目录
[1. 核心组件关系图](#1. 核心组件关系图)
[2. 代码中的关键实现](#2. 代码中的关键实现)
[1. 消息结构化存储](#1. 消息结构化存储)
[2. 动态提示组装机制](#2. 动态提示组装机制)
[1. 记忆容量控制](#1. 记忆容量控制)
[2. 记忆分片策略](#2. 记忆分片策略)
[3. 记忆检索增强](#3. 记忆检索增强)
[1. 记忆丢失问题排查](#1. 记忆丢失问题排查)
[.2. 消息类型不匹配修复](#.2. 消息类型不匹配修复)
[1. 个性化对话系统](#1. 个性化对话系统)
[2. 多模态记忆存储](#2. 多模态记忆存储)
2、ConversationBufferMemory关键参数

在AI对话系统开发中,让模型记住上下文如同赋予机器"短期记忆",这是构建连贯交互体验的关键。本文通过剖析一个完整的多轮对话实现案例,揭示LangChain的Memory模块如何突破大模型的"金鱼记忆"困境。
一、Memory架构设计解析
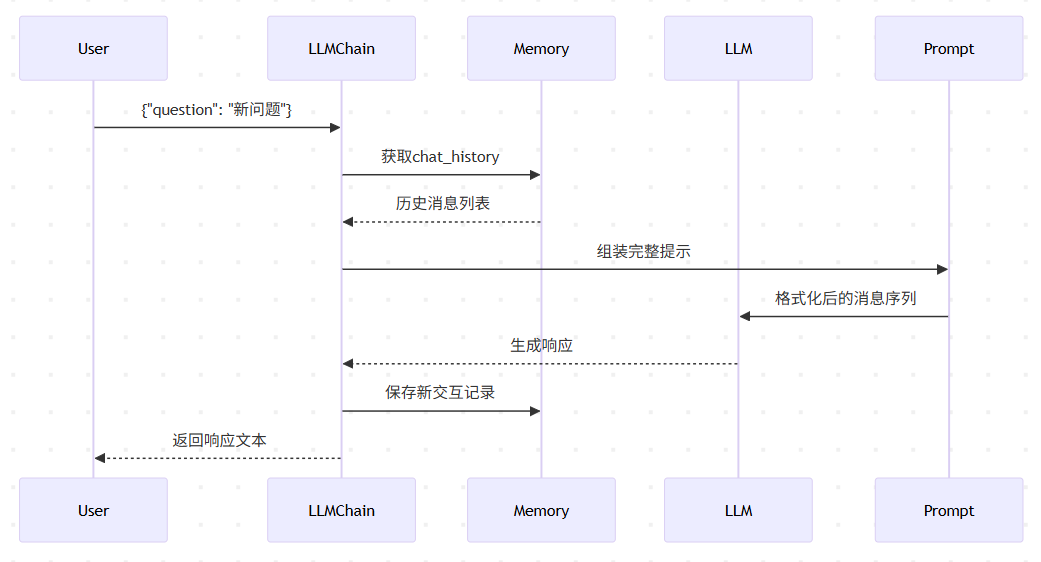
1. 核心组件关系图

2. 代码中的关键实现
python
# 记忆存储初始化(对话历史容器)
chat_memory = ConversationBufferMemory(
memory_key="chat_history", # 存储标识符
return_messages=True # 保持消息对象结构
)
# 记忆系统与链的整合
memory_chain = LLMChain(
llm=qwen,
prompt=prompt,
memory=chat_memory # 记忆注入
)二、对话记忆的工程实现
1. 消息结构化存储
python
# 典型记忆存储结构
[
HumanMessage(content="你好"),
AIMessage(content="您好!有什么可以帮助您?"),
HumanMessage(content="讲个笑话"),
AIMessage(content="为什么程序员总分不清万圣节和圣诞节?因为Oct31==Dec25!")
