《博主简介》
小伙伴们好,我是阿旭。
专注于计算机视觉领域,包括目标检测、图像分类、图像分割和目标跟踪等项目开发,提供模型对比实验、答疑辅导等。
《------往期经典推荐------》
二、机器学习实战专栏【链接】 ,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
《------正文------》
目录
- 引言
- 一、研究背景
- 二、核心方法设计:RT-DASR
-
- [(1)模块 1:BV-DHPE(双目视觉深度补偿头部姿态估计)](#(1)模块 1:BV-DHPE(双目视觉深度补偿头部姿态估计))
- [(2)模块 2:MSTBi-LSTM(多源时间双向长短期记忆网络)](#(2)模块 2:MSTBi-LSTM(多源时间双向长短期记忆网络))
- 三、实验验证与关键结果
- 四、研究结论与未来方向
引言

为解决现有基于计算机视觉的驾驶员注意力检测方法中,单目相机精度低、多传感器融合实时性差的问题,本文提出RT-DASR(实时驾驶员注意力状态识别方法) ,其核心包含BV-DHPE(双目视觉深度补偿头部姿态估计) 和MSTBi-LSTM(多源时间双向长短期记忆网络) 两大模块。BV-DHPE 通过双目相机与 YOLO11n Pose 定位面部关键点,利用双目视差计算空间距离补偿单目深度缺陷,使头部姿态估计的平均绝对误差(MAE)较单目方法降低44.7% ;MSTBi-LSTM 融合头部姿态角度、实时车速和注视区域语义,双向提取时间特征实现注意力判别。该方法在 NVIDIA Jetson Orin 部署时,注意力识别准确率达90.4% ,平均延迟仅21.5 ms,经实际矿用卡车驾驶场景测试,为提升驾驶员安全性提供了高精度、低延迟的解决方案。
一、研究背景
-
交通安全需求:驾驶员分心是交通事故核心诱因,美国 2010 年机动车事故社会成本达 836 亿美元,其中 15% 由分心驾驶导致,因此高效可靠的驾驶员注意力检测方法对提升驾驶安全至关重要。
-
现有方法的局限性:
- 生理信号法:通过 EEG(脑电图)、ECG(心电图)等监测,但依赖接触设备,存在成本高、舒适性差、干扰驾驶操作的问题。
- 驾驶行为法:通过方向盘操作、刹车模式等间接推断注意力,但受交通环境、路况、个人驾驶习惯影响大,泛化性和实时性不足。
- 计算机视觉法:因非侵入、低成本、可扩展性强成为主流,但存在两大缺陷 ------ 单目相机缺乏深度信息导致精度低,多传感器融合技术实时性差。
-
场景特殊性:现有研究未适配矿用卡车场景(矿卡体积大、需更广视野、需监控多控制面板),缺乏针对矿卡驾驶员的快速高精度注意力检测技术。
二、核心方法设计:RT-DASR
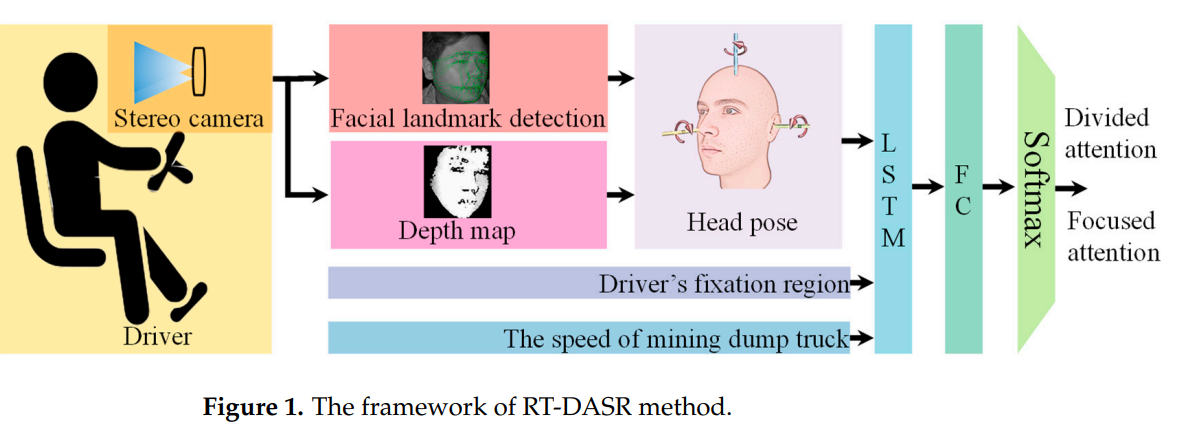
RT-DASR (实时驾驶员注意力状态识别方法)由两大核心模块构成,通过 "高精度头部姿态估计 + 多源时间特征融合" 实现注意力检测,具体设计如下:
