LEARNING DYNAMICS OF LLM FINETUNING
一句话总结
作者将LLM的学习动力机制拆解成AKG三项,并分别观察了SFT和DPO训练过程中正梯度信号和负梯度信号的变化及其带来的影响,并得到以下结论:
- SFT通过梯度相似性间接提升无关回答置信度;
- DPO负梯度回传会引发confidence(softmax score) 向模型训练前confidence最高的token聚集:DPO中正样本与 负样本之间的margin虽然在增大,但正样本的confidence 的上涨幅度 却没有训练前模型最中意的答案 的confidence涨得快。
吐槽一下,这篇非常不适合LLM伴读和粗读,因为符号多,符号的描述写的很松散,图表的讲解非常碎(一张图的解释可能会横跨两个subsection),我开始用LLM伴读给我弄的非常混乱,自己粗读发现跳过一两段可能一个符号什么意思就不知道了。最后老老实实一行一行读。虽然作者的工作非常详实,但是......只能说这种写法不坑老实人吧。
↓↓↓这里先补充一下Learning Dynamic的分析逻辑↓↓
学习动力机制(Learning Dynamic)指什么?
Learning Dynamic,简单来说,就是研究每次模型经过一个batch的数据训练后,参数发生了变化,这个变化如何影响模型的表现。具体来说,哪些方面变好了?哪些方面变差了?
用来描述哪些方面变好,哪些方面变差的工具就是先做一个观察数据集,这个数据集是静态的。
观察一个batch的训练后,观察数据集里的<哪些样本 >的预测结果有<什么样>的变化,就是研究Learning Dynamic。
为了衔接论文里的公式,这里把上面学习动力机制研究的公式写出来
第一步:定义,参数更新对特定样本的输出的影响
f ( x ; θ ) = π ( z ( x ; θ ) ) f(x;θ)=π(z(x;θ)) f(x;θ)=π(z(x;θ)) π π π是最后一层的softmax函数, x o x_o xo指的是观察集的样本。
--->参数更新 Δ θ Δθ Δθ 会导致输入 x x x的输出变化是
Δ f ( x o ; θ ) ≈ ∇ θ f ( x o ; θ ) ⋅ Δ θ Δf(x_o;θ)≈∇_θf(x_o;θ)⋅Δθ Δf(xo;θ)≈∇θf(xo;θ)⋅Δθ
第二步:展开 第一项
