25年4月来自天津大学、山东大学、瑞士ETH、南方科技大学、通用 AI 国家重点实验室、爱丁堡大学和中科院自动化所的论文"Dexterous Manipulation through Imitation Learning: A Survey"。
灵巧操作是指机械手或多指末端执行器通过精确、协调的手指运动和自适应力调制,熟练地控制、重定位和操纵物体的能力,能够实现类似于人手灵巧性的复杂交互。随着机器人技术和机器学习的最新进展,人们对这些系统在复杂和非结构化环境中运行的需求日益增长。由于灵巧操作的高维度和复杂的接触动力学,传统的基于模型方法难以跨任务和目标变化进行泛化。尽管强化学习 (RL) 等无模型方法前景光明,但它们需要大量的训练、大规模的交互数据以及精心设计的奖励机制,以确保稳定性和有效性。模仿学习 (IL) 提供一种替代方案,它允许机器人直接从专家演示中习得灵巧操作技能,捕捉细粒度的协调和接触动力学,同时无需显式建模和大规模试错。本综述概述基于模仿学习 (IL) 的灵巧操作方法,详细介绍最新进展,并探讨该领域的关键挑战。此外,本文还探讨增强 IL 驱动灵巧操作的潜在研究方向。
在过去的几十年里,机器人技术吸引了大量的研究兴趣,其中灵巧操作尤为受到关注。灵巧操作旨在利用机械手或其他末端执行器,以接近人类的灵巧度,在各种场景中执行复杂、精确和灵活的任务(例如抓取物体、打开抽屉和旋转铅笔)。这种高精度操作能力支持广泛的应用领域,包括工业制造1--4、太空或水下探索5--8以及医疗保健9--12。近年来,模仿学习13, 14的快速发展,旨在通过观察和模仿人类或其他智体的行为来获取知识,推动了计算机图形学和机器人技术的显著进步。作为一种为机器人配备人类先验知识的直观方法,尤其是在与物体交互和理解场景的能力方面,IL 在使机器人能够以类似人类的灵巧度执行任务方面表现出色。
早在强化学习 (RL) 被用于通过与环境的迭代交互和基于奖励的反馈机制来优化机器人行为策略之前,灵巧操作的研究就已经引起了广泛关注。传统方法通过域动态建模和应用最优控制方法来鼓励机器人获得灵巧操作技能。这些方法在理论上是合理的,但很大程度上依赖于世界模型的保真度。
然而,当涉及到灵巧操作时,例如组装精密部件或执行复杂的外科手术,需要高度的灵活性和多自由度的运动能力来执行复杂的类人任务。灵巧操作的成功执行取决于复杂且高精度的机械设计,例如多指机械手 20 或拟人手臂 21,以及处理高维空间 21 和多接触动力学 22 所需的复杂控制算法。如图所示:

近年来,将 IL 应用于机器人领域的探索引起研究人员的广泛关注。无需构建复杂的世界模型和精心设计的奖励函数,IL 就能让机器人通过观察和模仿专家演示来学习任务。这种方法很直观,因为目标是让机器人像人类专家一样执行任务来替代人类劳动。具体来说,第一步是收集专家演示的数据集,其中包含由人类或训练有素的智体执行的操作任务的轨迹。机器人以这些轨迹为参考来学习任务行为。为了确保一致性,最好在数据收集和执行阶段使用相同的机器人。然而,这种实现方式不利于促进异构机器人系统之间的数据共享。
一种解决方案是将原始机械手的轨迹映射到目标机器人,这一过程称为重定向。尽管如此,在构建大规模数据集的背景下,人类操作机器人进行数据收集的过程仍然是一项耗时耗力的任务。为了解决这个问题,研究人员17、23、24采用计算机视觉中的姿态估计技术,开发从人手到机械手的映射,有效降低收集演示数据的门槛。此外,数据集增强增强泛化到新物体和场景的能力,有助于扩展数据集。
IL 模仿类似于监督学习 (SL) 的专家行为,并且经常与强化学习 (RL) 相结合以解决复杂的决策任务。IL 和 SL 在从演示或真实数据中学习方面有相似之处。然而,它们的目标不同:SL 旨在在静态场景中产生与真实数据相同的输出,而 IL 则侧重于在动态环境中完成任务,例如操作任务中目标物体位置的变化和环境干扰。这类任务通常涉及连续决策,错误会逐步累积,最终导致错误加剧,最终导致整体任务失败。IL 通过在后续决策中调整和补偿初始错误来强调任务的完成,从而降低其整体影响。
