基于线性回归模型的汽车燃油效率预测
- 1.作者介绍
- 2.线性回归介绍
-
- [2.1 线性回归简介](#2.1 线性回归简介)
- [2.2 线性回归应用场景](#2.2 线性回归应用场景)
- 3.基于线性回归模型的汽车燃油效率预测实验
- 4.问题分析
基于线性回归模型的汽车燃油效率预测
1.作者介绍
郝颖,女,西安工程大学电子信息学院,2024级研究生
研究方向:机器视觉与人工智能
电子邮件:1418293433@qq.com
王晓睿,男,西安工程大学电子信息学院,2024级研究生,张宏伟人工智能课题组
研究方向:智能视觉检测与工业自动化技术
电子邮件:3234002295@qq.com
2.线性回归介绍
2.1 线性回归简介
线性回归是一种用于建模自变量(输入变量)与因变量(输出变量)之间线性关系的统计方法。通过拟合一条直线来预测因变量的值,旨在最大程度地反映数据点的趋势。
(1)单变量线性回归:描述一个自变量和目标变量之间的线性关系。
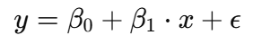
(2)多变量线性回归:拥有多个自变量的回归模型。
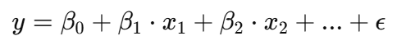
(3)R2(判定系数):用来衡量模型的拟合优度,R2的值越接近1,模型的拟合效果越好。
线性回归的核心目标是找到一组最佳系数,使得预测值与实际值之间的误差最小化。
2.2 线性回归应用场景
线性回归多应用于经济学、医学研究、工程领域等,下面给出四个应用案例。
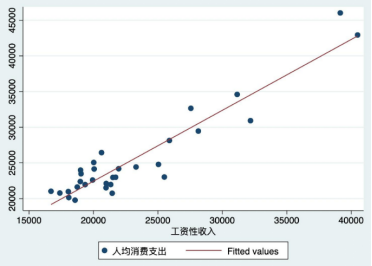
研究消费收入与消费

临床预测模型
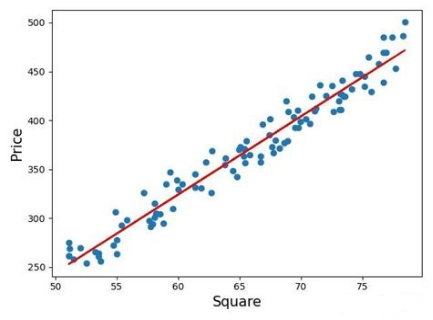
电器工程中负载预测
结构应力-应变分析
3.基于线性回归模型的汽车燃油效率预测实验
3.1 Auto MPG Data Set数据集
MPG汽车油耗数据集源自1983年的美国统计协会博览会,包含398个样本,9个特征,用于回归任务。
下载链接:seaborn-data/mpg.csv at master · mwaskom/seaborn-data · GitHub
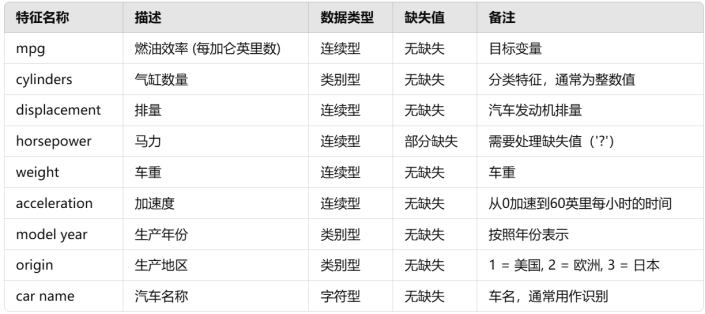
mpg,miles per gallon即油耗,这个数据集来自卡内基梅隆大学维护的StatLib库。1983年美国统计协会博览会使用了该数据集。这个数据集是对StatLib库中提供的数据集稍加修改的版本。根据Ross Quinlan(1993)在预测属性"mpg"中的使用,删除了 8 个原始实例,因为它们的"mpg"属性值未知。原始数据集在"auto-mpg.data-original"文件中。
3.2代码调试
1)导入必要库
python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error as mse
from matplotlib import rcParams2)配置字体
python
# 设置字体为 SimHei 以支持中文
rcParams['font.sans-serif'] = ['SimHei']
rcParams['axes.unicode_minus'] = False # 解决负号显示问题3)数据加载和预处理
python
path = 'auto-mpg.data'
columns = ["mpg", "cylinders", "displacement", "horsepower", "weight", "acceleration", "model year", "origin", "car name"]
cars = pd.read_csv(path, sep=r'\s+', names=columns, engine='python', on_bad_lines='skip')
cars = cars[cars.horsepower != '?']
