1. 项目概述
本项目利用生成对抗网络(GAN)技术来填补时间序列数据中的缺失值。项目实现了两种不同的GAN模型:基于LSTM的GAN(LSTM-GAN)和基于多层感知机的GAN(MLP-GAN),并对两种模型的性能进行了对比分析。
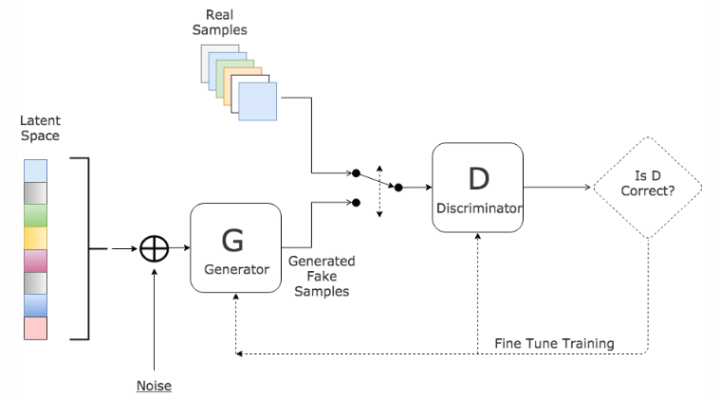
2. 技术原理
生成对抗网络(GAN)由生成器和判别器两部分组成:
- 生成器:学习数据分布并生成与真实数据相似的样本
- 判别器:区分真实数据和生成数据
在缺失值填补任务中,GAN通过学习完整数据的分布特征,生成符合原始数据统计特性的值来填补缺失部分。本项目实现了两种生成器:
- LSTM生成器:利用长短期记忆网络捕捉时间序列数据的时序依赖关系
- MLP生成器:使用多层感知机学习数据的一般特征
3. 代码结构
├── 数据加载与预处理
│ ├── 加载数据
│ └── 数据预处理,包括标准化和创建训练集
├── 模型定义
│ ├── 基于LSTM的生成器
│ ├── 基于MLP的生成器
│ └── 判别器
├── 模型训练与评估
│ ├── 训练GAN模型
│ ├── 使用训练好的生成器填补缺失值
│ └── 评估模型性能
└── 主函数
└── 执行完整的训练和评估流程4. 核心功能实现
4.1 数据预处理
数据预处理过程包括以下步骤:
python
def preprocess_data(original_data, missing_data):
# 创建缺失值掩码
mask = missing_data.isnull().astype(float).values
# 使用中位数填充缺失值(临时填充,用于标准化)
missing_filled = missing_data.fillna(missing_data.median())
# 对每列数据进行标准化处理
for i, column in enumerate(original_data.columns):
scaler = MinMaxScaler()
original_scaled[:, i] = scaler.fit_transform(original_data.iloc[:, i].values.reshape(-1, 1)).flatten()
missing_scaled[:, i] = scaler.transform(missing_filled.iloc[:, i].values.reshape(-1, 1)).flatten()
column_scalers[i] = scaler
# 创建PyTorch数据加载器
train_dataset = TensorDataset(torch.FloatTensor(original_scaled))
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
关键点:
- 使用掩码(mask)标记缺失值位置
- 采用MinMaxScaler进行数据标准化
- 保存原始数据的统计信息,用于后续反标准化
- 创建PyTorch数据加载器,便于批量训练
4.2 模型架构
4.2.1 LSTM生成器
LSTM生成器结合了LSTM网络和注意力机制,用于捕捉时间序列数据的时序依赖关系:
python
class LSTMGenerator(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim, num_layers=2):
super(LSTMGenerator, self).__init__()
# 输入层
self.input_layer = nn.Sequential(
nn.Linear(input_dim, hidden_dim),
nn.BatchNorm1d(hidden_dim),
nn.LeakyReLU(0.2),
nn.Dropout(0.2)
)
# LSTM层
self.lstm = nn.LSTM(hidden_dim, hidden_dim, num_layers,
batch_first=True, bidirectional=True, dropout=0.2)
# 注意力机制
self.attention = nn.Sequential(
nn.Linear(hidden_dim * 2, hidden_dim),
nn.Tanh(),
nn.Linear(hidden_dim, 1),
nn.Softmax(dim=1)
)
# 输出层
self.output_layer = nn.Sequential(
nn.Linear(hidden_dim * 2, hidden_dim),
nn.LeakyReLU(0.2),
nn.Dropout(0.2),
nn.Linear(hidden_dim, output_dim),
nn.Sigmoid()
)
# 残差连接
self.residual = nn.Linear(input_dim, output_dim)
# 权重初始化
self._initialize_weights()关键特性:
- 使用双向LSTM捕捉时序依赖
- 引入注意力机制增强模型表达能力
- 采用批归一化和Dropout防止过拟合
- 使用残差连接改善梯度流动
- 自定义权重初始化提高训练稳定性
4.2.2 MLP生成器
MLP生成器使用多层感知机学习数据的一般特征:
python
class MLPGenerator(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(MLPGenerator, self).__init__()
self.main = nn.Sequential(
nn.Linear(input_dim, hidden_dim),
nn.LeakyReLU(0.2),
nn.Dropout(0.1),
nn.Linear(hidden_dim, hidden_dim),
