Linux之 grep、find、ls、wc 命令
" 在 Linux 世界中,命令行是不可或缺的一部分,而掌握一些常用的命令可以帮助你更有效率地管理文件和系统。本文将为你介绍四個基礎而强大的 Linux 命令:grep、find、ls 和 wc,带你开启高效文件操作的旅程!"
01
概述
本系列主要讲解Linux运行时命令,包括网络、磁盘、内存、CPU相关参数等,主要是为了分享怎么通过常见的 Linux 命令去排查相关问题。比如:
-
发现机器的CPU负荷比较高,那么怎么查到是哪个进程CPU占用率比较高?
-
磁盘IO的写入很频繁,怎么查到是哪个进程或线程对磁盘IO频繁的操作?等等。
本系列就是分享诸如这类问题的排查技巧。注意,本系列的核心方向不是去讲解Linux的命令查找、显示当前目录等(比如ls、cat等)基础命令操作。本系列的重点分享内容包括:
-
Linux基础命令和工具。
-
CPU性能监控。
-
内存性能监控。
-
文件IO性能监控。
-
网络IO性能监控。
强烈推荐:Linux 大牛,Netflix 高级性能架构师 Brendan Gregg的博客http://www.brendangregg.com。《性能之巅》书籍就是他出版的,主要分为:CPU、内存、磁盘、网络四大块。
下面对应的命令大部分都不是专为某一个模块设计的。所以先把基本的命令都掌握,再去细分每个命令的侧重点。
1.1、监控
常用的命令:
| 工具 | 描述 |
|---|---|
| free | 显示系统内存使用情况,包括使用的内存、空闲的内存、缓存和交换区等信息。 |
| ping | 用于测试网络连接的工具,通过向目标主机发送 ICMP 回显请求并等待回复来测量网络延迟。 |
| vmstat | Virtual Memory Statistics,虚拟内存统计工具,提供系统内存、进程、CPU活动等信息。 |
| iostat | 用于报告中央处理器(CPU)统计信息和整个系统、适配器、tty 设备、磁盘和 CD-ROM 的输入/输出统计信息。 |
| dstat | 显示了cpu使用情况,磁盘io情况,网络发包情况和换页情况,输出是彩色的,可读性较强,相对于vmstat和iostat的输入更加详细且较为直观。 |
| pidstat | 监控所有或指定进程的资源占用情况,如CPU、内存、设备IO、任务切换、线程等。 |
| top | 动态显示系统性能信息,包括负载、进程状态、CPU 使用率、内存使用及交换分区的信息。 |
| iotop | LINUX进程实时监控工具,类似于 top 命令的工具,用于实时监控磁盘 I/O 使用情况及进程的信息。 |
| htop | 交互式进程查看器,提供用户友好的界面,支持按键操作以管理进程。一个文本模式的应用程序(在控制台或者X终端中),需要ncurses。 |
| mpstat | 报告 CPU 的统计信息,显示每个 CPU 的使用情况,有助于分析 CPU 性能。 |
| netstat | 显示与 IP、TCP、UDP 和 ICMP 协议相关的网络连接和统计信息。一般用于检验本机各端口的网络连接情况。 |
| ps | 显示当前进程的状态和相关信息,类似于 Windows 的任务管理器。 |
| strace | 跟踪程序执行过程中产生的系统调用及接收到的信号,用于诊断程序问题。 |
