
🐇明明跟你说过:个人主页
🏅个人专栏:《深度探秘:AI界的007》 🏅
🔖行路有良友,便是天堂🔖
目录
[1、什么是Lang Chain](#1、什么是Lang Chain)
1、开发环境配置(Python、LangChain、LLM模型选择)
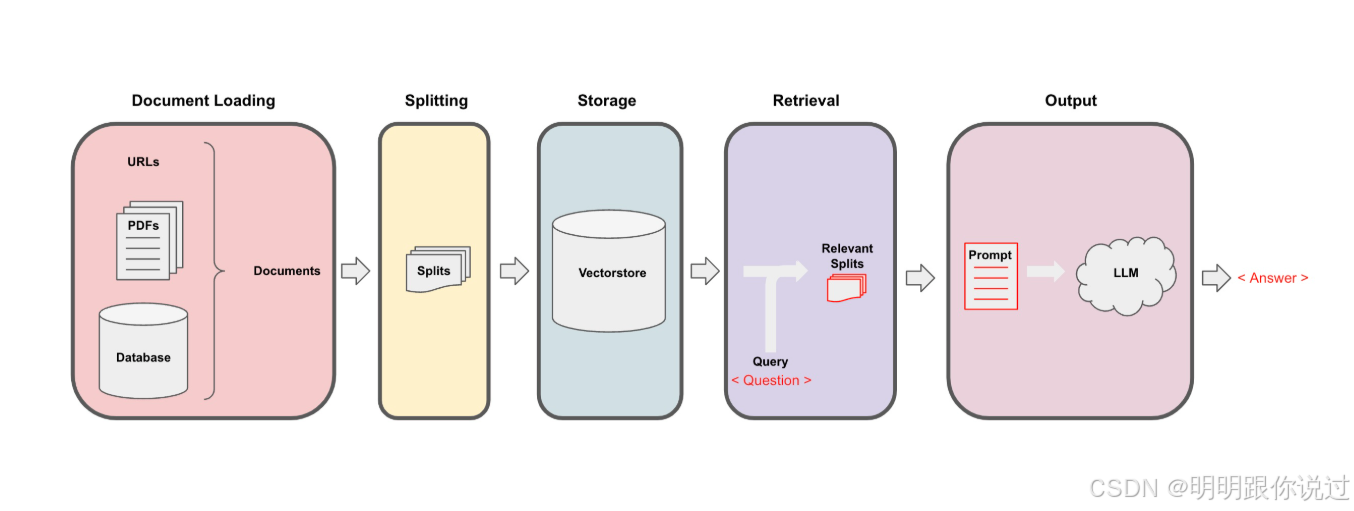
一、引言
1、什么是Lang Chain
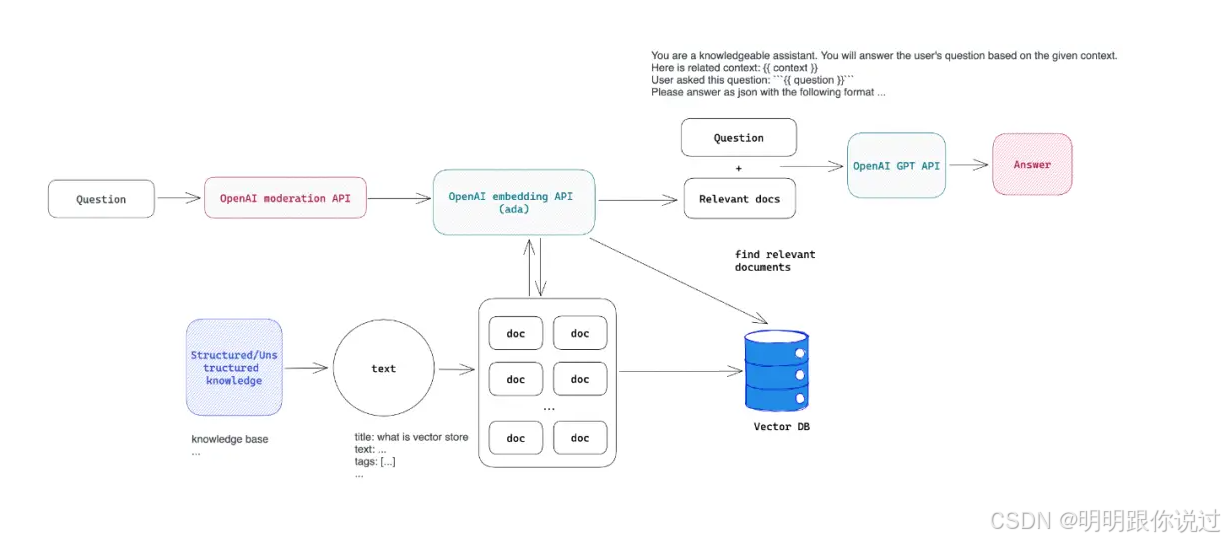
什么是 LangChain?🤖📚
LangChain 是一个帮助开发者轻松构建与 语言模型(如 GPT-3 或 GPT-4)互动的工具包。它为开发者提供了一整套现成的模块和功能,使得开发者能够快速创建强大的语言模型应用,无需从零开始。
🌟 通俗比喻:
想象你有一个超级聪明的助手(就是语言模型),它能够帮助你理解和生成各种文字内容📝。但是,如果你要让这个助手处理大量的信息,比如从多个文档中提取知识、或者在海量数据中找到特定的答案,事情就变得有点复杂了。
这时,LangChain 就像是一个智能助手管理系统,它将处理这些复杂任务的各种功能模块(如文本处理、数据检索、模型生成等)都打包在一起,简化了操作,让你更轻松地与这些强大的语言模型互动。

🔧 LangChain 做了什么?
文本处理 📄
- 有大量的文本数据(例如文章、书籍、报告等),LangChain 可以帮助你将它们切割成更小、更易于处理的块。这样,语言模型就能更好地理解和分析这些文本。
信息检索 🔍
- LangChain 能够将文本数据转化为"向量"形式,方便后续的查询和比较。就像你用 Google 搜索 查找信息一样,LangChain 会帮你找到最相关的内容。
问答系 统 ❓
- 想构建一个智能问答系统吗?LangChain 可以根据你的文档和数据库内容,自动从中提取出答案。你只需提出问题,系统会帮你查找最相关的答案。
多轮 对话 💬
- 如果你想要创建一个能够与人进行多轮对话的聊天机器人,LangChain 也能帮你管理对话的上下文。这样,机器人不仅能记住之前的对话,还能根据对话内容作出更智能的回答。

2、LangChain在问答系统中的核心优势
- 强大的信息检索功能 🔍
LangChain 能够轻松整合 信息检索(IR)系统,让问答系统不仅依赖于语言模型的生成能力,还能从大量数据中检索出最相关的信息。
-
向量数据库支持 :LangChain 支持集成 FAISS 等高效向量数据库,能够将文本数据转化为向量,提升查询效率。
-
精确匹配:可以根据用户的查询,快速查找到相关文档或数据,并为语言模型提供更精确的上下文。
