目录
[2.1 list的构造](#2.1 list的构造)
[2.2 list iterator](#2.2 list iterator)
[2.3 list capacity](#2.3 list capacity)
[2.4 list element access](#2.4 list element access)
[2.5 list modifiers](#2.5 list modifiers)
[编辑2.5.1 list插入和删除](#编辑2.5.1 list插入和删除)
[2.5.2 insert /erase](#2.5.2 insert /erase)
[2.5.3 resize/swap/clear](#2.5.3 resize/swap/clear)
[2.6 list的一些其他接口](#2.6 list的一些其他接口)
[2.6.1 splice](#2.6.1 splice)
[2.6.2 remove](#2.6.2 remove)
[2.6.3 sort](#2.6.3 sort)
1.迭代器的分类


这里需要说明一些东西:
1.就是下面的是上面的子类:比如双向迭代器是单向迭代器的子类(这个父子类的判断,跟迭代器的功能可没关系,不要说双向迭代器的功能比单向多,就说单向是双向的子类,不是这么来判断的)。
2.还有就是看上面的第二张图,越往后,迭代器的功能就越多,而且,都是对上一个迭代器的功能进行了继承并拓展。比如:双向迭代器的功能有++/--,而单向迭代器有++,双向迭代器是不是继承了单向迭代器的功能,并实现了拓展?是的!
2.list的使用
2.1 list的构造

list<int> l1; // 构造空的l1
list<int> l2(4, 100); // l2中放4个值为100的元素
list<int> l3(l2.begin(), l2.end()); // 用l2的[begin(), end())左闭右开的区间构造l3
list<int> l4(l3); // 用l3拷贝构造l4
list<int> l6={ 1,2,3,4,5 };//初始化列表初始化l6
2.2 list iterator
其实,对于lterator,也就跟前面的那几个一样使用就行,只不过,这里需要注意的是,vector是原生态指针,而list是对原生态指针(节点指针)进行封装,(模板),后面的模拟实现会讲。
注意:遍历链表只能用迭代器和范围for
2.3list capacity

2.4 list element access

2.5 list modifiers
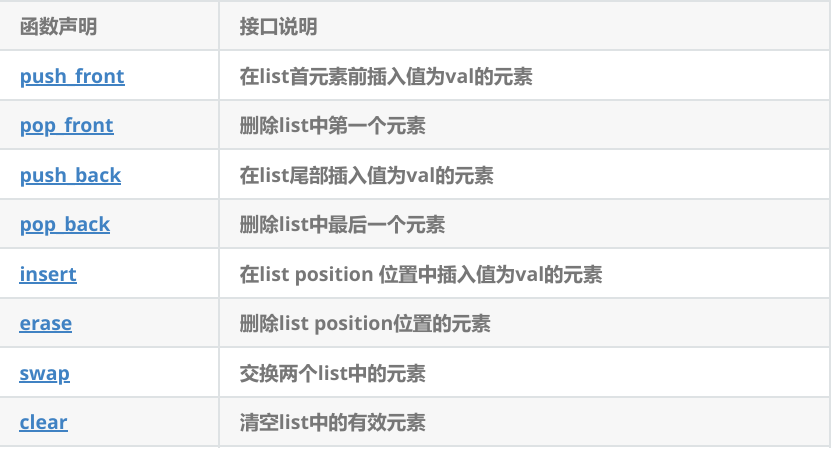 2.5.1 list插入和删除
2.5.1 list插入和删除
push_back/pop_back/push_front/pop_front

2.5.2 insert /erase
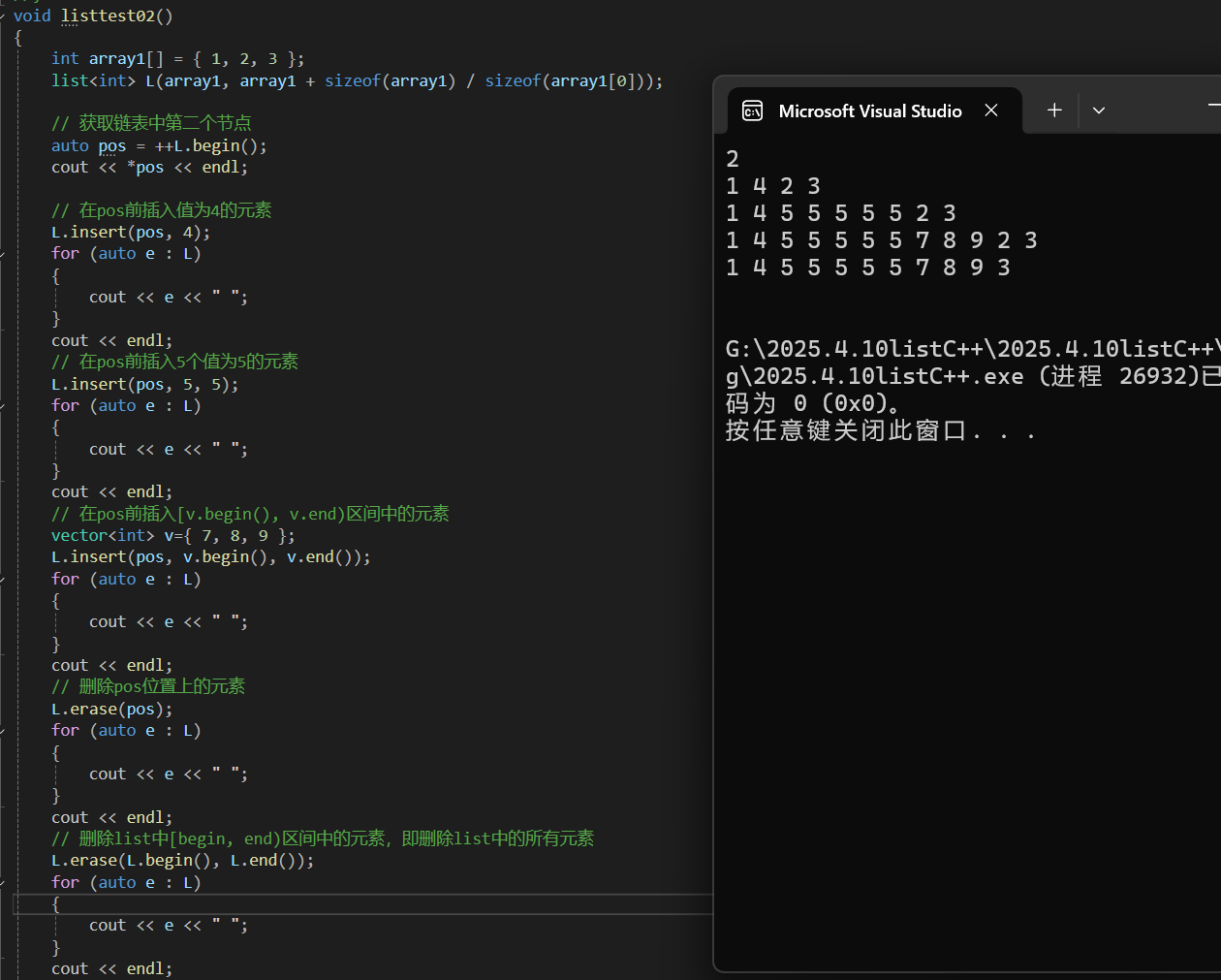
2.5.3 resize/swap/clear
