文章目录
- MambaVision
- 一、研究背景
-
- [(一)Transformer vs Mamba](#(一)Transformer vs Mamba)
- [(二)Mamba in CV](#(二)Mamba in CV)
- 二、相关工作
-
- [(一)Transformer 在计算机视觉领域的进展](#(一)Transformer 在计算机视觉领域的进展)
- [(二)Mamba 在计算机视觉领域的探索](#(二)Mamba 在计算机视觉领域的探索)
- [三、MambaVision 设计](#三、MambaVision 设计)
- 四、实验设置
- 五、实验结果
- 六、结论
MambaVision
论文阅读
论文链接:MambaVision: A Hybrid Mamba-Transformer Vision Backbone
本文提出了 MambaVision 这一专为视觉应用设计的混合骨干网络,通过重新设计 Mamba 结构和研究混合模式,在多项视觉任务中展现出优于同类模型的性能,为新型视觉模型的发展奠定了基础。
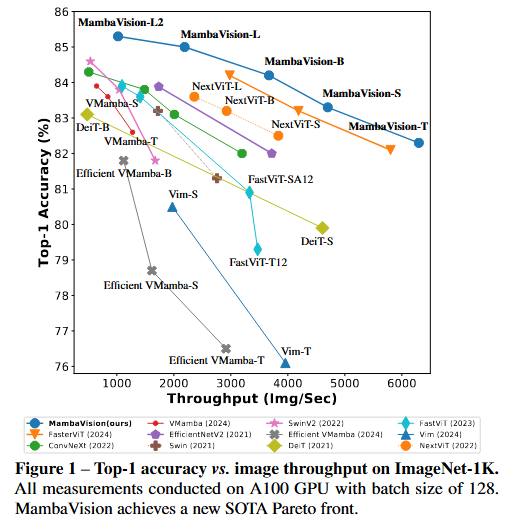
一、研究背景
(一)Transformer vs Mamba
- Transformer凭借注意力机制在多领域广泛应用,具备通用性和灵活性,适用于多模态学习。然而,其注意力机制的二次复杂度使得训练和部署成本高昂。
- Mamba作为一种新型状态空间模型(SSM),时间复杂度为线性,在语言建模任务中表现优异,甚至超越Transformer,其核心创新在于引入选择机制,可高效处理长序列数据。
(二)Mamba in CV
受 Mamba 启发,部分基于 Mamba 的骨干网络被应用于视觉任务,但 Mamba 的自回归特性在视觉领域存在局限:
- 图像像素的空间关系 具有局部且并行的特点,没有顺序依赖关系,与 Mamba顺序处理的序列数据不同。
- 像Mamba这样的自回归模型逐步处理数据的方式难以在一次前向传播中捕捉全局上下文,而视觉任务往往需要全局信息来准确判断局部。
二、相关工作
(一)Transformer 在计算机视觉领域的进展
1. ViT :利用自注意力层扩大感受野,但缺乏 CNN 的归纳偏差和位移不变性,需大规模数据集训练。
2. DeiT :引入知识蒸馏训练策略,能在小数据集上显著提升分类准确率。
3. LeViT :融合重新设计的多层感知机和自注意力模块,优化推理速度,提升效率和性能。
4. XCiT :引入转置自注意力机制,增强对特征通道交互的建模能力。
5. PVT :金字塔视觉,引入特征金字塔,可以生成多尺度的特征图用于密集预测任务,采用分层结构,降低空间维度,提高计算效率。
6. Swin Transformer :通过局部窗口自注意力平衡局部和全局上下文。
7. Twins Transformer :其空间可分离自注意力机制提升了效率。