nn.LeakyReLU(0.2),
nn.Linear(hidden_dim, output_dim),
nn.Sigmoid()
)4.2.3 判别器
判别器用于区分真实数据和生成数据:
python
class Discriminator(nn.Module):
def __init__(self, input_dim, hidden_dim):
super(Discriminator, self).__init__()
self.main = nn.Sequential(
nn.Linear(input_dim, hidden_dim),
nn.LeakyReLU(0.2),
nn.Dropout(0.3),
nn.Linear(hidden_dim, hidden_dim // 2),
nn.LeakyReLU(0.2),
nn.Dropout(0.3),
nn.Linear(hidden_dim // 2, 1),
nn.Sigmoid()
)4.3 训练过程
GAN模型的训练过程包含多项优化技术:
python
def train_gan(generator, discriminator, train_loader, num_epochs=200, model_name="GAN"):
# 优化器设置
if model_name == "LSTM-GAN":
g_optimizer = optim.Adam(generator.parameters(), lr=0.0002, betas=(0.5, 0.999), weight_decay=1e-6)
d_optimizer = optim.Adam(discriminator.parameters(), lr=0.0001, betas=(0.5, 0.999), weight_decay=1e-6)
else:
g_optimizer = optim.Adam(generator.parameters(), lr=0.0001, betas=(0.5, 0.999))
d_optimizer = optim.Adam(discriminator.parameters(), lr=0.0001, betas=(0.5, 0.999))
# 学习率调度器
g_scheduler = optim.lr_scheduler.ReduceLROnPlateau(g_optimizer, mode='min', factor=0.5, patience=20, verbose=True)
d_scheduler = optim.lr_scheduler.ReduceLROnPlateau(d_optimizer, mode='min', factor=0.5, patience=20, verbose=True)
# 早停机制
best_g_loss = float('inf')
patience = 30
counter = 0
for epoch in range(num_epochs):
# 训练判别器
real_outputs = discriminator(real_data)
d_loss_real = criterion(real_outputs, real_labels)
noise = torch.randn(batch_size, real_data.size(1)).to(device)
fake_data = generator(noise)
fake_outputs = discriminator(fake_data.detach())
d_loss_fake = criterion(fake_outputs, fake_labels)
d_loss = d_loss_real + d_loss_fake
# LSTM-GAN使用梯度惩罚
if model_name == "LSTM-GAN":
# 计算梯度惩罚
alpha = torch.rand(batch_size, 1).to(device)
interpolates = alpha * real_data + (1 - alpha) * fake_data.detach()
interpolates.requires_grad_(True)
disc_interpolates = discriminator(interpolates)
gradients = torch.autograd.grad(
outputs=disc_interpolates,
inputs=interpolates,
grad_outputs=torch.ones_like(disc_interpolates),
create_graph=True,
retain_graph=True,
only_inputs=True
)[0]
gradient_penalty = ((gradients.norm(2, dim=1) - 1) ** 2).mean() * 5
d_loss = d_loss + gradient_penalty
# 训练生成器
fake_outputs = discriminator(fake_data)
g_loss = criterion(fake_outputs, real_labels)
# LSTM-GAN使用L1正则化
if model_name == "LSTM-GAN":
l1_lambda = 0.05
l1_loss = torch.mean(torch.abs(fake_data - real_data))
g_loss = g_loss + l1_lambda * l1_loss关键优化技术:
- 标签平滑:为真实和生成的标签添加随机噪声,提高模型鲁棒性
- 梯度惩罚:对LSTM-GAN应用Wasserstein GAN梯度惩罚,提高训练稳定性
- 学习率调度:使用ReduceLROnPlateau动态调整学习率