在灵巧操作任务中,RL 和 Il 通常结合使用。这种结合解决由智体庞大而复杂的动作空间带来的效率低下问题,因为其空间自由度很高,使得纯 RL 探索的效率降低。IL 利用专家演示提供直接指导,从而减少探索时间并提高效率。此外,操作任务的奖励函数通常难以设计,不同的任务通常需要不同的奖励函数。然而,IL 的优势在于它拥有一个相对通用的奖励函数来拟合演示轨迹,只需提供不同的演示数据,最终提高学习效率和任务成功率。
IL 对于灵巧操作任务尤其有利。这是因为灵巧操作所涉及的物体通常是为人类设计的,因此执行这些任务的机器人很可能具有与人类或人体部位相似的结构,例如人形机器人、双臂机械手或灵巧手。它们通常需要精确的控制、协调和适应性,而这些特性很难通过传统方法实现。具体来说,这种学习范式包括各种分支,例如行为克隆 2526,混合方法(RL 和 IL 的结合)2728,分层 IL 2930 等,每个分支都为学习过程贡献了独特的优势。
由于 IL 与灵巧操作的交叉代表机器人研究的前沿。在过去的十年中,包括 DAPG 27(DRL 与人类演示相结合以解决高维灵巧操作任务);隐行为克隆 26(专注于从数学角度改进机器人策略学习);Hiveformer 31(探索创建多模态交互式智体);扩散策略 32(利用生成模型的最新进展以在操作任务中实现更佳性能)在内的多项研究已被提出,并显著扩展机器人灵巧操作的可实现边界。
然而,尽管近年来该领域取得了长足的进步,但仍面临诸多挑战。IL 的数据收集既费时又费力 33。将习得的行为泛化到新任务和不同环境中也并非易事 34。此外,实时控制和模拟-到-现实的迁移(即在模拟中训练的机器人必须在现实世界中高效运行)都阻碍其应用 35。应对这些挑战需要齐心协力,开发更高效的数据收集方法,改进学习算法,并增强机器人系统的物理能力。
本综述的主要目的是概述基于 IL 的灵巧操作方法。如图所示综述的结构:基于 IL 的灵巧操纵方法
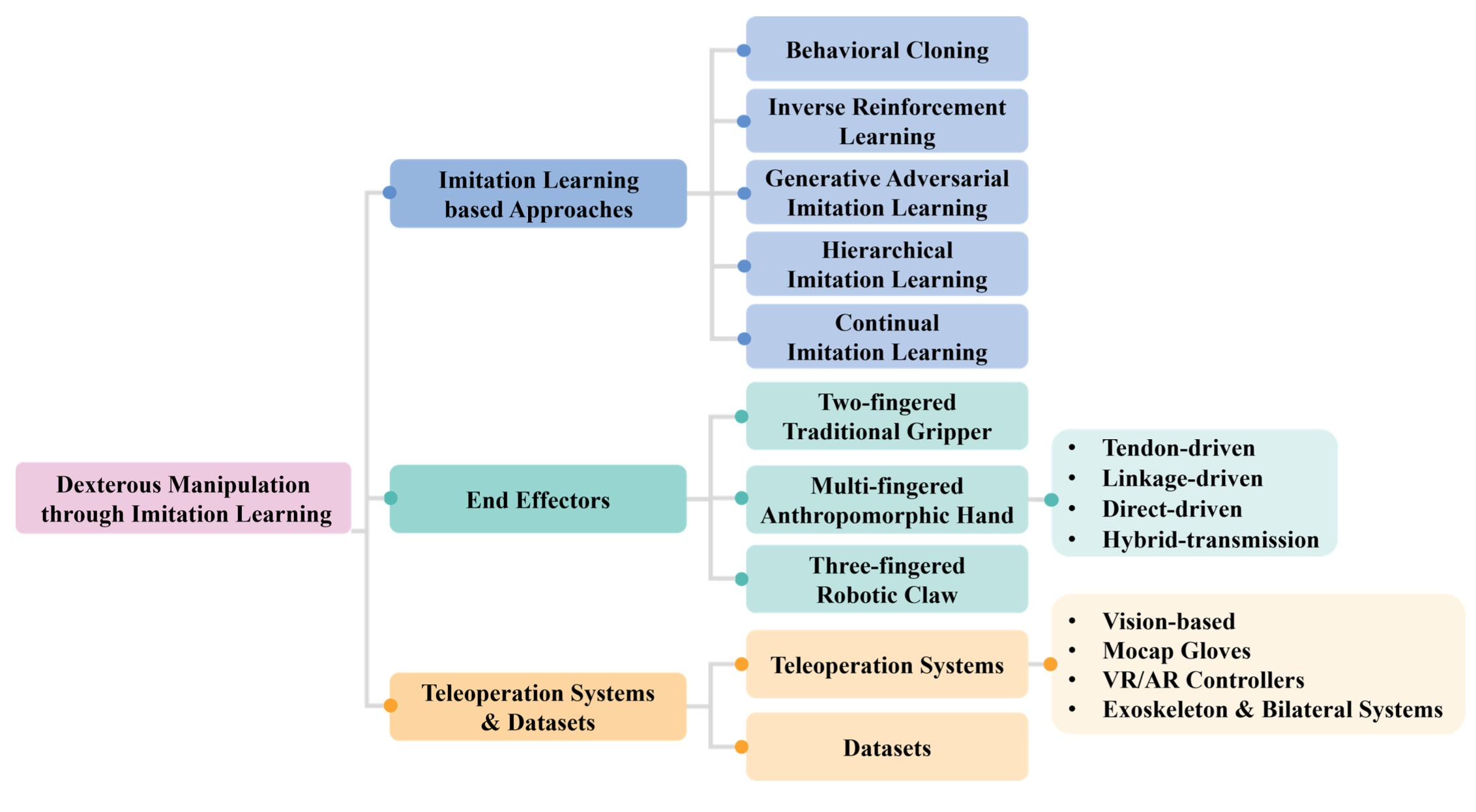
灵巧操作
在机器人领域,灵巧操作 36--38 是指机器人系统执行复杂而精确任务的能力。这些任务通常使用夹持器或灵巧手来抓取、操纵和操控物体 39。灵巧操作具有高度自由度和精细运动技能的特点,其范围不仅限于简单的拾取和放置操作,还包括工具使用、物体重定位和复杂的装配任务等活动。实现此类操作通常需要使用复杂的末端执行器,这些末端执行器旨在模拟人手的多功能性和灵巧性,例如多指手或拟人机械臂。
灵巧操作面临着多项重大挑战,包括精确控制、高维运动规划以及对动态环境的实时适应性 40。这些任务的复杂性不仅需要稳健的机械设计,还需要能够处理多接触交互复杂性和现实场景中固有的多变性的先进控制算法。
由于操作任务的复杂性日益增加,传统的基于模型的方法 41, 42 已不再适合执行复杂任务的机器人。因此,基于学习的方法得到广泛的研究,其中强化学习 (RL) 成为一种有效的方法。许多研究利用强化学习帮助机器人学习灵巧策略 43--47。然而,纯强化学习有几个固有的缺点。在灵巧操作任务中,强化学习算法通常难以有效地探索高维动作空间 48。此外,设计合理的奖励函数具有挑战性;有缺陷的奖励函数会影响探索和学习速度,导致性能下降。
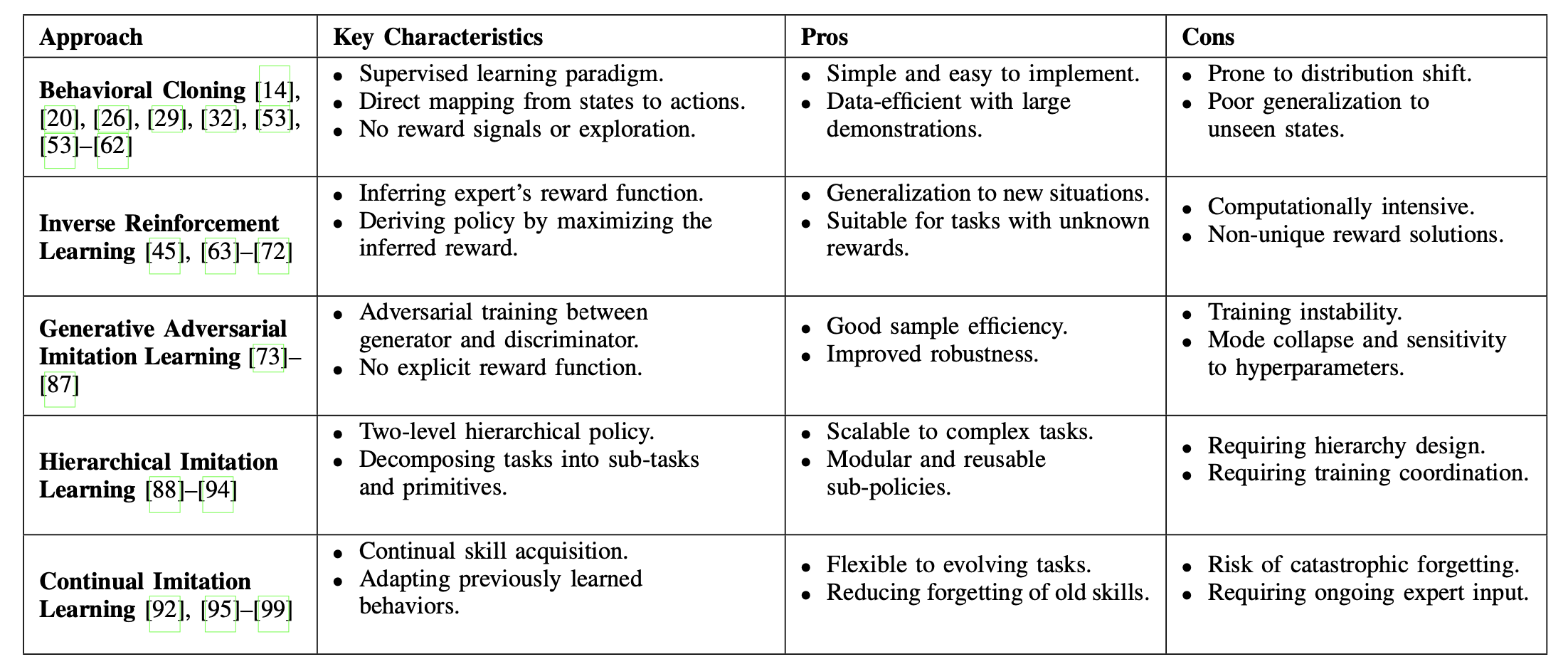
最近,模仿学习 (IL) 的进展为应对这些挑战开辟新的途径。下表是各种 IL 方法的比较:
模仿学习
IL 的主要目的是使智体能够通过模仿专家演示来学习和执行行为 35。相比之下,纯强化学习需要精心设计的奖励函数,并且在所需行为难以用算法描述但易于演示的场景中尤其有效。IL 利用这些专家演示,通过建立观察的状态与相应动作之间的关联来指导智体的学习过程。通过 IL,智体可以超越仅仅在受控和受限环境中复制基本和预定义行为的范畴,使其能够在复杂的非结构化环境中自主执行最优动作 49。因此,IL 显著减轻专家的负担,促进了高效的技能迁移。
IL 方法大致可分为几个子类,包括行为克隆 50、逆强化学习 (IRL) 51 和生成对抗模仿学习 (GAIL) 52。行为克隆通过 SL 技术将观察的动作直接映射到智体的动作。另一方面,IRL 旨在推断激励演示者行为的底层奖励结构,从而使智体能够相应地优化其行为。GAIL 采用对抗性训练技术,通过区分专家行为和智体行为来改进模仿策略,从而提高智体准确复制所需行为的能力。
