Qwen-VL 是阿里云研发的大规模视觉语言模型(Large Vision Language Model, LVLM)。Qwen-VL 可以以图像、文本、检测框作为输入,并以文本和检测框作为输出。Qwen-VL 系列模型性能强大,具备多语言对话、多图交错对话等能力,并支持中文开放域定位和细粒度图像识别与理解。
安装方法
pip install git+https://github.com/huggingface/transformers accelerate
pip install qwen-vl-utils[decord]模型硬件要求:
| Precision | Qwen2.5-VL-3B | Qwen2.5-VL-7B | Qwen2.5-VL-72B |
|---|---|---|---|
| FP32 | 11.5 GB | 26.34 GB | 266.21 GB |
| BF16 | 5.75 GB | 13.17 GB | 133.11 GB |
| INT8 | 2.87 GB | 6.59 GB | 66.5 GB |
| INT4 | 1.44 GB | 3.29 GB | 33.28 GB |
模型特性
- 强大的文档解析能力:将文本识别升级为全文档解析,擅长处理多场景、多语言以及包含各种内置元素(手写文字、表格、图表、化学公式和乐谱)的文档。
- 精准的对象定位跨格式支持:提升了检测、指向和计数对象的准确性,支持绝对坐标和JSON格式,以实现高级空间推理。
- 超长视频理解和细粒度视频定位:将原生动态分辨率扩展到时间维度,增强对时长数小时的视频的理解能力,同时能够在秒级提取事件片段。
- 增强的计算机和移动设备代理功能:借助先进的定位、推理和决策能力,为模型赋予智能手机和计算机上更出色的代理功能。
使用案例
基础图文问答
python
from transformers import Qwen2_5_VLForConditionalGeneration, AutoProcessor
from qwen_vl_utils import process_vision_info
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-VL-7B-Instruct", torch_dtype="auto", device_map="auto"
)
# 传入文本、图像或视频
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "Describe this image."},
],
}
]
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to(model.device)
# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)多图输入
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": "file:///path/to/image1.jpg"},
{"type": "image", "image": "file:///path/to/image2.jpg"},
{"type": "text", "text": "Identify the similarities between these images."},
],
}
]视频理解
-
Messages containing a images list as a video and a text query
messages = [
{
"role": "user",
"content": [
{
"type": "video",
"video": [
"file:///path/to/frame1.jpg",
"file:///path/to/frame2.jpg",
"file:///path/to/frame3.jpg",
"file:///path/to/frame4.jpg",
],
},
{"type": "text", "text": "Describe this video."},
],
}
] -
Messages containing a local video path and a text query
messages = [
{
"role": "user",
"content": [
{
"type": "video",
"video": "file:///path/to/video1.mp4",
"max_pixels": 360 * 420,
"fps": 1.0,
},
{"type": "text", "text": "Describe this video."},
],
}
] -
Messages containing a video url and a text query
messages = [
{
"role": "user",
"content": [
{
"type": "video",
"video": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-VL/space_woaudio.mp4",
"min_pixels": 4 * 28 * 28,
"max_pixels": 256 * 28 * 28,
"total_pixels": 20480 * 28 * 28,
},
{"type": "text", "text": "Describe this video."},
],
}
]
物体检测
- 定位最右上角的棕色蛋糕,以JSON格式输出其bbox坐标

- 请以JSON格式输出图中所有物体bbox的坐标以及它们的名字,然后基于检测结果回答以下问题:图中物体的数目是多少?

图文解析OCR
- 请识别出图中所有的文字
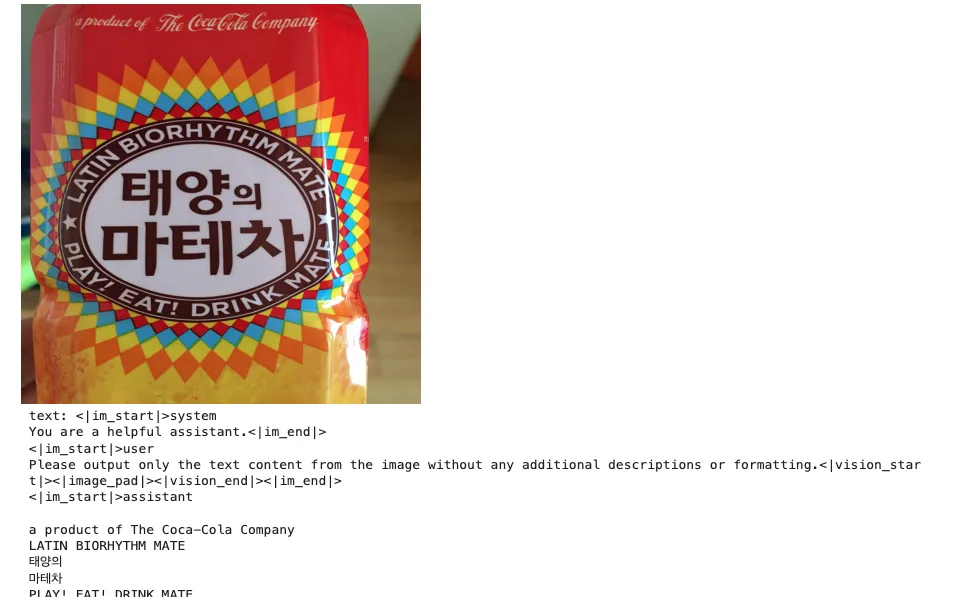
- Spotting all the text in the image with line-level, and output in JSON format.