∇ θ f ( x o ; θ ) = ∂ π ( z ( x o ; θ ) ) ∂ z ⏟ softmax雅可比 J π ( z ) ⋅ ∇ θ z ( x o ; θ ) ⏟ logits的梯度 \nabla_\theta f(x_o;\theta) = \underbrace{\frac{\partial \pi(z(x_o;\theta))}{\partial z}}{\text{softmax雅可比 } J\pi(z)} \cdot \underbrace{\nabla_\theta z(x_o;\theta)}_{\text{logits的梯度}} ∇θf(xo;θ)=softmax雅可比 Jπ(z) ∂z∂π(z(xo;θ))⋅logits的梯度 ∇θz(xo;θ)
第三步: Δ θ Δθ Δθ 把梯度替换成 当批次样本 { x 1 , . . . , x i , . . . x n } \{x_1,...,x_i,...x_n\} {x1,...,xi,...xn} 带来的梯度
把 Δ θ Δθ Δθ 替换成 Δ θ = − η ∇ θ L ( θ ) Δθ=−η∇ _{θ}L(θ) Δθ=−η∇θL(θ) 即学习率乘以梯度
∇ θ L ( θ ) = 1 n ∑ i = 1 n ( π ( z ( x i ; θ ) ) − y i ) ⊤ ⋅ ∇ θ z ( x i ; θ ) ⏟ 通过链式法则: ∂ L ∂ z ⋅ ∂ z ∂ θ \nabla_\theta L(\theta) = \frac{1}{n} \sum_{i=1}^n \underbrace{\left( \pi(z(x_i;\theta)) - y_i \right)^\top \cdot \nabla_\theta z(x_i;\theta)}_{\text{通过链式法则:} \frac{\partial L}{\partial z} \cdot \frac{\partial z}{\partial \theta}} ∇θL(θ)=n1i=1∑n通过链式法则:∂z∂L⋅∂θ∂z (π(z(xi;θ))−yi)⊤⋅∇θz(xi;θ)
第四步:两个展开式带回源式