- 自动化文档处理和文本切割 📝✂️
在问答系统中,我们往往需要处理大量的文档和文本数据。LangChain 提供了强大的文本切割和预处理功能:
-
自动分割长文档 :LangChain 提供文本切割工具(如
RecursiveCharacterTextSplitter),将长文本分割成较小的片段,便于更高效地进行处理和查询。 -
文本清洗和格式化:它帮助开发者自动处理文本数据,去除无关信息,确保模型输入的文本是干净且易于理解的。
二、环境搭建与基础准备
1、开发环境配置(Python、LangChain、LLM模型选择)
Python版本:3.12.7
安装 LangChain 工具包
pip install langchain_community langchain_openai langchain langchain_openaiLLM,这里的大模型我们使用 OpenAI 的大模型,如果还没有申请OpenAI 的KEY,可以参考:
《LangChain 安装与环境搭建,并调用OpenAI与Ollama本地大模型》这篇文章
2、安装FAISS数据库
执行以下命令:
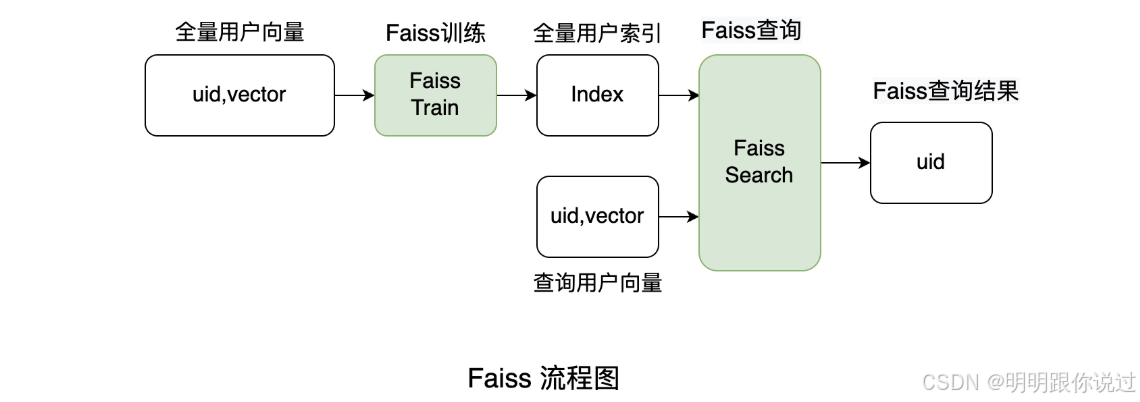
pip install faiss-cpu3、FAISS数据库介绍
📊🔍FAISS (Facebook AI Similarity Search )是一个由 Facebook AI Research 开发的高效向量检索库,专为处理大规模高维数据集中的 相似性搜索 设计。FAISS 是一个 开源 项目,旨在提供 快速的近似最近邻(ANN) 搜索功能,广泛应用于机器学习、自然语言处理、推荐系统等领域。
FAISS 的核心优势在于它能在处理海量数据时提供 高效的检索 ,尤其是在计算 向量相似性 时,性能远超传统的数据库系统。
FAISS 的核心特点 🌟
高效的向量 相似性搜索 🔍
-
FAISS 可以在大规模数据集中进行 高效的向量相似性搜索,帮助用户从海量数据中找到最相似的项。
-
它支持 内存中索引 (例如,使用 CPU 或 GPU)以及 磁盘存储索引,即使在数据集非常庞大的情况下也能提供快速的检索。
支持多种 距离度量 📏
-
FAISS 支持 欧氏距离 (L2)、内积等常见的距离度量方法,能够根据不同应用场景灵活选择合适的度量方式。
-
这些距离度量对于处理 文本、图像、音频 等多模态数据非常有用。
支持高维 数据 🔢
-
FAISS 能处理 高维 (几百维、几千维甚至更多)的数据,尤其适用于机器学习中通过 嵌入(embedding)生成的高维向量。
-
例如,处理文本时,FAISS 能够高效地检索基于语言模型生成的 词向量 或 句向量。