基于IL的灵巧操作方法分为四类:(1)行为克隆;(2)逆强化学习;(3)生成对抗模仿学习;以及其他扩展框架,包括(4)分层模仿学习和(5)持续模仿学习。
行为克隆
- 描述:行为克隆 (BC) 是指通过直接从已演示的状态-动作对中学习来复制专家行为。具体而言,BC 的特点是:(1) 采用监督学习范式;(2) 状态-到-动作的直接映射,而不依赖于奖励信号或探索(这在强化学习中很常见)。
为了正式定义 BC,考虑 n 个演示的集合 D = {τ_1, ..., τ_n},其中每个演示 τ_i 是长度为 N_i 的状态-动作对序列。具体而言,τ_i = {(s_1, a_1), ..., (s_N_i, a_N_i)},其中状态 s ∈ S,动作 a ∈ A。S 和 A 分别表示状态空间和动作空间。 BC 的目标是学习一个策略 π : S → A,通过最小化演示动作的负对数似然来模仿专家行为。
- 研究进展:BC 在灵巧操作 20、53、54、100、101 方面取得显著进展,并在推动 55 和抓取 14 等相对简单的任务中展现出有效的性能。然而,它在动态环境和长周期任务中的适用性仍然是一个活跃的研究领域。
BC 模型的训练数据通常来自针对特定任务定制的专家演示。因此,当智体在训练期间遇到未见过的状态时,它可能会做出偏离专家行为的动作,导致任务失败。在连续的决策过程中,即使每一步与专家行为的微小偏差也会随着时间的推移而累积,从而导致所谓的"复合误差"问题。这一问题在灵巧操作任务 56, 57 中尤为明显,因为动作空间维数较高,而且任务成功与预测动作轨迹的一致性之间存在很强的依赖关系。为了减轻灵巧操作中的复合误差,Mandlekar 29 提出一个分层框架,该框架将演示轨迹在不同任务的交叉点处进行分段,然后重新组合它们以合成未见过任务的轨迹。同样,Zhao 53 通过考虑与高维视觉观测的兼容性来解决这个问题。他们提出预测整个动作序列而不是逐步预测动作,从而缩短有效决策范围并减轻复合误差。
BC 的另一个挑战是其对多模态数据建模的能力有限,而多模态数据在从现实世界环境中收集的人类演示中很常见。为了克服这一限制,已经提出几种方法来建模多模态动作分布。Florence 26 将 BC 表述为基于条件能量的建模问题,用于捕获多模态数据分布,尽管这会增加计算开销。同样,Shafiullah 58 建议将动作分布建模为高斯混合。他们的方法利用 Transformer 架构有效地利用先前观察的历史,并通过基于 token 的输出实现多模态动作预测。另一个有希望的方向是利用生成模型来捕捉专家行为的内在多样性。Mandlekar 59 建议使用生成模型进行轨迹预测,实现选择性模仿,尽管这种方法依赖于精心策划的针对特定任务的数据集。
最近,扩散模型在增强 BC 方法的鲁棒性和泛化方面表现出巨大潜力。Chen 60 提出一个扩散增强 BC 框架,该框架对专家演示的条件概率分布和联合概率分布进行建模。基于这个想法,Chi 32 使用扩散模型作为决策模型,根据视觉输入和机器人的当前状态直接生成顺序动作。此外,3D 扩散策略 61 利用 3D 输入表示来更好地捕捉场景空间配置。类似地,3D 扩散器 Actor 62 通过 3D Relative Transformer 框架整合 RGB 和深度信息以及语言指令、机器人本体感觉和噪声轨迹,利用完整的 3D 场景表示。
- 讨论:一般来说,基于 BC 的方法在泛化和建模多模态动作分布方面存在困难。为了克服这些限制,扩散模型最近引起了越来越多的关注。它们既可以用作直接生成动作序列的决策模型 32,也可以用作指导动作生成过程的高级策略模型 60。在这两种设置中,扩散模型都表现出良好的性能,并且比传统的 BC 方法具有更好的灵活性。
逆强化学习
- 描述:逆强化学习 (IRL) 颠覆了传统的强化学习框架,后者专注于学习最大化预定义奖励函数的策略。相反,IRL 旨在推断出能够最好地解释一组专家演示的底层奖励函数。
