1 背景
这两年在自动驾驶这个行业,给人的感觉是:似乎不懂大模型,不懂端到端,就要被淘汰了。而事实并不是如此,笔者在之前的文章中《自动驾驶---聊聊传统规控和端到端》也聊过自己对传统算法和端到端的思考。
同时,也引用了两位行业专家对自动驾驶未来的看法:
传统Planner的确有其局限性,但端到端就没有其局限性了吗?答案是有的,但这不代表我们不去认识它,了解它,甚至利用它。
2 自动驾驶大模型
传统的自动驾驶规划模块通常基于规则(如状态机等)或优化算法,其特点是:
-
强依赖人工规则:需预先定义大量驾驶场景的应对策略(如变道、避障)。
-
计算复杂度高:动态环境下实时决策搜索可能面临复杂度高的问题。
-
泛化能力弱:难以应对复杂长尾场景(如突发障碍物、人车混行、潮汐车道无法识别等)。
自动驾驶大模型的出现就是为了解决传统算法难以解决的问题,下面笔者从一般自动驾驶大模型的架构开始,阐述其基本框架。
本篇博客先介绍传统的端到端思路,在框架上其实和原有感知框架差不太多,多的是最后一层,在原有BEV特征或者OCC特征的基础上,增加一个单独的任务Head用于轨迹解码。
后续再介绍以VLM视觉语言大模型为主的自动驾驶端到端架构。
2.1 大模型的核心思想
大模型通过海量驾驶数据训练,学习人类驾驶员的决策逻辑和环境理解能力,实现更智能的规划:
-
输入:多模态信息(激光雷达、摄像头、地图、导航信息,甚至语音提示等)。
-
输出:未来轨迹(路径+速度+行为决策)。
-
关键技术:
-
端到端学习:直接从感知输入到规划输出的映射(如Wayve的LINGO-1)。
-
Transformer架构:处理时序和空间依赖关系,支持长距离规划(如Tesla的Occupancy Networks)。
-
模仿学习与强化学习结合:模仿人类驾驶行为,并通过仿真环境优化策略(如Waymo的ChauffeurNet)。
-
2.2 模型分类
从模型分类上来说,主要包括以下几种形式(感知模型+端到端模型):
-
基于BEV(Bird's Eye View)的规划模型
-
核心思想:将多传感器数据统一映射到鸟瞰图坐标系,BEV特征作为planner模型的输入。
-
代表:理想双系统之快系统
-
-
基于Occupancy Networks(占据网络)的规划模型
-
核心思想:静止障碍物的占据栅格(Occupancy Grid)以及动态障碍物的未来运动轨迹(Occupancy Flow),作为planner模型的输入。
-
代表:特斯拉(V12之前)
-
-
模仿学习与强化学习结合模型
-
模仿学习(Imitation Learning):从人类驾驶数据中学习驾驶策略(如Waymo的ChauffeurNet)。
-
强化学习(Reinforcement Learning):在仿真环境中通过试错优化策略(如Waymo的Parallel Domain)。
-
-
视觉语言模型增强的规划模型
-
核心思想:利用大语言模型(VLM、LLM)理解图片、导航指令、交通规则或场景语义,生成可解释的规划决策。
-
典型方法:
-
DriveLM(谷歌):将规划问题转化为"视觉-语言-动作"的推理链,举例:"前方有行人,应减速让行"。
-
DriveVLM(理想):慢思考系统处理复杂场景。
-
-
2.3 模型输入与输出设计
整体模型的输入输出和下图基本相同,区别主要在于模型内部结构。
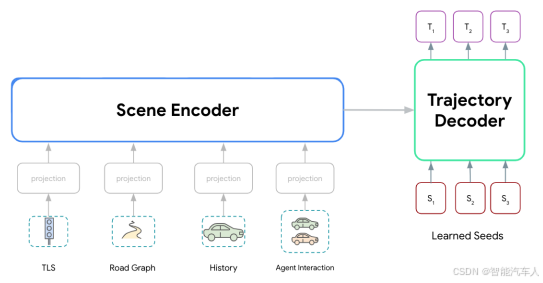
(1)输入信息
-
传感器数据:摄像头图像、激光雷达点云、毫米波雷达等(动静态信息,以及道路标识等语义信息)。
-
地图与定位:地图的车道拓扑、交通标志、定位信息(GPS+IMU等)。
-
任务指令:导航信息。
(2)输出形式
-
轨迹输出:路径点序列(x, y, 速度、加速度、航向角)。
-
行为决策:离散动作(如变道、停车、让行)或连续控制(方向盘转角、油门/刹车)。
-
不确定性估计:对规划结果的置信度(如避障路径的可行性概率)。
2.4 模型架构与流程
典型模型结构通常分为编码器-解码器框架,具体如下:
(1)编码器结构
编码器由多层堆叠的Transformer层构成,每层包含以下三个核心模块:
a. 自注意力机制(Self-Attention)
-
Query-Key-Value生成:每个输入元素(如车辆、车道线)通过线性变换生成Q、K、V向量。
-
交互建模:计算注意力权重(Q与K的点积缩放后Softmax),加权聚合V向量,捕捉元素间关系(如车辆避让、车道跟随)。
-
改进设计:
-
多头注意力:并行多个注意力头,捕捉不同类型交互(如空间邻近性、运动趋势)。
-
时空编码:在输入中加入时间位置编码,区分历史帧的时间顺序。
-
b. 前馈神经网络(FFN)
- 对自注意力输出进行非线性变换(如ReLU激活),增强模型表达能力。
c. 残差连接与层归一化
- 每个模块的输出通过残差连接与层归一化稳定训练过程。
(2)编码器的输出
-
输出形式 :每个输入元素(交通参与者、地图元素)的上下文感知特征向量。一个二维矩阵(或张量),维度为 (
)。
-
(N):输入序列的长度(元素数量),包括所有交通参与者(车辆、行人等)和地图元素的编码单元。
-
(D):每个元素的特征维度(由模型设计决定,例如256、512等)。
-
-
特征内容:
-
包含自身历史运动模式(如加速/减速趋势)。
-
融合周围参与者行为的影响(如前车刹车导致减速需求)。
-
结合地图约束(如车道保持、路口转向规则)。
-
-