Δ f ( x ; θ ) ≈ − η n ∑ i = 1 n J π ( z ( x ; θ ) ) ⋅ ∇ θ z ( x ; θ ) ⋅ ( π ( z ( x i ; θ ) ) − y i ) ⊤ ⋅ ∇ θ z ( x i ; θ ) \Delta f(x;\theta) \approx -\frac{\eta}{n} \sum_{i=1}^n \left J_\\pi(z(x;\\theta)) \\cdot \\nabla_\\theta z(x;\\theta) \\right \cdot \left \\left( \\pi(z(x_i;\\theta)) - y_i \\right)\^\\top \\cdot \\nabla_\\theta z(x_i;\\theta) \\right Δf(x;θ)≈−nηi=1∑nJπ(z(x;θ))⋅∇θz(x;θ)⋅(π(z(xi;θ))−yi)⊤⋅∇θz(xi;θ)
第五步:把gradient乘积写成NTK项
Δ f ( x ; θ ) ≈ − η n J π ( z ( x ; θ ) ) ∑ i = 1 n ⟨ ∇ θ z ( x ; θ ) , ∇ θ z ( x i ; θ ) ⟩ ⏟ NTK项 K ( x , x i ) ⋅ ( π ( z ( x i ; θ ) ) − y i ) Δf(x;θ) ≈ -\frac{η}{n} J_π(z(x;θ)) \sum_{i=1}^n \underbrace{\left\langle \nabla_θ z(x;θ), \nabla_θ z(x_i;θ) \right\rangle}{\text{NTK项 } \mathbf{K}(x, x_i)} \cdot \left( π(z(x_i;θ)) - y_i \right) Δf(x;θ)≈−nηJπ(z(x;θ))i=1∑nNTK项 K(x,xi) ⟨∇θz(x;θ),∇θz(xi;θ)⟩⋅(π(z(xi;θ))−yi)
最终
Δ f ( x o ; θ ) ≈ − η n ⋅ J π ( z ( x o ; θ ) ) ⏟ softmax非线性效应 ⋅ ∑ i = 1 n K ( x o , x i ) ⏟ 样本相关性 ⋅ ( π ( z ( x i ; θ ) ) − y i ) ⏟ 训练样本误差 \Delta f(x_o;\theta) \approx -\frac{\eta}{n} \cdot \underbrace{J\pi(z(x_o;\theta))}{\text{softmax非线性效应}} \cdot \sum{i=1}^n \underbrace{\mathbf{K}(x_o, x_i)}{\text{样本相关性}} \cdot \underbrace{\left( \pi(z(x_i;\theta)) - y_i \right)}{\text{训练样本误差}} Δf(xo;θ)≈−nη⋅softmax非线性效应 Jπ(z(xo;θ))⋅i=1∑n样本相关性 K(xo,xi)⋅训练样本误差 (π(z(xi;θ))−yi)
最终这个式子里面的第一项、第二项和第三项分别对应了文章公式3的 AKG。
其中K的部分,代表了在函数空间中的样本相关性(不是两个样本乍看之下像不像,而是通过梯度核(NTK)映射之后像不像。文章在分析SFT时会一直用这个角度
G是训练样本误差带来的影响,这个在DPO分析中还会被拆成正负两项(因为DPO用的是margin)
关键细节与结论
1. G项给SFT带来的是训练Token的confidence上升
这里的confidence指的是Token的输出概率(softmax之后的score)
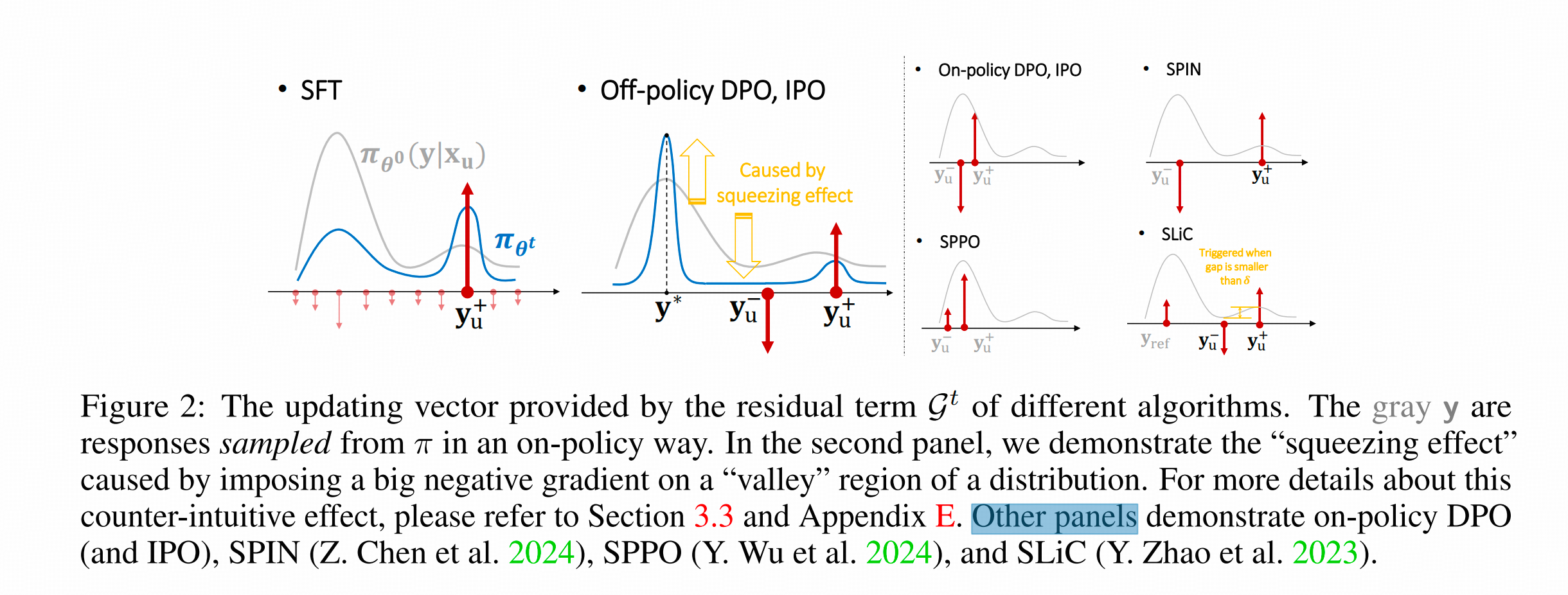
看上图中左侧第一张图,灰色是本步骤之前的这个样本的词表上的所有Score的曲线。蓝色就是这一步训练之后,词表上所有词的Score的变化。
这是很符合直觉的,也是论文的前菜.(但是这张图特别不好,把后面要说的东西的分析也放这儿了,看着很乱。大概是因为投稿篇幅的关系,作者压进来了)
2. SFT中 出现在训练集里的y,会在挂羊头卖狗肉的情况下也很自信
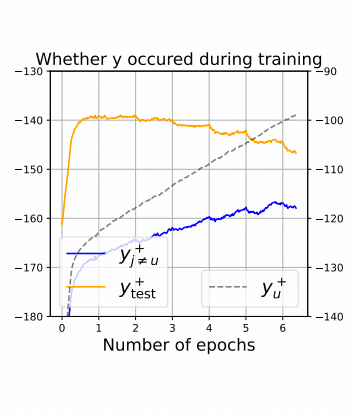
文中figure3的这张图,展示的是
π ( y u + ∣ x u ) π(y_{u^+}|x_u) π(yu+∣xu) -虚线, π ( y j ∣ x u ) π(y_{j}|x_u) π(yj∣xu)-蓝色线, 和 π ( y t e s t + ∣ x u ) π(y_{test^+}|x_u) π(ytest+∣xu)-橙色线 在训练过程中的变化。( π π π是softmax函数,这三条线都对应的是模型分)
其中 π ( y u + ∣ x u ) π(y_{u^+}|x_u) π(yu+∣xu) 就是训练集中样本A 对应的答案A的概率;
π ( y j ∣ x u ) π(y_{j}|x_u) π(yj∣xu)是训练集中样本A作为context(或者说prompt),后面接样本B的正确答案y_j的时候的score
