注意力机制是一个非常伟大的机制,说它是现代人工智能的基石也不为过。因为现在大语言模型,如chatgpt,deepseek这种,底层用到了Transformer,而Transformer是一种部件级别的基础网络模型,类似于卷积神经网络CNN和循环神经网络RNN的地位。Transformer正是基于注意力机制提出的,在一篇举世闻名的论文《Attention is all you need》中首次被提出。这次我们来看看注意力机制的原理,并用一个例子来说明。
关于注意力机制的文章我也写过几篇了,之前介绍的不够通俗,《深度学习进阶:自然语言处理》这本书中的介绍我觉得很通俗,也很清楚,所以写出来和大家分享一下。
我们上一篇文章介绍了序列到序列的生成模型Seq2seq,Seq2seq底层是两个LSTM组合的,一个成为编码器(Encoder),一个成为解码器(Decoder),训练时候叫做解码器,实际使用的时候就叫做生成器(generator)。结构如下:
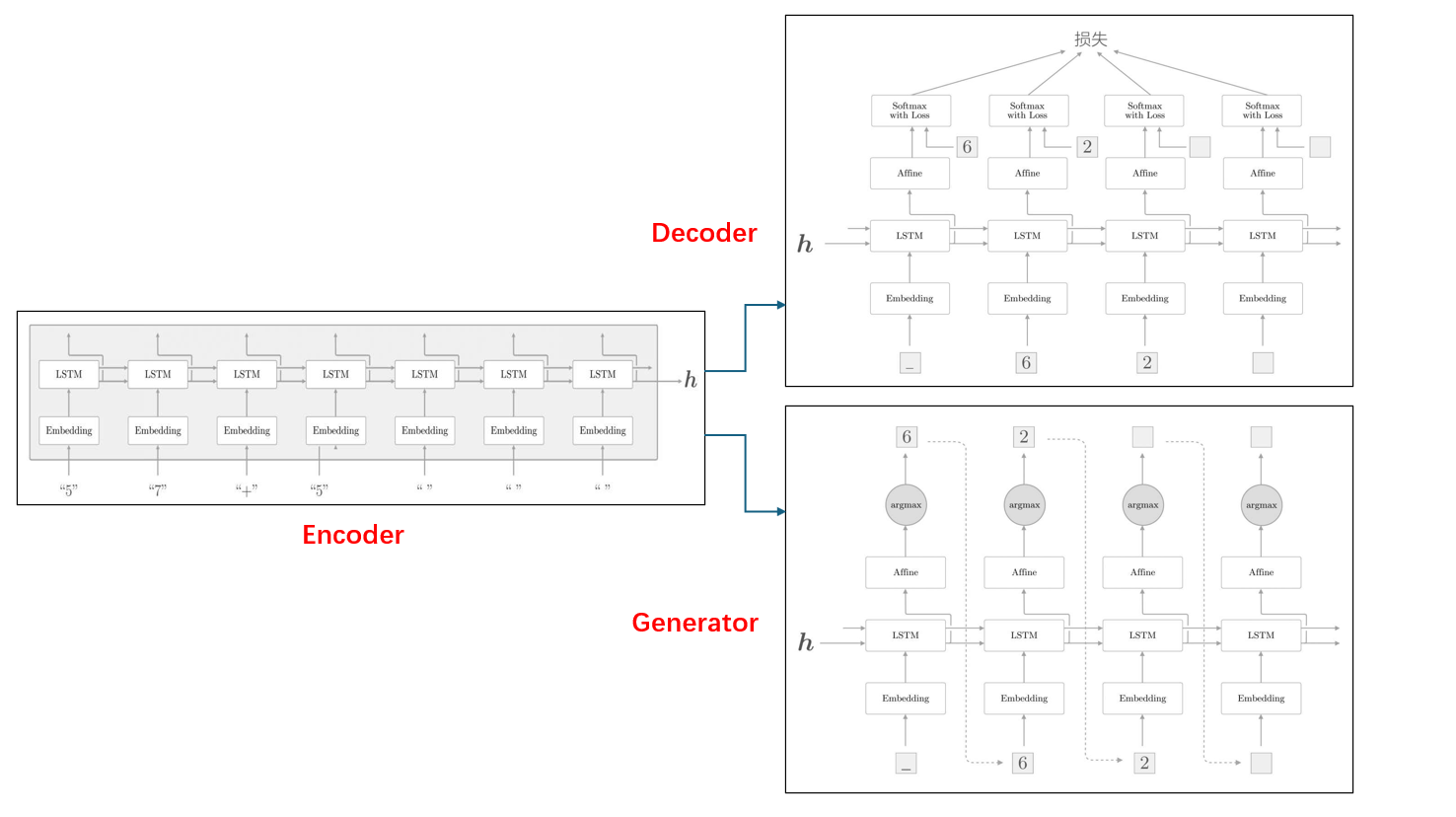
编码器先对输入进行Embedding,把单词表示成向量,然后通过LSTM,得到一个隐藏信息输出h。解码器把输入单词Embedding后,把得到的单词向量合并编码器输出的隐藏信息h,一起输入到解码器的LSTM中,输出的隐藏信息再输出到分类层affine,最后通过softmax得到输出单词的概率。从而计算损失值。
但是这种解码器,只有解码器的第一个节点获取到了编码器输出隐藏信息,可能造成信息的丢失,所以前一篇文章中有一种改进方法叫做:Peeky。
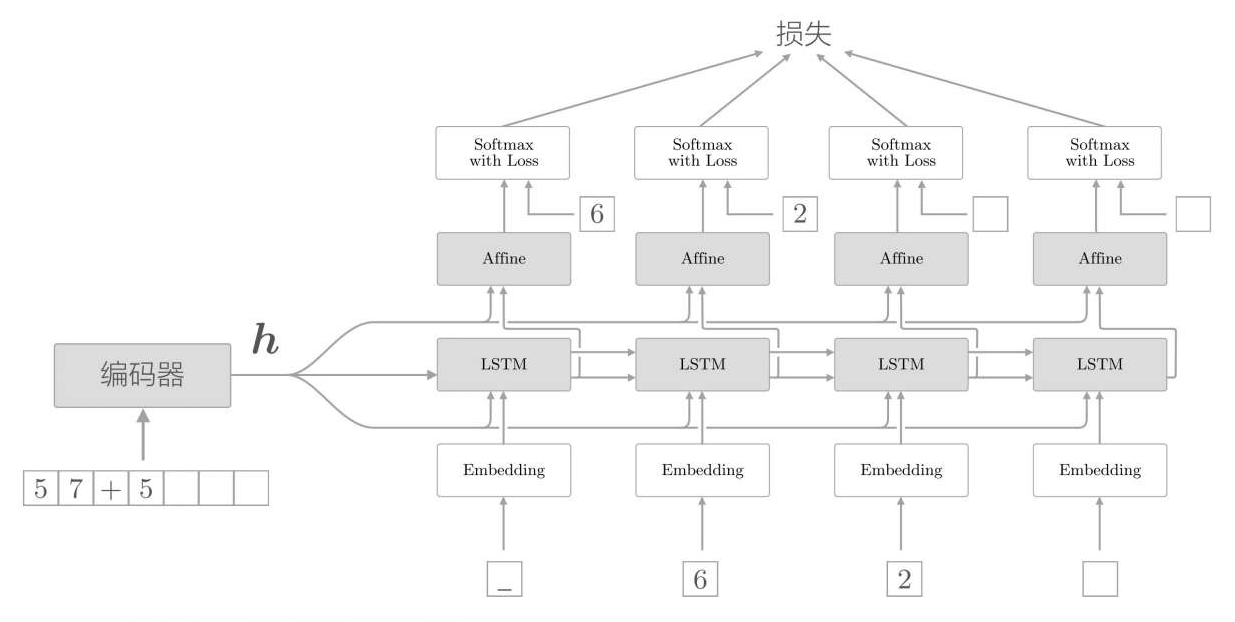
Peeky把编码器输出的隐藏信息分别传递到解码器的每一个节点中,使得每个节点都可以获取到编码器的完整隐藏信息,其余结构完全相同,该方法效果得到了明显提升。
注意力机制,其实就是在此基础上进一步的改进。之前的模型只使用了编码器输出隐藏信息hs的最后一行,现在把整个hs都进行输出,进行某种计算。简单来说,它把编码器输出的隐藏信息和解码器的LSTM输出的隐藏信息做了某种计算,把这个结果信息输入到了分类层affine中,再进行分类。示意图如下:
