孤立森林算法:异常检测的高效利器
文章目录
- 孤立森林算法:异常检测的高效利器
1 引言
在数据挖掘和机器学习领域,异常检测是一个重要的研究方向。异常检测的目标是从数据集中找出与大多数数据显著不同的异常点。这些异常点可能代表系统故障、欺诈行为、网络入侵等异常情况。本文将介绍一种高效的异常检测算法------孤立森林(Isolation Forest),它以其简单高效的特点在异常检测领域备受关注。
2 孤立森林算法原理
2.1 核心思想
孤立森林算法的核心思想非常直观:异常点更容易被孤立 。如下图所示,B点所表示的数据很可能是一个异常值。
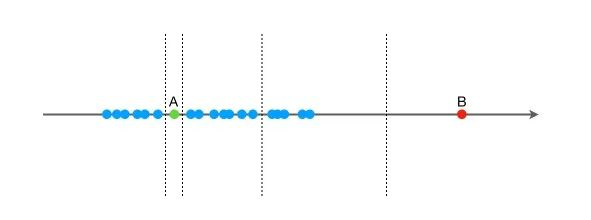
与传统的基于密度或距离的异常检测方法不同,孤立森林采用了一种全新的视角:通过随机构建决策树来孤立数据点。算法假设异常点具有以下两个关键特性:
- 数量少
- 特征 值与正常点显著不同
基于这两个特性,异常点通常更容易在决策树的早期被孤立出来,即到达叶子节点所需的决策路径更短。
2.2 算法流程
孤立森林(Isolation Forest)是一种无监督学习算法,主要用于异常检测,以下是它的主要步骤和相关公式(参考资料:孤立森林(isolation):一个最频繁使用的异常检测算法 。):
步骤一:构建孤立树(iTree)
- 随机选择数据集的子样本
- 随机选择一个特征维度 q
- 随机选择一个分割值 p (在特征 q 的最大值和最小值之间)
- 根据特征 q 和分割值 p 将数据分为左右两部分
- 递归重复上述过程,直到:
- 节点中只包含一个样本
- 达到预定义的最大树高度 (通常为 log₂(子样本大小))
- 所有样本具有相同的特征值
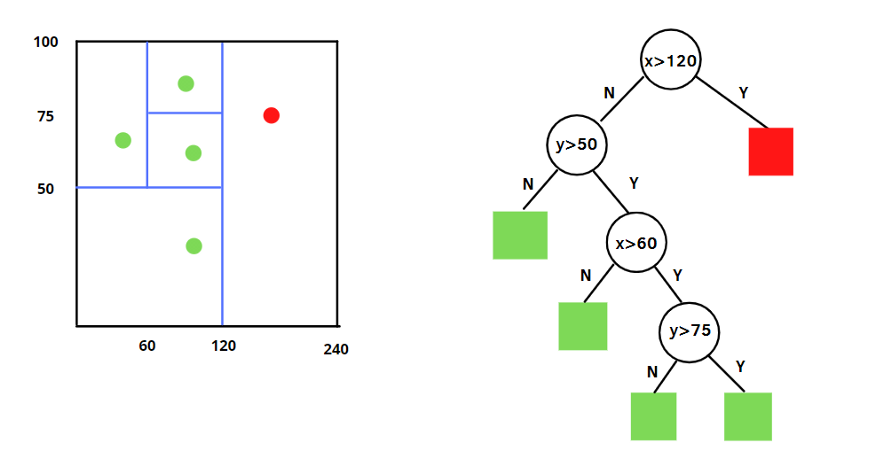
步骤二:构建孤立森林(iForest)
- 重复构建多棵孤立树(通常为50-100棵)
步骤三:计算异常分数
- 对于每个样本,计算在每棵树 中的路径长度(从根节点到终止节点的边数)
- 取这个样本在所有树中的平均路径长度作为该样本的最终路径长度
异常分数 s 的计算公式为:
s ( x , n ) = 2 − E ( h ( x ) ) c ( n ) s(x, n) = 2^{-\frac{E(h(x))}{c(n)}} s(x,n)=2−c(n)E(h(x))
其中:
- h ( x ) h(x) h(x) 是样本 x x x 的平均路径长度
- E ( h ( x ) ) E(h(x)) E(h(x)) 是 h ( x ) h(x) h(x) 的期望值
- c ( n ) c(n) c(n) 是样本数为 n 的二叉搜索树的平均路径长度的归一化因子
归一化因子 c ( n ) c(n) c(n) 的计算公式:
c ( n ) = 2 H ( n − 1 ) − 2 ( n − 1 ) n c(n) = 2H(n-1) - \frac{2(n-1)}{n} c(n)=2H(n−1)−n2(n−1)
其中 H ( i ) H(i) H(i) 是第 i 个调和数:
H ( i ) = ln ( i ) + 0.5772156649 H(i) = \ln(i) + 0.5772156649 H(i)=ln(i)+0.5772156649
- 当 s s s 接近 1 时,样本更可能是异常点
- 当 s s s 接近 0.5 时,样本更可能是正常点
- 当 s s s 明显小于 0.5 时,样本可能在一个密集区域
通常我们设置一个阈值(如0.6)来判断异常点。
3 代码实现
下面是使用Python和scikit-learn库实现孤立森林算法的示例:
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import IsolationForest
from sklearn.datasets import make_blobs
# 生成示例数据:正常点和异常点
n_samples = 300
n_outliers = 15
