《Adaptive Mixtures of Local Experts》
- 前言
- 一、让协同学习竞争
-
- [1.1 方案](#1.1 方案)
- [1.2 方案演变的由来](#1.2 方案演变的由来)
- 二、让竞争学习协同
-
- [2.1 竞争学习](#2.1 竞争学习)
- [2.2 竞争学习协同](#2.2 竞争学习协同)
- 三、案例验证
-
- [3.1 任务背景](#3.1 任务背景)
- [3.2 实验结果](#3.2 实验结果)
- [3.3 后续工作 (Future Work)](#3.3 后续工作 (Future Work))
前言
论文提出了一个基于多个分离网络的有监督学习方案,该方案可以解决整个训练集中的子集问题.该方案既可以看做多层有监督网络模块的版本,也可以看作是竞争学习的协同版本.该方案将这个两个看似差异很大的版本联系了起来.最后使用元音分辨任务对该方案进行了验证与说明,其具体方法是通过将元音任务拆分为几个子任务,每个子任务由一个简单的专家网络负责.
一、让协同学习竞争
1.1 方案
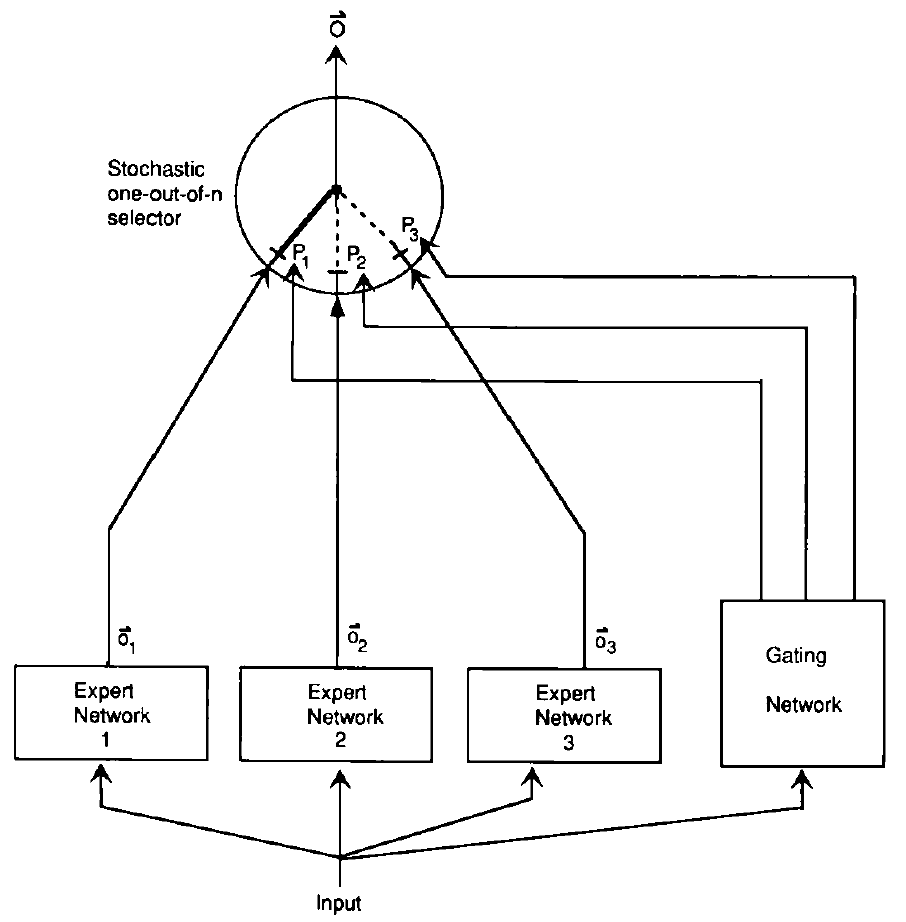
其整体方案如下图所示,输入给到多个专家网络,每个会获得一个输出,同时输入还会给到一个门控网络,门控网络输出专家个数的概率,每个概率对应一个专家,该概率代表了该专家被选择作为输出的概率.比如下图所示就是选择了1号专家的输出作为最终输出,其被选择的概率为p1.