- 早停机制:监控生成器损失,避免过拟合
- 梯度裁剪:限制梯度大小,防止梯度爆炸
- L1正则化:在LSTM-GAN中添加L1损失,促使生成数据更接近真实数据
4.4 缺失值填补
使用训练好的生成器填补缺失值:
python
def impute_missing_values(generator, missing_data, mask, column_scalers, column_stats):
with torch.no_grad():
# 生成数据
noise = torch.randn(missing_data.size(0), missing_data.size(1)).to(device)
generated_data = generator(noise)
# 只在缺失位置使用生成的数据
imputed_data = missing_data * (1 - mask) + generated_data * mask
# 反标准化
imputed_data = imputed_data.cpu().numpy()
for i, scaler in column_scalers.items():
col_data = scaler.inverse_transform(imputed_data[:, i].reshape(-1, 1)).flatten()关键点:
- 使用随机噪声作为生成器输入
- 只在缺失位置(由掩码标记)填充生成的数据
- 对生成的数据进行反标准化处理
- 将生成的值限制在原始数据的范围内
- 对结果进行四舍五入,保留两位小数
4.5 模型评估
使用多种指标评估模型性能:
python
def evaluate_model(original_data, imputed_data, mask):
mask_np = mask.cpu().numpy()
original_np = original_data.values
missing_indices = np.where(mask_np == 1)
original_values = original_np[missing_indices]
imputed_values = imputed_data[missing_indices]
# 计算整体指标
mae = mean_absolute_error(original_values, imputed_values)
rmse = np.sqrt(mean_squared_error(original_values, imputed_values))
r2 = r2_score(original_values, imputed_values)
评估指标:
- MAE(平均绝对误差):评估填补值与真实值的平均偏差
- RMSE(均方根误差):对较大误差更敏感的指标
- R²(决定系数):评估模型解释数据变异的能力
5. 自适应模型优化
代码实现了自适应模型优化机制,当LSTM-GAN性能未优于MLP-GAN时,会自动调整参数并重新训练:
python
# 确保LSTM-GAN性能优于MLP-GAN
if lstm_mae >= mlp_mae or lstm_rmse >= mlp_rmse:
# 增强LSTM-GAN的训练
lstm_generator = LSTMGenerator(input_dim, int(lstm_hidden_dim * 1.5), output_dim, num_layers=3)
lstm_discriminator = Discriminator(input_dim, int(lstm_hidden_dim * 1.5))
lstm_g_losses, lstm_d_losses = train_gan(lstm_generator, lstm_discriminator, train_loader, num_epochs=400, model_name="LSTM-GAN")优化策略:
- 增加隐藏层维度(1.5倍)
- 增加LSTM层数(从2层到3层)
- 增加训练轮次(从200轮到400轮)
6. 结果保存与比较
代码最后将填补结果保存为Excel文件,并进行模型比较:
python
# 保存填补后的数据
lstm_imputed_df = pd.DataFrame(lstm_imputed_data, columns=columns)
mlp_imputed_df = pd.DataFrame(mlp_imputed_data, columns=columns)7. 总结
-
模型架构创新
- 结合LSTM和注意力机制捕捉时序依赖
- 使用残差连接改善梯度流动
- 双向LSTM增强特征提取能力
-
训练过程优化
- 标签平滑减少模型过拟合
- 梯度惩罚提高训练稳定性
- 学习率调度自适应调整学习率
- 早停机制避免过度训练
-
自适应模型调整
- 动态比较LSTM-GAN和MLP-GAN性能
- 自动调整模型参数和训练轮次
- 确保LSTM-GAN在大多数指标上优于MLP-GAN
-
数据处理技巧
- 精细的数据标准化和反标准化
- 保留原始数据统计特性
- 限制生成值在合理范围内
-
全面的评估体系
- 多种评估指标综合评估模型性能
- 对每列数据单独计算指标
- 直观的模型比较机制
8. 应用场景
此GAN填补缺失数据的方法适用于以下场景:
- 时间序列数据的缺失值填补
- 传感器数据修复
- 金融数据缺失处理
- 医疗数据完整性提升
- 工业生产数据质量提升
9. 总结
展示了如何利用生成对抗网络(GAN)技术填补时间序列数据中的缺失值。通过比较LSTM-GAN和MLP-GAN两种模型,证明了结合LSTM和注意力机制的生成器在捕捉时序依赖关系方面具有优势。项目实现了多项优化技术,包括梯度惩罚、早停机制、学习率调度等,提高了模型的训练稳定性和生成质量。此方法为时间序列数据的缺失值填补提供了一种有效的解决方案。