一、Redis 是什么?为什么我们需要它?
Redis(Remote Dictionary Server )是一种高性能的内存型键值对数据库 。
通俗地讲,它就像一个超快的、放在内存中的超级字典 ,你可以用它来存数据、查数据,而且快得飞起。

但比一般的键值对,比如 HashMap 强大的多,Redis 中的 value 支持 string、hash、 list、set、zset、Bitmaps、 HyperLogLog、GEO等多种数据结构。
而且因为 Redis 的所有数据都存放在内存当中,所以它的读写性能非常出色。
不仅如此,Redis 还可以将内存数据持久化到硬盘上,这样在发生类似断电或者机器故障的时候,内存中的数据并不会"丢失"。
除此之外,Redis 还提供了键过期、发布订阅、事务、流水线、Lua 脚本等附加功能,是互联网技术领域中使用最广泛的缓存中间件。
Redis 和 MySQL 的区别?
- Redis:数据存储在内存 中的 NoSQL(内存数据库),读写性能非常好 ,适合 高并发、缓存、排行榜。
- MySQL:数据存储在硬盘 中的 SQL (关系型数据库),适合 事务、复杂查询、持久化存储。
🌰 类比理解
如果我们把传统数据库比作一个大仓库,数据存硬盘,查找、读写速度较慢;
那 Redis 就像是老板桌上随手翻的便签纸,写上就能随时翻,速度非常快。
二、Redis 能做什么?真实业务场景举例
| 典型场景 | 用途 |
|---|---|
| 用户登录验证 | 保存用户 token、session,实现快速认证验证 |
| 秒杀系统 | 控制库存、限流防刷,减少数据库压力 |
| 缓存热点数据 | 缓存用户信息、文章详情,减少数据库访问,提高访问速度 |
| 实时排行榜 | 使用 ZSet 实现积分排行、浏览量排行等 |
| 消息队列 | 使用 List 实现简单队列,异步处理任务(如下单、发短信) |
| 分布式锁 | 保证多个服务节点之间互斥执行操作 |
| 限流器 | 基于时间窗口或令牌桶算法,控制接口访问频率 |
三、Redis 支持的数据结构(核心)
Redis 有五种基本数据类型,这五种数据类型分别是:string(字符串)、hash(哈希)、list(列表)、set(集合)、sorted set(有序集合,也叫 zset)。
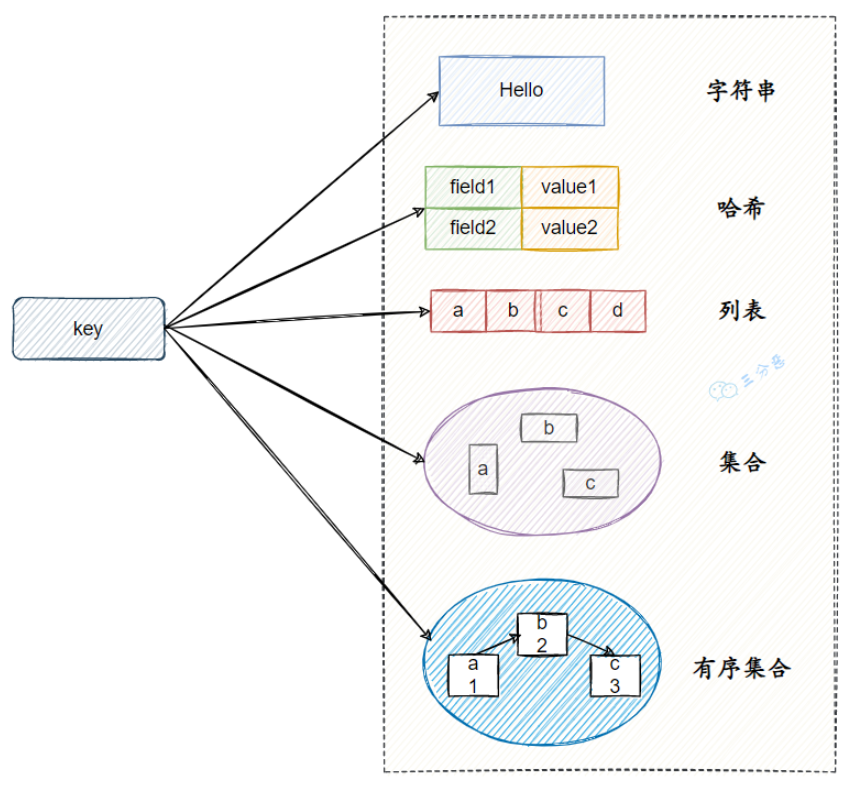
简单介绍下 string?