]- 设计优势:保留原始消息类型,支持角色区分化处理
2. 动态提示组装机制
python
# 运行时实际发生的提示拼接
final_prompt = [
SystemMessage(content="你是一个专业的聊天AI"),
HumanMessage(content="你好"),
AIMessage(content="您好!有什么可以帮助您?"),
HumanMessage(content="讲个笑话")
]- 技术价值:使模型始终在完整对话上下文中生成响应
三、Memory类型选型指南
| Memory类型 | 存储原理 | 适用场景 | 代码示例 |
|---|---|---|---|
| ConversationBufferMemory | 完整保存所有对话记录 | 短对话调试 | return_messages=True |
| ConversationBufferWindowMemory | 仅保留最近K轮对话 | 移动端轻量化应用 | k=3 |
| ConversationSummaryMemory | 存储摘要而非原始对话 | 长文档分析 | summary_prompt=... |
| CombinedMemory | 混合多种存储策略 | 复杂对话系统 | memories=[buffer, summary] |
四、生产环境优化实践
1. 记忆容量控制
python
from langchain.memory import ConversationBufferWindowMemory
# 保留最近3轮对话
optimized_memory = ConversationBufferWindowMemory(
k=3,
memory_key="chat_history",
return_messages=True
)- 避免问题:GPT-3.5的4k token限制下,防止长对话溢出
2. 记忆分片策略
python
class ChunkedMemory:
def save_context(self, inputs, outputs):
# 将长对话分段存储
chunk_size = 500 # 按token计算
self.chunks = split_text(inputs['question'], chunk_size)- 应用场景:法律咨询、医疗问诊等长文本领域
3. 记忆检索增强
python
from langchain.retrievers import TimeWeightedVectorStoreRetriever
# 基于时间权重的记忆检索
retriever = TimeWeightedVectorStoreRetriever(
vectorstore=FAISS(),
memory_stream=chat_memory.load_memory_variables({})['chat_history']
)- 技术价值:优先召回相关性高且较近期的对话
五、典型问题调试技巧
1. 记忆丢失问题排查
python
# 打印记忆状态
print(chat_memory.load_memory_variables({}))
# 期望输出:
# {'chat_history': [HumanMessage(...), AIMessage(...)]}.2. 消息类型不匹配修复
python
# 错误现象:TypeError: sequence item 0: expected str instance, HumanMessage found
# 解决方案:确保Memory配置return_messages=True- 长对话性能优化
python
# 监控内存使用
pip install memory_profiler
mprof run python chat_app.py六、扩展应用场景
1. 个性化对话系统
python
# 用户画像记忆
profile_memory = ConversationBufferMemory(
memory_key="user_profile",
input_key=["age", "occupation"]
)
# 组合记忆体系
combined_memory = CombinedMemory(memories=[chat_memory, profile_memory])2. 多模态记忆存储
python
from langchain_core.messages import ImageMessage
# 支持图片记忆
chat_memory.save_context(
{"question": "分析这张图片"},
{"output": ImageMessage(content=image_bytes)}
)- 记忆持久化方案
python
# SQLite存储实现
from langchain.memory import SQLiteMemory
persistent_memory = SQLiteMemory(
database_path="chat.db",
session_id="user123"
)结语 :
通过合理运用Memory组件,开发者可以构建出具备以下能力的智能对话系统:
✅ 30轮以上连贯对话
✅ 个性化上下文感知
✅ 长期用户画像记忆
✅ 跨会话状态保持
工作流程图
示例代码关键方法对照表
1、库名解析
| 方法/类名 | 所属模块 | 核心功能 |
|---|---|---|
ChatPromptTemplate |
langchain.prompts | 多角色提示模板构建 |
SystemMessagePromptTemplate |
langchain.prompts | 系统角色提示定义 |
MessagesPlaceholder |
langchain.prompts | 动态消息占位符 |
HumanMessagePromptTemplate |
langchain.prompts | 用户消息格式化 |
ConversationBufferMemory |
langchain.memory | 对话历史缓冲存储 |
LLMChain |
langchain.chains | 语言模型执行流水线 |
2、ConversationBufferMemory关键参数
| 参数名 | 类型 | 作用说明 | 默认值 |
|---|---|---|---|
memory_key |
str | 记忆字典的键名 | "history" |
return_messages |
bool | 是否返回Message对象 | False |
input_key |
str | 输入项的键名 | None |
return_messages=True
