一、前言
本期我们聊一下缓存击穿,其实缓存击穿和缓存穿透很相似,区别就是,缓存穿透是一些黑客故意请求压根不存在的数据从而达到拖垮系统的目的,是恶意的,有针对性的。缓存击穿的情况是,数据确实存在,只不过因为某些原因导致缓存中数据消失了,导致请求到达了数据库,从而导致数据库的崩,下面我们看看这个问题是怎么个情况。
二、问题描述
我们之前也介绍过,缓存和数据库双写一致的事情,一般是如果缓存中不存在的话,就从数据库中再查询一遍,然后将查询到的数据维护到缓存中,等下次请求的时候,就能直接从缓存中获取到了,正常是这么个套路,没毛病。但是我们之前也介绍过,有一些热点数据,在启动的时候就需要加载到缓存中,热点数据的特点就是访问频繁,为了减少数据库压力才放到缓存中,那么如果是热点数据在缓存中失效,那么数据库访问压力就会剧增,情况再糟糕一点,热点数据访问量巨大,那么数据库被拖垮那也是板上钉钉的事情。
那么热点数据为什么会失效?
其中一个原因是缓存过期了,热点数据被设置了过期时间,一旦过期,大量请求达到数据库,压垮数据库。
还有别的原因,缓存搭建了主从结构,主从的数据同步存在延时,导致客户端请求从节点时拿不到数据,或者是主节点使用了rdb备份方式,恰好宕机丢失了一部分数据中包含了热点数据等等,缓存失效的可能原因我们先暂时讨论这么多,这不是我们本次讨论的内容。
三、解决方案
3.1、热点数据设置永不过期
对于热点数据,如果担心因为缓存过期引起击穿,我们可以尝试不设置过期时间,这样就不用担心因缓存过期导致缓存击穿了。
不设置过期时间是个好办法,不过我想既然给设置了过期时间,那么说明确实需要设置过期时间,那么在这种情况下,不设置过期时间就不适用了,我们采取另一种方案。
3.2、互斥锁方案
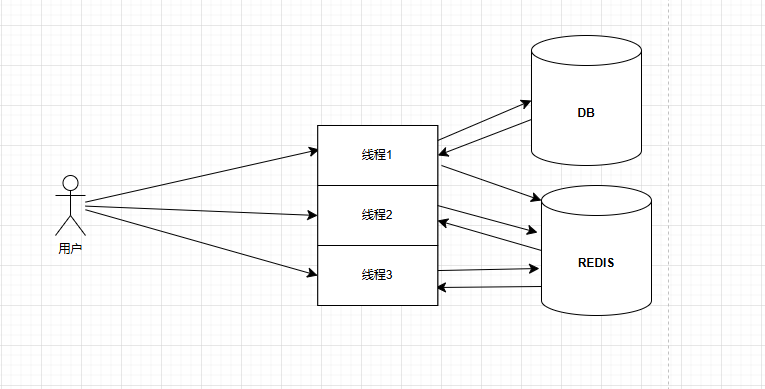
我们再唠叨一下缓存击穿的特点,大量请求达到数据库导致数据库崩溃。那我们简单分析一下,核心问题是大量请求到达数据库,而且这些请求的都是同一个key的数据。
基于上述两点可以想想办法:
首先我们可以基于同一个key进行加锁,保证同一时间只会有一个线程访问数据库。如果某个线程先获取到了锁,先进行一次缓存读取,如果确实没有数据,再去访问数据库,将数据库中的数据加载到缓存中并返回,之后将锁释放。依次往复。为什么要这么做,数据库访问过一次之后,缓存中就会维护好数据,其他的请求当然也没有再访问数据库并维护缓存的必要了。
java
@Test
public void cachePenetrate() throws Exception{
int countNumber = 5;
CountDownLatch countDownLatch = new CountDownLatch(countNumber);
//查询数据
for (int i = 0; i < countNumber; i++) {
new Thread(()->{
Long id = 3L;
String cacheKey = "mutualExclusion:"+id;
String lockKey = "mutualExclusionLock:"+id;
//线程从缓存中获取数据