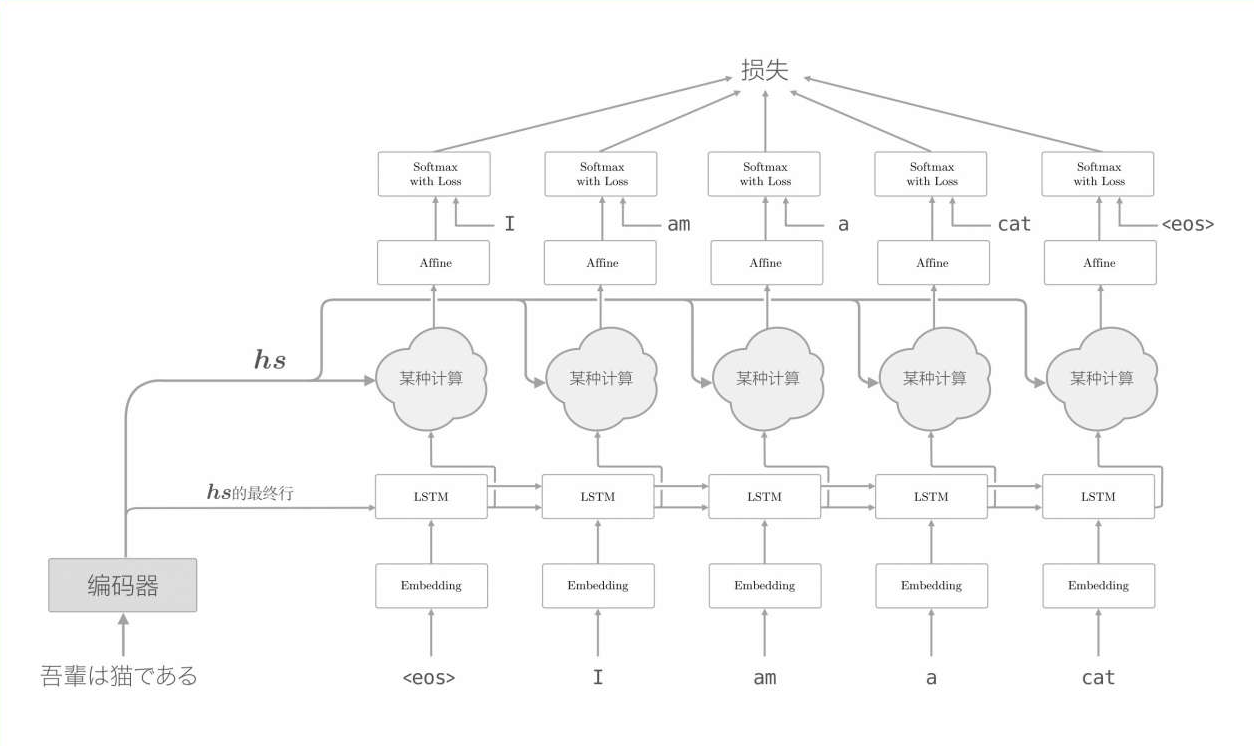
这个"某种计算"就是注意力机制Attention。
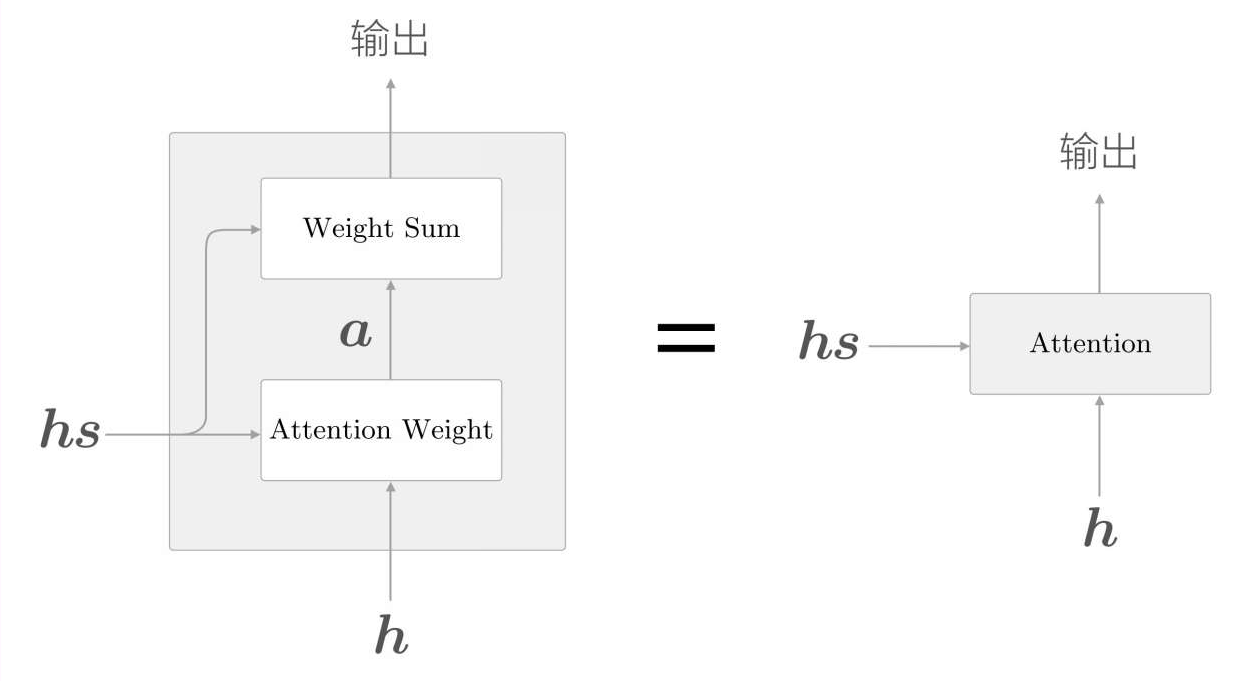
注意力机制的计算分为两部分,首先计算Attention Weight,再进行Weight Sum计算。其实就是将hs和h去求一个相似度,这个相似度就是a,然后根据a去对hs求一个加权和,得到weight sum。书中的例子特别好:
如果编码器输出的hs是表示几个单词的向量,那么如果有个向量a可以表示每个单词的重要性,那么就可以就可以用hs和a求一个加权和,得到的结果就是上下文向量,用这个上下文向量去进行分类,会比较好,因为他采用了上下文信息,并且根据不同的权重进行了考虑。
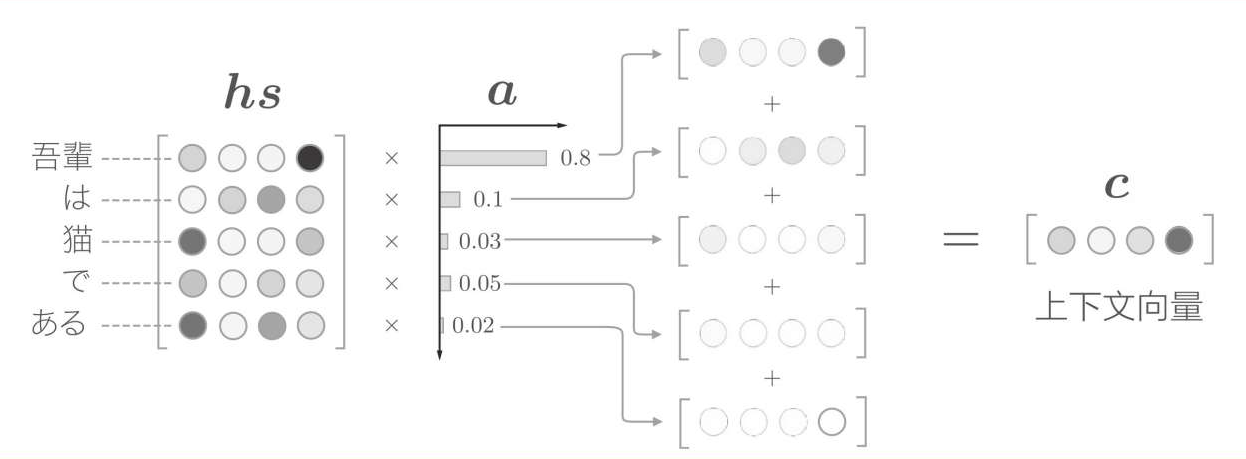
好了,现在的问题是怎么求得这个重要性向量a,最简单的方法就是直接求相似度,编码器隐藏向量hs和解码器LSTM输出的隐藏信息h直接的相似度,用内积实现即可。背后的意义就是用数值表示这个h在多大的程度上和hs的各个单词向量"相似",越相似则权重越高。
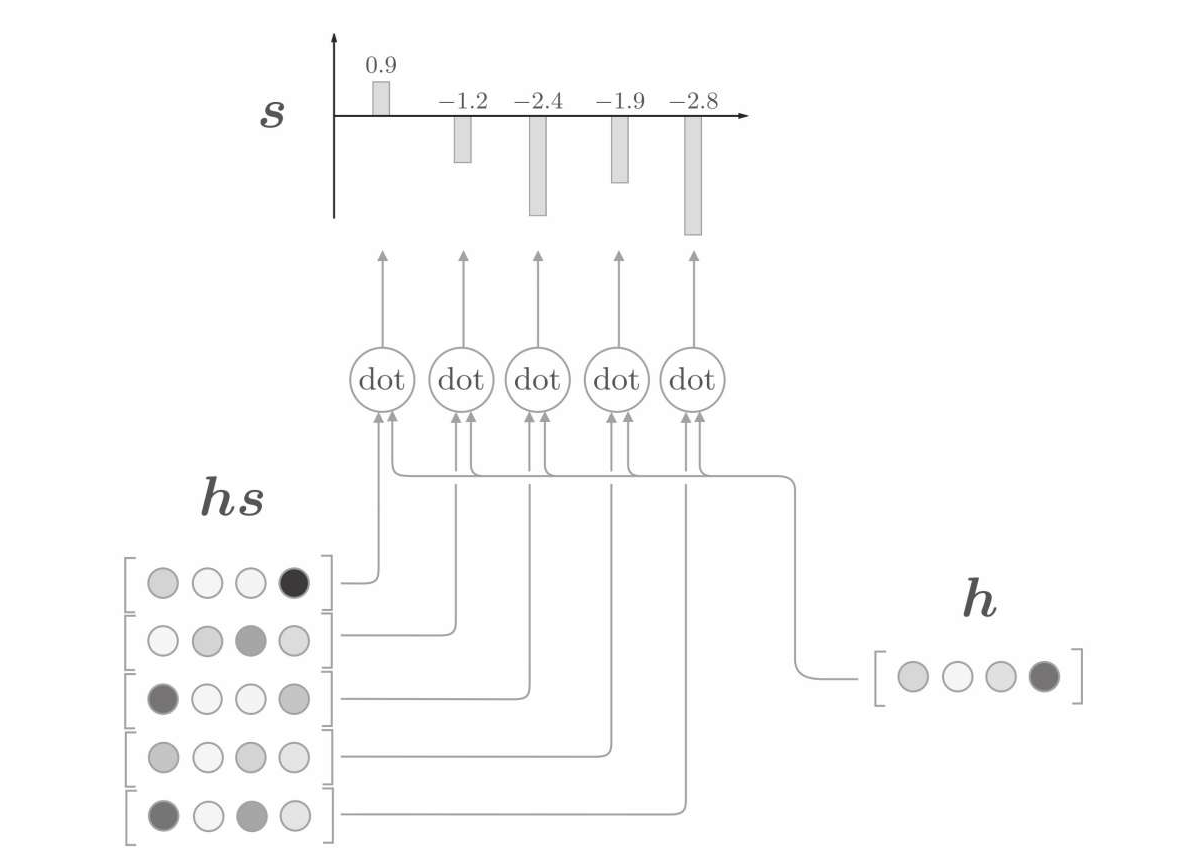
对内积结果用softmax计算一下,把结果转换成0到1之间的概率值。就是我们前面要的向量a了。
真正的结构就是这样:
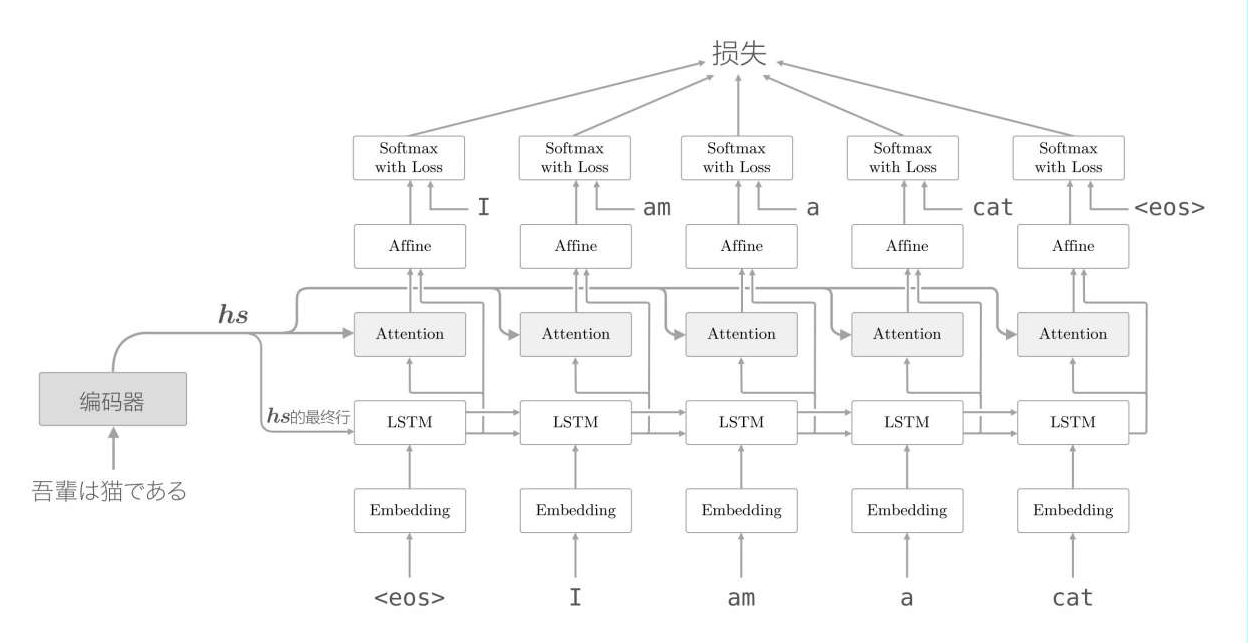
它把编码器输出的隐藏信息和解码器的LSTM输出的隐藏信息求了一个相似度,得到了两个向量的相似度,然后用这个相似度来编码器的隐藏信息hs做加权和,得到上下文的权重,把这个信息输入到了分类层affine中,再进行分类。
下面我们来实现一下代码,首先是AttentionWeight,输入编码器隐藏信息hs,以及解码器LSTM输出的隐藏信息h。