(1)模块 1:BV-DHPE(双目视觉深度补偿头部姿态估计)
-
目标:解决单目相机深度信息缺失导致的头部姿态估计精度低问题。
-
硬件配置:双目相机(基线 43mm,焦距 3.5mm),配备 940nm 近红外 LED 补光器,确保低光照环境稳定工作。
-
关键步骤 :
-
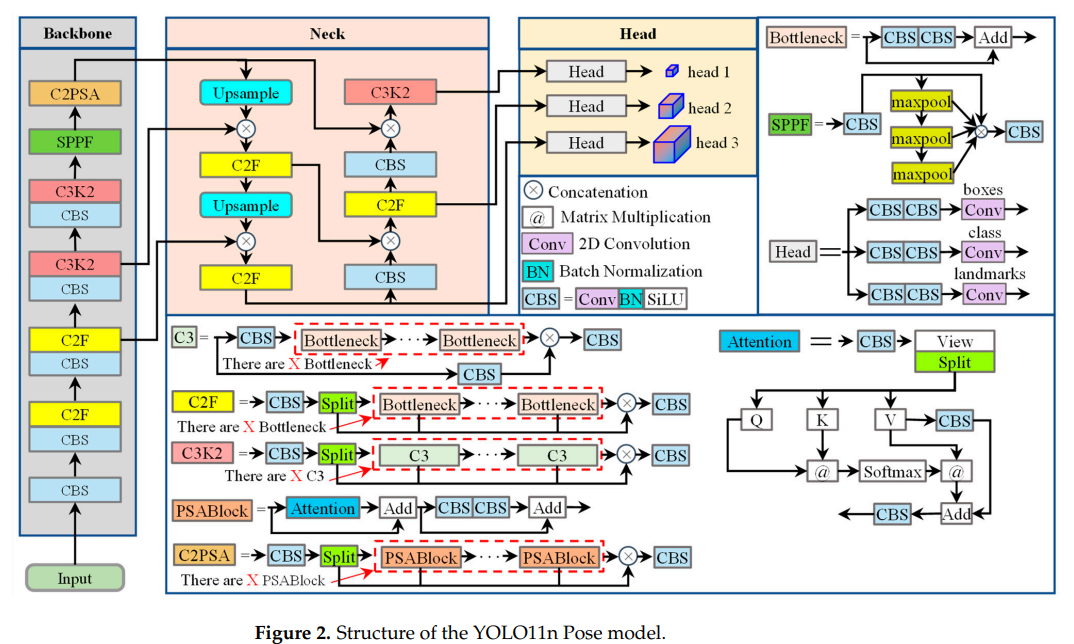
面部关键点定位 :采用 YOLO11n Pose 模型,直接回归 17 个面部关键点,筛选 8 个受表情影响小的点(内 / 外眼角、眉外端、鼻孔)作为候选点,避免传统 "人脸检测→关键点定位" 两阶段流程,提升精度与速度。
-
深度计算 :基于双目视差原理,通过立体匹配生成视差图,结合公式Z =dfB(f 为焦距,B 为基线,d 为视差)将视差转换为深度,获取候选点的 3D 世界坐标。
-
姿态角提取 :利用相机内参矩阵K =f**x 000f**y 0cxc**y1和外参 R\|t,通过奇异值分解(SVD)求解旋转矩阵 R,再分解 R 得到头部的 3 个欧拉角(俯仰:绕 x 轴;滚转:绕 y 轴;偏航:绕 z 轴)。
-
-
性能优势 :头部姿态估计 MAE 较单目方法降低44.7%,极端头部运动时误差更可控(俯仰峰值误差从 12.1°→3.6°,偏航从 9.3°→6.5°)。
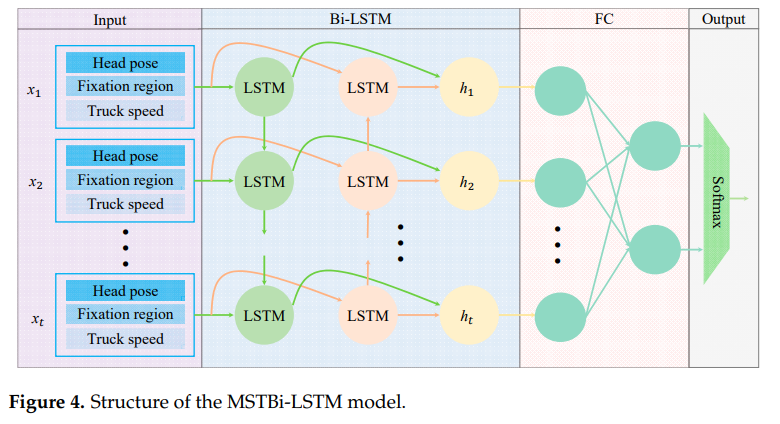
(2)模块 2:MSTBi-LSTM(多源时间双向长短期记忆网络)
-
目标:融合多源时序数据,提升注意力状态判别的连续性与准确性。
-
输入特征设计:
特征类型 维度 说明 头部姿态 3 俯仰、偏航、滚转 3 个欧拉角(归一化后) 注视区域 1 cabin 内 12 个分区(用 1-12 数值表示) 实时车速 1 矿用卡车实时行驶速度 总输入维度 16 ------ -
网络结构:
- 双向 LSTM 层:包含前向 LSTM(按时间顺序提取特征)和反向 LSTM(按时间逆序提取特征),捕捉多源数据的长期时间依赖关系,隐藏单元 128 个,序列长度 300。
- 全连接层(FC)+ Softmax:将双向 LSTM 输出拼接后输入 FC 层,再通过 Softmax 分类为 "专注" 或 "分心" 两类。
-
性能优势:多源特征融合后,注意力识别准确率达 93.2%(训练阶段),推理时间仅 0.1ms,兼顾精度与效率。
三、实验验证与关键结果
(1)实验环境与数据集
| 实验类型 | 硬件配置 | 软件配置 | 数据集详情 |
|---|---|---|---|
| 模型训练 | Intel Xeon Silver 4210 + NVIDIA RTX 3090 | Ubuntu 22.04,PyTorch 2.3,CUDA 11.2 | YOLO11n Pose:9798 张图像(6:2:2 分拆);MSTBi-LSTM:5000 个 60s 样本(3000:1000:1000 分拆) |