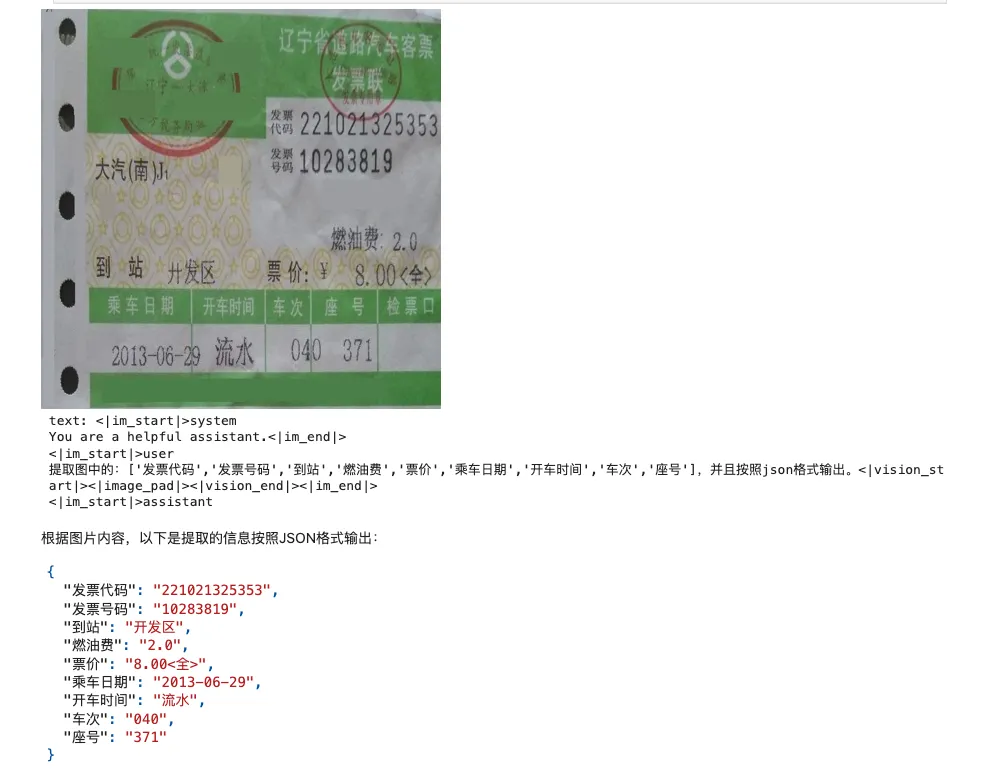
- 提取图中的:'发票代码','发票号码','到站','燃油费','票价','乘车日期','开车时间','车次','座号',并且按照json格式输出。
Agent & Computer Use
The user query:在盒马中,打开购物车,结算(到付款页面即可) (You have done the following operation on the current device):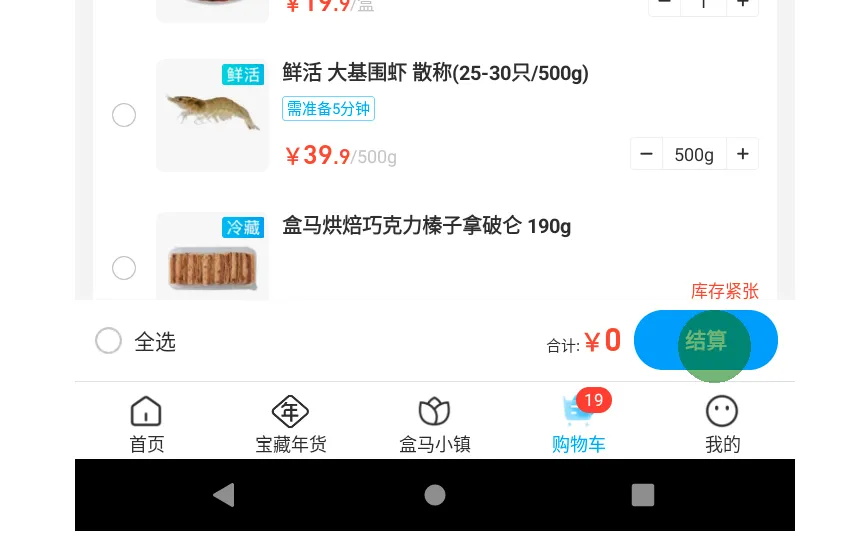
编辑推荐
系统地介绍大语言模型的提示词工程以及AI Agent的基本概念和设计方法论。许多用户在使用ChatGPT等AI工具时,常常感到困惑:为什么有时候能得到满意的回答,有时候却答非所问?通过本书,读者将学习如何构建有效的AI提示词,以及如何设计合理的对话流程,从而更好地驾驭AI工具。