1.2 方案演变的由来
在这篇论文之前已有类似的方案,但是其loss函数方式是让每个专家都预测一部分加起来得到完整的预测.这种方法相当于加强了各专家之间关联程度,一旦某一个专家发生大的波动,剩余专家也会受到较大影响.从理论角度看,该公式的学习目标,每一个专家学习的是其余专家与标签的残差.这样的专家之间的协调作用更强,那么本文的作者更希望专家之间的独立性增强,一些专家能够处理特定的场景 .因此对loss进行了改进.
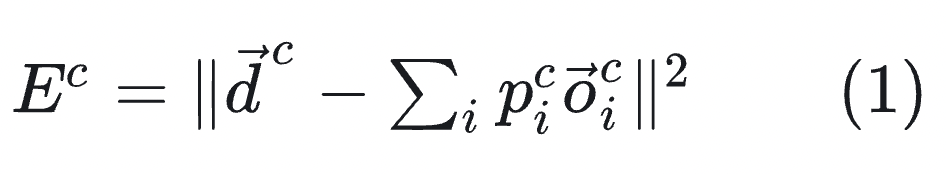
其改进loss如下所示,新的loss下,要求每个专家输出完整的预测,每个专家有一定概率被选中作为目标预测,将各专家协作的关系变为了竞争的关系.这样的话一个专家的预测不再直接受到其它专家权重输出的影响 .
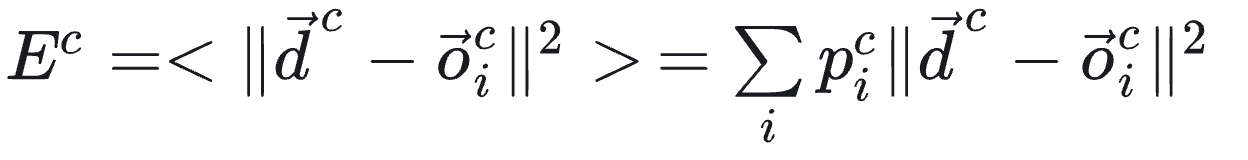
因为专家训练与门控网络训练是一起进行的,这样当一个专家的预测误差更小时,门控网络会给其更大的权重,反正会减小其权重.
在实际应用中本文使用了一个更优的loss如公式(3),对原loss采用了取负,指数与log处理,其两者导数对比如下,前者就是简单的专家输出误差与权重,而后者引入了其它专家的重要性来对比当前专家的重要性,使得当前专家知道自己是否更重要 ,进而指导它面对当前的case,是否应该大力更新自己的权重。特别是在训练的早期,相比于公式(4)的梯度计算方式,后者可以让模型更快地拟合 。
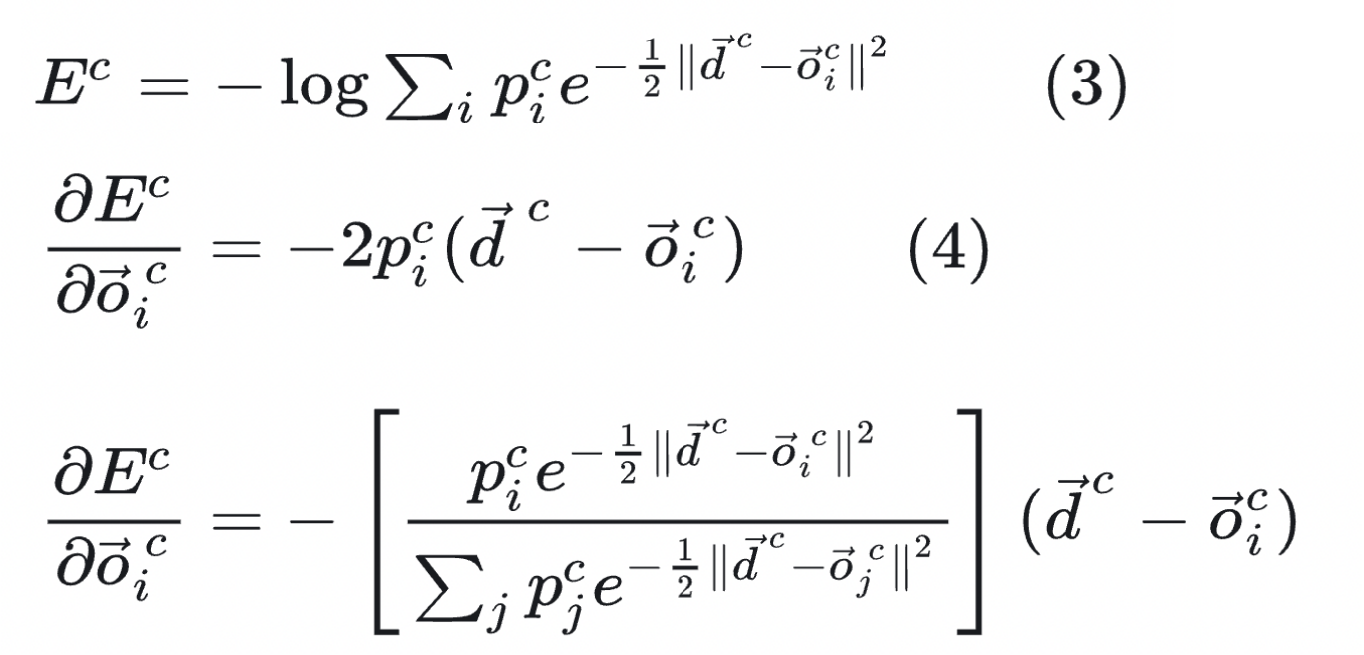
二、让竞争学习协同
2.1 竞争学习