| 模型部署 | NVIDIA Jetson Orin(边缘设备) | Ubuntu 20.04,JetPack 5.1.4,TensorRT 8.5 | ------ |
| 实车测试 | 矿用卡车(配备双目相机) | ------ | 40 名司机 1440h 数据(53% 白天,47% 夜间),600 个分心片段 + 3000 个非分心片段 |
(2)关键实验结果
-
YOLO11n Pose 性能(与同类模型对比):
模型 面部检测 AP50-95(%) 关键点检测 AP50-95(%) 参数量(M) 推理时间(ms) YOLOv8n Pose 89.2 93.0 3.3 1.1 YOLO11n Pose 90.7 94.5 2.9 1.1 YOLO12n Pose 89.2 93.1 2.8 1.7 - 结论:YOLO11n Pose 在检测精度(AP50-95 最高)、参数量(2.9M,低于 YOLOv8n)、推理速度(1.1ms,与 YOLOv8n 相当,快于 YOLO12n)上综合最优。
-
BV-DHPE 与单目方法头部姿态估计误差对比:
评估指标 单目方法(俯仰) BV-DHPE(俯仰) 单目方法(偏航) BV-DHPE(偏航) 单目方法(滚转) BV-DHPE(滚转) MAE(°) 2.0 0.8 1.4 1.0 1.1 0.6 RMSE(°) 2.7 0.9 2.0 1.4 1.3 0.8 最大误差(°) 12.1 3.6 9.3 6.5 7.7 3.5 - 结论:BV-DHPE 在所有维度误差均显著降低,MAE 平均下降 44.7%,抗动态干扰能力更强。
-
RT-DASR 实车测试性能(与单目方法对比):
方法 准确率(%) F1 分数 TPR(%) FPR(%) 推理延迟(ms) 单目方法 80.1 80.3 80.4 19.8 18.2 RT-DASR 90.4 92.3 90.7 8.8 21.5 - 结论:RT-DASR 准确率提升 10.3%,FPR 降低 11.0%(减少误报警),虽延迟增加 3.3ms,但 21.5ms 仍满足实时预警需求。
四、研究结论与未来方向
-
核心结论:
- RT-DASR 通过 BV-DHPE 补偿深度信息、MSTBi-LSTM 融合多源时序特征,实现了矿用卡车驾驶员注意力的高精度(90.4%)、低延迟(21.5ms)检测。
- 边缘部署时,FP16 精度仅导致 0.3% 准确率损失,兼顾性能与硬件资源限制。
-
局限性:
- 极端头部旋转时,关键点匹配易失效,导致误判;
- 矿用卡车场景方法难以迁移至普通轿车(视野、监控需求不同);
- 缺乏统一数据集,无法与现有主流方法直接对比。
-
未来方向:采用多相机构建多视图立体视觉系统,覆盖宽角度头部旋转场景,解决关键点缺失导致的姿态估计失效问题。
好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!