cars['horsepower'] = cars['horsepower'].astype(float)4)单变量和多变量线性回归模型比较
python
# 单变量和多变量线性回归模型比较
print("\n==== 单变量和多变量线性回归模型比较 ====")
# 单变量线性回归
X = cars[['weight']]
Y = cars['mpg']
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=0)
lr = LinearRegression()
lr.fit(X_train, Y_train)
single_r2 = lr.score(X, Y)
print(f'单变量线性回归模型得分 (R²): {single_r2:.4f}')
print(f'单变量回归系数: {lr.coef_[0]:.4f}')
print(f'单变量截距: {lr.intercept_:.4f}')
# 多变量线性回归
features = ['weight', 'horsepower', 'displacement']
mul_lr = LinearRegression()
mul_lr.fit(cars[features], cars['mpg'])
cars['mpg_prediction'] = mul_lr.predict(cars[features])
multi_r2 = mul_lr.score(cars[features], cars['mpg'])
print(f'多变量线性回归模型得分 (R²): {multi_r2:.4f}')
print(f'多变量回归系数: {mul_lr.coef_}')
print(f'多变量截距: {mul_lr.intercept_:.4f}')5)比较输出
python
# 比较输出
improvement = (multi_r2 - single_r2) * 100
print(f'模型性能提升幅度: {improvement:.2f}%')6)训练集和测试集可视化比较
python
# 训练集和测试集可视化比较
plt.figure(figsize=(8, 6))
plt.scatter(X_train, Y_train, color='blue', label='训练数据', alpha=0.7)
plt.plot(X_train, lr.predict(X_train), color='red', linewidth=2, label='单变量回归线')
plt.xlabel('重量 (weight)', fontsize=14)
plt.ylabel('燃油效率 (mpg)', fontsize=14)
plt.title('单变量线性回归 - 训练集', fontsize=16)
plt.legend()
plt.grid(True, linestyle='--', alpha=0.5)
plt.show()
plt.figure(figsize=(8, 6))
plt.scatter(X_test, Y_test, color='green', label='测试数据', alpha=0.7)
plt.plot(X_test, lr.predict(X_test), color='red', linewidth=2, label='单变量回归线')
plt.xlabel('重量 (weight)', fontsize=14)
plt.ylabel('燃油效率 (mpg)', fontsize=14)
plt.title('单变量线性回归 - 测试集', fontsize=16)
plt.legend()
plt.grid(True, linestyle='--', alpha=0.5)
plt.show()7)多变量回归可视化
python
# 多变量回归可视化
fig, axes = plt.subplots(1, 3, figsize=(18, 6))
fig.suptitle("多变量线性回归效果", fontsize=20)
for ax, feature in zip(axes.flat, features):
ax.scatter(cars[feature], cars['mpg'], color='blue', alpha=0.7, label='真实值', edgecolors='k')
ax.scatter(cars[feature], cars['mpg_prediction'], color='red', alpha=0.7, label='预测值', edgecolors='k')
ax.set_title(f'{feature} 与 mpg', fontsize=16)
ax.set_xlabel(feature, fontsize=14)
ax.set_ylabel('mpg', fontsize=14)
ax.grid(True, linestyle='--', alpha=0.5)
ax.legend()
plt.tight_layout()
plt.show()3.3完整代码
python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error as mse
from matplotlib import rcParams
# 设置字体为 SimHei 以支持中文
rcParams['font.sans-serif'] = ['SimHei']
rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 数据加载和预处理
path = 'auto-mpg.data'
columns = ["mpg", "cylinders", "displacement", "horsepower", "weight", "acceleration", "model year", "origin", "car name"]
cars = pd.read_csv(path, sep=r'\s+', names=columns, engine='python', on_bad_lines='skip')
cars = cars[cars.horsepower != '?']