FAISS 如何工作? 🛠️
FAISS 的工作原理可以分为以下几个步骤:
数据向 量化 📈
-
首先,数据(如文本、图像、音频)需要被转化为 向量 ,这通常通过 深度学习模型(例如,BERT、ResNet、VGG)生成。
-
这些向量是高维的,表示数据中的某些特征。
构建 索引 🗄️
- 使用 FAISS 的不同索引结构(如 Flat 、IVF 、HNSW 等)将向量数据进行 索引。这一步骤的目的是加速查询过程。
查询和相 似性搜索 🔍
-
用户提出查询,FAISS 会通过 计算查询向量与数据集中向量的相似度(如计算内积或欧氏距离)来找出最相似的项。
-
FAISS 提供近似最近邻搜索,通常在 大规模数据集 中可以显著提高检索速度。
FAISS 应用场景 🚀
FAISS 广泛应用于 自然语言处理 、计算机视觉 和 推荐系统 等领域,以下是一些典型的应用:
推荐 系统 🎯
- FAISS 可以帮助根据用户历史行为或偏好从庞大的商品或内容库中找到相似的商品或内容,提供个性化推荐。
文本相似性检索 📝
- 在处理大量文本数据时(如文档、文章、问题解答等),FAISS 可以高效地查询最相关的文本,支持 问答系统 、信息检索系统等应用。
图 像检索 🖼️
- 在计算机视觉领域,FAISS 能够从 图像特征向量 中找到相似图像,广泛应用于 图像检索 、图像分类 和 面部识别 等任务。
三、代码部分
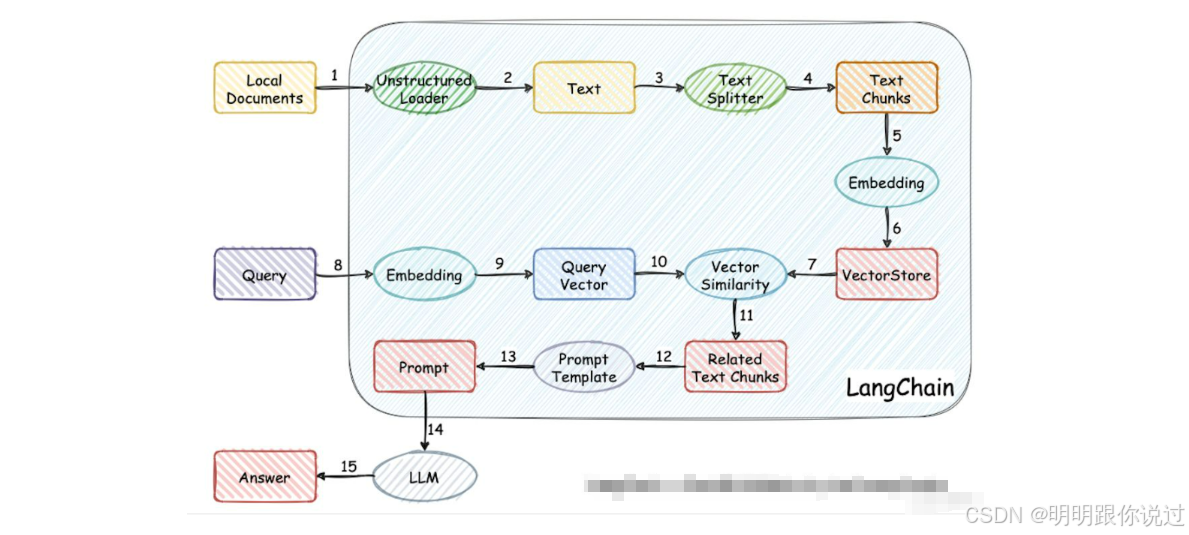
1、向量化文档
代码如下:
python
# 加载文档
docs = ["三星 W25 手机512G价格为¥15999", "三星 W25 手机1T价格为¥17999",]
# 将字符串转换为 Document 对象
documents = [Document(page_content=doc) for doc in docs]
# 文本切割
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
split_docs = text_splitter.split_documents(documents)
# 创建Embedding
embeddings = OpenAIEmbeddings()
# 使用FAISS创建向量数据库
db = FAISS.from_documents(split_docs, embeddings)
# 保存数据库
db.save_local("faiss_index")- 加载文档 📄
- 这里创建了一个简单的 文档列表 (
docs),其中包含两条字符串,每条字符串描述了一个三星手机的不同存储版本和价格。