IRL 会估计一个与演示的状态-动作对 D = {τ_1,τ_2,...,τ_N} 最匹配的奖励函数 R(s, a),其中 τ_i = {(s_0,a_0),(s_1,a_1),...,(s_t,a_t)}。假设这些演示是由专家根据最优或接近最优的策略生成的。IRL 问题通常在有限马尔可夫决策过程中表述,定义为 M = ⟨S, A, T, R, γ⟩,其中 S 和 A 分别是状态和动作空间,T(s′ |s, a) 是状态转移概率,R(s, a) 是奖励函数,γ ∈ 0,1 是折扣因子。IRL 通常将奖励函数表示为特征函数的线性组合。
IRL 在灵巧操作场景中尤其具有优势,因为手动定义奖励函数通常具有挑战性或不切实际。IRL 已在各种灵巧操作任务中展现出有效性,包括灵巧抓取、组装以及在动态和不确定环境中的操作。
- 研究进展:近期研究利用 IRL 框架来解决复杂的灵巧操作任务。Orbik 63 首次通过引入奖励归一化、任务特定特征掩码和随机样本生成,推进 IRL 在灵巧操作中的应用。这些技术有效地减轻对已演示动作的奖励偏差,并增强在高维状态-动作空间中的学习稳定性,从而在未见过的场景中实现了更好的泛化。基于在这种高维环境中高效学习的需求,生成因果模仿学习(Generative Causal Imitation Learning) 64 通过将最大熵模型与自适应采样策略相结合,提高了 IRL 的采样效率。该方法通过神经网络利用非线性函数逼近,能够在处理未知系统动态的同时,实现富有表现力的成本函数学习。为了进一步将用户反馈融入学习过程,ErrP-IRL 65 将误差-相关势能 66 与 IRL 相结合。该方法根据用户的认知反应分配轨迹权重,然后利用这些权重迭代地优化以径向基函数和表示的奖励函数。
除了人工反馈之外,近期的研究还探索从大规模非结构化演示中学习奖励函数。GraphIRL 67 从各种视频演示中提取特定于任务的嵌入。通过将目标交互建模为图结构并执行时间对齐,GraphIRL 可以学习可迁移的奖励函数,而无需显式的奖励设计或环境对应,从而实现跨域操作。为了进一步提高策略精度,Naranjo-Campos 68 建议将 IRL 与近端策略优化(PPO) 45 相结合。他们的方法结合基于专家轨迹的特征和反向折扣因子来解决目标状态附近的特征消失问题,从而提高学习策略的鲁棒性。最近,Visual IRL 69 将 IRL 的范围扩展到人机协作任务。它采用对抗性 IRL 从人类演示视频中推断奖励函数,并引入一种神经-符号映射,将人体运动学转化为机器人的关节配置。这种方法不仅确保末端执行器的精确放置,而且还保留类人的运动动力学,从而促进机器人在灵巧操作任务中表现出自然有效的行为。
- 讨论:总之,IRL 在灵巧操作任务中展现出巨大的潜力。通过从专家演示中推断底层奖励函数,IRL 使机器人能够泛化复杂行为并适应不同的环境,而无需手动设计奖励函数。这种能力在奖励规范具有挑战性或不切实际的灵巧操作场景中尤为有价值 70,71。尽管取得这些令人鼓舞的进展,但最先进的 IRL 方法仍然面临一些局限性。主要挑战之一在于准确估计奖励函数,尤其是在高维动作空间或稀疏反馈信号的环境中。此外,IRL 方法通常依赖于大量专家演示数据,由于数据收集所需的高成本和时间,这在实际应用中构成了限制 70,72。
GAIL
1)描述:生成对抗模仿学习 (GAIL) 将生成对抗网络 (GAN) 框架 102 扩展到模仿学习领域。它将模仿过程表述为生成器和鉴别器之间的双人对抗博弈。生成器对应策略 π,旨在生成与专家演示非常相似的行为;而鉴别器 D(s, a) 则评估状态-动作对 (s, a) 是源自专家数据 M 还是由 π 生成。具体而言,GAIL 最小化专家和生成器的状态-动作分布之间的 Jensen-Shannon 散度。通过对抗性训练过程,GAIL 能够有效地从专家演示中学习复杂行为,而无需显式地恢复奖励函数。
-