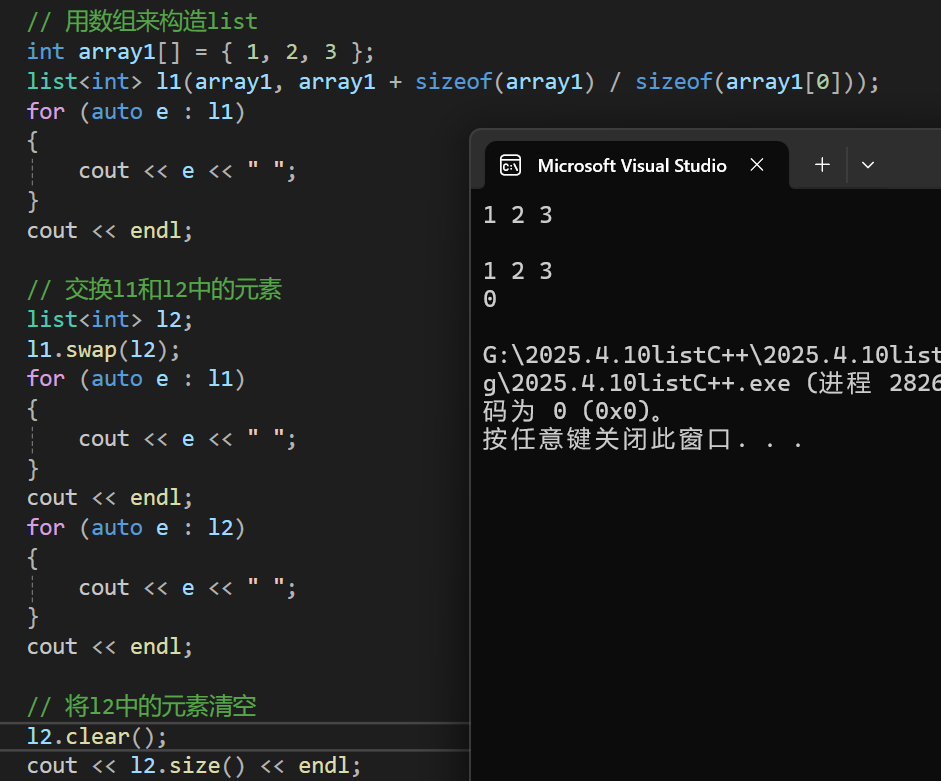
2.6 list的一些其他接口
2.6.1 splice
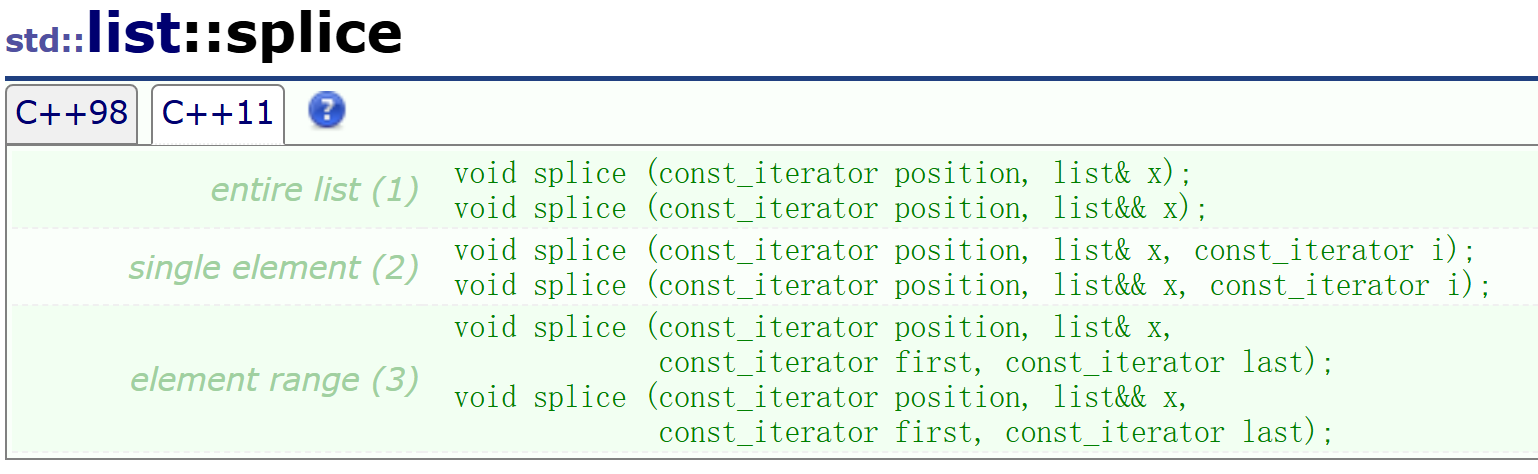
C++11相对于C++98来说增加了一个"模板特化",这个东西咱们后面会出一期模板专题,专门来讲这个模板。那么接下来先不看模板特化,先看引用。
这个接口的作用是将一个链表中的数据裁剪(裁剪后,原链表中的数据将消失),到另一个链表中。接下来看官方库中的代码例子来理解:
std::list<int> mylist1, mylist2; std::list<int>::iterator it; // set some initial values: for (int i=1; i<=4; ++i) mylist1.push_back(i); // mylist1: 1 2 3 4 for (int i=1; i<=3; ++i) mylist2.push_back(i*10); // mylist2: 10 20 30 it = mylist1.begin(); ++it; // points to 2 mylist1.splice (it, mylist2); // mylist1: 1 10 20 30 2 3 4 // mylist2 (empty) // "it" still points to 2 (the 5th element) mylist2.splice (mylist2.begin(),mylist1, it); // mylist1: 1 10 20 30 3 4 // mylist2: 2 // "it" is now invalid. it = mylist1.begin(); std::advance(it,3); // "it" points now to 30 mylist1.splice ( mylist1.begin(), mylist1, it, mylist1.end()); // mylist1: 30 3 4 1 10 20
直接来看mylist1.splice ,这个的意思是将mylist2中的数据剪裁到 it指向的那个数据之前的位置,并将原mylist2中的数据清零。
第二个:将mylist1中的原it指向的数据(2),剪裁到mylist2的begin()指向的位置。
第三个:将mylist1中的从it位置开始,end()结束的数据(30,3,4)剪裁到begin()的位置。
2.6.2 remove
void remove (const value_type& val);
删除链表中值为val的数据。
2.6.3 sort
 其实list中的sort无法使用算法库中的sort,因为算法库中的sort实现是靠+/-来实现,但是list迭代器不支持+/-,而且,相对于vector来说,list的sort排序,特别对于一些特别大的数据来说,效率 会很低。
其实list中的sort无法使用算法库中的sort,因为算法库中的sort实现是靠+/-来实现,但是list迭代器不支持+/-,而且,相对于vector来说,list的sort排序,特别对于一些特别大的数据来说,效率 会很低。
