从数据格式转换的角度 flink cdc 如何同步数据,写入paimon?
从一个测试用例着手
org/apache/flink/cdc/connectors/paimon/sink/v2/PaimonSinkITCase.java
java
public void testSinkWithDataChange(String metastore, boolean enableDeleteVector)
throws IOException, InterruptedException, Catalog.DatabaseNotEmptyException,
Catalog.DatabaseNotExistException, SchemaEvolveException {
// 初始化paimon的元数据
initialize(metastore);
// 创建paimonSink
PaimonSink<Event> paimonSink =
new PaimonSink<>(
catalogOptions, new PaimonRecordEventSerializer(ZoneId.systemDefault()));
PaimonWriter<Event> writer = paimonSink.createWriter(new MockInitContext());
Committer<MultiTableCommittable> committer = paimonSink.createCommitter();
// insert
writeAndCommit(
writer, committer, createTestEvents(enableDeleteVector).toArray(new Event[0]));
Assertions.assertThat(fetchResults(table1))
.containsExactlyInAnyOrder(
Row.ofKind(RowKind.INSERT, "1", "1"), Row.ofKind(RowKind.INSERT, "2", "2"));
// delete
writeAndCommit(
writer,
committer,
generateDelete(
table1, Arrays.asList(Tuple2.of(STRING(), "1"), Tuple2.of(STRING(), "1"))));
Assertions.assertThat(fetchResults(table1))
.containsExactlyInAnyOrder(Row.ofKind(RowKind.INSERT, "2", "2"));
// update
writeAndCommit(
writer,
committer,
generateUpdate(
table1,
Arrays.asList(Tuple2.of(STRING(), "2"), Tuple2.of(STRING(), "2")),