π ( y t e s t + ∣ x u ) π(y_{test^+}|x_u) π(ytest+∣xu) 是训练集中样本A作为context,后面接测试集中某个样本的正确答案的时候的score。
如果按照我们的希望🔽
给定样本A的prompt,样本B的正确答案作为output的时候,这个答案是错的,他的confidence不应该上涨。
但在作者的实验记录下,这一数值上涨了。这就是作者认为SFT中一部分幻觉的来源
3. K项给SFT带来的是意思相近和格式相近的答案的confidence的上升
作者在分析的时候使用的是DPO数据集(Antropic-HH 和UltraFeedback),尽管他在训练SFT的时候仅适用了 DPO数据集中的prefer样本 y u + y_{u^+} yu+,但在分析中他同时分析了less prefer(负样本) y u − y_{u^-} yu−。
下图中, y u + y_{u^+} yu+ 是DPO样本集中<正样本>
y u − y_{u^-} yu− 是DPO样本集中<负样本>
y g p t s + y_{gpts^+} ygpts+ 是用GPT针对DPO样本集中<正样本>做的同意改写样本
y g p t s − y_{gpts^-} ygpts− 是用GPT针对DPO样本集中<负样本>做的同意改写样本
y h u m y_{hum} yhum 是随机的一个句子(跟训练样本无关)
y j ≠ u + y_{{j≠u}^+} yj=u+ 是训练集中另一个样本的<正样本>
y t e s t + y_{{test}^+} ytest+ 是测试集中某个样本的<正样本>
y r n d y_{{rnd}} yrnd 是随机英文词组成的字符串(连句子都不是)
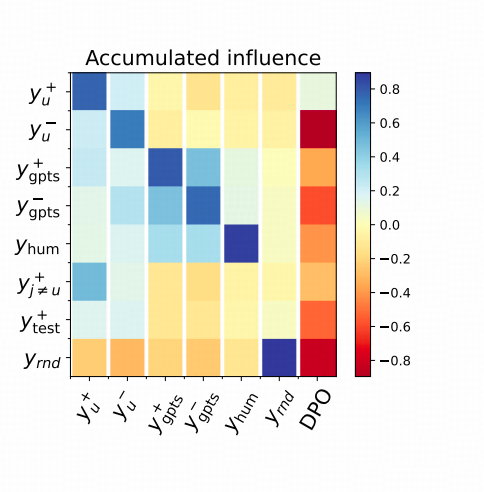
基于以上符号意义,观察上图,蓝色部分confidence上涨,橙色就是下降。上图中左侧多个列都显示,每训练25步 x u ; y u x_u;y_u xu;yu就观察一次,发现一些语义或者格式相似( y g p t s + y_{gpts^+} ygpts+)的样本的confidence也上涨了。
同时乱序的字符串( y h u m y_{hum} yhum和 y r n d y_{rnd} yrnd)训练的时候,其他有正常语义的答案的confidence都会降低。因为,用K来衡量的距离跟这些乱序的答案的距离是很大的,Learning Dynamic的角度上看这些confidence也确实应该下降。