研究进展:GAIL 已广泛应用于灵巧操作领域。然而,其有效性在很大程度上取决于专家演示的质量和可用性,而这些演示的收集通常需要耗费大量的劳动力,并且容易出现不一致 73,74。这种差异源于收集者偏见 75、专家错误、噪声数据、非凸解空间和次优策略 76 等因素。此外,数据稀缺进一步限制学习效率和策略鲁棒性。为了应对这些挑战,人们提出各种 GAIL 扩展。HGAIL 77 采用后见之明经验回放来合成类似专家的演示,而无需真实的专家数据。AIL-TAC 76 引入一个半监督校正网络来改进嘈杂的演示。GAIL 也已用于模拟-到-现实的迁移 78,减少对现实世界专家数据的依赖。尽管如此,GAIL 仍然存在模式崩溃的问题,即学习的策略只能捕捉到一小部分行为,而且当鉴别器的性能超过生成器时,还会出现梯度消失的问题。为了缓解这些问题,RIDB 79 结合变分自编码器来学习语义策略嵌入,并实现跨行为的平滑插值。WAIL 80 利用 Wasserstein GAN 框架 81 来提高训练稳定性并减少模式崩溃。DIL-SOGM 82 进一步引入一种自组织生成模型,无需编码器即可捕捉多种行为模式。同时,一些研究也提高 GAIL 在不完美演示下的鲁棒性。GA-GAIL 83 使用第二个鉴别器来识别目标状态,从而增强从次优数据中学习策略的能力。RB-GAIL 84 集成排序机制和多个鉴别器,在利用生成经验的同时,对多种行为模式进行建模。除了解决专家演示的质量和可用性问题外,近期研究还致力于在其他方面提升基于 GAIL 的灵巧操作方法的性能。例如,TRAIL 85 引入了约束判别器优化,以防止判别器关注虚假的、与任务无关的特征(例如视觉干扰项),从而保留有意义的奖励信号并提升任务性能。在人类模仿的背景下,Antotsiou 86 将逆运动学和粒子群优化与 GAIL 相结合,以减轻传感器噪声和领域差异,使机器人能够在模拟环境中自主抓取物体。此外,P-GAIL 87 将熵最大化的 deep-P 网络融入 GAIL,以改进可变形体操作任务中的策略学习。
-
讨论:尽管一些扩展已经解决 GAIL 在灵巧操作方面的具体挑战,但它仍然继承对抗训练的基本局限性。特别是,GAIL 经常受到训练不稳定性的影响,并且在扩展到高维动作空间时面临困难。
HIL
- 描述:分层模仿学习 (HIL) 是一种模仿学习框架,旨在通过将复杂任务分解为分层结构来解决这些任务。HIL 通常采用两级结构,其中高级策略负责根据当前状态和任务需求生成一系列子任务或原语,低级策略则执行子任务以实现总体目标。这种分层分解通过将决策和控制分离,能够更有效地处理长期复杂的任务。
从数学上讲,高级策略 π_h 从预定义的一组原语 {p_1,p_2,...,p_K} 中选择一个原语 p_i。然后,相应的低级策略π_p_i 生成执行所选原语的动作。
HIL 的总体目标是最小化累积损失函数 L(π),该函数通过联合优化高层决策和低层控制执行,明确反映策略的层次结构,以实现有效的任务分解和协调。
HIL 中高级和低级策略的参数通常通过三种方法确定:(1)从演示中学习,利用专家演示来训练两个级别的策略;(2)优化,应用强化学习或其他优化方法来完善策略;(3)手动调优,在初始阶段或根据特定任务要求手动调整策略。HIL 的一个关键优势在于,它能够通过将任务分解为层次结构来降低直接动作空间搜索的复杂性。这种分解不仅提高了学习效率,尤其是在长期任务中,而且还通过多层次优化提高了泛化能力和任务成功率。
2)研究进展:近年来,HIL 在机器人技术领域取得显著进展,尤其是在任务分解和技能泛化方面。CompILE 88 通过将任务分解为独立的子任务来增强复杂环境中的泛化能力。这种组合方法为后续研究奠定基础,尤其是在涉及长时间序列的任务方面。在此基础上,Xie 89 将 HIL 应用于双臂操作,并引入 HDR-IL 框架。该框架将任务分解为多个运动基元,并使用图神经网络来建模目标关系。
HIL 也已成功应用于各种灵巧操作任务。Sun 90 提出的 ARCH 框架,提出了一个专为长视界、接触丰富的机器人装配量身定制的框架。它将预定义的低级技能库与高级策略的模仿学习相结合,从而能够高效地组合和调整技能,以处理复杂、高精度的任务。Xu 91 提出的 XSkill 进一步将 HIL 扩展到跨模态技能发现。他们的框架展示了如何通过学习不同模态的技能映射,使机器人能够泛化到不同的环境中。此外,Wan 92 提出 LOTUS 框架,它致力于通过将任务分解为连续的子任务,并支持在不同条件下进行策略调整,来保持动态环境中的技能连续性和稳定性。为了有效地训练高级和低级策略,最近的研究探索了游戏数据的使用。Wang 93 提出 MimicPlay,它利用非结构化的人类游戏交互来指导机器人操作。这种方法从游戏数据中学习高级潜规划,并用它们在少量演示的情况下训练低级视觉运动控制器。同样,Lin 94 提出 H2RIL,它通过从与任务无关的游戏数据中提取交互感知技能嵌入来利用跨域演示。这些嵌入通过时间序列对比学习与人类视频对齐,使系统能够推广到新的可组合任务,并适应分布外的场景。