Arrays.asList(Tuple2.of(STRING(), "2"), Tuple2.of(STRING(), "x"))));
Assertions.assertThat(fetchResults(table1))
.containsExactlyInAnyOrder(Row.ofKind(RowKind.INSERT, "2", "x"));
if (enableDeleteVector) {
Assertions.assertThat(fetchMaxSequenceNumber(table1.getTableName()))
.containsExactlyInAnyOrder(
Row.ofKind(RowKind.INSERT, 1L), Row.ofKind(RowKind.INSERT, 3L));
} else {
Assertions.assertThat(fetchMaxSequenceNumber(table1.getTableName()))
.containsExactlyInAnyOrder(
Row.ofKind(RowKind.INSERT, 1L),
Row.ofKind(RowKind.INSERT, 2L),
Row.ofKind(RowKind.INSERT, 3L));
}
}整体流程:
-
创建变更事件。
-
创建PaimonWriter
-
对于每一个事件event,都调用paimonWriter中的write。具体又包括以下几个步骤
-
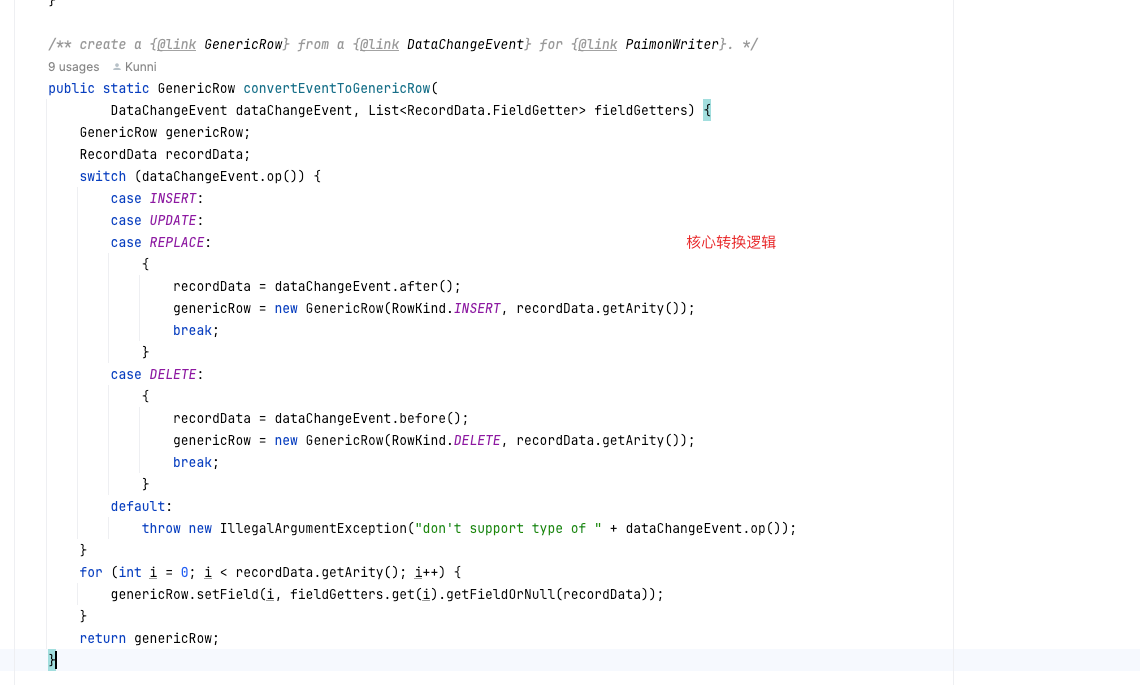
- 序列化event为paimon 中的数据格式genericRow
-
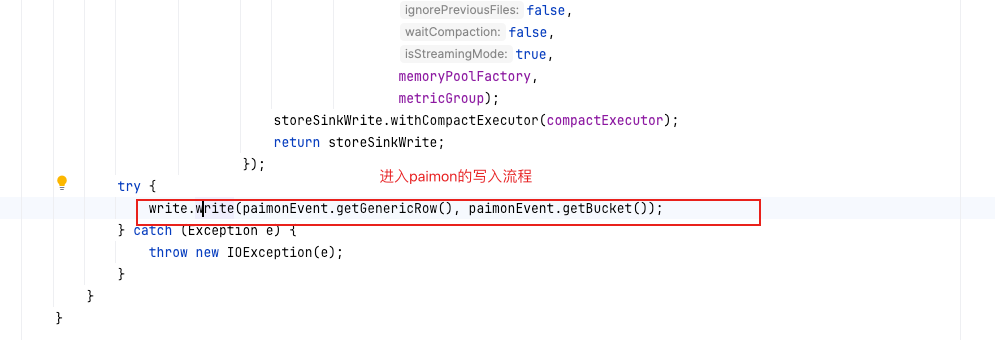
- 创建paimon的write算子(StoreSinkWrite),将genericRow写入paimon表. 进入paimon内部的写入逻辑。
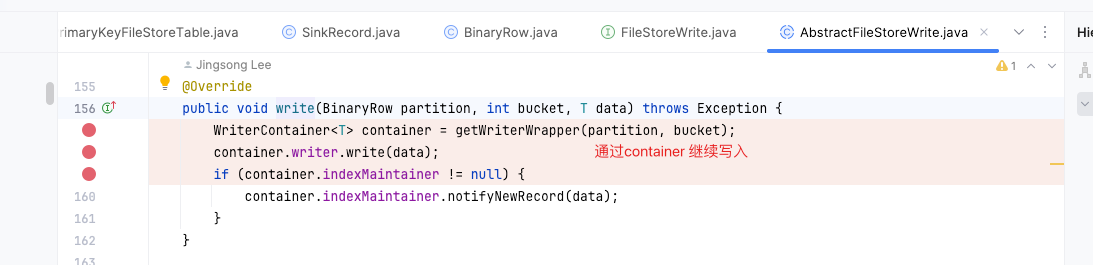
- 从每一条row中提取rowkind(INSERT,UPDATE_BEFORE,UPDATE_AFTER,DELETE)
- 提取data,MergeTreeWriter中执行两个操作,内存够,就把数据put到内存,内存不够就flush到磁盘
- 创建paimon的write算子(StoreSinkWrite),将genericRow写入paimon表. 进入paimon内部的写入逻辑。
源码
Flink cdc 代码
- 创建测试data change event
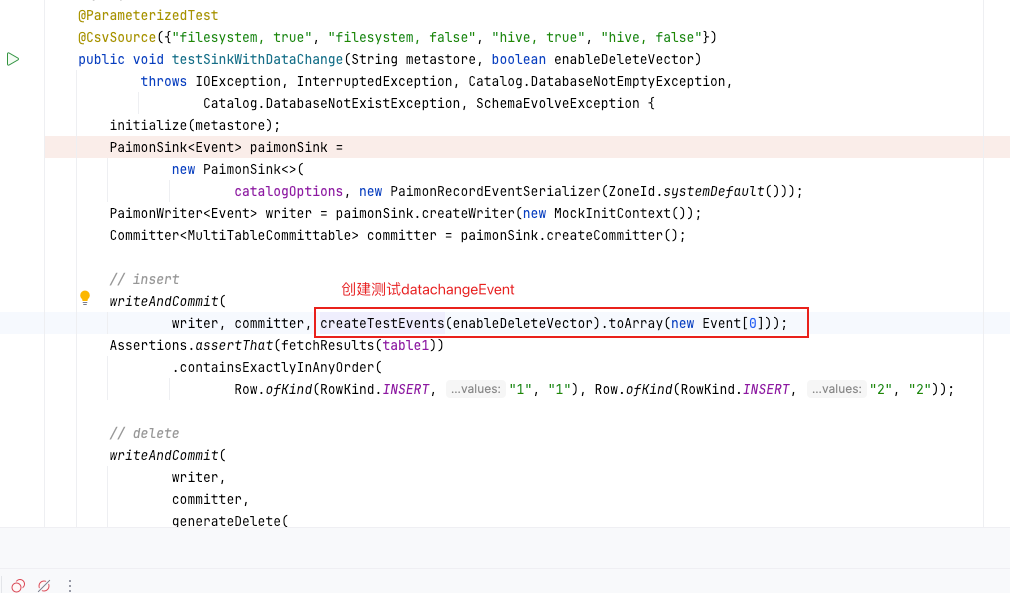
- 遍历事件

- 序列化

- 核心转换逻辑
- paimon的写入
以下是paimon的代码



总结
回到本文的标题:从数据格式转换的角度 flink cdc 如何把数据处理成paimon?
在flink cdc端 核心是 convertEventToGenericRow,处理dataChangeEvent 和 genericRow 对应。
为什么要这么对应?