| ltrace | 跟踪进程调用的库函数,帮助分析程序的库函数使用情况。 |
| uptime | 显示系统当前运行时间和负载信息,为用户提供系统负载状态的一个快照。能够打印系统总共运行了多长时间和系统的平均负载,uptime命令最后输出的三个数字的含义分别是1分钟,5分钟,15分钟内系统的平均负荷。 |
| lsof | 列出当前系统中打开的文件及相关进程,帮助识别文件使用情况。 |
| perf | Linux kernel 自带的性能分析工具,帮助识别程序性能瓶颈,通过分析 CPU 使用情况及热点函数。是Linux kernel自带的系统性能优化工具。优势在于与Linux Kernel的紧密结合,它可以最先应用到加入Kernel的new feature,用于查看热点函数,查看cashe miss的比率,从而帮助开发者来优化程序性能。 |
| tcpdump | 网络抓包工具,捕获和分析网络数据包,常用于网络故障排查和监控。 |
| sar | 收集和报告系统活动信息,涵盖 CPU、内存、I/O、网络等性能指标。 |
| blktrace | 跟踪块设备 I/O 操作,分析系统的磁盘 I/O 性能及行为。 |
下面这张图是 Brendan Gregg 提供的一个性能优化命令集。可以看到有很多命令可以监控系统的性能,比如文件系统相关、调用栈相关、网络相关等的命令。 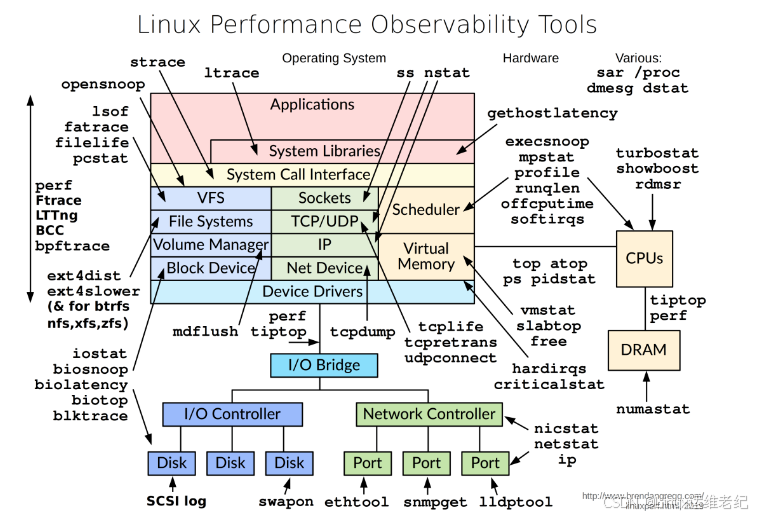
1.2、测试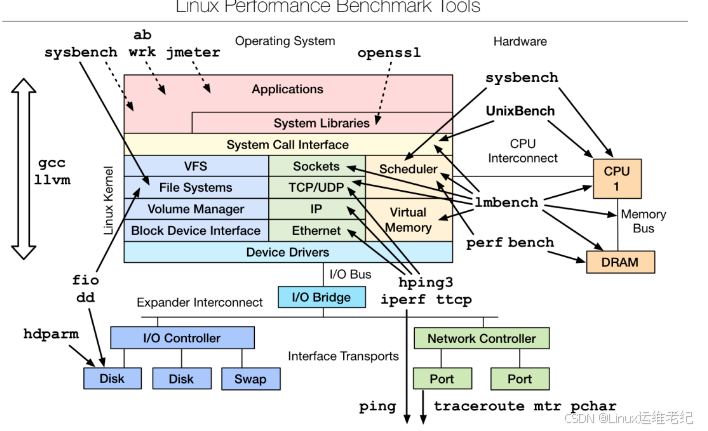
sysbench是一个模块化、跨平台、多线程基准测试工具,可用于以下性能测试:
-
CPU性能。
-
磁盘IO性能。
-
调度程序性能。
-
内存分配及传输速度。
-
POSIX线程性能。
-
数据库性能(OLTP基准测试)。
Linux CPU使用率主要是从以下几个维度进行统计:
| 指标 | 描述 |
|---|---|
%usr |
普通进程在用户模式下执行的时间 |
%sys |
进程在内核模式下的执行时间 |
%nice |
被提高优先级的进程在用户模式下的执行时间 |
%idle |
空闲时间 |
%iowait |
等待I/O完成的时间 |
%irp |
处理硬中断请求花费的时间 |
%soft |
处理软中断请求花费的时间 |
%steal |
是衡量虚拟机CPU的指标,是指分配给本虚拟机的时间片被同一宿主机别的虚拟机占用,一般%steal值较高时,说明宿主机的资源使用已达到瓶颈。 |
一般情况下,CPU大部分的时间片都是消耗在用户态和内核态上。
sys和user间的比例是相互影响的,%sys比例高意味着被测服务频繁的进行用户态和系统态之间的切换,会带来一定的CPU开销,这样分配处理业务的时间片就会较少,造成系统性能的下降。对于IO密集型系统,无论是网络IO还是磁盘IO,一般都会产生大量的中断,从而导致%sys相对升高,其中磁盘IO密集型系统,对磁盘的读写需要占用大量的CPU,会导致%iowait的值一定比例的升高,所以当出现%iowait较高时,需排查是否存在大量的不合理的日志操作,或者频繁的数据载入等情况;
1.3、优化
Linux Performance Tuning Tools的示意图,展示了Linux系统中不同的工具及其对应的组件。 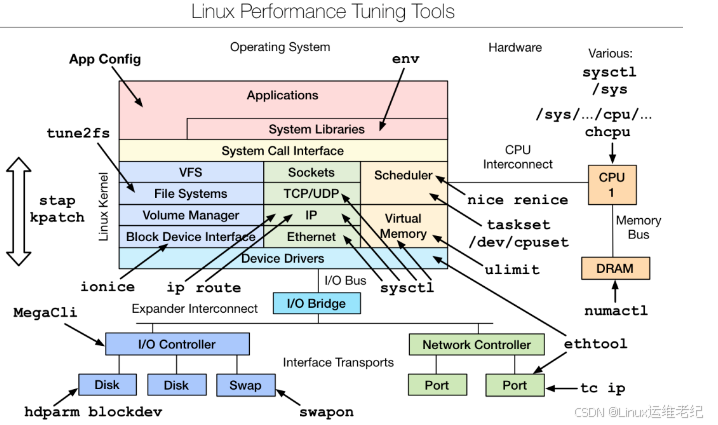
02