X, _ = make_blobs(n_samples=n_samples-n_outliers, centers=1, cluster_std=0.5, random_state=42)
# 添加一些异常点
rng = np.random.RandomState(42)
X = np.vstack([X, rng.uniform(low=-4, high=4, size=(n_outliers, 2))])
# 训练孤立森林模型
clf = IsolationForest(n_estimators=100, max_samples='auto', contamination=float(n_outliers) / n_samples,
random_state=42)
clf.fit(X)
# 预测结果
y_pred = clf.predict(X) # 1表示正常点,-1表示异常点
scores = clf.decision_function(X) # 异常分数
# 可视化结果
plt.figure(figsize=(10, 7))
plt.scatter(X[:, 0], X[:, 1], c=y_pred, cmap='viridis', s=50)
plt.colorbar(label='预测结果:1为正常,-1为异常')
plt.title('孤立森林异常检测结果')
plt.xlabel('特征1')
plt.ylabel('特征2')
plt.show()算法优势
孤立森林算法相比传统异常检测方法具有以下优势:
- 高效性:时间复杂度为O(n log n),适用于大规模数据集
- 无需密度估计:不需要计算点与点之间的距离或密度,减少了计算开销
- 适应高维数据:不受维度灾难的影响,在高维空间中表现良好
- 无需假设数据分布:不需要对数据分布做任何假设
- 易于实现和使用:算法简单,参数较少
应用场景
孤立森林算法在多个领域有广泛应用:
- 金融欺诈检测:识别异常交易行为
- 网络安全:检测网络入侵和异常流量
- 工业监控:发现设备异常运行状态
- 医疗健康:识别异常生理指标
- 质量控制:检测生产过程中的异常产品
算法参数调优
在使用孤立森林算法时,以下参数需要特别关注:
- n_estimators:森林中树的数量,通常100~200棵树已经足够
- max_samples:每棵树的样本数量,默认为'auto'(256)
- contamination:数据集中预期的异常比例
- max_features:每次分割考虑的特征数量
- bootstrap:是否使用有放回抽样
局限性与改进
尽管孤立森林算法表现优秀,但它也存在一些局限性:
- 对于具有不同密度区域的数据集,可能会将低密度正常区域误判为异常
- 在处理包含大量不相关特征的数据时效果可能下降
针对这些问题,研究人员提出了一些改进版本,如Extended Isolation Forest和SCiForest等。
结论
孤立森林算法凭借其简单、高效、可扩展的特点,已成为异常检测领域的重要工具。它不仅在理论上具有坚实基础,在实际应用中也展现出了强大的性能。对于需要进行异常检测的数据科学家和工程师来说,孤立森林无疑是一个值得掌握的算法。
在实际应用中,建议将孤立森林与其他异常检测方法结合使用,以获得更加稳健的检测结果。同时,针对特定领域的数据特点进行参数调优,也能显著提升算法性能。
参考资料
- Liu, F. T., Ting, K. M., & Zhou, Z. H. (2008). Isolation forest. In 2008 Eighth IEEE International Conference on Data Mining (pp. 413-422). IEEE.
- Scikit-learn官方文档:Isolation Forest
- 周志华. (2016). 机器学习. 清华大学出版社.
本文介绍了孤立森林算法的基本原理、实现方法、优势特点及应用场景,希望能对读者理解和应用这一算法有所帮助。如有问题,欢迎在评论区讨论交流!