字符串是最基础的数据类型,key 是一个字符串,不用多说,value 可以是:
- 字符串(简单的字符串、复杂的字符串(例如 JSON、XML))
- 数字 (整数、浮点数)
- 甚至是二进制(图片、音频、视频),但最大不能超过 512MB。
字符串主要有以下几个典型的使用场景:
- 缓存功能
- 计数
- 共享 Session
- 限速
简单介绍下 hash?
键值对集合,key 是字符串,value 由多个字段(field)和对应值(value1)组成,相当于一个对象的属性列表。比如:user:1 作为 key,其中 name 和 age 是字段(field),对应值(value1)分别是 'pwzs' 和 18。
哈希主要有以下两个典型应用场景:
- 缓存用户信息
- 缓存对象
简单介绍下 list?
list 是一个简单的字符串列表,按照插入顺序排序。可以添加一个元素到列表的头部(左边)或者尾部(右边)。
列表主要有以下两个使用场景:
- 消息队列
- 文章列表
简单介绍下 set?
Set 是一个无序集合,元素是唯一的,不允许重复。
简单介绍下 zset?
Zset 是有序集合,比 set 多了一个排序属性 score。
| 类型 | 简介 | 示例用途 |
|---|---|---|
| String | 最常用,字符串/数字都能存 | 缓存用户信息,token 值等 |
| Hash | 类似 Java 的 Map |
缓存对象,如 user:1001 => {name:张三} |
| List | 链表结构,可当队列使用 | 异步队列、消息列表等 |
| Set | 无序集合,不重复元素 | 标签集合、共同好友等 |
| ZSet | 有序集合(带权重分数) | 排行榜、打分系统 |
| Bitmap | 位数组,可用于统计 | 统计活跃用户、签到状态等 |
| HyperLogLog | 近似去重统计(节省空间) | UV(独立访客)数量估算 |
| Geo | 地理坐标存储 | 附近的人、地图服务 |
| Stream | 日志流/消息队列结构 | 异步事件、实时日志处理等 |
四、为什么 Redis 这么快?