grep 搜索字符
grep 命令用于在文件中执行关键词搜索,并显示匹配的效果。
基本语法:
grep [选项] 模式 [文件...]部分常用选项:
| 参数 | 作用 |
|---|---|
| -c | 仅显示找到的行数 |
| -i | 忽略大小写 |
| -n | 显示行号 |
| -v | 反向选择,仅列出没有关键词的行。v 是 invert 的缩写。 |
| -r | 递归搜索文件目录 |
| -C n | 打印匹配行的前后n行 |
-E |
使用扩展正则表达式。 |
-l |
仅显示包含匹配行的文件名。 |
-h |
不显示文件名。 |
-w |
仅匹配整个单词。 |
-o |
仅显示匹配的模式。 |
-q |
静默模式,不输出任何内容。 |
-A n |
显示匹配行及其后面的 n 行。 |
-B n |
显示匹配行及其前面的 n 行。 |
-f 文件名 |
从文件中读取模式。 |
基本正则表达式:
-
.:匹配任意单个字符。 -
*:匹配前一个字符零次或多次。 -
[]:匹配括号内的任意一个字符。 -
[^]:匹配括号内以外的任意一个字符。 -
\: 转义字符,用于匹配特殊字符。 -
^:匹配行首。 -
$:匹配行尾。 -
|:或运算符。 -
():分组运算符。
扩展正则表达式:
-
+:匹配前一个字符一次或多次。 -
?:匹配前一个字符零次或一次。 -
{}:匹配前一个字符指定次数。
示例:
-
在指定文件查找,查找login关键字。
grep login ImUser.cpp -
多个文件中搜索。
grep login ImUser.cpp MsgConn.cpp -
在多个文件搜索的时候,可以使用通配符。在以 cpp结尾的文件中,搜索包含login 的行
grep login *.cpp -
递归搜索目录下所有文件, 搜索 msg_server目录下所有文件,打印出包含 login的行。
grep login -r msg_server/ -
反向查找,查找文件中,不包含 CImUser 的行。
grep -v CImUser ImUser.cpp -
找出文件中包含 login的行,并打印出行号。
grep -n login ImUser.cpp -
找出文件中包含 login的行,打印出行号,并显示前后3行。
grep -C 3 -n login ImUser.cpp -
找出文件中包含 login的行,打印出行号,并显示前后3行,并忽略大小写。
grep -C 3 -i -n login ImUser.cpp
注意事项:
-
grep命令通常用于处理文本文件,但也支持从标准输入读取数据。 -
grep命令的效率取决于模式的复杂度和文件的大小。 -
grep命令可以与其他命令结合使用,例如管道和重定向。
其他相关命令:
-
egrep:等价于grep -E,使用扩展正则表达式。 -
fgrep:等价于grep -F,使用固定字符串匹配。 -
ag:更快更强大的搜索工具。 -
03
find 查找文件
find 命令用于在文件系统中搜索文件和目录,并对找到的项目执行操作。通过文件名查找文件的所在位置,文件名查找支持模糊匹配。
基本语法:
find [起始目录] [选项] [表达式]参数:
-
起始目录: 指定搜索的起始目录。如果省略,则默认从当前目录开始搜索。 -
选项: 用于控制搜索行为和输出结果。 -
表达式: 用于描述要搜索的目标文件或目录。
