
很久没有跟踪无监督MVS的工作了,今天快速过一篇ECCV2024 Oral的文章,作者都来自UCSB。这也是我第一次知道这个学校也有组在做MVS。
项目地址:Github
文章目录
- [1 Introduction](#1 Introduction)
- [2 Related Work](#2 Related Work)
- [3 Methods](#3 Methods)
-
- [3.1 Preliminaries](#3.1 Preliminaries)
- [3.2 Depth-Smoothness Loss](#3.2 Depth-Smoothness Loss)
- [3.3 Image-Synthesis Loss](#3.3 Image-Synthesis Loss)
- [3.4 Supervision View Sampling](#3.4 Supervision View Sampling)
- [4 Experiments](#4 Experiments)
- [5 核心代码](#5 核心代码)
1 Introduction
论文的主要创新点集中在改进无监督 MVS 的核心损失函数,提出了 DIV Loss,包括以下三个关键部分:
- 提出了一个新的深度平滑loss,使用Clamped 2nd-Order Depth Smoothness
- 提出了一个learning-based监督,通过合成图像来做,提升与视角相关的效果
- 除了使用本来的source views之外,还使用更多的view来做监督,以增强网络预测未见视角的能力

2 Related Work
介绍了有监督和无监督的MVS,并且多介绍了深度平滑的一些工作,为后面展开说自己的方法做铺垫。
3 Methods
3.1 Preliminaries
pipeline如下图所示:
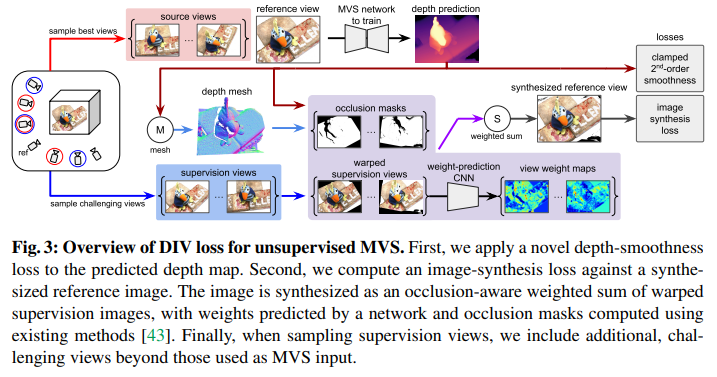
3.2 Depth-Smoothness Loss
如图2所示,传统无监督MVS的平滑损失使用一阶梯度,这样的损失鼓励locally-constant depth,容易导致楼梯效应(stair-stepping),在物体边界就深度非常不准,造成artifacts。于是,部分工作使用二阶梯度,来鼓励locally-smooth depth,这样虽然能缓解楼梯效应,但这样会错误地跨物体边界平滑,导致深度边界模糊,如图4所示。

作者发现,二阶梯度光滑性是有用的,但不应在边界区域过度 penalize。因此,他们提出梯度截断(Clamping),即在计算损失时将二阶梯度的绝对值限制在一个上限。这样的话,在平滑区域,损失与传统二阶平滑一致,就能保持平滑表面;在物体边界,二阶梯度通常很大,但被 clamp 限制,就不会被过度penalize了,并且,允许出现清晰的深度不连续性,可以消除深度渗透问题。
本文创新点:提出 "二阶梯度+梯度截断"。
- 对二阶梯度进行截断(clamp),允许在物体边界处出现锐利的深度不连续。
- 在平滑区域仍能保持光滑性,显著减少边界artifacts。
- 效果:显著改善物体边界的深度预测质量。
3.3 Image-Synthesis Loss
传统无监督MVS使用基于warp的photometric loss,并用min-K策略过滤遮挡与高误差像素。
本文创新点:引入一个小 CNN 网络。
- 将 warp 后的多视角图像作为输入,预测每个像素的权重。
- 将加权融合后的结果作为"合成参考图像"进行 photometric supervision。
- 同时结合显式的遮挡 mask(shadow mapping)。
- 优点:更好地处理视角相关效应(如高光、反射);避免手工设计启发式规则。
3.4 Supervision View Sampling
以往方法使用的监督视图与MVS输入视图完全一致。
本文创新点:DIV Loss 额外采样一些非输入视图作为监督信号。
