f' % (total_correct / total_samples))总体代码
python
import torch
import torch.nn as nn
from torchvision.datasets import CIFAR10
from torchvision.transforms import ToTensor
from torchvision.transforms import Compose
import torch.optim as optim
from torch.utils.data import DataLoader
import time
import matplotlib.pyplot as plt
from torchsummary import summary
BATCH_SIZE = 8
# 1. 数据集基本信息
def create_dataset():
# 加载数据集:训练集数据和测试数据
train = CIFAR10(root='data', train=True, transform=Compose([ToTensor()]), download=True)
valid = CIFAR10(root='data', train=False, transform=Compose([ToTensor()]), download=True)
# 返回数据集结果
return train, valid
# if __name__ == '__main__':
# # 数据集加载
# train_dataset, valid_dataset = create_dataset()
# # 数据集类别
# print("数据集类别:", train_dataset.class_to_idx)
# # 数据集中的图像数据
# print("训练集数据集:", train_dataset.data.shape)
# print("测试集数据集:", valid_dataset.data.shape)
# # 图像展示
# plt.figure(figsize=(2, 2))
# plt.imshow(train_dataset.data[1])
# plt.title(train_dataset.targets[1])
# plt.show()
# 2.模型构建
class ImageClassification(nn.Module):
# 定义网络结构
def __init__(self):
super(ImageClassification, self).__init__()
# 定义网络层:卷积层+池化层
self.conv1 = nn.Conv2d(3, 6, stride=1, kernel_size=3)
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2 = nn.Conv2d(6, 16, stride=1, kernel_size=3)
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
# 全连接层
self.linear1 = nn.Linear(576, 120)
self.linear2 = nn.Linear(120, 84)
self.out = nn.Linear(84, 10)
# 定义前向传播
def forward(self, x):
# 卷积+relu+池化
x = torch.relu(self.conv1(x))
x = self.pool1(x)
# 卷积+relu+池化
x = torch.relu(self.conv2(x))
x = self.pool2(x)
# 将特征图做成以为向量的形式:相当于特征向量
x = x.reshape(x.size(0), -1)
# 全连接层
x = torch.relu(self.linear1(x))
x = torch.relu(self.linear2(x))
# 返回输出结果
return self.out(x)
# 3.训练模型
def train(model,train_dataset):
criterion = nn.CrossEntropyLoss() # 构建损失函数
optimizer = optim.Adam(model.parameters(), lr=1e-3) # 构建优化方法
epoch = 100 # 训练轮数
for epoch_idx in range(epoch):
# 构建数据加载器
dataloader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
sam_num = 0 # 样本数量
total_loss = 0.0 # 损失总和
start = time.time() # 开始时间
# 遍历数据进行网络训练
for x, y in dataloader:
output = model(x)
loss = criterion(output, y) # 计算损失
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播
optimizer.step() # 参数更新
total_loss += loss.item() # 统计损失和
sam_num += 1
print('epoch:%2s loss:%.5f time:%.2fs' %(epoch_idx + 1,total_loss / sam_num,time.time() - start))
# 模型保存
torch.save(model.state_dict(), 'data/image_classification.pth')
# 4.预测模型
def test(valid_dataset):
# 构建数据加载器
dataloader = DataLoader(valid_dataset, batch_size=BATCH_SIZE, shuffle=True)
# 加载模型并加载训练好的权重
model = ImageClassification()
model.load_state_dict(torch.load('data/image_classification.pth'))
model.eval()
# 计算精度
total_correct = 0
total_samples = 0
# 遍历每个batch的数据,获取预测结果,计算精度
for x, y in dataloader:
output = model(x)
total_correct += (torch.argmax(output, dim=-1) == y).sum()
total_samples += len(y)
# 打印精度
print('Acc: %.2f' % (total_correct / total_samples))
if __name__ == '__main__':
#1.数据集加载
train_dataset, valid_dataset = create_dataset()
#2.模型实例化
model = ImageClassification()
#3.模型训练
train(model, train_dataset)
#4.预测模型
test(valid_dataset)