cars['horsepower'] = cars['horsepower'].astype(float)
# 单变量和多变量线性回归模型比较
print("\n==== 单变量和多变量线性回归模型比较 ====")
# 单变量线性回归
X = cars[['weight']]
Y = cars['mpg']
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=0)
lr = LinearRegression()
lr.fit(X_train, Y_train)
single_r2 = lr.score(X, Y)
print(f'单变量线性回归模型得分 (R²): {single_r2:.4f}')
print(f'单变量回归系数: {lr.coef_[0]:.4f}')
print(f'单变量截距: {lr.intercept_:.4f}')
# 多变量线性回归
features = ['weight', 'horsepower', 'displacement']
mul_lr = LinearRegression()
mul_lr.fit(cars[features], cars['mpg'])
cars['mpg_prediction'] = mul_lr.predict(cars[features])
multi_r2 = mul_lr.score(cars[features], cars['mpg'])
print(f'多变量线性回归模型得分 (R²): {multi_r2:.4f}')
print(f'多变量回归系数: {mul_lr.coef_}')
print(f'多变量截距: {mul_lr.intercept_:.4f}')
# 比较输出
improvement = (multi_r2 - single_r2) * 100
print(f'模型性能提升幅度: {improvement:.2f}%')
# 训练集和测试集可视化比较
plt.figure(figsize=(8, 6))
plt.scatter(X_train, Y_train, color='blue', label='训练数据', alpha=0.7)
plt.plot(X_train, lr.predict(X_train), color='red', linewidth=2, label='单变量回归线')
plt.xlabel('重量 (weight)', fontsize=14)
plt.ylabel('燃油效率 (mpg)', fontsize=14)
plt.title('单变量线性回归 - 训练集', fontsize=16)
plt.legend()
plt.grid(True, linestyle='--', alpha=0.5)
plt.show()
plt.figure(figsize=(8, 6))
plt.scatter(X_test, Y_test, color='green', label='测试数据', alpha=0.7)
plt.plot(X_test, lr.predict(X_test), color='red', linewidth=2, label='单变量回归线')