python
class AttentionWeight:
def __init__(self):
self.params, self.grads = [], []
self.softmax = Softmax()
self.cache = None
def forward(self, hs, h):
N,T,H = hs.shape
hr = h.reshape(N,1,H).repeat(T,axis=1)
# hr = h.reshape(N,1,H) # 也可以用广播机制实现
t = hs*hr
s = np.sum(t,axis=2)
a = self.softmax.forward(s)
self.cache = (hs,hr)
return a
def backward(self, da):
hs, hr = self.cache
N,T,H = hs.shape
ds = self.softmax.backward(da)
dt = ds.reshape(N,T,1).repeat(H, axis=2)
dhs = dt*hr
dhr = dt*hs
dh = np.sum(dhr,axis=1)
return dhs,dhWeightSum根据AttentionWeight得到的相似度a,以及编码器输出hs,来计算上下文向量。
python
class WeightSum:
def __init__(self):
self.params, self.grads = [], []
self.cache = []
def forward(self, hs, a):
N,T,H = hs.shape
ar = a.reshape(N,T,1).repeat(H, axis=2)
t = hs*ar
c = np.sum(t, axis=1)
self.cache = (hs, ar)
return c
def backward(self, dc):
hs, ar = self.cache
N,T,H = hs.shape
# sum的反向传播
dt = dc.reshape(N,1,H).repeat(T,axis=1)
dar = dt*hs
dhs = dt*ar
# repeat的反向传播
da = np.sum(dar,axis=2)
return dhs,da这里面就是要注意,sum运算的反向传播是repeat,repeat运算的反向传播是sum。下面是把WeightSum和AttentionWeight合并为一个Attention的层的代码。
python
class Attention:
def __init__(self):
self.params, self.gards = [], []
self.attention_weight_layer = AttentionWeight()
self.weight_sum_layer = WeightSum()
self.attention_weight = None
def forward(self, hs, h):
a = self.attention_weight_layer.forward(hs,h)
out = self.weight_sum_layer.forward(hs,a)
self.attention_weight = a
return out
def backward(self, dout):
dhs0,da = self.weight_sum_layer.backward(dout)
dhs1,dh = self.attention_weight_layer.backward(da)
dhs = dhs0+dhs1
return dhs,dhTimeAttention就是在时间序列上做Attention。
python
class TimeAttention:
def __init__(self):
self.params, self.grads = [], []
self.layers = None
self.attention_weights = None