3.list的模拟实现
其实,list的模拟实现还是比较难的,咱们以前模拟实现的vector,string难在它的实现上面,而list的模拟实现难在它的实现框架上面,那么下面让博主来帮助你们理解吧。

这个分为三个重要的模板。
1.一个是对于链表中的节点的模板(因为数据T可能有不同的类型)
2.一个是对于迭代器实现的模板,那这时候就要有人问了:以前的vector不是没有迭代器实现模板吗?这不一样,list的迭代器是对原生态指针的封装,就是一个模板。而且,在这里的iterator相当于是类了,就是好像不再是指针,但还是具有指针的效果。
3.最后一个就是整个的list链表它也是一个模板。
那么接下来让咱们来看看模板吧,等会我会把为什么这么写的目的,以及细节全部讲透。
//这是第一个类模板
template<class T>
struct list_node
{
list_node* _next;
list_node* _prev;
T _data;//注意,这里的_data是模板数据,后面会用到这个知识点。
list_node(const T& x = T())//初始化
:_next(nullptr)
,_prev(nullptr)
,_data(x)
{}
};
//这是第二个类模板// typedef list_iterator<T, T&, T*> iterator;
// typedef list_iterator<T, const T&, const T*> const_iterator;
template<class T, class Ref, class Ptr>
struct list_iterator
{
typedef list_node<T> Node;
typedef list_iterator<T, Ref, Ptr> Self;
Node* _node;
list_iterator(Node* node)//初始化
:_node(node)
{}
};
//这是第三个类模板
template<class T>
class list
{
typedef list_node<T> Node;
public:
typedef list_iterator<T, T&, T*> iterator;
//typedef list_const_iterator<T> const_iterator;
typedef list_iterator<T, const T&, const T*> const_iterator;
List() //初始化
{
_head = new Node;
_head->_prev = _head;
_head->_next = _head;
_size = 0;
}
private:
Node* _head;
size_t _size;
};
