门控循环单元(GRU)
关注一个序列
- 不是每个观察值都是同等重要的

- 想只记住相关的观察需要:
- 能关注的机制(更新门)
- 能遗忘的机制(重置门)
门
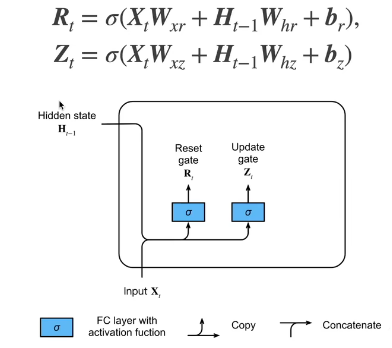
候选隐状态
H ~ t = tanh ( X t W x h + ( R t ⊙ H t − 1 ) W h h + b h ) , \tilde{\mathbf{H}}t = \tanh(\mathbf{X}t \mathbf{W}{xh} + \left(\mathbf{R}t \odot \mathbf{H}{t-1}\right) \mathbf{W}{hh} + \mathbf{b}_h), H~t=tanh(XtWxh+(Rt⊙Ht−1)Whh+bh),
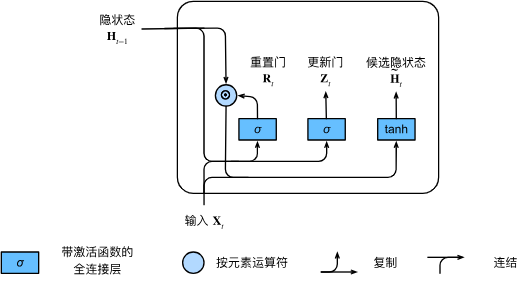
要是没有 R t R_t Rt 的话,就是之前介绍的 RNN 计算隐藏状态的方式。 ⊙ \odot ⊙ 是按元素乘法的意思。要是 R t R_t Rt 几乎为 0 的话,就意味着将上一个时刻的隐藏状态几乎忘掉。要是 R t R_t Rt 全是 1 表示所有前面的信息全部拿过来做当前的更新。类似于电路里面门的概念。
真正的隐状态
H t = Z t ⊙ H t − 1 + ( 1 − Z t ) ⊙ H ~ t . \mathbf{H}_t = \mathbf{Z}t \odot \mathbf{H}{t-1} + (1 - \mathbf{Z}_t) \odot \tilde{\mathbf{H}}_t. Ht=Zt⊙Ht−1+(1−Zt)⊙H~t.
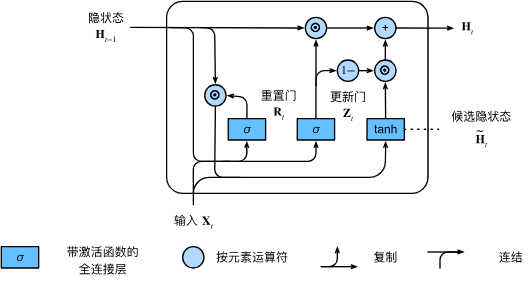
假如 Z t \mathbf{Z}_t Zt 都等于 1 ,则忽略掉当前的输入 X t \mathbf{X}_t Xt 。假如 Z t \mathbf{Z}_t Zt 都等于 0,基本上回到了 RNN 的情况:不去直接拿过去的状态,而是去看现在更新的状态。
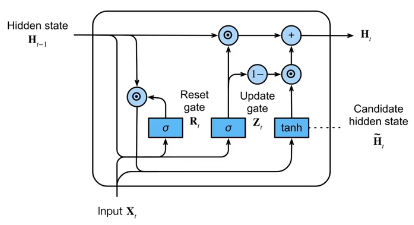
总结
R t = σ ( X t W x r + H t − 1 W h r + b r ) , R_t = σ(X_t W_{xr} + H_{t-1} W_{hr} + b_r), Rt=σ(XtWxr+Ht−1Whr+br), Z t = σ ( X t W x z + H t − 1 W h z + b z ) , Z_t = σ(X_t W_{xz} + H_{t-1} W_{hz} + b_z), Zt=σ(XtWxz+Ht−1Whz+bz), H ~ t = t a n h ( X t W x h + ( R t ⊙ H t − 1 ) W h h + b h ) , \tilde{H}t = tanh(X_t W{xh} + (R_t ⊙ H_{t-1}) W_{hh} + b_h), H~t=tanh(XtWxh+(Rt⊙Ht−1)Whh+bh), H t = Z t ⊙ H t − 1 + ( 1 − Z t ) ⊙ H ~ t H_t = Z_t ⊙ H_{t-1} + (1 - Z_t) ⊙ \tilde{H}_t Ht=Zt⊙Ht−1+(1−Zt)⊙H~t