- 将字符串转换为
Document对象 📝
- 将每个字符串(文档内容)转换为
Document对象。Document是 LangChain 中的一个类,用于封装文本数据及其相关元数据。这里的page_content=doc将字符串作为文档的内容。
- 文本切割(分割长文本) ✂️
- 使用
RecursiveCharacterTextSplitter来切割文档。这个工具将文档按照一定的字符数量(这里是 1000 字符)进行切割,同时允许文档切割片段之间有 200 字符的重叠。这样做的目的是确保文档在切割后,仍然能够保持上下文的连贯性。
- 创建文档的嵌入(Embedding) 🧠
OpenAIEmbeddings是 LangChain 提供的一个工具,用于将文本转换为 向量嵌入(embedding)。嵌入是将文本表示为数字向量,这些向量能够捕捉到文本的语义信息。在此例中,使用的是 OpenAI 的嵌入模型。
- 使用 FAISS 创建向量数据库 🔣
- 使用 FAISS 向量数据库来存储文本的嵌入。FAISS 是一个高效的相似性搜索库,可以对文本进行向量化处理后快速查询相似的内容。
split_docs是切割后的文档,embeddings是生成这些文档的嵌入的工具。from_documents方法会将文档转换为向量,并将它们存储在 FAISS 向量数据库中。这个数据库支持高效的相似性查询。
- 保存向量数据库 💾
- 最后,将构建好的 FAISS 向量数据库保存到本地文件系统。数据库会保存在名为
faiss_index的文件夹中。我们可以将其用于后续的查询和检索操作。
2、创建问答
代码如下:
python
# 加载FAISS数据库
db = FAISS.load_local("C:/Users/LMT/PycharmProjects/AI/LangChain/faiss_index", embeddings, allow_dangerous_deserialization=True)
# 初始化语言模型(这里用的是OpenAI)
llm = ChatOpenAI(model="gpt-4o")
# 创建问答链
qa_chain = RetrievalQA.from_chain_type(llm=llm, chain_type="map_reduce", retriever=db.as_retriever())
# 查询
query = "三星 W25 手机512G价格是多少"
response = qa_chain.invoke(query)
print(response)- 加载 FAISS 数据库 📂