每一个类或者类模板写出来后,一定要记得初始化,这里需要注意一点,也是我写代码的时候发现的:当你写一个类的时候,一定要注意,这个类的构造尤其重要,就比如我这个,我如果说不写这个构造的话,那么编译器会默认构造,那么_head就是空,你是在end()位置插入,也就是_head位置,你的_head还是空,当你的pos._node获得节点的时候,这个还是空呢,是访问不了任何成员的。因为下面要用到cur去访问,所以记住,空节点访问不了任何成员 。
这个注意事项涉及到insert的模拟实现的,所以在这里咱们先把insert的模拟实现写了。
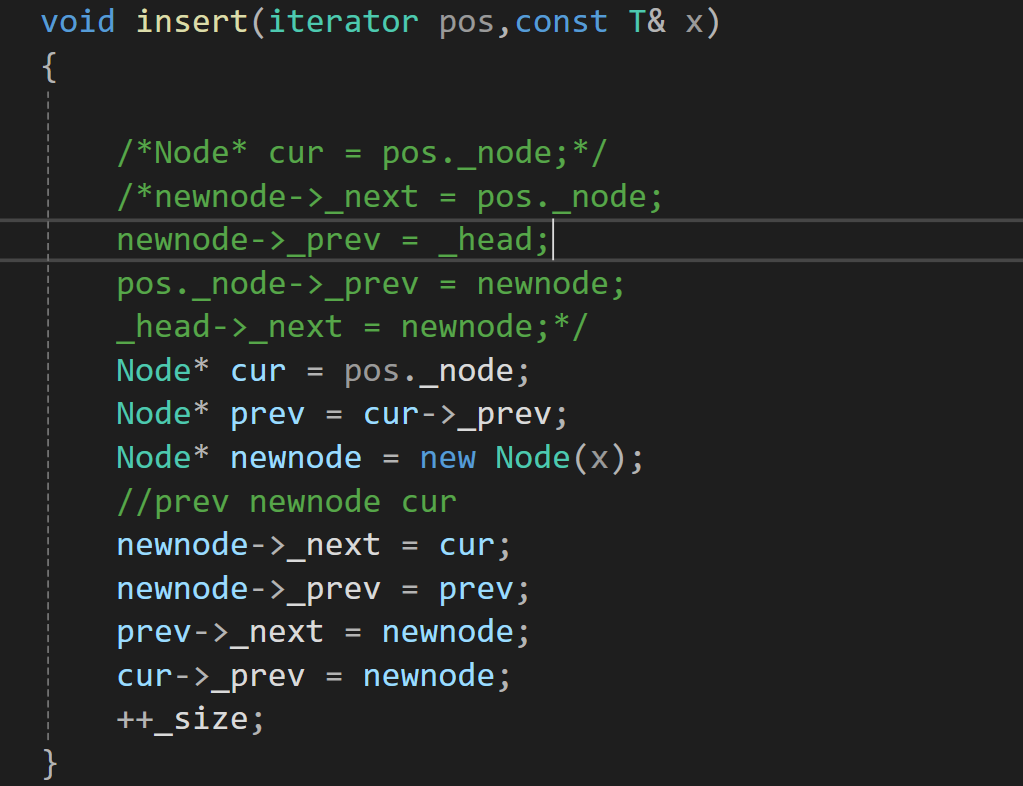
这里涉及到几个老生常谈的问题:
1.连接链表的时候的顺序问题,一般先将新插入的链表连接好,(当然,你要是说先将各个要用到的节点重新定义一下,那就不要管顺序的问题了),顺序的问题就是为了避免有找不到节点的情况出现。
2.这里的pos是迭代器类型,不是说迭代器是指针嘛?怎么访问它的成员变量不应该用->嘛?怎么用"."呢?这个问题,咱们后面跟另外一个问题一起将。 (标题:最后一个问题处)
好,那么咱们接下来接着往后看模拟实现:
第一个类模板已经实现完了,接下来看第二个类模板的实现:
// typedef list_iterator<T, T&, T*> iterator;
// typedef list_iterator<T, const T&, const T*> const_iterator;
template<class T,class Ref,class Ptr>
struct list_iterator
{
typedef list_node<T> Node;
typedef list_iterator<T, Ref, Ptr> Self;
Node* _node;//定义一个节点
list_iterator(Node* node)
:_node(node)//初始化那个节点
{}
Ref operator*()
{
return _node->_data;
}
Ptr operator->()
{
return &_node->_data;
}
//前置++
Self& operator++()
{
_node = _node->_next;
return *this;
}
//后置++
Self operator++(int)
{
Self tmp(*this);
_node = _node->_next;
return tmp;
}
//前置--
Self& operator--()
{
_node = _node->_prev;
return *this;
}
//后置--
Self operator--(int)
{
Self tmp(*this);
_node = _node->_prev;
return tmp;
}
bool operator!=(const Self &s) const//lt.end()这是个迭代器类型啊,肯定是Self&,怎么能是List<T>呢?
{
return _node != s._node;
}
bool operator==(const Self& s) const