代码实现
首先导入必要的环境,并使用时间机器数据集:
python
import torch
from torch import nn
from d2l import torch as d2l
batch_size, num_steps = 32, 35 # 批量大小,每个计算长度
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)**初始化模型参数**
下一步是初始化模型参数。我们从标准差为 0.01 0.01 0.01 的高斯分布中提取权重,并将偏置项设为 0 0 0,超参数num_hiddens定义隐藏单元的数量,实例化与更新门、重置门、候选隐状态和输出层相关的所有权重和偏置。
python
def get_params(vocab_size, num_hiddens, device):
num_inputs = num_outputs = vocab_size
def normal(shape):
return torch.randn(size=shape, device=device)*0.01
# 每调用这个函数,返回三个参数,这样写简便一点
def three():
return (normal((num_inputs, num_hiddens)),
normal((num_hiddens, num_hiddens)),
torch.zeros(num_hiddens, device=device))
W_xz, W_hz, b_z = three() # 更新门参数
W_xr, W_hr, b_r = three() # 重置门参数
W_xh, W_hh, b_h = three() # 候选隐状态参数
# 输出层参数
W_hq = normal((num_hiddens, num_outputs))
b_q = torch.zeros(num_outputs, device=device)
# 附加梯度
params = [W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q] # 9+2个可学习参数
for param in params:
param.requires_grad_(True)
return params定义模型
现在我们将 **定义隐状态的初始化函数** init_gru_state。此函数返回一个形状为(批量大小,隐藏单元个数)的张量,张量的值全部为零。
python
def init_gru_state(batch_size, num_hiddens, device):
return (torch.zeros(
(batch_size, num_hiddens), device=device), )现在我们准备**定义门控循环单元模型** ,模型的架构与基本的循环神经网络单元是相同的,
只是权重更新公式更为复杂。
python
