目录
[1 Hive概述:连接SQL世界与Hadoop生态](#1 Hive概述:连接SQL世界与Hadoop生态)
[2 从传统数据仓库到Hive的演进之路](#2 从传统数据仓库到Hive的演进之路)
[2.1 传统数据仓库的局限性](#2.1 传统数据仓库的局限性)
[2.2 Hive的革命性突破](#2.2 Hive的革命性突破)
[3 Hive的核心架构与执行流程](#3 Hive的核心架构与执行流程)
[3.1 Hive系统架构](#3.1 Hive系统架构)
[3.2 SQL查询执行全流程](#3.2 SQL查询执行全流程)
[4 Hive与传统方案的对比分析](#4 Hive与传统方案的对比分析)
[5 Hive最佳实践](#5 Hive最佳实践)
[5.1 存储格式选择建议](#5.1 存储格式选择建议)
[5.2 性能优化技巧](#5.2 性能优化技巧)
1 Hive概述:连接SQL世界与Hadoop生态
在大数据时代,Hive作为Apache顶级开源项目,成功架起了传统SQL与Hadoop分布式计算之间的桥梁。它允许数据分析师和数据工程师使用熟悉的SQL语法来查询和管理存储在Hadoop分布式文件系统(HDFS)中的海量数据。

- Hive充当SQL用户与Hadoop集群之间的"翻译官"
- 将SQL查询转换为底层计算引擎(如MapReduce、Tez或Spark)可执行的任务
- 通过元数据管理实现表结构的持久化存储
2 从传统数据仓库到Hive的演进之路
2.1 传统数据仓库的局限性
传统数据仓库(如Teradata、Oracle Exadata)在大数据时代面临的主要问题:
- 垂直扩展成本呈指数级增长
- 商业许可费用昂贵
- 难以处理非结构化数据
- 批处理延迟高
2.2 Hive的革命性突破
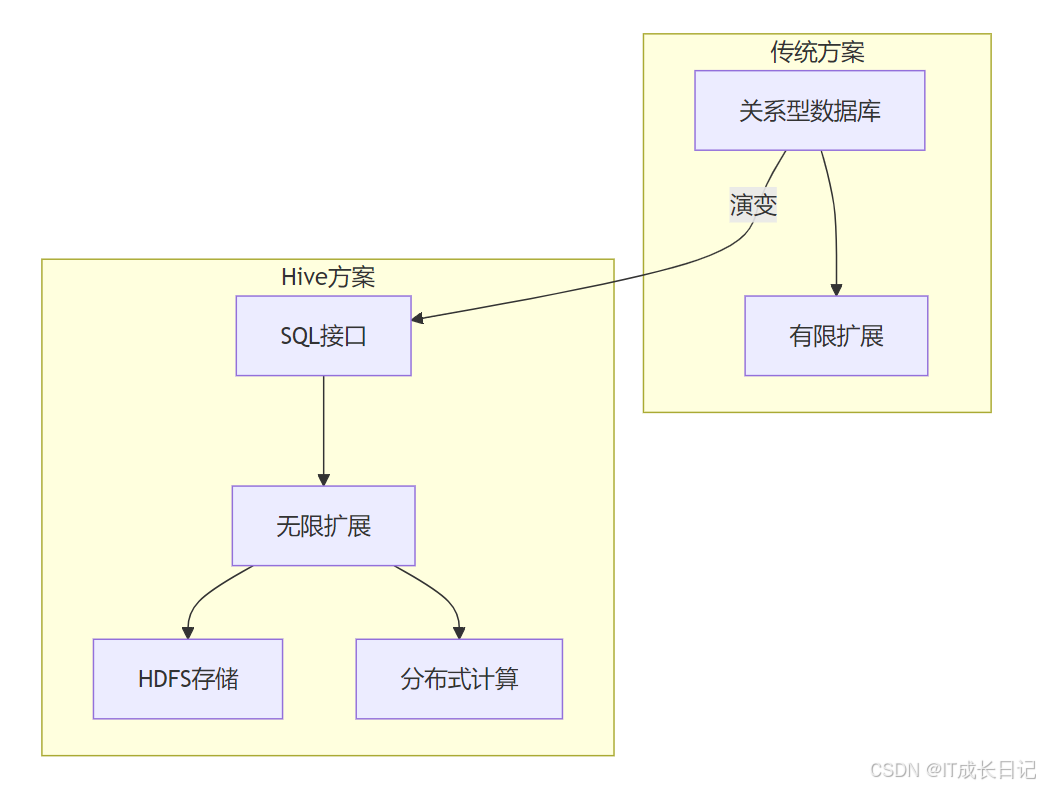
- 使用HDFS实现存储层无限扩展
- 支持多种文件格式(文本、ORC、Parquet等)
- 通过元数据服务实现表结构管理
- 兼容大多数SQL-92标准