{
return _node == s._node;
}
};
这里由于放图片,代码太长,影响观看,所以直接用块引用。
1.这个T,Ref,Ptr 都是指代的什么东西呀?首先,这是一个类模板,所以说,这三个肯定都是指代的一类东西。根据上面的两行代码可知,T就是_data的类型,而Ref是T&或const T&,所以知道为什么要写成模板了吧,你要是不写模板,就要实现两次关于T&以及const T&的代码,造成代码冗余。Ptr同理。
2.对于list这样对原生态指针进行封装(类模板)的,都是不可以直接使用*以及->的,都需要自己去自定义实现。这里的typedef也是为了避免代码的冗余。
3.*是对一个指针的解引用,拿到的是数据,所以说,用的是Ref(即T&或const T&),->跟*一样,都是访问元素的操作。只不过在标准迭代器设计中,->应该返回容器中元素的地址(指针)。
一个是元素的地址,一个是元素的引用,返回的都跟元素有关,所以说,是跟T(数据)有关。
4.而++,--,这个是返回的是迭代器本身,因为`operator++`的作用是移动迭代器到下一个位置。
就是移动倒了下一个节点。所以返回`Self`或`Self&`确保了迭代器类型的正确性。如果返回`Ref`或`Ptr`,则会导致类型不匹配。
可以这么理解,就是从小到大,小就是节点中的数据的访问就是返回的是Ref以及Ptr,而大就是整个节点的移动。
5.判断两个节点是否相等,传参用的是self,因为判断节点时候相等,本来就是判断连那两个迭代器是否相等(节点中的元素),因为对元素的访问用的就是迭代器。
好了,这个类模板中的问题我已经说清楚了,接下来看最后一个类模板。
template<class T>
class list
{
typedef list_node<T> Node;
public:
typedef list_iterator<T, T&, T*> iterator;
typedef list_iterator<const T, const T&, const T*> const_iterator;
iterator begin()
{
return iterator(_head->_next);
}
iterator end()
{
return iterator(_head);//注意是_head,不是_head->_prev
}
const_iterator begin() const //后面的这个const 不能忘了
{
return const_iterator(_head->_next);
}
const_iterator end() const
{
return const_iterator(_head);//注意是_head,不是_head->_prev
}
/*~list()
{
_data = nullptr;
_head->_next = _head->_prev = _head;
}*/
//你这个写的不是析构,顶多算是初始化,只有一个哨兵位。
~list()
{
clear();
delete _head;
