粒子群优化算法(PSO)详解与Python实现
文章目录
前言
大家好,今天我想和大家分享一下粒子群优化算法(Particle Swarm Optimization, PSO)的基本原理和实现方法。作为一种受自然界鸟群觅食行为启发的智能优化算法,PSO因其简单高效的特点在机器学习、神经网络训练、函数优化等领域有着广泛应用。
1. 粒子群算法简介
粒子群优化算法 是由Kennedy和Eberhart于1995年提出的一种群体智能 优化算法。它模拟了鸟群的社会行为,如鸟在寻找食物时的协作方式。在PSO中,每个候选解被视为一个"粒子",所有粒子在搜索空间中移动,并根据自身经验 和群体经验不断调整位置,最终找到最优解。
2. 算法原理
2.1 基本概念
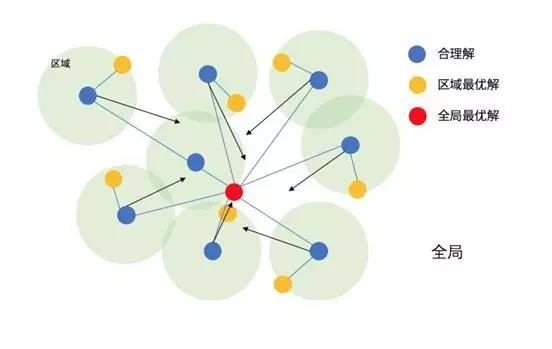
- 粒子(Particle): 搜索空间中的一个候选解
- 位置(Position): 粒子在搜索空间中的坐标,代表一个可能的解
- 速度(Velocity): 粒子移动的方向和步长
- 个体最优解(pbest): 粒子历史上找到的最优位置
- 全局最优解(gbest): 整个群体历史上找到的最优位置
- 适应度函数(Fitness Function): 用于评价粒子位置好坏的函数
2.2 更新公式
粒子的位置和速度更新公式如下:
v i ( t + 1 ) = w ∗ v i ( t ) + c 1 ∗ r 1 ∗ ( p i b e s t − x i ( t ) ) + c 2 ∗ r 2 ∗ ( g b e s t − x i ( t ) ) v_i(t+1) = w * v_i(t) + c_1 * r_1 * (p^{best}_i - x_i(t)) + c_2 * r_2 * (g^{best} - x_i(t)) vi(t+1)=w∗vi(t)+c1∗r1∗(pibest−xi(t))+c2∗r2∗(gbest−xi(t))
x i ( t + 1 ) = x i ( t ) + v i ( t + 1 ) x_i(t+1) = x_i(t) + v_i(t+1) xi(t+1)=xi(t)+vi(t+1)
其中:
- v i ( t ) v_i(t) vi(t)和 x i ( t ) x_i(t) xi(t)分别是粒子 i i i在 t t t时刻的速度和位置
- w w w是惯性权重,控制粒子保持原来运动方向的程度
- c 1 c_1 c1和 c 2 c_2 c2是加速常数,分别控制粒子向个体 最优解和全局最优解移动的程度
- r 1 r_1 r1和 r 2 r_2 r2是 ( 0 , 1 ) (0,1) (0,1)之间的随机数,增加搜索的随机性
- p i b e s t p^{best}_i pibest是粒子 i i i的个体最优位置
- g b e s t g^{best} gbest是群体的全局最优位置
3. Python实现
下面是一个简单的Python实现,用于求解函数f(x,y) = x^2 + y^2的最小值:
python
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation
# 定义目标函数
def objective_function(x, y):
return x**2 + y**2
# 粒子群优化算法
class PSO:
def __init__(self, n_particles, n_iterations, bounds, w=0.5, c1=1, c2=2):
self.n_particles = n_particles # 粒子数量
self.n_iterations = n_iterations # 迭代次数
self.bounds = bounds # 搜索空间边界
self.w = w # 惯性权重
self.c1 = c1 # 个体学习因子
self.c2 = c2 # 社会学习因子
# 初始化粒子位置和速度
self.positions = np.random.uniform(bounds[0], bounds[1], (n_particles, 2))
self.velocities = np.random.uniform(-1, 1, (n_particles, 2))
# 初始化个体最优位置和适应度
self.pbest_positions = self.positions.copy()
self.pbest_values = np.array([objective_function(p[0], p[1]) for p in self.positions])
# 初始化全局最优位置和适应度
self.gbest_index = np.argmin(self.pbest_values)
self.gbest_position = self.pbest_positions[self.gbest_index].copy()
self.gbest_value = self.pbest_values[self.gbest_index]
# 存储每次迭代的位置,用于可视化
self.history = [self.positions.copy()]
self.gbest_history = [self.gbest_value]
def update(self):
for i in range(self.n_iterations):
# 更新速度
r1, r2 = np.random.random(2)
self.velocities = (self.w * self.velocities +
self.c1 * r1 * (self.pbest_positions - self.positions) +
self.c2 * r2 * (self.gbest_position - self.positions))