3 Hive的核心架构与执行流程
3.1 Hive系统架构
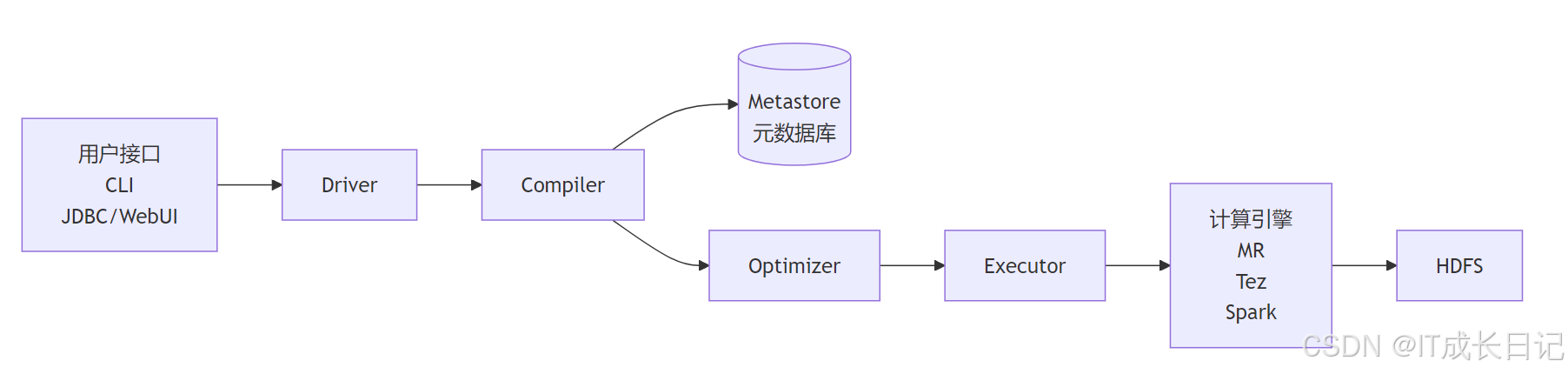
- 用户接口:提供多种访问方式
- Driver:控制整个查询生命周期
- Compiler:SQL解析和任务生成
- Metastore:存储表结构等元数据
- Executor:任务提交和监控
3.2 SQL查询执行全流程

- 语法解析:将SQL转换为抽象语法树(AST)
- 逻辑优化:应用谓词下推、分区裁剪等优化规则
- 物理计划:生成可执行的DAG任务图
- 任务执行:通过计算引擎完成分布式计算
4 Hive与传统方案的对比分析
|------|--------------|--------------|
| 维度 | 传统数据仓库 | Hive解决方案 |
| 扩展能力 | 垂直扩展,有限 | 水平扩展,近乎无限 |
| 成本模型 | CAPEX高,许可费用贵 | OPEX低,开源免费 |
| 数据规模 | TB级 | PB级+ |
| 查询延迟 | 亚秒级 | 分钟级+ |
| 数据格式 | 仅结构化 | 结构+半结构化 |
| 生态整合 | 封闭系统 | 深度Hadoop生态集成 |
5 Hive最佳实践
5.1 存储格式选择建议
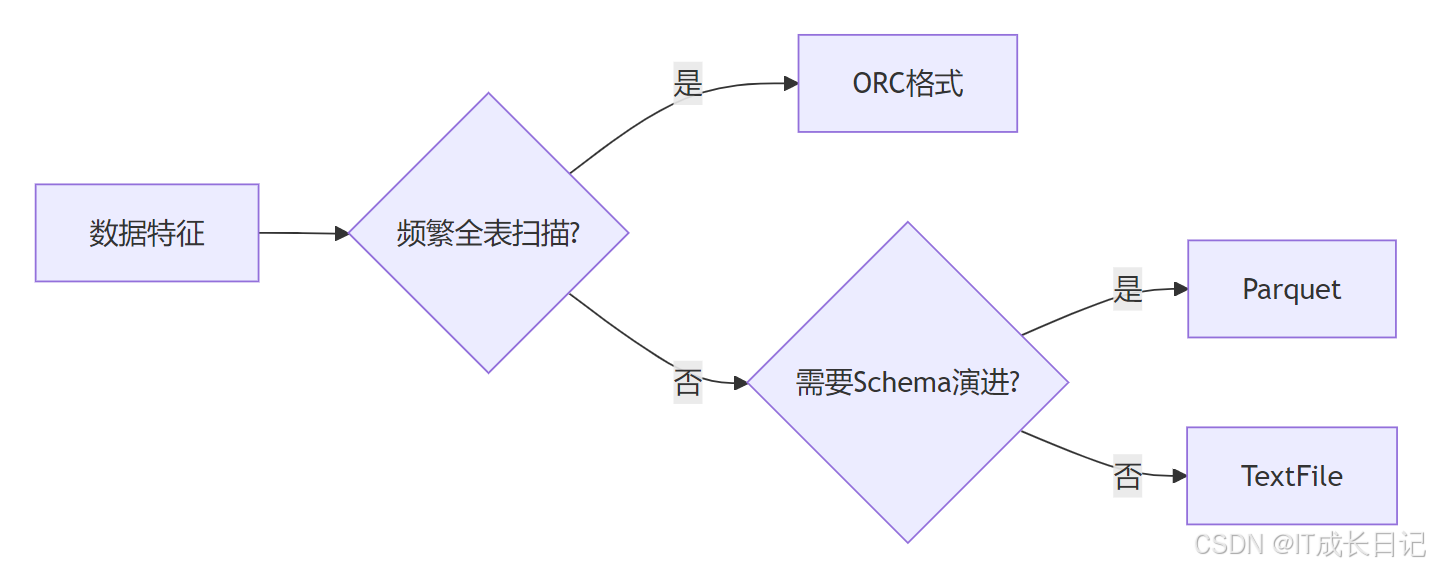
格式选择指南:
- ORC:适合Hive专属场景,压缩率高
- Parquet:跨生态通用,支持复杂嵌套结构
- TextFile:易读性高但性能较差
5.2 性能优化技巧
-
分区设计:按时间、地域等维度合理分区
示例
create table logs (
id bigint,
content string
) partitioned by (dt string, region string); -
启用向量化执行
set hive.vectorized.execution.enabled=true;
-
使用CBO优化器
set hive.cbo.enable=true;