》最炸裂的其实是这个图的最后一列 DPO这列,这列引入的是下面一个结论
4. DPO中的负梯度会给所有未被训练的答案打负分
作者实验中发现,如果下图左1所示,在用DPO训练很多个epoch的过程中,根据训练样本正确答案改写的正样本 y g p t s + y_{gpts^+} ygpts+ (语义相同)和 y g p t f + y_{gptf^+} ygptf+ (格式相同)的confidence都在持续下降。
这是与我们的直觉相反的。
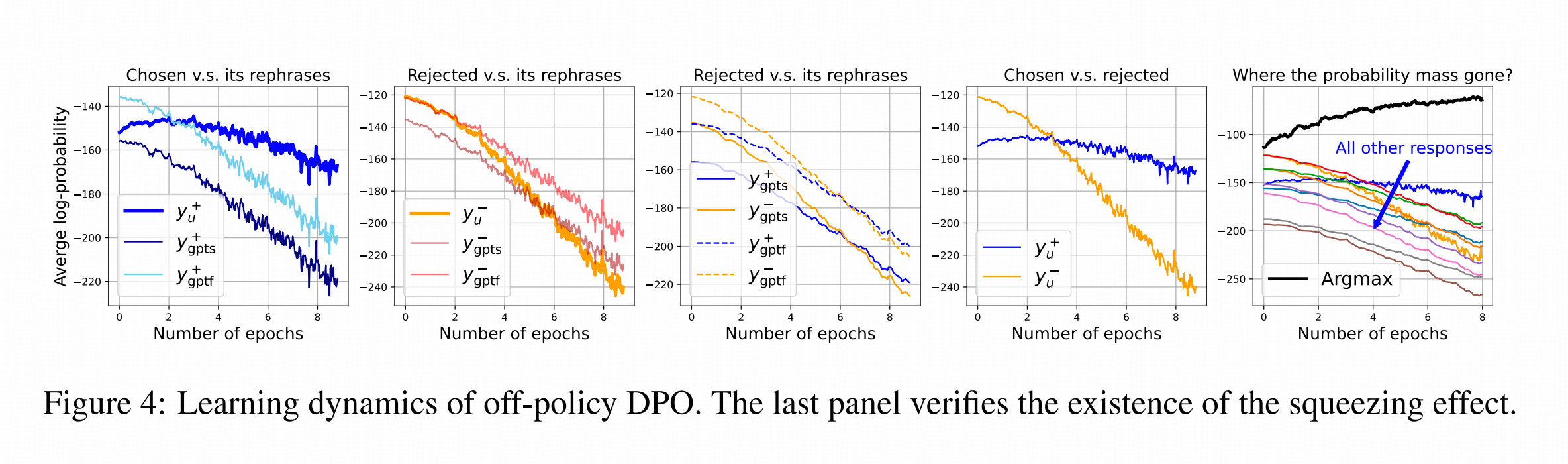
同时,上图左2显示,不仅DPO中正样本的改写样本的confidence在持续下滑,负样本的confidence也在持续下滑(仔细看数轴,这组斜率更大)
看上图的左4,在训练中的正样本和负样本的confidence的变化是:正样本的confidence先上涨后下滑,到第四个epoch,连正样本的confidence都比训练前要低了;而负样本的confidence全程咔咔下跌。
那正负样本的confidence都跌了,谁涨了呢? (毕竟是用softmax转换过的score,有人跌就有人涨)
答:看第左5,图中的黑线是模型在DPO之前(如果按照RL的说法,可以说是reference model)最prefer的答案的概率。
整个训练过程,reference model中概率最高的token的概率涨的最猛,比训练的正样本y还猛。
5. 这种错位的虹吸效应的源头是DPO的负梯度影响
文中的大部分拆解都沿用了经典的拆分方案。DPO上做了一个变化,把G分成了正负两部分。

这里有个比较讨厌的东西 χ u − χ^-_u χu− 这个符号其实是附录中下面高亮部分的意思,就是 x u x_u xu是一样的,y不一样。这么表示其实有点讨厌,一来是符号不在公式附近(在附录B ),二来这么写其实挺容易让人误解的。
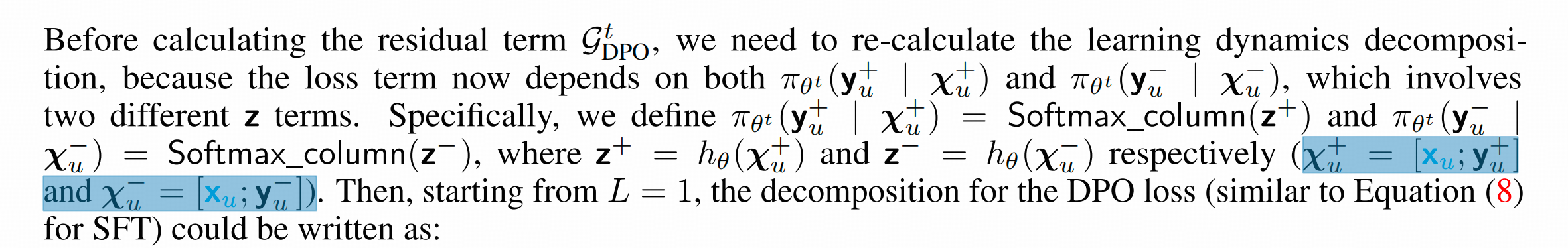
前面这种奇怪的现象主要来自于负梯度的回传,也就是 G − G^- G−的部分。
在附录中,作者还展示了reference model对 y u + y_{u^+} yu+分布形状不同的时候 ,DPO的负梯度带来的影响差别。