8. Focal Transformer:利用焦点自注意力捕捉长距离空间交互细节。
(二)Mamba 在计算机视觉领域的探索
1.Vim :提出双向 SSM,试图提升全局上下文捕捉能力,但双向编码增加计算量,导致训练和推理变慢,且难以有效融合多方向信息。
2.EfficientVMamba:采用空洞卷积和跳跃采样提取全局空间依赖关系,使用分层架构,在不同分辨率下分别利用 SSM 和 CNN 的优势。
相比之下,MambaVision 在高分辨率下利用 CNN 更快提取特征,低分辨率下结合 SSM和自注意力捕捉更细粒度细节,在准确率和吞吐量上更具优势。
3.VMamba:引入跨扫描模块 CSM 实现一维选择扫描,扩大全局感受野,但感受野受跨扫描路径限制。
相比之下,MambaVision 的混合器设计更简单,能捕捉短程和长程依赖,且使用 CNN 层快速提取特征,在性能和吞吐量上更优。
三、MambaVision 设计
(一)宏观架构
MambaVision 采用分层架构,包含 4 个不同阶段 。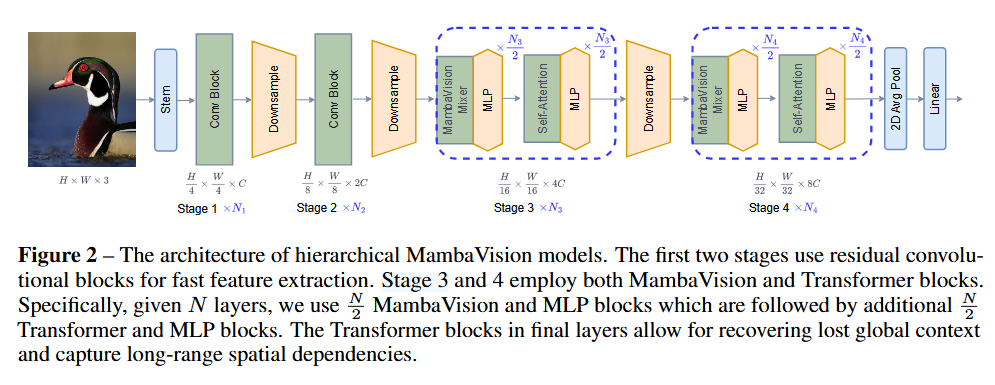
- 前两个阶段使用残差卷积块,用于在较高输入分辨率下快速提取特征。
- 后两个阶段融合了 MambaVision 和Transformer 块。
具体而言,给定N层,使用N个MambaVision 和MLP块,随后是另外N 个Transfomer 和 MLP 块。最终层中的Transformer 块能够恢复丢失的全局上下文,并捕捉长距离的空间依赖关系。
(二)微观架构
Mamba 是结构化状态空间序列模型(S4)的扩展,能将 1D 连续输入转换为输出。
其连续参数经离散化处理后,可通过全局卷积计算输出。
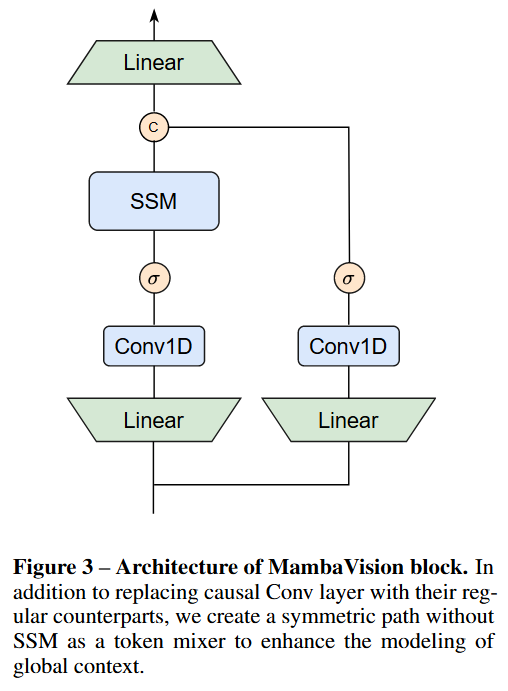
为使 Mamba 更适用于视觉任务,重新设计了 Mamba 混合器:
- 用常规卷积替换因果卷积,因为因果卷积限制了信息传播方向,对视觉任务不利;
- 添加无 SSM 的对称分支,由额外卷积和 SiLU 激活函数组成,补偿因 SSM 顺序约束丢失的信息;
- 将两个分支输出拼接并通过线性层投影,使最终特征表示融合顺序和空间信息。 此外,采用通用多头自注意力机制,其计算方式与以往研究类似。
四、实验设置
1.图像分类
- 在 ImageNet-1K 数据集上进行图像分类实验,遵循标准训练方法,所有模型均训练300个epoch,采用余弦衰减调度器,其中分别使用了20个epoch进行预热和冷却阶段。使用LAMB 优化器,设置全局批量大小4096、初始学习率0.005和权重衰减0.05,利用 32 个 A100 GPU 加速训练。
2.目标检测和实例分割
- 以预训练模型为骨干网络,在 MS COCO 数据集上进行目标检测和实例分割任务,使用 Mask-RCNN 头,超参数设置初始学习率0.0001、批量大小16、权重衰减为0.05的X3学习率调度,使用 8 个 A100 GPU 进行训练。