维度 :假设输入序列长度为(N),特征维度为(D),则输出为(
-
输出示例
假设场景中有3辆车(A、B、C)和10个关键地图元素(车道线、交通灯等),则编码器输出矩阵的维度为:

每行对应一个元素的特征向量,举例:
-
第1行:车辆A的编码特征(包含自身轨迹和与其他车辆、地图的交互)。
-
第5行:某条车道线的编码特征(包含其几何形状及对车辆的影响)。
(3)MLP解码器
-
定义: MLP 是由至少一个隐藏层(Hidden Layer)构成的全连接神经网络,能够学习输入数据到输出目标的非线性映射关系。
-
核心特点:
-
非线性:通过激活函数引入非线性表达能力。
-
全连接:相邻层的所有神经元相互连接,权重参数通过训练调整。
-
监督学习:依赖标注数据,通过优化损失函数进行训练。
-
-
MLP 的网络结构:MLP 包含以下三类层:
-
输入层(Input Layer):
-
接收原始数据(如特征向量),不进行任何计算。
-
神经元数量 = 输入数据的维度(例如图像像素数或特征数量)。
-
-
隐藏层(Hidden Layer):
-
核心计算层,可包含多层,每层由多个神经元组成。
-
每个神经元对输入进行加权求和,并通过激活函数输出结果。
-
隐藏层数及神经元数量需根据任务调整(超参数)。
-
-
输出层(Output Layer):
-
生成最终预测结果,结构依任务而定:
-
分类任务:Softmax 函数输出概率分布。
-
回归任务:线性输出(无激活函数)。
-
-
-
(4)MLP解码过程
有了上述Transformer编码器得到的特征信息,可以通过MLP或者Transformer解码。下面主要阐述MLP解码。
MLP 解码器 :将特征向量解码为 轨迹点序列 (如位置、速度、加速度)或 驾驶决策(如转向角、油门)。
-
MLP 的核心作用 :MLP 的任务是将 Transformer 输出的抽象特征映射到具体的 规划输出 。主要特征包括:
-
特征维度压缩与解耦
-
输入:Transformer 输出的高维特征向量(如 512 维)。
-
操作 :通过多层全连接网络逐步降低维度,例如**
512→256→128→64**。 -
目的:提取与规划任务直接相关的低维特征(如轨迹的横向/纵向控制量)。
-
-
轨迹点回归
-
输出设计:MLP 最后一层输出维度为 2*T(假设生成 T 个轨迹点,每个点包含 x, y 坐标)。
-
激活函数 :输出层通常使用 线性激活 (直接回归坐标值)或 Tanh(限制输出范围)。
-
-
多任务分支 :若需同时输出轨迹和驾驶决策,MLP 可设计为 多分支结构。
-
-
MLP详细过程
-
输入: Transformer 编码器输出的 全局特征向量(例如 512 维),包含环境感知(障碍物、车道线)、车辆状态(速度、位置)、意图(变道、跟车)等信息。
-
解码过程
-
将高维特征(如 512 维)映射到低维物理空间(如 2D 坐标)。
-
MLP 网络 将特征向量解码为 轨迹点序列,每个点包含位置(x, y)、速度、加速度等参数。
-
MLP 逐步降维:
512 → 256 → 128 → 64 → 2*T(T 为轨迹点数量)。
-
-
**输出:**时间离散化的轨迹点(如未来 5 秒,按 0.1 秒间隔生成 50 个点)。
-
-
简单示例
MLP 逐步降维
python
class TrajectoryDecoder(nn.Module):
def __init__(self, input_dim, output_steps):
super().__init__()
self.mlp = nn.Sequential(
nn.Linear(input_dim, 256),
nn.ReLU(),
nn.Linear(256, 128),
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, 2 * output_steps) # 输出所有轨迹点的x,y坐标
)
def forward(self, feature):
return self.mlp(feature) # 输出形状:[Batch, 2*T]输出处理:将 2*T 的向量拆分为 T 个 (x, y) 坐标点
python
trajectory = output.view(-1, T, 2) # 形状变为 [Batch, T, 2]3 训练目标与损失函数
- 轨迹回归损失: 最小化预测轨迹与真实轨迹的误差(常用Smooth L1 Loss):
-
多模态损失:
-
Winner-Takes-All:仅优化最接近真实轨迹的预测分支。
-
Mode-Xent:对多模态输出进行意图分类(如变道概率)。
-
-
物理约束损失:
-
动力学可行性:惩罚超过最大曲率或加速度的轨迹点。
-
碰撞规避:计算预测轨迹与障碍物的最小距离损失。
-
4 实际应用的问题
在实际应用中,也会遇到模型参数过多,运行推理比较慢的问题,各家也会集中解决类似的问题。
-
部署优化:
-
模型轻量化:通过知识蒸馏将模型压缩为实时推理版本(延迟<50ms)。
-
硬件加速:使用TPU/GPU批处理,支持同时预测数百个障碍物轨迹(堆硬件不是长久之计)。
-
-
数据增强:合成罕见场景的仿真数据。
-
在线学习:在车队运营中收集边缘案例,持续更新模型。
-
交互博弈不确定性:引入逆强化学习(IRL)推断他车意图,提升博弈轨迹的合理性。
-
世界模型:构建大量仿真场景数据集同时进行训练。
-