在竞争学习架构中,通过对所有类的对数概率 l o g P c logP^c logPc来选择最优类(例如概率最大的类)实现竞争学习,对数概率由一个带加权的高斯核函数模型得到,其具体含义是每个神经元i通过的其权重向量 μ i \mu_i μi 衡量样本 o c o^c oc的匹配程度, p i p_i pi是选中i的概率,全部加起来为1,k为标准化常数。
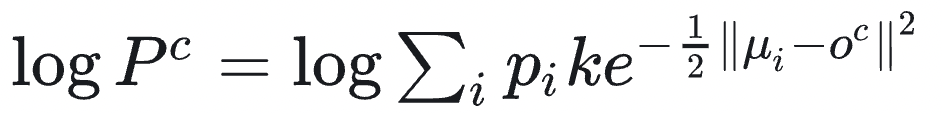
- 软竞争学习是通过学习调整权重,提高被选中的概率
- 硬竞争学习是忽略多个隐藏单元的输出,而是由最接近的隐藏单元得到
2.2 竞争学习协同
本文的方案是将隐藏单元替换为专家,其输出代表了多维高斯分布的均值,因此当前输入函数是由场景代表而不是权重.同时还使用了门控网络,由输入决定各专家的混合比例,这使得竞争学习之间具备一定协同能力.
三、案例验证
3.1 任务背景
元音辨别任务,元音为i,I,a,A四个,数据由75个录音员(包含老青少)
3.2 实验结果
其训练测试指标不变,看四个不同方案达到该指标的训练批次与时间,其中方案分别为4,8个神经网络专家,6,12层隐藏层的BP(反向传播网络),可以看到8个专家方案的批次,时间(SD)都是最少的.

现在来看一下各专家表现,以4个专家的方案为例,其中点带label的为样本点,Net 0,1,2为专家分界线,没有第四个专家,因为其权重为0,相当于没有起作用 ;gate 0:2线是0,2专家的门控分界线,在其左侧专家2权重更大,右侧专家0权重更大,因此元音a,A的分界线其左侧为专家2的线,右侧为专家0的线构成.

3.3 后续工作 (Future Work)
作者建议了一些未来研究方向:
- 扩展至更复杂任务: 探索AMLE在结构化数据、时间序列和多模态任务中的应用。
- 改善训练算法: 提升门控网络和专家模型的优化效率。
- 进一步理论分析: 深入研究模型对深度学习中表示学习的影响。