def gru(inputs, state, params):
W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q = params
H, = state
outputs = []
for X in inputs:
# @ 就是矩阵乘法,和torch.matmul一样,还有和 torch.mm 一样的功能
Z = torch.sigmoid((X @ W_xz) + (H @ W_hz) + b_z)
R = torch.sigmoid((X @ W_xr) + (H @ W_hr) + b_r)
H_tilda = torch.tanh(
(X @ W_xh) + ((R * H) @ W_hh) + b_h)
H = Z * H + (1 - Z) * H_tilda
Y = H @ W_hq + b_q
outputs.append(Y)
return torch.cat(outputs, dim=0), (H,)**训练**与预测
训练结束后,我们分别打印输出训练集的困惑度,以及前缀"time traveler"和"traveler"的预测序列上的困惑度。
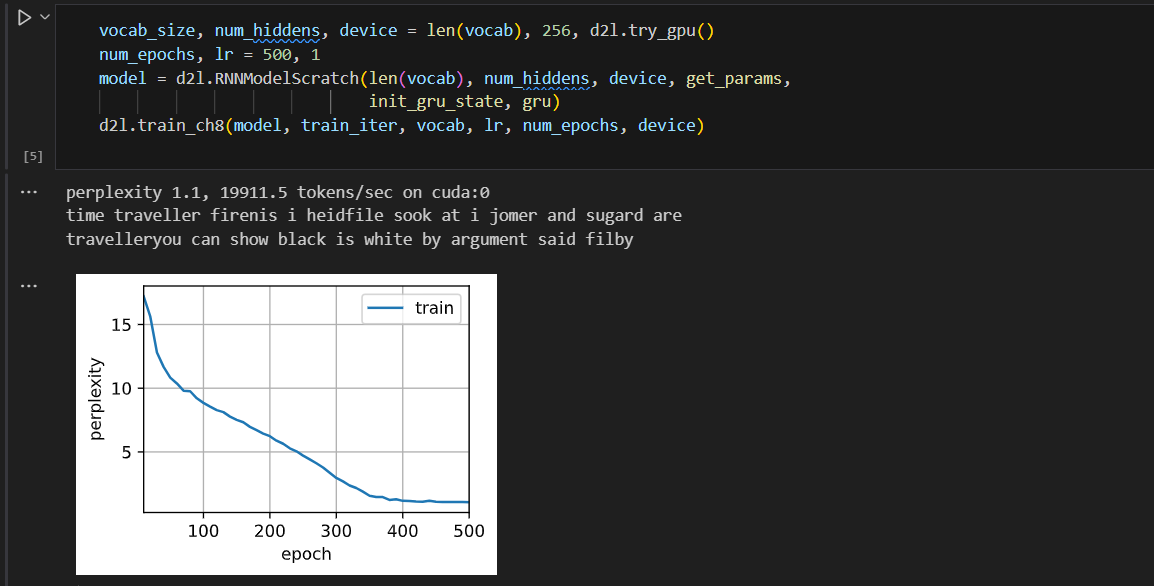
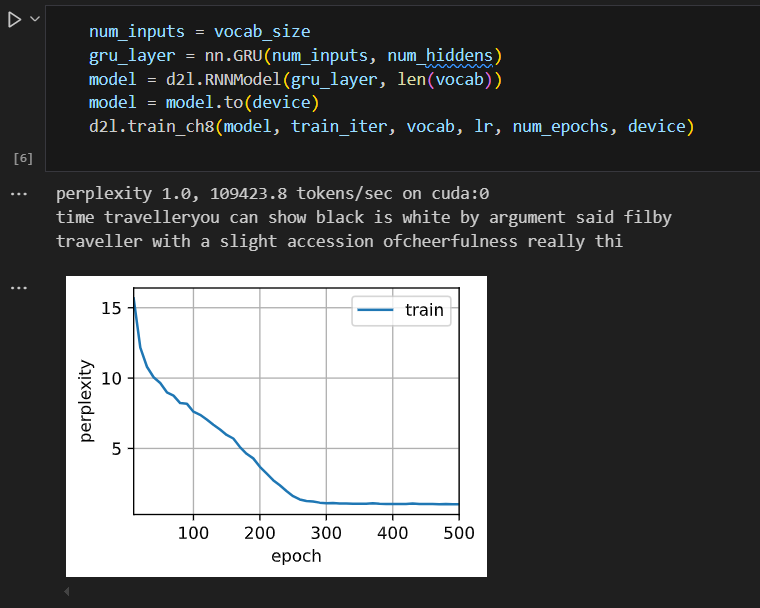
**简洁实现**
高级API包含了前文介绍的所有配置细节,所以我们可以直接实例化门控循环单元模型。这段代码的运行速度要快得多,因为它使用的是编译好的运算符而不是Python来处理之前阐述的许多细节。
小结
- 门控循环神经网络可以更好地捕获时间步距离很长的序列上的依赖关系。
- 重置门有助于捕获序列中的短期依赖关系。
- 更新门有助于捕获序列中的长期依赖关系。
- 重置门打开时,门控循环单元包含基本循环神经网络;更新门打开时,门控循环单元可以跳过子序列。
QA 思考
Q1:GRU网络中, R t R_t Rt 和 Z t Z_t Zt 的网络结构一样,为什么就可以自动把 R t R_t Rt 选成 Reset gate , Z t Z_t Zt 选成 Update gate?
A1:网络结构是一样的,但是 W W W 是可以学习的。这是我们对于模型的要求,但是模型是不是这样算的,我们是不知道的,也许模型能够学出来我们需要的样子,也许没有学习出来,可以通过可视化的方式看一下训练好的模型是不是满足我们的要求。
Q2:GRU有了Rt是不是不需要像RNN那样在换数据的时候resetH了?GRU可以自己学习到这个
A2:不是这样的,实际上,一句话概括就是:R作用于Ht-1,代表遗忘,Z作用于Xt,代表更新
Q3:GRU中的初始化隐藏层大小可以随便写吗,和MLP对比
A3:可以的,这两者的写法没有本质的区别,一般就是128、256、512。在 很大很大的时候会用到 1024。
Q4:normal函数中, torch.randn(size=shape, device=device)* 0.01这个地方为何乘以0.01
A4:只是说实践出来,发现这个在不是很深的网络中使用0.01效果还不错,于是就使用了这个。