def forward(self, hs_enc, hs_dec):
N,T,H = hs_dec.shape
out = np.empty_like(hs_dec)
self.layers = []
self.attention_weights = []
for t in range(T):
layer = Attention()
out[:,t,:] = layer.forward(hs_enc, hs_dec[:,t,:])
self.layers.append(layer)
self.attention_weights.append(layer.attention_weight)
return out
def backward(self, dout):
N,T,H = dout.shape
dhs_enc = 0
dhs_dec = np.empty_like(dout)
for t in range(T):
layer = self.layers[t]
dhs,dh = layer.backward(dout[:,t,:])
dhs_enc += dhs
dhs_dec[:,t,:] = dh
return dhs_enc,dhs_dec 最后利用TimeAttention构建编码器和解码器,最终合并编码器和解码器得到基于注意力机制的Seq2seq模型。其他如LSTM等模块和原来的Seq2seq模型一样的。
编码器和之前的编码器几乎一致,只是返回的时候返回了整个hs,而原来只是返回了hs的最后一行。
python
class AttentionEncoder(Encoder):
def forward(self, xs):
xs = self.embed.forward(xs)
hs = self.lstm.forward(xs)
return hs
def backward(self, dhs):
dout = self.lstm.backward(dhs)
dout = self.embed.backward(dout)