_head = nullptr;//别忘了置为空
}
//拷贝构造
list(List<T>& s)
{
_head = new Node;
_head->_next = _head;
_head->_prev = _head;
_size = 0;
for (auto& e : s)
{
push_back(e);
}
}
//lt2=lt3
list<T>& operator=(List<T> ta)
{
swap(ta);
return *this;
}
void swap(List<int>& ta)
{
std::swap(_head, ta._head);
std::swap(_size, ta._size);
}
list(initializer_list<T> il)//列表初始化的模拟实现
{
_head = new Node;
_head->_next = _head;
_head->_prev = _head;
_size = 0;
for (auto& e : il)
{
push_back(e);
}
}
void clear()//clear的模拟实现
{
List<int>::iterator it = begin();
while (it != end())
{
it=erase(it);
it++;
}
}
//当你写一个类的时候,一定要注意,这个类的构造尤其重要
//就比如我这个,我如果说不写这个构造的话,那么编译器会默认构造,那么_head就是空
//你是在end()位置插入,也就是_head位置,你的_head还是空,
//当你的pos._node获得节点的时候,这个还是空呢,是访问不了任何成员的。
list() //因为下面要用到cur去访问,所以记住,空节点访问不了任何成员
{
_head = new Node;
_head->_prev = _head;
_head->_next = _head;
_size = 0;
}
void insert(iterator pos,const T& x)
{
/*Node* cur = pos._node;*/
/*newnode->_next = pos._node;
newnode->_prev = _head;
pos._node->_prev = newnode;
_head->_next = newnode;*/
Node* cur = pos._node;
Node* prev = cur->_prev;
Node* newnode = new Node(x);
//prev newnode cur
newnode->_next = cur;
newnode->_prev = prev;
prev->_next = newnode;
cur->_prev = newnode;
++_size;
}
iterator erase(iterator pos)
{
assert(pos != end());
Node* cur = pos._node;
Node* next = cur->_next;//这儿有错