上面这个分析有个需要注意的点,就是这个DPO是off-policy的(虽然我们说DPO的时候通常就是off-policy的),即完全是静态的样本集,正样本和负样本都不是通过play逐步变化的。
那如果是on-policy的 ,也就是随着模型训练,概率分布有变化的时候(或者 y u + = y u ∗ y_{u^+}=y_{u^*} yu+=yu∗ 或 y u − = y u ∗ y_{u^-}=y_{u^*} yu−=yu∗ , u ∗ u^* u∗指的就是reference model最中意的答案。)负梯度带来的影响是什么样的?
灰线是训练前,蓝线是训练后
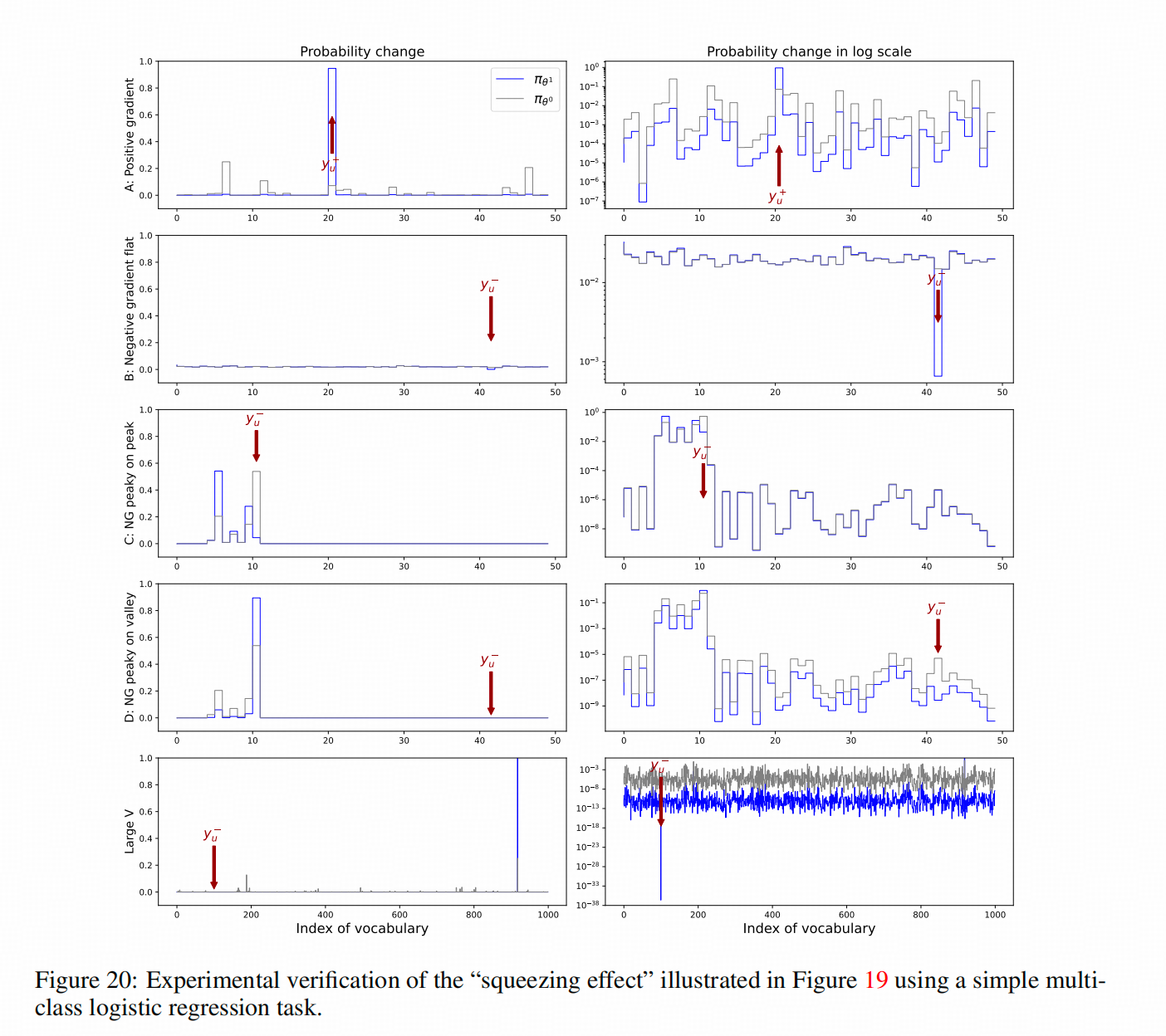
看图的第三行,在原先分布是有几个特殊token的概率较高的情况下, y u − y_{u^-} yu−直接作用到reference模型概率最高的token上时,其他概率相对较高的token的概率被直接抬起来很多。
看图的第四行,在原先分布是有几个特殊token的概率较高的情况下, y u − y_{u^-} yu−直接作用到reference模型概率很低的token时,原先概率最高的token的概率被大大提升了。而不是所有概率高的token的概率都提升了,而是效用集中到一个token上。
评价
多于1个epoch问题就会逐渐凸显
在作者原文的大部分实验图中,都能看到,尽管DPO带来的挤压效应在多个epoch之后就显得非常病态。在实际训练过程中,其实也是这样的,不管是SFT还是DPO,在已知-->"全参数微调可以让模型在一个epoch之内完成记忆"<--这个前提下,训练超过1个epoch都要非常小心。而且在准备样本的过程中也要考虑,样本实际重复的情况来算实际epoch数。
定点制作DPO数据效果会很好
我这里提供的是论文作者论述以外,一个自己之前实践上的经验:制作两个只有关键知识点不同,其他描述完全相同的样本,比如"上海迪士尼上午9点开园"和"上海迪士尼上午10点开园",这个会很大程度上提高模型的知识矫正(更新)效率。比unlearning还快。
完全静态的DPO样本集,会很快打乱SFT中已经训练好的模式
同样是跟作者的认知比较像的,如果先训练SFT把想要的模式注入到LLM里,然后用DPO来训,前面SFT的胜利成果可能在很小的样本量下就不行了。原因就在于SFT注入的本身就是一个模型原来并不prefer的格式。而且注入的点可能覆盖面并不够大(小样本的时候)