引言
最近工作中引入了模型策略,所以在平时会在数仓上进行一些作业开发,分析数据,今天就基础性的了解下数仓的架构。
什么是数仓?
数仓(数据仓库,Data Warehouse),就是一种数据库,不过它被专门设计用于支持企业决策分析和报告操作;
通常用于存储和管理来自多个业务系统的数据,使企业能够进行深入的数据分析和挖掘,从而改进业务决策。
数仓的架构
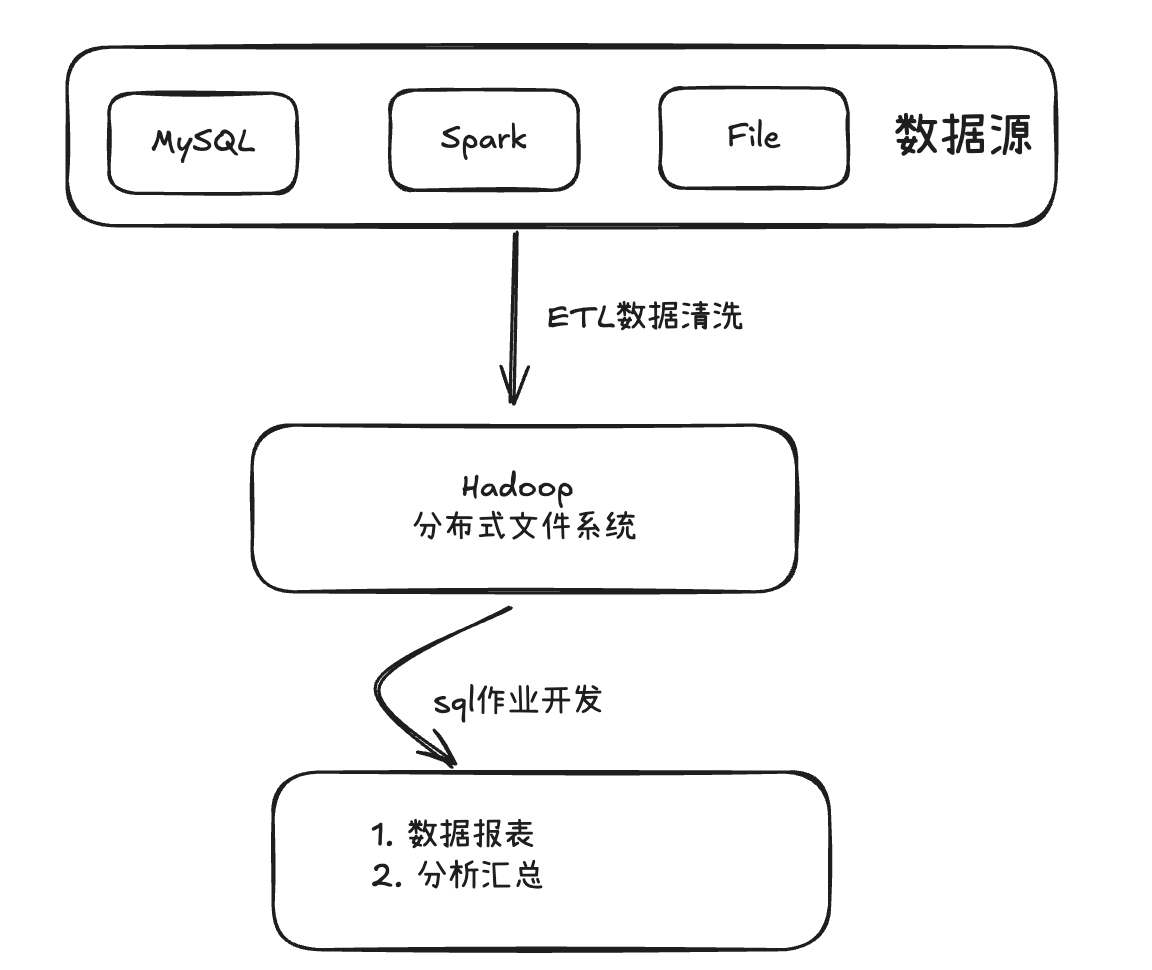
数据源
数仓一般会支持多种数据源接入,如MySQL、Spark、Flink、硬盘文件等。
ETL数据清洗
即**(Extract, Transform, Load)过程**:包括数据的清洗、转换和加载;以确保数据质量和数据准确性。
数据存储
考虑到企业级业务的数据量大,存储成本较高;一般用Hadoop存储原始数据;
不过清洗后的内容,数据量通常会越来越少,可以根据查询性能、写入导出频率选择不同的存储方案。
| 数据层 | 存储方案 | 存储格式 | 应用场景 |
|---|---|---|---|
| ODS(原始数据层) | Hadoop HDFS | Parquet | 存储原始订单、用户行为数据 |
| DW(数据仓库层) | Amazon Redshift | 列式存储 | 存储清洗后的订单、用户数据 |
| DM(数据集市层) | MySQL | 行式存储 | 存储销售部门的销售分析数据 |
| 归档层 | Amazon S3 Glacier | - | 存储历史订单数据(5年以上) |
查询分析
数据处理:使用 Spark SQL 进行数据清洗、转换和分析。
结果存储:将分析结果写回 MySQL 或其他数据库,供业务系统使用。
其中SQL执行过程,还涉及到资源调度、批处理等核心提效手段,具体的资源调度策略与批处理方式需要结合hadoop食用。
| 维度 | 批处理 | 资源调度 |
|---|---|---|
| 核心目标 | 高效执行批量任务 | 动态分配和管理计算资源 |
| 技术实现 | Hadoop、Spark、Flink | YARN、Kubernetes、Mesos |
| 优化方向 | 数据本地性、任务拆分、弹性伸缩 | 公平调度、抢占式调度、资源预留 |