# 更新位置
self.positions += self.velocities
# 边界处理
self.positions = np.clip(self.positions, self.bounds[0], self.bounds[1])
# 计算新位置的适应度
current_values = np.array([objective_function(p[0], p[1]) for p in self.positions])
# 更新个体最优
improved_indices = current_values < self.pbest_values
self.pbest_positions[improved_indices] = self.positions[improved_indices].copy()
self.pbest_values[improved_indices] = current_values[improved_indices]
# 更新全局最优
min_index = np.argmin(self.pbest_values)
if self.pbest_values[min_index] < self.gbest_value:
self.gbest_position = self.pbest_positions[min_index].copy()
self.gbest_value = self.pbest_values[min_index]
# 保存历史
self.history.append(self.positions.copy())
self.gbest_history.append(self.gbest_value)
def get_result(self):
return self.gbest_position, self.gbest_value
# 运行PSO
bounds = [-5, 5] # 搜索范围
pso = PSO(n_particles=20, n_iterations=50, bounds=bounds)
pso.update()
best_position, best_value = pso.get_result()
print(f"最优解: x={best_position[0]:.6f}, y={best_position[1]:.6f}")
print(f"最优值: {best_value:.6f}")4. 算法可视化
为了更直观地理解PSO的搜索过程,我们可以添加可视化代码:
python
# 绘制收敛曲线
plt.figure(figsize=(10, 6))
plt.plot(pso.gbest_history)
plt.xlabel('迭代次数')
plt.ylabel('全局最优值')
plt.title('PSO收敛曲线')
plt.grid(True)
plt.show()
# 创建搜索空间的3D图
fig = plt.figure(figsize=(10, 8))
ax = fig.add_subplot(111, projection='3d')
# 创建网格
x = np.linspace(bounds[0], bounds[1], 100)
y = np.linspace(bounds[0], bounds[1], 100)
X, Y = np.meshgrid(x, y)
Z = objective_function(X, Y)
# 绘制曲面
ax.plot_surface(X, Y, Z, cmap='viridis', alpha=0.5)
# 绘制粒子最终位置
final_positions = pso.history[-1]
final_values = np.array([objective_function(p[0], p[1]) for p in final_positions])
ax.scatter(final_positions[:, 0], final_positions[:, 1], final_values, color='red', s=50, label='粒子')
# 绘制全局最优解
ax.scatter(best_position[0], best_position[1], best_value, color='blue', s=100, label='全局最优解')
ax.set_xlabel('X')
ax.set_ylabel('Y')
ax.set_zlabel('f(X,Y)')
ax.set_title('粒子群优化算法 - 3D可视化')
ax.legend()
plt.show()5. PSO的优缺点
优点
- 算法结构简单,易于实现
- 参数少,调整方便
- 基于群体智能,具有较强的全局搜索能力
- 不需要目标函数的梯度信息,适用范围广
缺点
- 容易早熟收敛,陷入局部最优
- 收敛速度在迭代后期可能变慢
- 参数设置对算法性能影响较大
- 对于高维复杂问题,性能可能不如其他高级优化算法
6. 改进策略
为了克服PSO的缺点,研究人员提出了多种改进策略:
- 线性递减惯性权重:随着迭代进行,逐渐减小惯性权重,平衡全局与局部搜索能力
- 自适应参数调整:根据搜索过程动态调整参数
- 多种群策略:使用多个子群体并行搜索,增加多样性
- 混合算法:与其他优化算法(如遗传算法)结合,取长补短
7. 应用领域
粒子群算法在许多领域都有广泛应用:
- 神经网络训练
- 特征选择
- 聚类分析
- 路径规划
- 参数优化
- 电力系统优化
- 机器人控制
- 图像处理
总结
粒子群优化算法作为一种简单而强大的优化工具,在解决复杂优化问题方面表现出色。它的简洁性、易实现性和良好的全局搜索能力使其成为科研和工程领域的热门选择。尽管存在一些局限性,但通过各种改进策略,PSO仍然是现代优化算法家族中的重要一员。
希望这篇文章能帮助你理解粒子群算法的基本原理和实现方法。如果有任何问题,欢迎在评论区留言讨论!