一、 引言
在智能监控、自动驾驶、人机交互等领域,准确理解视频中的动作序列至关重要。然而,传统方法依赖复杂的视觉模型,计算成本高且难以捕捉长时依赖。近期,一项名为 Semantic2Graph 的研究通过图神经网络(GNN)和多模态特征融合,在视频动作分割任务中取得了显著突破,甚至超越现有最优模型!

二、 传统方法的痛点
传统视频动作分割模型(如3D-CNN、Transformer)通常需要堆叠深层网络或引入注意力机制来提取时空特征。这些方法虽然有效,但存在两大问题:
-
计算成本高:长视频处理需要大量计算资源。
-
长时依赖建模难:相邻帧的关系容易捕捉,但跨越多帧的语义关联(如"切菜"与"装盘")难以建模。
而 Semantic2Graph 另辟蹊径,将视频转化为图结构,用"节点分类"替代传统序列建模,大幅降低了计算复杂度。
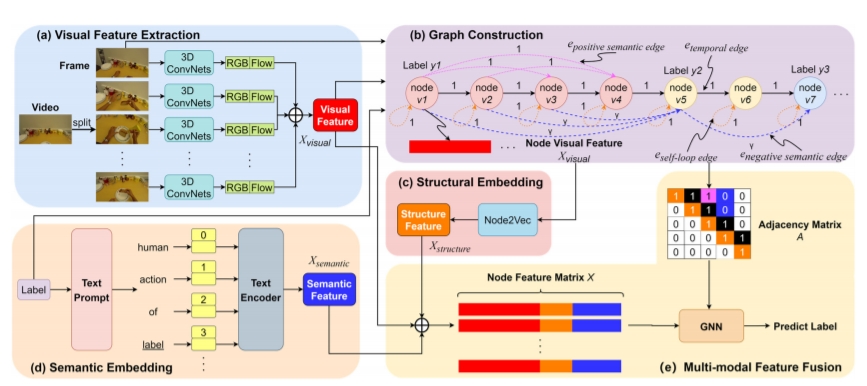
三 、Semantic2Graph的核心创新
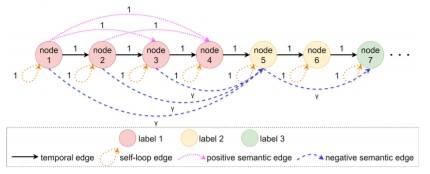
- 视频变图:三类边捕捉精细关系
-
时间边(Temporal Edges):连接相邻帧节点,保留时间顺序。
-
语义边(Semantic Edges):根据动作标签的相似性,跨帧连接相同或不同动作的节点。例如,所有"切菜"帧通过语义边直接关联,无需逐帧传递信息。
-
自循环边(Self-Loop):保留节点自身特征,防止信息丢失。
- 多模态特征融合:视觉+结构+语义
-
视觉特征:通过I3D模型提取RGB和光流信息。
-
结构特征:利用Node2Vec编码节点邻域关系。
-
语义特征:基于文本提示(如"切菜"扩展为"人类正在切菜的视频"),通过CLIP模型生成语义嵌入。
三类特征拼接后输入GNN,实现高效融合。
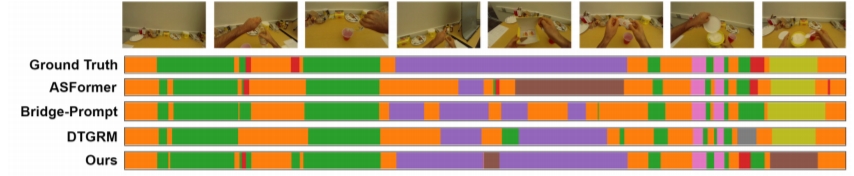
四 、实验结果:全面超越SOTA
在 GTEA 和 50Salads 两个经典数据集上,Semantic2Graph的表现亮眼:
-
准确率(Acc):GTEA达89.8%,50Salads达88.6%,比主流模型(如ASFormer、Bridge-Prompt)提升约10%。
-
计算效率:模型参数量仅0.27M,推理速度达0.98ms/帧,比传统视觉模型快20%以上。
五 、实际应用与未来展望
-
智能监控:实时识别异常动作(如跌倒、打架)。
-
自动驾驶:精准理解行人意图,提升决策安全性。
-
人机交互:让机器人更自然地模仿人类动作序列。
未来,研究团队计划将Semantic2Graph扩展至动作验证、子图提取等任务,并探索动态图构建以适应复杂场景。
六、 结语
Semantic2Graph通过"以图代序"的创新思路,为视频理解提供了轻量高效的解决方案。随着多模态技术与图神经网络的深度结合,AI对动态世界的感知能力将迈上新台阶。
论文链接