主要选项:
| 选项 | 作用 |
|---|---|
-name 模式 |
根据文件名匹配模式搜索。支持通配符 * 和 ?。 |
-iname 模式 |
根据文件名匹配模式搜索,忽略大小写。 |
-type 类型 |
根据文件类型搜索。例如 f 表示文件,d 表示目录,l 表示符号链接。 |
-size +n |
搜索大小大于 n 个块的文件。 |
-size -n |
搜索大小小于 n 个块的文件。 |
-size n |
搜索大小等于 n 个块的文件。 |
-mtime +n |
搜索修改时间距离现在超过 n 天的文件。 |
-mtime -n |
搜索修改时间距离现在少于 n 天的文件。 |
-mtime n |
搜索修改时间距离现在正好 n 天的文件。 |
-atime |
根据访问时间进行搜索。用法与 -mtime 相同。 |
-ctime |
根据文件创建时间进行搜索。用法与 -mtime 相同。 |
-user 用户名 |
搜索属于特定用户的文件。 |
-group 组名 |
搜索属于特定组的文件。 |
-perm 模式 |
根据权限模式搜索文件。例如 -perm 644 搜索权限为 -rw-r--r-- 的文件。 |
-exec 命令 {} \; |
对找到的文件执行指定的命令。 |
-ok 命令 {} \; |
对找到的文件执行指定的命令,并在执行前提示用户确认。 |
-print |
打印找到的文件的路径。 |
-print0 |
打印找到的文件的路径,并使用空字符作为分隔符。 |
-depth |
先搜索子目录再搜索当前目录。 |
-maxdepth n |
设置最大搜索深度。 |
-mindepth n |
设置最小搜索深度。 |
! |
取反运算符,用于排除某些文件或目录。 |
-o |
或运算符,用于组合多个搜索条件。 |
-a |
与运算符,用于组合多个搜索条件。 |
() |
括号用于分组搜索条件。 |
示例:
-
查找当前目录下所有以 .txt 结尾的文件:
find . -name "*.txt" -
查找 /home 目录下所有大于 10M 的文件:
find /home -size +10M -
查找 /tmp 目录下修改时间距离现在超过 7 天的文件:
find /tmp -mtime +7 -
查找当前目录下所有权限为 755 的文件:
find . -perm 755 -
查找 /var/log 目录下所有以 .log 结尾的文件,并删除它们:
find /var/log -name "*.log" -delete -
查找当前目录下所有目录,并打印它们的路径:
find . -type d -print -
查找当前目录下所有以 .txt 结尾的文件,并把它们复制到 /backup 目录:
find . -name "*.txt" -exec cp {} /backup \; -
查找当前目录下所有以 .txt 结尾的文件,并提示用户是否删除它们:
-
04
ls 显示文件
ls 命令用于列出目录的内容。它可以显示文件和目录的名称、大小、修改时间、权限等信息。
基本语法:
ls [选项] [文件或目录...]| 选项 | 描述 | 类别 |
|---|---|---|
-a |
显示所有文件,包括隐藏文件(以 . 开头的文件)。 |
列出文件信息 |
-l |