3.语义分割
- 在 ADE20K 数据集上进行语义分割任务,使用 UperNet 头和 Adam-W 优化器,初始学习率6e-5,全局批量大小16,使用 8 个 A100 GPU 进行训练。
五、实验结果
1.图像分类
-
MambaVision 在 ImageNet-1K 分类任务中表现卓越,在 Top-1
准确率和图像吞吐量方面大幅超越CNN、Transformer、Conv - Transformer 和 Mamba 的不同模型系列。
-
与流行模型如 ConvNeXt 和 Swin Transformer 相比,MambaVision-B 的 Top-1准确率更高,图像吞吐量也更优。
-
与基于 Mamba 的模型相比同样展现出优势,且 MambaVision模型变体的计算量(FLOPs)低于同等规模的其他模型。
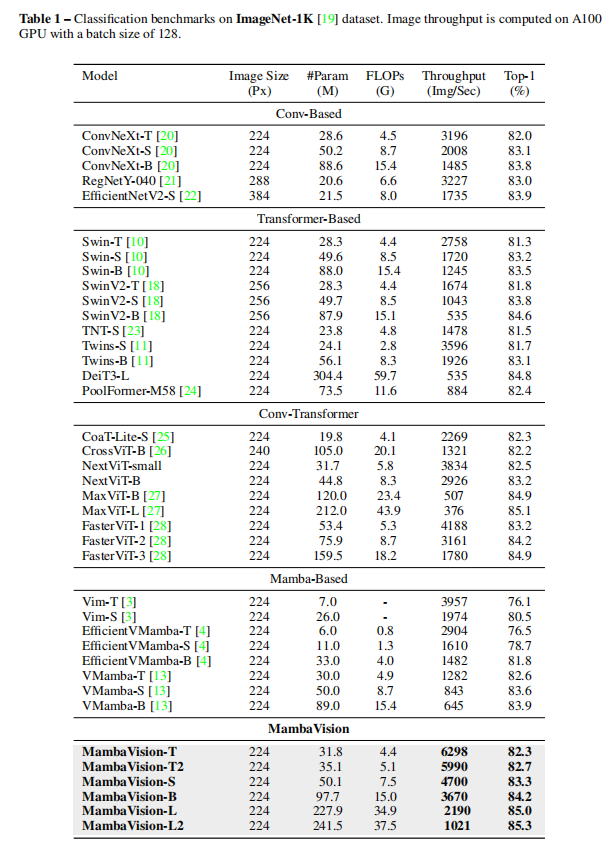
2.目标检测与分割
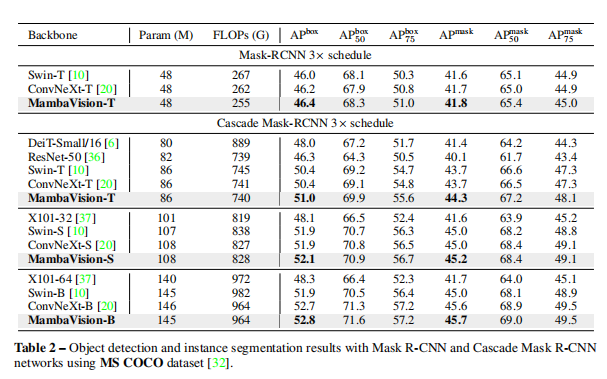
-
在 MS COCO 数据集的目标检测和实例分割实验中,使用简单 Mask-RCNN 检测头,预训练的 MambaVision-T
骨干网络在 AP box和AP mask上超越 ConvNeXt-T 和 Swin-T 模型。
-
使用 Cascade Mask-RCNN 网络时,MambaVision-T、MambaVision-S 和 MambaVision-B
表现更优,在 AP box和 AP mask上相对于对比模型有明显提升。
-
在 ADE20K 数据集的语义分割任务中,MambaVision 不同变体在 mIoU 指标上优于相近规模的竞争模型,验证了其作为视觉骨干网络在不同任务中的有效性,尤其在高分辨率设置下表现出色。
3.消融实验
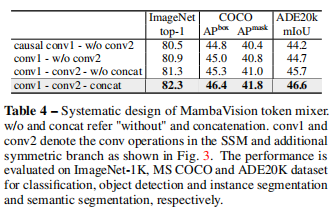
- 对 MambaVision 混合器进行消融实验,结果表明用常规卷积替换因果卷积、添加对称分支 (即SMM和非SMM)并拼接输出,能显著提升模型在分类、目标检测、实例分割和语义分割任务中的性能,验证了设计的有效性。
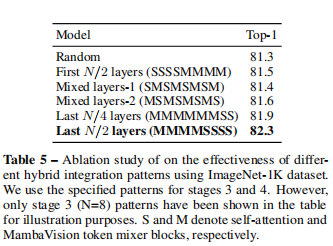
- 研究不同混合集成模式对模型的影响发现,在每个阶段最后几层使用自注意力块的设计能有效提升性能,且当自注意力块数量增加到每个阶段最后 N/2 层 时,模型达到最佳性能。
六、结论
- 首次提出 MambaVision 这一专为视觉应用设计的 Mamba-Transformer 混合骨干网络。
- 重新设计 Mamba公式增强了全局上下文表示学习能力,全面研究混合设计集成模式。
- MambaVision 在 Top-1准确率和图像吞吐量上达到新的最优前沿,大幅超越基于 Transformer 和 Mamba 的模型,为新一代混合视觉模型发展提供了基础。