return dout解码器和生成器,解码器结合了注意力层Attention。
python
class AttentionDecoder:
def __init__(self, vocab_size, wordvec_size, hidden_size):
V,D,H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
# 初始化权重和偏置
embed_W = (rn(V,D)/100).astype('f')
lstm_Wx = (rn(D,4*H)/np.sqrt(D)).astype('f')
lstm_Wh = (rn(H,4*H)/np.sqrt(H)).astype('f')
lstm_b = np.zeros(4*H).astype('f')
affine_W = (rn(2*H,V)/np.sqrt(2*H)).astype('f')
affine_b = np.zeros(V).astype('f')
# 模型的每层
self.embed = TimeEmbedding(embed_W)
self.lstm = TimeLSTM(lstm_Wx,lstm_Wh,lstm_b,stateful=True)
self.attention = TimeAttention()
self.affine = TimeAffine(affine_W, affine_b)
layers = [self.embed,self.lstm,self.attention,self.affine]
# 初始化参数和梯度
self.params, self.grads = [], []
for layer in layers:
self.params += layer.params
self.grads += layer.grads
def forward(self, xs, enc_hs):
h = enc_hs[:,-1]
self.lstm.set_state(h)
out = self.embed.forward(xs)
dec_hs = self.lstm.forward(out)
c = self.attention.forward(enc_hs, dec_hs)
out = np.concatenate((c,dec_hs), axis=2)
score = self.affine.forward(out)
return score
def backward(self, dscore):
dout = self.affine.backward(dscore)
N, T, H2 = dout.shape
H = H2 // 2
dc, ddec_hs0 = dout[:,:,:H], dout[:,:,H:]
denc_hs, ddec_hs1 = self.attention.backward(dc)
ddec_hs = ddec_hs0 + ddec_hs1
dout = self.lstm.backward(ddec_hs)
dh = self.lstm.dh
denc_hs[:, -1] += dh
self.embed.backward(dout)
return denc_hs
def generate(self, enc_hs, start_id, sample_size):
sampled = []
sample_id = start_id
h = enc_hs[:, -1]
self.lstm.set_state(h)
for _ in range(sample_size):
x = np.array([sample_id]).reshape((1, 1))
out = self.embed.forward(x)
dec_hs = self.lstm.forward(out)
c = self.attention.forward(enc_hs, dec_hs)
out = np.concatenate((c, dec_hs), axis=2)
score = self.affine.forward(out)