3)讨论:综上所述,HIL 在任务分解、技能泛化和处理长视域任务方面表现出显著的优势。通过引入层级结构和多级控制策略,各种灵巧操作任务取得显著进展。然而,当前的研究仍面临跨模态技能泛化的自适应性以及模型在动态环境下的鲁棒性和连续性等挑战。尤其是在任务环境发生显著变化时,如何快速调整和优化现有技能库以实现任务的平稳过渡仍是一个亟待解决的问题。
持续模仿学习
- 描述:持续模仿学习 (CIL) 是一种将持续学习与模仿学习相结合的方法,旨在使智体能够通过在动态变化的环境中模仿专家行为来持续获取和适应技能。具体而言,在初始阶段,智体通过专家演示学习基本技能。在后续阶段,智体逐步积累知识,适应新任务或环境,并降低遗忘先前获取技能的风险。
在 CIL 中,策略 π 的优化是通过最小化所有先前遇到任务的累积模仿损失来实现的。
CIL 的核心目标是利用新的演示不断优化策略 π,同时保持在先前学习任务上的表现。这尤其具有挑战性,因为它需要在新技能获取与先前获取技能的熟练程度之间取得平衡。
2)研究进展:CIL 已成为机器人技术领域的一个关键研究方向,其目标是使机器人能够从任务演示中不断习得新技能,同时减轻对先前学习任务的"灾难性遗忘"。为此,人们提出各种专门针对灵巧操作的方法。
CIL 的早期研究侧重于使机器人能够在不损害先前获取技能的情况下在不同任务之间切换,这为后续研究奠定了基础 95。然而,这些方法通常需要大量的存储和计算资源,限制了它们在实际应用中的实用性。为了解决这些限制,研究人员提出了特定任务的适配器结构,引入轻量级适配器来实现无缝任务切换 96。这种方法有效地降低了存储开销,并提高了对新任务的适应性,尽管当任务差异很大时,其性能往往会下降。进一步的进展探索了使用无监督技能发现来增强适应性92。通过动态生成新技能并将其集成到机器人现有的技能组合中,这种方法提高了机器人处理复杂且不断变化的任务的能力。虽然在模拟中已经证明了有希望的结果,但这些技能在现实场景中的有效性和泛化能力仍有待验证。CIL的进一步发展引入一个概念,即通过"行为蒸馏"学习统一的策略97。与早期研究不同,这种方法通过采用单一策略结构来解决多任务学习的挑战,从而无需在引入新任务时使用额外的适配器。然而,设计这种统一策略仍然具有挑战性,尤其是在保持先前学习的任务性能的同时适应新任务方面。与此同时,GAN的出现启发基于CIL的深度生成重放(DGR)98的发展,这使得机器人能够通过生成合成的任务轨迹来不断获取新技能。这种方法减少了存储历史任务数据或重建先前环境的需求,从而有效地降低存储开销。然而,确保生成轨迹的质量和一致性仍然是一个悬而未决的挑战。此外,人们已经探索自监督学习,以提取技能抽象并扩展CIL在复杂控制任务中的适用性99。该方法表明,即使在没有明确的任务演示的情况下,机器人也可以通过自监督不断获得新技能。
3)讨论:综上所述,当前针对灵巧操作的CIL研究主要集中于有效的多任务学习、DGR技术的应用以及自监督的技能抽象。通过这些方法,研究人员解决了持续学习的一些核心挑战,特别是在任务切换和技能整合方面。然而,实际部署仍然存在重大挑战。生成数据的质量和一致性尚未达到最佳水平,这可能会影响决策和任务执行的准确性。此外,尽管一些方法降低存储和计算需求,但在更复杂的场景中,资源消耗仍然是一个限制因素。此外,当前方法的泛化能力,尤其是在处理多样化任务和动态环境方面的能力,对于实际应用来说仍然不足。
末端执行器是位于机器人操作器尖端的组件,可直接与环境交互以执行任务。在灵巧操作中,末端执行器通常分为两指夹持器、多指拟人手和三指机械爪。本节将按顺序介绍这三种类型,重点介绍它们的设计原理、优势和权衡利弊。
两指传统夹持器
两指夹持器因其可靠性、简单性和易于控制而得到广泛应用。它们通常由具有一个自由度 (DoF) 的单个执行器驱动,经济高效,适用于需要一致性的重复性任务 103。例如,104 展示一个配备这种夹持器的 Franka 机器人,它可以执行诸如摆放早餐桌之类的任务。同样,Kim 105 使用两指夹持器进行基于凝视预测的行为克隆,106 中的肌腱驱动变型,展示抓取各种家居物品的能力。