Node* prev = cur->_prev;
next->_prev = prev;
prev->_next = next;
delete cur;
cur = nullptr;
--_size;
return next;
//return iterator(next)
//这样写也可以,第二种写法,这个类型也是iterator的,正好
//第一种写法也可以,只不过单参数返回支持隐式类型转换,所以说也不要担心他的类型问题。
}
void push_back(const T& x)
{
insert(end(), x);
}
void push_front(const T& x)
{
insert(begin(), x);
}
void pop_back()
{
erase(--end());
}
void pop_front()
{
erase(begin());
}
private:
Node* _head;
size_t _size;
};
1.为什么这里的erase返回的是next(下一个位置)?而vector中返回的是原位置?这里都涉及到迭代器失效的问题,不过呢,vector的底层是数组啊,底层是连续的,而且它的erase后,后面的元素都得往前移动一个,所以说vector的erase返回的还是下一个元素位置,只不过下一个元素的位置现在是被删除元素的位置。而list的erase后,所有的元素的位置并不发生任何变化,所以说这个返回的是真真正正的下一个元素的位置。
2.list迭代器失效:
前面说过,此处大家可将迭代器暂时理解成类似于指针,迭代器失效即迭代器所指向的节点的无 效,即该节点被删除了。因为list的底层结构为带头结点的双向循环链表,因此在list中进行插入 时是不会导致list的迭代器失效的,只有在删除时才会失效,并且失效的只是指向被删除节点的迭 代器,其他迭代器不会受到影响。
3.这里有些博友可能会有些疑问:iterator begin()不是迭代器嘛?不是应该定义在iterator那个模板中嘛?为什么会出现在list这个大模板中?
首先,begin()和end()是容器的成员函数,属于容器的接口,用于获取容器的起始和结束迭代器。迭代器类本身不负责管理容器的元素范围,它只负责遍历和访问元素。因此,begin()的位置应该在容器类中,而不是迭代器类里。
其次:迭代器的作用是提供一种访问容器元素的方法,但它并不了解容器的内部结构,比如链表的头节点_head的位置。只有容器自己知道如何获取起始和结束的位置,所以容器必须提供这些方法。如果让迭代器自己生成begin(),它需要访问容器的私有成员(如_head),这会破坏封装性,或者需要将迭代器设为容器的友元,增加耦合。
总结下来就是list中实现的是整个迭代器,而iterator中实现的是迭代器对元素的访问,并不关心整个迭代器是怎么运行的,搭建的,它只关心怎么访问数据。其实这种设计符合面向对象的原则,容器管理数据,迭代器提供访问方式,各司其职。
好,还剩下几个问题,把他们说清楚:
1.为什么前两个模板都是使用struct?使用class不可以吗?