Object valObj = redisTemplate.opsForValue().get(cacheKey);
String code = "";
if(Objects.isNull(valObj)){
code = mutualExclusion(cacheKey,lockKey, id);
}else {
code = valObj.toString();
}
System.out.println(Thread.currentThread().getName()+"已获取到值:"+code);
countDownLatch.countDown();
},"线程"+(i+1)).start();
}
countDownLatch.await();
}
/**
* 功能描述: 互斥锁解决缓存穿透
* @Author:huhy
* @Date: 2025/4/10 22:38
*/
private String mutualExclusion(String cacheKey,String lockKey,Long id){
//开启分布式锁
RLock lock = redissonClient.getLock(lockKey);
try {
lock.lock();
//在获取锁之后,从缓存中获取一次数据,看看是否已有其他线程写入
Object valObj = redisTemplate.opsForValue().get(cacheKey);
//如果缓存中有数据,则直接返回
if(Objects.nonNull(valObj)){
System.out.println("缓存中已有数据,线程【"+Thread.currentThread().getName()+"】未进行数据库查询");
return valObj.toString();
}
System.out.println("缓存中没有数据,线程【"+Thread.currentThread().getName()+"】正在进行数据库查询并设置缓存");
TSCodeRule tsCodeRule = codeRuleService.selectTSCodeRuleById(id);
//设置过期时间为5秒
redisTemplate.opsForValue().set(cacheKey,tsCodeRule.getCodePrefix(),5,TimeUnit.SECONDS);
}finally {
lock.unlock();
}
return null;
}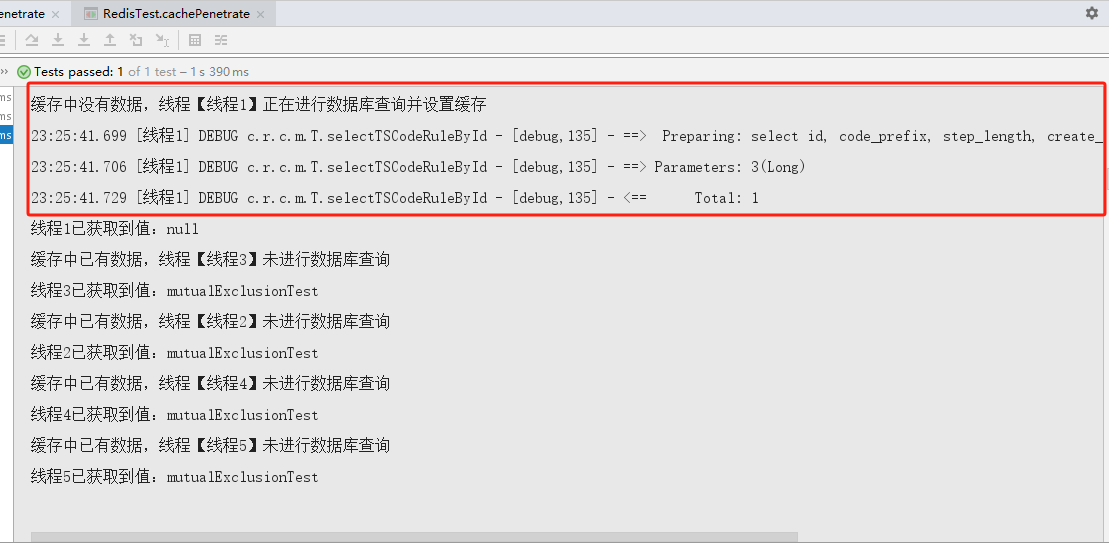
测试代码中,设置了5个线程,只有第一个线程进行了数据库查询,后边的线程都读取到了线程1设置好的缓存数据,减少了数据库的访问压力,算是解决了缓存击穿的问题。
T哥:什么叫算是解决了,那到底解决没啊。
小永哥:被你发现了,解决是解决了,但是我们设置缓存的初衷是什么?不就是看中它快嘛,热点数据本来访问量就大,放到缓存本来就是为了快速响应的,现在好了,加上了锁,都串行化了,那势必会牺牲掉性能。
T哥:别卖关子了,我知道你还有招,赶紧的吧........
