《DeepSeek-VL: Towards Real-World Vision-Language Understanding》
1. 摘要/引言
基于图片问答(Visual Question Answering,VQA)的任务
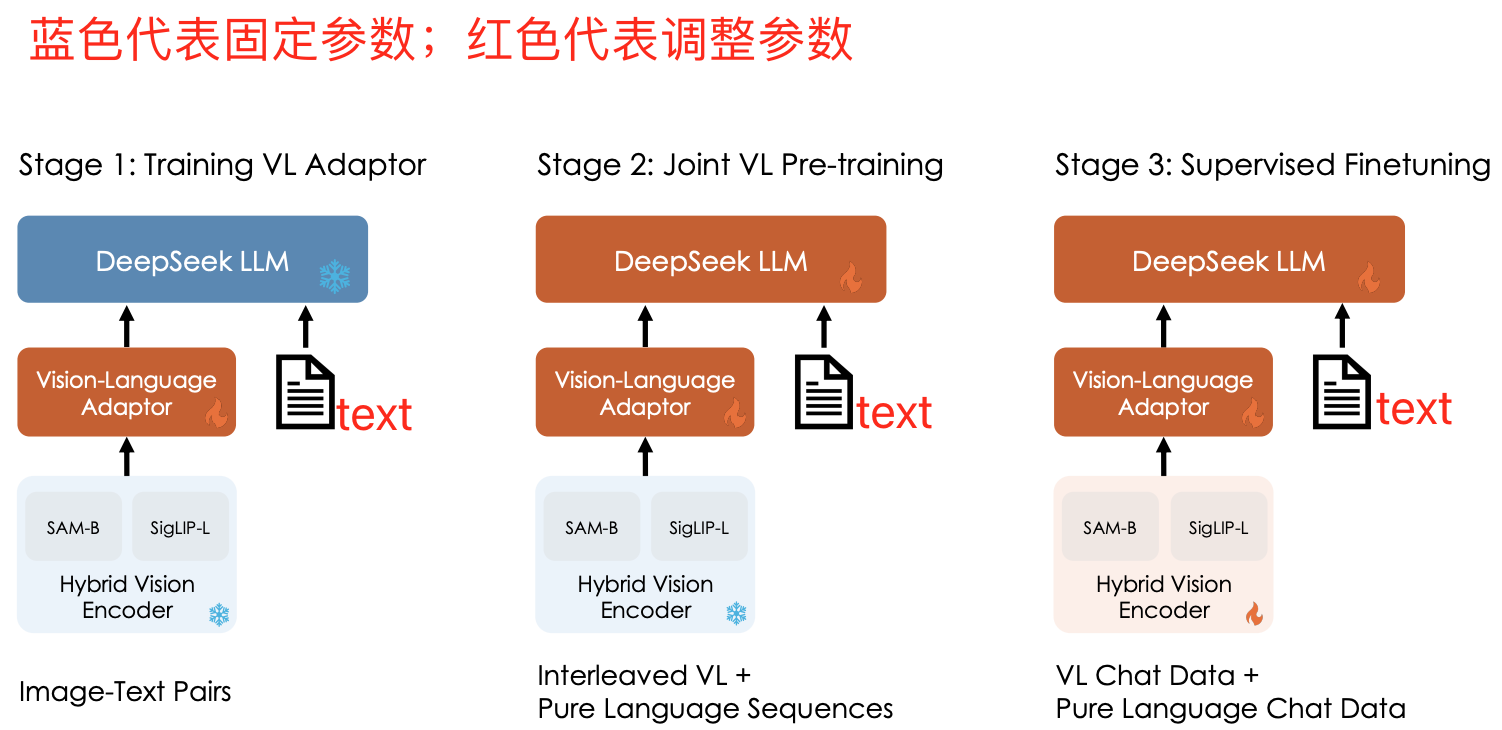
2. 模型结构 和 三段式训练
1)使用 SigLIP 和 SAM 作为混合的vision encoder,也就用的 对比学习 和Segment Anything(有监督学习)的混合vision encoder
2)Vision-Language Adaptor 负责将动态分块后的图像特征转换为语言模型可处理的离散的token-ids