首先看list_node结构体,它有三个成员变量:_next、_prev和_data,构造函数也是public的。如果用class的话,默认是private,需要显式声明public才能让外部访问这些成员。而用struct的话,构造函数和成员变量默认都是public的,这样在list类中可以直接访问这些成员,比如在list的insert或erase函数里,可以直接操作节点的_next和_prev指针。为了更方便的访问成员变量,且要频繁的访问成员变量,就将那个类置为struct。
struct用于那些需要所有成员公开的情况,比如节点和迭代器,而class用于需要封装的情况,比如容器本身。这样的选择主要是基于默认访问权限的不同,简化代码的同时保持必要的封装性。
2.这三个模板写一块不可以吗?为什么要分开写?
首先,我需要确认这三个模板各自的职责:
-
**list_node**:通常是一个结构体,包含数据和指向前后节点的指针,作为链表的节点。
-
**list_iterator**:迭代器类,用于遍历链表,提供操作符重载如++、--、*、->等。
-
**list**:链表类本身,管理节点的创建、删除,提供插入、删除等接口。
而之所以不把他们设置为一个类,是因为你的class中的成员变量不想被别人访问,但是你的其他的类中的成员变量确实被频繁访问,要是都放到一个类中,那肯定就混乱了。
其实就是每个模板负责不同的职责,分离关注点,符合良好的面向对象设计原则。
4.最后一个问题
先来看一段代码:
struct AA
{
int _a1;
int _a2;
AA(int a1 = 1, int a2 = 1)
:_a1(a1)
,_a2(a2)
{}
};
list<AA> lt1;
lt1.push_back({ 1,1 });
lt1.push_back({ 2,2 });
lt1.push_back({ 3,3 });
list<AA>::iterator lit1 = lt1.begin();
while (lit1 != lt1.end())
{
//cout << (*lit1)._a1 <<":"<< (*lit1)._a2 << endl;
// 特殊处理,省略了一个->,为了可读性
cout << lit1->_a1 << ":" << lit1->_a2 << endl;
cout << lit1.operator->()->_a1 << ":" << lit1.operator->()->_a2 << endl;
++lit1;
}
cout << endl;
1.好,咱们先来处理那个遗留下来的问题: 为什么pos后要用"."来访问成员变量,首先:这个地方iterator是一个类,不是指针,所以,pos是这个类实例化出的对象,所以现在知道这里为什么用"."来访问成员变量了吧。
2.这里,原先咱们说T是一个数据类型对吧,那么这里的AA就是_data,所以,_data中还有数据:_a1,_a2。所以,这里_data就是一个struct类。
2.1先来看注释掉的那个代码,其实是调用了operator*,返回的是AA&,而AA又是一个类,所以访问其中的元素就是用到了"."。
2.2
-> 用于指针 :当变量是指向结构体/类类型的指针时,用 -> 访问成员(等价于 (*lit1)._a1)。
lit1.operator->()->_a1是类实例化出的lit1对象,先调用operator->()重载,返回的是AA*,而AA(data)是个类,所以再次访问AA类中的成员变量需要用到>。
其实这个等价于lit1._node->_data._a1。
且 lit1.operator->()->_a1简写就是lit1->_a1。
lit1->_a1:调用 list_iterator::operator->(),返回指向当前节点数据(AA 对象)的指针(AA*)。等价代码:AA* ptr = &(lit1._node->_data); // operator-> 返回 &_data cout << ptr->_a1 << ":" << ptr->_a2 << endl;
ok,那么关于这个模块的所有问题我已经讲清楚了,各位如果能看到最后,那么经过我的讲解,一定可以理解这些问题。
本篇完...................