-
这行代码从本地路径加载已保存的 FAISS 向量数据库。路径
"C:/Users/LMT/PycharmProjects/AI/LangChain/faiss_index"指向之前存储的 FAISS 索引文件。 -
embeddings:使用的嵌入工具,用于将文本转换为向量的工具。 -
allow_dangerous_deserialization=True:这是一个安全选项,表示允许加载通过 pickle 存储的 FAISS 数据库文件。这个选项的作用是为了防止可能来自不受信任源的恶意代码执行。
- 初始化语言模型(OpenAI GPT) 🤖
- 这里使用的是 OpenAI GPT-4 模型(
gpt-4o),作为问答系统的核心语言模型。
- 创建问答链(QA Chain) 🔗
-
这里创建了一个 问答链(QA Chain),该链将使用 FAISS 向量数据库来检索与查询最相关的文档,并利用 GPT-4 生成回答。
-
from_chain_type:这个方法用于从指定的链类型创建问答链。-
llm=llm:将先前初始化的 GPT-4 模型作为问答链的语言模型。 -
chain_type="map_reduce":指定链的类型为 map_reduce,这意味着系统会先检索相关文档,然后将它们的内容传递给语言模型,模型再进行处理和整合最终的答案。 -
retriever=db.as_retriever():将 FAISS 向量数据库转换为检索器(retriever)。检索器负责从 FAISS 数据库中检索与查询最相似的文档。
-
- 执行查询并获取回答 🧐💬
-
query = "三星 W25 手机512G价格是多少":这是用户输入的查询,目的是询问三星 W25 手机512G版本的价格。 -
qa_chain.invoke(query):通过问答链(QA Chain)执行查询。这个方法将根据用户的查询去 FAISS 数据库中查找相关文档,并将这些文档输入到 GPT-4 模型中,生成一个回答。
- 打印答案 🖨️
- 最后,打印出从模型生成的回答,这个回答是针对用户查询的最佳匹配。
3、完整代码
python
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.docstore.document import Document
from langchain.chains import RetrievalQA
from langchain_openai import ChatOpenAI
# 加载文档
docs = ["三星 W25 手机512G价格为¥15999", "三星 W25 手机1T价格为¥17999",]