- 挑战网络去预测能在未见视角下仍一致的深度。
- 提高模型泛化能力与对缺失信息的鲁棒性。
- 几乎无额外计算成本。
4 Experiments
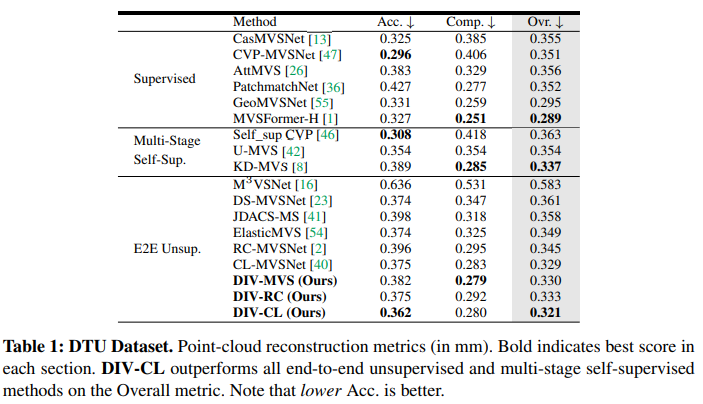
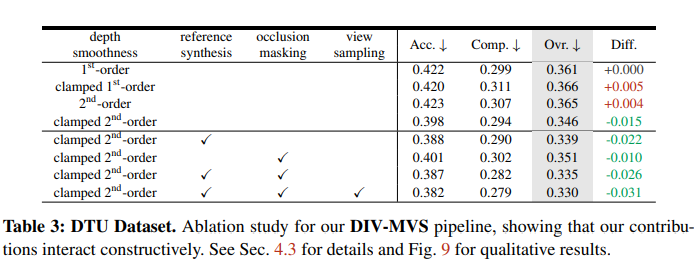
目前来说纯无监督MVS这个是SOTA,从实验表格上看这个截断loss和策略上的trick在其他MVS pipeline也可以用上。
5 核心代码
核心创新点,也就是loss中深度平滑正则项,对二阶梯度的截断,实现很简单。
python
def depth_smoothness_2nd_order(depth, img, lambda_wt=1.0, clip=2.0):
"""Computes image-aware depth smoothness loss using relaxed 2nd-order formulation."""
# 对深度图计算一阶梯度,append_zeros=True表示在图像边界补零,避免尺寸不一致
depth_dx, depth_dy = gradient(depth, append_zeros=True)
# 对一阶梯度再求梯度,得到二阶梯度
depth_dxdx, depth_dxdy = gradient(depth_dx, append_zeros=True)
depth_dydx, depth_dydy = gradient(depth_dy, append_zeros=True)
# enormous 2nd order gradients correspond to depth discontinuities
# 将所有二阶梯度截断到[-clip, clip],避免边界处的大梯度被过度penalize,从而允许物体边界出现锐利的深度不连续
depth_dxdx = torch.clip(depth_dxdx, -clip, clip)
depth_dxdy = torch.clip(depth_dxdy, -clip, clip)
depth_dydx = torch.clip(depth_dydx, -clip, clip)
depth_dydy = torch.clip(depth_dydy, -clip, clip)
# 对图像计算一阶梯度
image_dx, image_dy = gradient(img, append_zeros=True)
# get weight for gradient penalty
# 在图像的边缘处,梯度大,权重变小,相当于放宽深度平滑约束(允许深度跳变)
# 在图像平坦区域,梯度小,权重接近1,相当于强化平滑约束
weights_x = torch.exp(-(lambda_wt * torch.sum(torch.abs(image_dx), 3, keepdim=True)))
weights_y = torch.exp(-(lambda_wt * torch.sum(torch.abs(image_dy), 3, keepdim=True)))
# 对 x、y 方向分别计算平滑损失,每个方向同时考虑同方向和交叉方向的二阶导数(平均后求和),最终返回两个方向的加权平均
smoothness_x = weights_x * (torch.abs(depth_dxdx) + torch.abs(depth_dydx)) / 2.
smoothness_y = weights_y * (torch.abs(depth_dydy) + torch.abs(depth_dxdy)) / 2.
return torch.mean(smoothness_x) + torch.mean(smoothness_y)这个正则是一种无监督的几何先验,解决了"深度要合理"的问题,允许物体边界处的锐利跳变。