最近的研究通过大规模模仿数据集(例如 MIME 107、RH20T 108、Bridge Data 109 和 Droid 110)进一步扩展夹持器的功能。双臂系统也通过协调两个夹持器来增强操作能力。例如,111 通过双-动作模仿学习实现了剥香蕉。Mobile ALOHA 112 和 UMI 113 演示煮虾、叠布和洗碗等更复杂的任务。
尽管取得了这些进展,但双指夹持器在灵巧操作方面仍然存在根本性的限制,这需要在手内重新配置物体 114。它们结构简单且缺乏内部自由度,限制了抓取后的调整 103。此外,与人手的形态差异阻碍从演示中学习,并无法复制类似人类的手内(in-hand)运动 115。
多指拟人手
为了克服双指夹持器的灵活性限制,具有类人形态的机械手得到广泛的开发。这些拟人手更适合与为人类设计的物体和环境进行交互 116。它们通常可以根据传动机制分为:肌腱(tendon)驱动、连杆驱动、直接驱动和混合系统,这些传动机制从根本上影响了它们的性能特征 117, 118。
- 肌腱驱动方法:肌腱驱动手,使用线缆传动来驱动关节,模仿人类肌腱。这种设计结构紧凑、自由度多、灵活性高,使其成为拟人手开发的常见选择。为了适应高自由度,执行器通常位于前臂的较远处。
代表性示例包括 Utah/MIT 手 129(如图 (l) 所示)、Shadow 灵巧手 130(如图 (a) 所示)和 Awiwi 手 131--134(如图 (b) 所示),它们均采用拮抗(antagonistic)肌腱布线实现仿生运动。具有滚动接触关节的 FLLEX 手 135,136 和 Faive 手 137(如图 (j) 所示)分别展现稳健性和滚球操作能力。其他典型的肌腱驱动手包括 Robonaut R2 手 138、Valkyrie 手 139,140、UB 手 141--143、DEXMART 手 144,145、iCub 手 146 和仿生手 147(如图 © 所示)。虽然远程驱动减轻手部重量,但由于传动路径较长,会带来摩擦和肌腱磨损。为了解决这个问题,一些设计将所有执行器嵌入手掌内部。例如,DEXHand 148、SpaceHand 149、CEA Hand 150 和 OLYMPIC Hand 151,它们优先考虑模块化和紧凑集成。DexHand 021 152、Tesla Optimus Hand 153(如图 (k) 所示)和 PUDU DH11 Hand 154 等商业设计也采用这种方法。

尽管肌腱驱动手在灵活性和拟人化方面具有优势,但它们也面临着摩擦损失 155、156、末端终止 133、157、158、肌腱蠕变和磨损 159--161 等挑战,这些挑战会影响耐用性和可靠性。因此,大多数此类方法仅局限于研究领域,在实际工业应用中的部署有限。
- 连杆驱动方法:连杆驱动手采用刚性机械连杆控制关节运动,具有高精度、可重复性和鲁棒性。与肌腱驱动设计相比,它们通常提供较少的自由度 (DoF),但驱动更简单、更可靠。因此,大多数商用假肢和机械手都采用这种机制。由于空间限制和紧凑性要求,大多数连杆驱动手指由单个电机驱动,主要分为两类:单自由度耦合型和多自由度欠驱动型 162。
在单自由度型中,关节是机械耦合的,因此在屈曲过程中预成形保持不变。典型的设计包括采用逆四杆耦合的 S 形手指 163 和 Liu 164设计的每根手指使用两个四杆机构的人形手。类似的配置出现在 INSPIRE-ROBOTS RH56 122(如上图 (f) 所示)、Bebionic 手 165、166、BrainRobotics 手 167 和 OYMotion OHand 123(见如上图 (g) 所示)等手中。
相比之下,欠驱动手指可以适应接触力,增强抓握适应性。例如,采用 Whiffle 树机构的 Southampton 手 168、采用基于连杆的自适应机构的 LISA 手 169、MORA HAP-2 手 170、AR 手 III 171 以及 Cheng 172 设计的采用多连杆或四连杆自适应机构的假肢手。