以长格式列出文件信息,包括文件权限、文件大小、文件所有者、修改时间等。 | 列出文件信息 |
-h |
以易于阅读的格式显示文件大小,例如 1K、2M、3G 等。 | 列出文件信息 |
-t |
按修改时间排序。 | 列出文件信息 |
-r |
反转排序顺序。 | 列出文件信息 |
-S |
按文件大小排序。 | 列出文件信息 |
-i |
显示文件 inode 号。 | 列出文件信息 |
-d |
显示目录本身的信息,而不是目录内的文件信息。 | 列出文件信息 |
-R |
递归列出所有子目录。 | 列出文件信息 |
-F |
在文件名后添加标记,表示文件类型。例如 / 表示目录,* 表示可执行文件,@ 表示符号链接等。 |
文件显示格式 |
-b |
将不可打印字符显示为反斜杠转义字符。 | 文件显示格式 |
-c |
使用数字字符编码显示文件。 | 文件显示格式 |
-G |
显示颜色,用于区分不同类型的文件。 | 文件显示格式 |
-1 |
单行显示文件名,每个文件名占一行。 | 其他 |
-C |
多列显示文件名,根据终端宽度自动调整列数。 | 其他 |
-m |
用逗号分隔显示文件名。 | 其他 |
-n |
使用数字用户 ID 和组 ID 显示文件信息。 | 其他 |
-p |
在目录名后添加 /。 |
其他 |
-q |
将不可打印字符显示为 ?。 |
其他 |
-s |
显示文件大小(以块为单位)。 | 其他 |
示例:
-
列出当前目录下所有文件:
ls -
以长格式列出当前目录下所有文件:
ls -l -
列出当前目录下所有文件,包括隐藏文件:
ls -a -
列出当前目录下所有文件,按修改时间排序:
ls -lt -
递归列出 /home/user 目录下所有文件:
ls -R /home/user -
列出当前目录下所有文件,并用颜色区分文件类型:
ls -G
05
wc 命令
wc 命令用于统计文件中的行数、字数和字节数。利用wc指令我们可以计算文件的Byte数、字数、或是列数,若不指定文件名称、或是所给予的文件名为"-",则wc指令会从标准输入设备读取数据。
基本语法:
wc [选项] [文件...]主要选项:
-
-l或--lines: 统计行数。 -
-w或--words: 统计字数。 -
-c或--bytes或--chars: 统计字节数。 -
-m: 统计字符数。 -
-L: 统计最长行的长度。 -
-W: 统计单词数。
示例:
-
统计文件 test.txt 的行数、字数和字节数:
wc test.txt -
只统计文件 test.txt 的行数:
wc -l test.txt -
统计多个文件 test.txt 和 data.log 的行数:
wc -l test.txt data.log -
统计文件 test.txt 的最长行的长度:
wc -L test.txt
注意事项:
-
wc命令默认统计所有三个值(行数、字数和字节数)。 -
wc命令可以使用多个选项组合,以实现不同的统计功能。 -
wc命令的输出结果可能会根据文件内容和系统环境有所不同。
其他:
-
wc 命令可以用于统计标准输入的内容,例如:
cat test.txt | wc -l -
wc 命令可以与其他命令结合使用,例如:
# 统计文件 `test.txt` 中包含 "error" 字符串的行数。 grep "error" test.txt | wc -l