-
必要性:
-
MessagesPlaceholder需要Message对象列表(而不仅是字符串) -
保持消息类型信息(系统/人类/AI消息)
-
-
对比实验:
设置 输入格式 是否可用 return_messages=TrueMessage对象列表 ✅ return_messages=False纯文本字符串 ❌
3、LLMChain()关键参数
-
核心参数:
参数 类型 作用说明 llmBaseLanguageModel 语言模型实例 promptBasePromptTemplate 提示模板 memoryBaseMemory 记忆系统 verbosebool 是否打印执行日志
示例代码
代码说明:
该代码实现了一个基于LangChain的带记忆功能的智能对话系统,主要演示以下核心能力:
- **对话记忆管理**
通过`ConversationBufferMemory`实现对话历史的持久化存储,突破大模型单次请求的上下文限制,支持连续多轮对话。
- **提示工程架构**
采用分层提示模板设计:
系统消息固化AI角色设定
`MessagesPlaceholder`动态注入历史对话
用户消息模板接收即时输入
- **服务集成方案**
对接阿里云灵积平台(DashScope)的千问大模型,演示:
第三方模型API调用
参数调优(temperature=0增强确定性)
- **执行流水线封装**
使用`LLMChain`将提示工程、记忆系统、模型调用封装为可复用组件,体现LangChain模块化设计思想。完整技术栈涵盖环境变量管理、类型化消息处理、交互式调试等工程实践。
python
from langchain.chat_models import ChatOpenAI
from langchain.prompts import (
ChatPromptTemplate,
MessagesPlaceholder,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
import os
from dotenv import load_dotenv
#一、加载配置环境
load_dotenv()
# 二、初始化ChatOpenAI模型
llm = ChatOpenAI(
model="qwen-max",
api_key=os.getenv("DASHSCOPE_API_KEY"),
openai_api_base="https://dashscope.aliyuncs.com/compatible-mode/v1",
temperature=0
)
# 三、创建对话提示模板
prompt = ChatPromptTemplate(
messages=[
SystemMessagePromptTemplate.from_template(
"You are a nice chatbot having a conversation with a human."
),
# 这里的`variable_name`必须与记忆中的对应
MessagesPlaceholder(variable_name="chat_history"),
HumanMessagePromptTemplate.from_template("{question}")
]
)
#四、定义历史消息存储
# 注意我们设置`return_messages=True`以适配MessagesPlaceholder
# 注意`"chat_history"`与MessagesPlaceholder名称对应
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
#五、创建LLMChain实例,用于处理对话
conversation = LLMChain(
llm=llm,
prompt=prompt,
verbose=True,
memory=memory
)
#六、定义模拟历史对话消息
# 注意我们只传入`question`变量 - `chat_history`由记忆填充
conversation({"question": "你好"})
conversation({"question":"你能给我讲一个苹果和医生的笑话吗?"})
conversation({"question":"说得好,再讲一个"})
conversation({"question":"讲一个葫芦娃的笑话"})
#七、问题输入执行
while True:
question = input("请输入问题:")
if question.lower() == "exit":
response = conversation({"question": "再见"}) # 主动触发结束语
print(response['text'])
break
response = conversation({"question": question})
print(response['text']) # 确保输出模型响应运行结果
> Entering new LLMChain chain...
Prompt after formatting:
System: You are a nice chatbot having a conversation with a human.
Human: 你好
AI: 你好!有什么可以帮助你的吗?
Human: 你能给我讲一个苹果和医生的笑话吗?
AI: 当然可以,这里有一个经典的笑话:
为什么医生建议每天吃一个苹果?
因为医生需要钱买房子!(实际上原话是 "An apple a day keeps the doctor away",意思是"一天一个苹果,医生远离我",但这个版本更幽默一些。)
希望这能让你会心一笑!
Human: 说得好,再讲一个
AI: 好的,再来一个苹果和医生的笑话:
为什么苹果不喜欢去看医生?
因为每次医生都会说:"你看起来有点核(核心)问题!"
希望这个也能让你笑一笑!
Human: 讲一个葫芦娃的笑话
AI: 当然可以,这里有一个关于葫芦娃的笑话:
为什么葫芦娃们总是穿肚兜?
希望这个笑话能让你开心一笑!
Human: 回答我刚刚的问题
> Finished chain.
好的,再来一个关于葫芦娃的笑话
为什么葫芦娃们每次都能找到爷爷?
因为不管他们被妖怪抓到哪里,只要喊一声"爷爷,救我!"爷爷就能立刻感应到他们的位置。这大概是因为葫芦娃和爷爷之间有特殊的"GPS"吧!
希望这个笑话能让你笑一笑!
请输入问题:
说明:主要看最后一个问题"回答我刚刚的问题",可以发现大模型能够根据历史对话再去讲述关于葫芦娃的笑话。这也就说明成功实现了Memory记忆功能。