- 内存存储:所有数据存储在内存中,使得数据的读写操作避开了磁盘 I/O,访问速度比磁盘快几个数量级。
- 单线程模型:任何时刻只有一个命令在执行,避免了多线程加锁带来的开销,简化实现(但 I/O 非阻塞,效率高)。
- 高效的数据结构:底层精心设计的结构如 ziplist、skiplist、Hash、List 等。
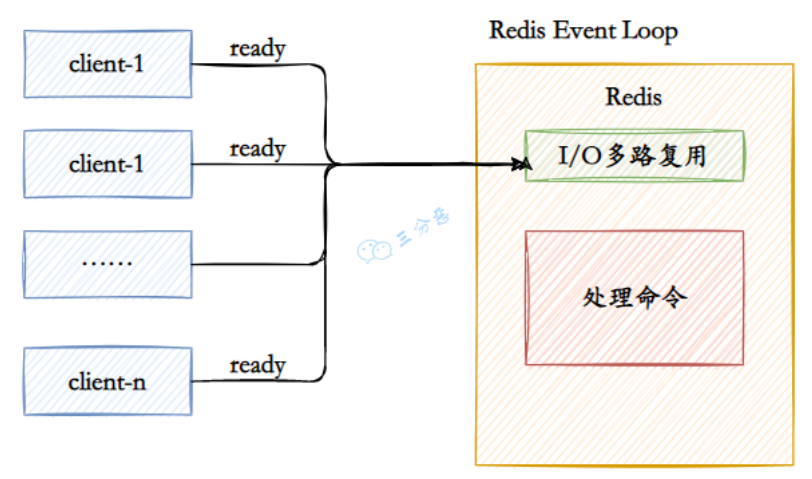
- I/O 多路复用 :基于 Linux 的
select/epoll机制。该机制允许内核中同时存在多个监听套接字和已连接套接字,内核会一直监听这些套接字上的连接请求或者数据请求,一旦有请求到达,就会交给 Redis 处理,就实现了所谓的 Redis 单个线程处理多个 IO 读写的请求。
五、Redis 的核心机制与原理
1. 缓存穿透、缓存击穿、缓存雪崩
| 问题 | 含义 | 解决方案 |
|---|---|---|
| 缓存穿透 | 请求的数据不存在于缓存和数据库 | 缓存空值、使用布隆过滤器 |
| 缓存击穿 | 热点 key 失效瞬间,大量请求涌入数据库 | 设置互斥锁(互斥更新)、提前更新缓存 |
| 缓存雪崩 | 大量 key 同时过期,数据库被打爆 | 设置不同过期时间、引入限流、预热机制等 |
2. Redis 的持久化机制
| 类型 | 描述 | 优点 | 缺点 |
|---|---|---|---|
| RDB | 快照保存(定时保存数据快照) | 启动快、恢复快 | 数据可能丢失(非实时) |
| AOF | 日志追加(每次写操作都记录) | 更高可靠性,可追加回放 | 文件大、恢复慢 |
| 混合持久化 | RDB + AOF 合并 | 综合两者优点 | 复杂度高,需合理配置 |
3. Redis 线程模型(为什么用单线程还能高性能)
- Redis 使用单线程处理命令请求,避免加锁。
- 通过 I/O 多路复用(epoll),能同时监听多个客户端连接。
- 耗时任务如 RDB/AOF 会另起子线程处理,不影响主线程性能。
六、Redis 与数据库一致性问题
- 场景:更新数据库后再更新 Redis,如果 Redis 更新失败,数据就不一致。
- 常见策略 :
- 延迟双删策略 :
- 删除缓存 → 更新数据库 → 延迟一段时间再次删缓存。
- 消息队列保障一致性 :
- 写数据库同时发送消息,由订阅服务异步更新缓存。
- 先更新数据库,再删除缓存(简单易行,但有窗口期风险)
- 延迟双删策略 :
七、面试陷阱与思路整理
| 面试问题 | 建议回答要点 |
|---|---|
| Redis 为什么用单线程还很快? | 内存 + 非阻塞 I/O + 避免上下文切换 |
| 缓存与数据库如何保持一致? | 延迟双删、消息队列、最终一致性等策略 |
| Redis 能做分布式锁吗?如何实现? | setnx + expire 实现互斥锁,RedLock 多实例增强稳定性 |
| Redis 持久化机制有几种?区别? | RDB 快速恢复,AOF 实时性高,混合持久化性能兼顾 |
八、Redis 学习脉络图(Mermaid)
Redis 基础知识 数据结构 高性能原理 持久化机制 分布式特性 常见应用场景 String/Hash/List/Set/ZSet 单线程机制 I/O 多路复用 RDB / AOF / 混合持久化 主从复制 / 哨兵 / 集群 缓存 / 分布式锁 / 队列 / 排行榜
九、总结一句话
Redis 就像一位放在你身边、反应飞快的"记事小助手",能极大地加速系统处理效率,但也需要你合理使用、考虑一致性问题和扩展性,否则"聪明反被聪明误"。