小永哥:好的。
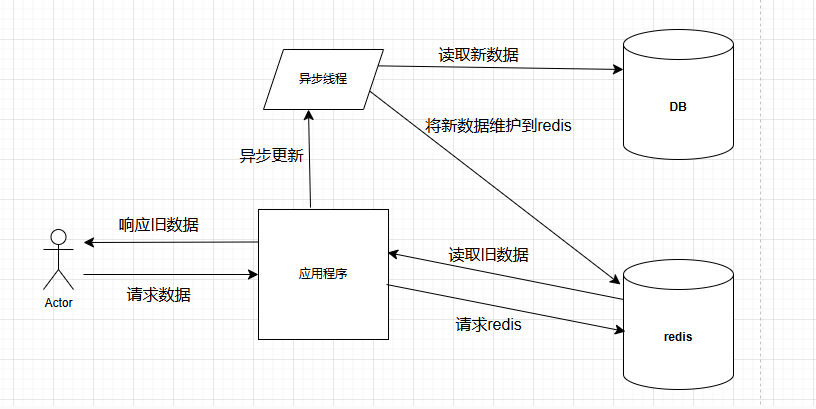
3.3、逻辑过期方案
逻辑过期的意思是:不再设置过期时间,将过期时间与值一起保存到redis中,当应用程序读取到缓存中值的时候,将值中包含的过期时间读取出来进行校验,如果已过期,那么开启新的线程异步去维护缓存数据,而本次还是返回旧数据。这么做的好处是应用程序依旧能保持很高的响应,缺点就是,如果数据库中数据被修改过的话,无法及时返回最新的数据。
java
@Test
public void logicExpireTest() throws Exception{
int countNumber = 50;
CountDownLatch countDownLatch = new CountDownLatch(countNumber);
//查询数据
for (int i = 0; i < countNumber; i++) {
new Thread(()->{
random = new Random();
try {
TimeUnit.SECONDS.sleep(random.nextInt(3) + 1);
}catch (Exception e){}
System.out.println(Thread.currentThread().getName()+"已获取到值:"+getCacheValueByKey(4L));
countDownLatch.countDown();
},"线程"+(i+1)).start();
}
countDownLatch.await();
}
String getCacheValueByKey(Long id){
//从缓存中获取值
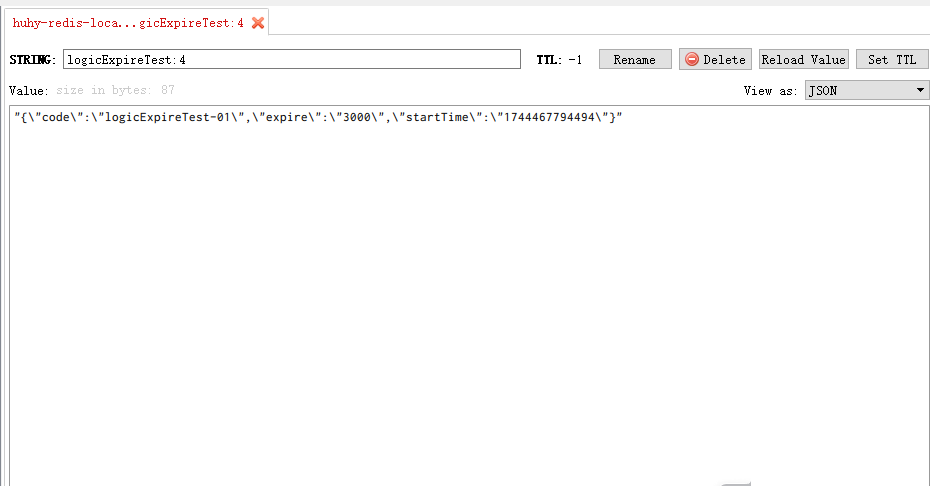
String cacheKey = "logicExpireTest:"+id;
String jsonStr = redisTemplate.opsForValue().get(cacheKey).toString();