plt.xlabel('重量 (weight)', fontsize=14)
plt.ylabel('燃油效率 (mpg)', fontsize=14)
plt.title('单变量线性回归 - 测试集', fontsize=16)
plt.legend()
plt.grid(True, linestyle='--', alpha=0.5)
plt.show()
# 多变量回归可视化
fig, axes = plt.subplots(1, 3, figsize=(18, 6))
fig.suptitle("多变量线性回归效果", fontsize=20)
for ax, feature in zip(axes.flat, features):
ax.scatter(cars[feature], cars['mpg'], color='blue', alpha=0.7, label='真实值', edgecolors='k')
ax.scatter(cars[feature], cars['mpg_prediction'], color='red', alpha=0.7, label='预测值', edgecolors='k')
ax.set_title(f'{feature} 与 mpg', fontsize=16)
ax.set_xlabel(feature, fontsize=14)
ax.set_ylabel('mpg', fontsize=14)
ax.grid(True, linestyle='--', alpha=0.5)
ax.legend()
plt.tight_layout()
plt.show()3.4结果展示
1)代码运行结果
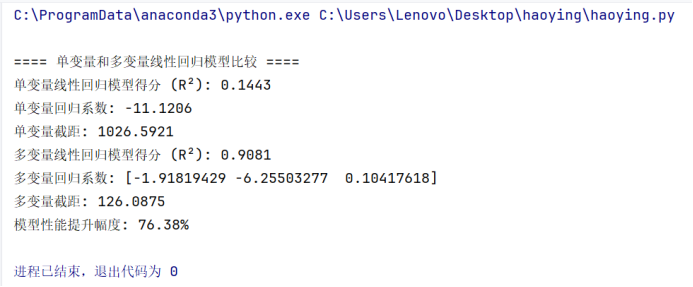
单变量模型对目标变量的解释能力较差,仅能解释14.43%的方差,多输入模型能够解释90.81%的数据方差,大大提高了对MPG的预测精度。多变量模型通过引入更多的特征
2)汽车属性与燃油效率关系,数据点越密集代表与燃油效率之间的相关性越高。,相较于单变量模型在性能上提升了 76.38%,性能提升显示了多变量回归在处理复杂数据关系时的优势。
3)单变量线性回归测试集和训练集回归线,其中模型的拟合效果不算特别理想,数据点的离散程度较大,表明单变量回归无法很好地描述数据的复杂性。
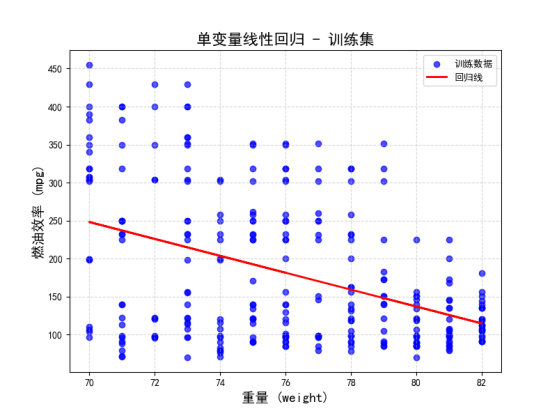
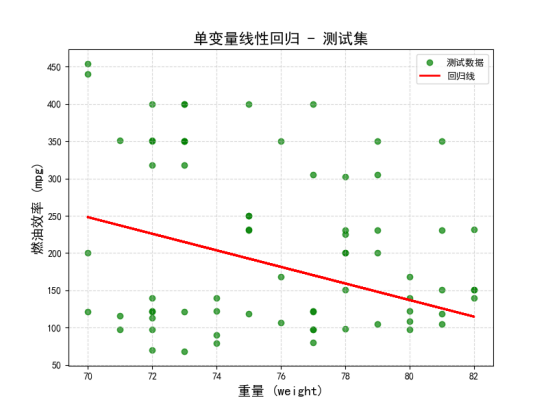
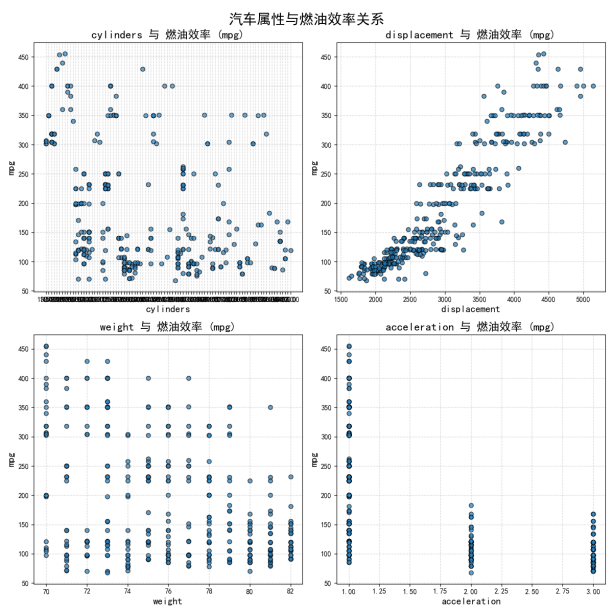
4)多变量线性回归效果,结果图表明多变量模型对传统燃油车基础参数具备解释力。
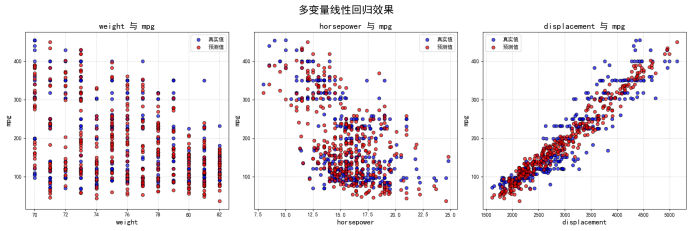
4.问题分析
1)数据处理问题
数据集的"horsepower"列存在无效数据'?',如果没有正确清理或转换成数值,会导致模型训练时错误。
2)可视化问题
散点图绘制未正确设置导致图表中数据点分布不合理或未正确配置字体或加载必要库,导致图表未正确显示。
3)数据集分割问题
划分训练集和测试集时未随机或分割比例有问题,导致模型在测试集上表现不佳。