sample_id = np.argmax(score.flatten())
sampled.append(sample_id)
return sampled两者结合在一起构成了AttentionSeq2seq模型。
python
class AttentionSeq2seq(Seq2seq):
def __init__(self, vocab_size, wordvec_size, hidden_size):
args = vocab_size, wordvec_size, hidden_size
self.encoder = AttentionEncoder(*args)
self.decoder = AttentionDecoder(*args)
self.softmax = TimeSoftmaxWithLoss()
self.params = self.encoder.params + self.decoder.params
self.grads = self.encoder.grads + self.decoder.grads下面做了一个实验,用于将各种日期格式转变成标准日期格式来测试一下AttentionSeq2seq的效果。这里的输入就是各种格式的日期数据,输出就是标准的日期格式,编码器将输入数据进行编码,得到的结果通过解码器进行解码,训练10个epoch,在训练2个epoch后,精度就达到了99.9%了。
对于训练过后的模型,我们可以可视化注意力机制,横轴表示输入的信息,纵轴表述输出的标签,高亮由训练后的模型Attention来决定。
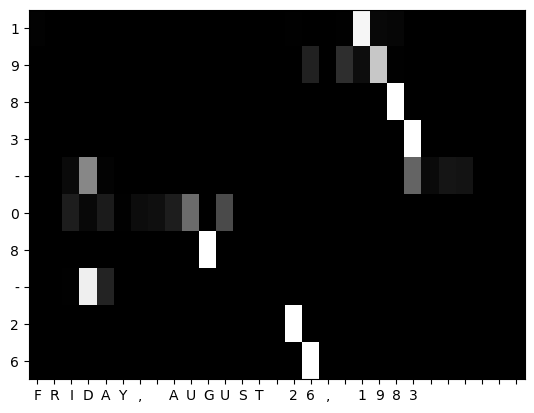
可以看到,在这个测试数据中,输入的是"FRIDAY, AUGUST 26, 1983",FRIDAY没有与之对应的单词,所以亮色显示在横线-处,AUGUEST显示最亮的地方对应的纵轴正是8,26的高亮部分对应的纵轴也是26,1983的高亮部分对应到纵轴上也是1983,可以看到注意力都被正确的表示出来了。