Map<String,String> cacheCodeMap = JSON.parseObject(jsonStr,Map.class);
//校验是否已超时
long startTime = Long.parseLong(cacheCodeMap.get("startTime"));
long expire = Long.parseLong(cacheCodeMap.get("expire"));
boolean isExpire = (System.currentTimeMillis() - startTime) > expire;
//如果超时,另起线程去维护redis
if(isExpire){
new Thread(()->{
TSCodeRule tsCodeRule = codeRuleService.selectTSCodeRuleById(id);
Map<String,String> codeInfoMap = new HashMap<>();
codeInfoMap.put("code",tsCodeRule.getCodePrefix());
codeInfoMap.put("expire",String.valueOf(3000));
codeInfoMap.put("startTime",String.valueOf(System.currentTimeMillis()));
redisTemplate.opsForValue().set(cacheKey,JSON.toJSONString(codeInfoMap));
}).start();
}
//始终返回从缓存中读取到的数据
return cacheCodeMap.get("code");
}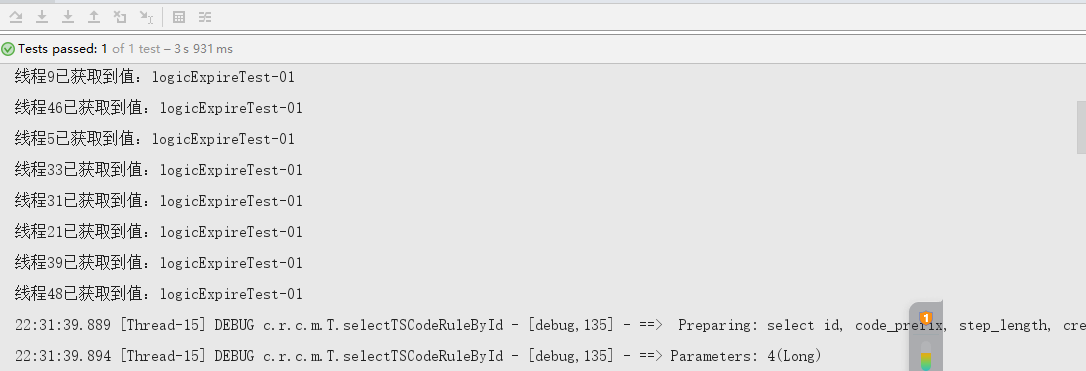
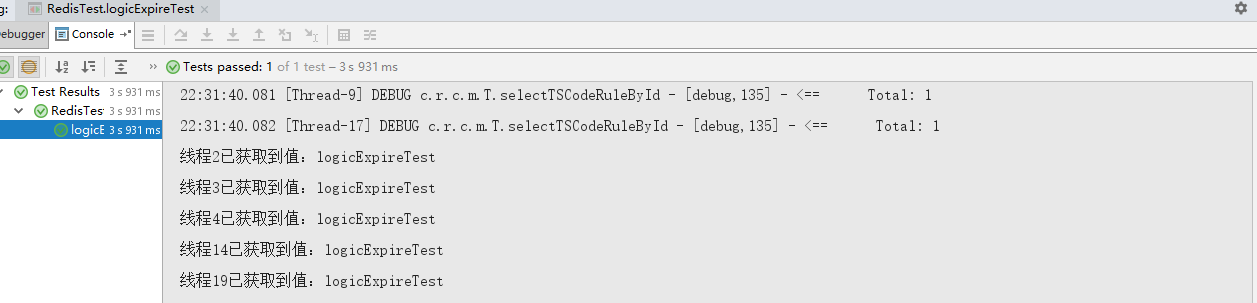
经过运行测试代码,我们可以看到,有的线程是新值,有的是旧值。
四、结语
缓存穿透我们讨论了三种解决方式,这两种方式并没有谁比谁更优秀,没有哪种解决方案是完美的,只有适合应用场景的解决方案,在日常应用时需要我们灵活选择。