# 将字符串转换为 Document 对象
documents = [Document(page_content=doc) for doc in docs]
# 文本切割
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
split_docs = text_splitter.split_documents(documents)
# 创建Embedding
embeddings = OpenAIEmbeddings()
# 使用FAISS创建向量数据库
db = FAISS.from_documents(split_docs, embeddings)
# 保存数据库
db.save_local("faiss_index")
# 加载FAISS数据库
db = FAISS.load_local("C:/Users/LMT/PycharmProjects/AI/LangChain/faiss_index", embeddings, allow_dangerous_deserialization=True)
# 初始化语言模型(这里用的是OpenAI)
llm = ChatOpenAI(model="gpt-4o")
# 创建问答链
qa_chain = RetrievalQA.from_chain_type(llm=llm, chain_type="map_reduce", retriever=db.as_retriever())
# 查询
query = "三星 W25 手机512G价格是多少"
response = qa_chain.invoke(query)
print(response)这段代码的功能是构建一个基于 FAISS 向量数据库 和 OpenAI GPT-4 的问答系统。它将文档转化为向量,存储在 FAISS 数据库中,使用 GPT-4 来生成对用户查询的答案。问答系统的主要步骤是:
-
加载文档并切割成片段。
-
创建嵌入并存储到 FAISS 向量数据库中。
-
加载 FAISS 数据库并初始化 GPT-4 模型。
-
使用检索和生成模型回答用户的查询。
这个系统可以用于各种信息检索任务,比如产品信息查询、文档检索、FAQ 自动化等。
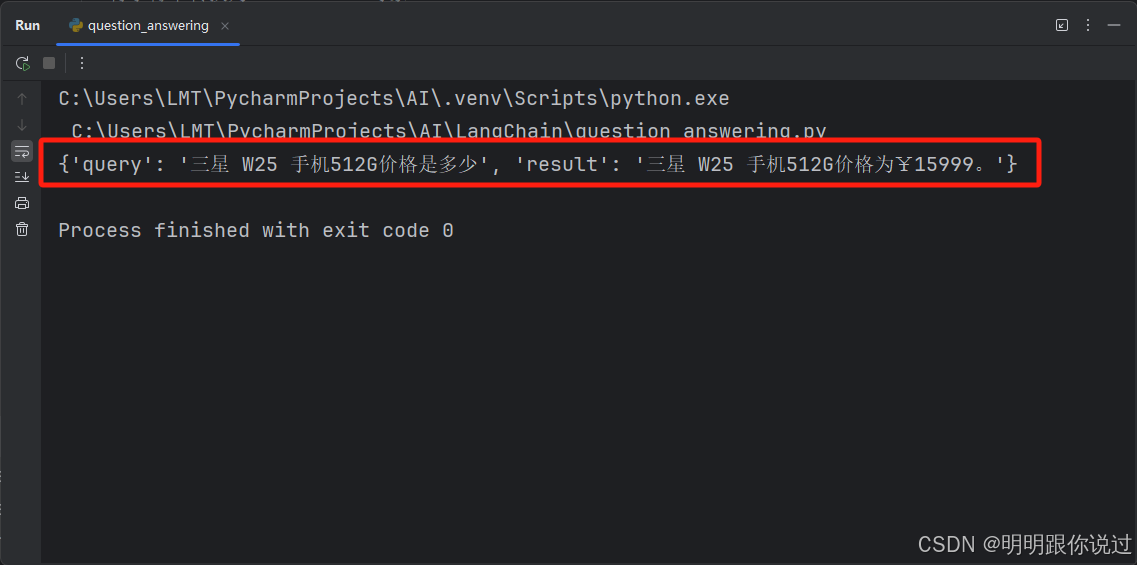
4、运行
代码执行后,结果如下:
💕💕💕每一次的分享都是一次成长的旅程,感谢您的陪伴和关注。希望这些文章能陪伴您走过技术的一段旅程,共同见证成长和进步!😺😺😺
🧨🧨🧨让我们一起在技术的海洋中探索前行,共同书写美好的未来!!!