虽然大多数设计每个手指使用一个电机,但也有少数设计采用多个执行器来提高灵活性。 ILDA 机械手 117(见如上图 (d) 所示)每根手指采用三个电机,并结合 PSS/PSU 链条和四连杆机构,实现了与人手相当的工作空间和指尖力。类似的高自由度连杆设计出现在 AIDIN ROBOTICS 机械手 173 和 RY-H1 机械手 174 中。
- 直接驱动方法:直接驱动机械手通过将执行器直接连接到关节来消除中间传动。这简化机械结构,同时仍然允许较高的可驱动自由度,类似于肌腱驱动设计。
代表性示例包括具有 19 个自由度的 OCU-Hand 175,其中大多数关节由嵌入式直流电机单独驱动;以及 TWENDY-ONE 机械手 176,它通过关节级电机布置实现 13 个自由度。 KITECH-Hand 177、Allegro Hand 125(如上图 (i) 所示)和 LEAP Hand 178 采用模块化手指设计,将电机直接集成到指骨中。LEAP Hand 还引入了一种通用外展(abduction)-内收(adduction)电机配置,以增强 MCP 关节的灵活性。
虽然直接驱动技术提供较高的控制精度和响应速度,但它也带来一些潜在的缺点,例如质量增加、转动惯量增加以及手指体积增大,这可能会影响精细操作任务的灵活性。这些局限性部分解释为什么大多数直接驱动手采用四指配置。
- 混合传动方案:除了上述传动类型外,许多拟人手还采用混合方案,以整合不同方案的优势。
例如,DLR/HIT 机械手 II 179 和 NAIST 机械手 180 采用模块化手指,结合了电机、皮带、齿轮、肌腱或连杆系统。MCR 机械手系列 181, 182 采用连杆-肌腱混合传动系统,实现了紧凑性和高功能性。Adab Mora 机械手 183、LEAP 机械手 V2(DLA 机械手)184 和 Hu 等人的机械手 118(见上图 (e) 所示)也在手指内集成了多个传动元件,以提高整体性能和适应性。其他混合设计明确区分了不同手指的机构,以满足特定的功能需求。例如,PUT 机械手 124(见上图 (h) 所示)结合了直接驱动的拇指、连杆驱动的食指/中指以及肌腱驱动的无名指/小指。类似地,MPL v2.0 手 185、触觉手 186 和六自由度开源手 187 对拇指采用直接或齿轮驱动,同时对其他手指使用肌腱、连杆或同步带驱动。Owen 188、Ryu 189 和 Ke 190 等开发的手也采用类似的方法,实施了针对拇指的混合策略,以增强对抗性和灵活性。
三指机械爪:一种权衡方案
拟人手设计的多样性,很大程度上源于机械简单性和灵巧性之间的根本权衡191。虽然人手拥有超过20个自由度192--198,但以机械方式复制这种复杂性仍然不切实际。更高的灵活性通常会增加结构和控制的复杂性、成本以及故障敏感性199--201,从而限制高自由度机械手在实际应用中的可行性202,203。
为了缓解这些问题,人们采用几种简化策略:使用弹性部件进行欠驱动 127、130、168、169、200、201;减少不必要的自由度或指骨(phalange) 122、123、127、165;甚至完全省略一根手指 125、129、139、148、176、178。这些方法凸显在实际约束条件下实现功能最大化的挑战。
作为简约的两指夹持器和复杂的多指拟人手之间的折衷方案,三指机械爪提供一种功能上的中间地带。虽然从解剖学角度来看并不像人类,但三根手指足以执行常见的抓握类型,例如圆柱形和球形动力抓握 199,并且可以支持一部分手内操作任务。
许多三指爪展现出了令人印象深刻的能力。例如,Shadow 的 DEX-EE 204(见图 (a))和 TRX Hand 207 表现出很高的鲁棒性和灵活性。BarrettHand 208(见图 (b))通过欠驱动实现自适应抓取。肌腱驱动的设计,如 i-HY Hand 199(见图 ©)和 Model O 209,可以实现诸如旋转和精确过渡等动作。DClaw 210 和 TriFinger 211 等系统能够通过强化学习执行精细操作任务。其他新架构包括基于连杆的 212、电机多路复用 213 和链带集成的爪 214,每种架构都具有不同的特性。
DoraHand 203(见图 (d))、SARAH 215、D'Manus 216 和 Kinova Jaco 爪 217 等三指爪,进一步证明了这种设计选择在研究和辅助应用方面的实用性和多功能性。
