一、导读
当前的多模态大语言模型虽然在图像和视频理解方面取得了进展,但大多仍停留在"看图说话"的层面,缺乏对视频背后三维空间结构和动态变化的深层理解。这类模型往往把视频当作一系列孤立的帧来处理,忽略了视频作为连续、高带宽的视觉流所蕴含的时空信息,导致在长视频、多场景、持续感知任务中表现不佳。
为了解决这一问题,本文提出了Cambrian-S模型框架 ,通过引入预测性感知机制 和构建大规模空间感知数据集VSI-590K ,显著提升了模型在空间推理任务上的表现。实验表明,该模型在多个空间理解基准上取得了显著进步,并在新提出的VSI-Super评测集上展现出优于现有商业模型的能力。
原、文指路👉更多大模型前沿资讯+资料![]() https://mp.weixin.qq.com/s/s5MQK4awaQ6S0dKRdB6dLg
https://mp.weixin.qq.com/s/s5MQK4awaQ6S0dKRdB6dLg
二、论文基本信息

三、主要贡献与创新
-
提出空间超感知(Spatial Supersensing) 的概念层次,将视频理解分为语义感知、流式事件认知、隐式3D空间认知和预测性世界建模四个阶段。
-
构建了VSI-Super评测集,包含长时空间回忆(VSR)和持续计数(VSC)任务,挑战现有模型的长期记忆与推理能力。
-
发布了VSI-590K数据集,包含59万条空间感知指令微调样本,涵盖真实视频、仿真数据和伪标注图像。
-
提出了预测性感知(Predictive Sensing) 机制,通过下一帧潜在特征预测与"惊喜"信号驱动记忆管理与事件分割。
-
训练了Cambrian-S系列模型,在多个空间理解基准上取得显著提升,并在VSI-Super任务上优于Gemini-2.5等商业模型。
四、研究方法与原理
本文提出了一种预测性感知机制,通过让模型学习预测下一帧的潜在特征,并利用预测误差(即"惊喜")来指导记忆管理和事件分割,从而实现对长视频的持续理解。
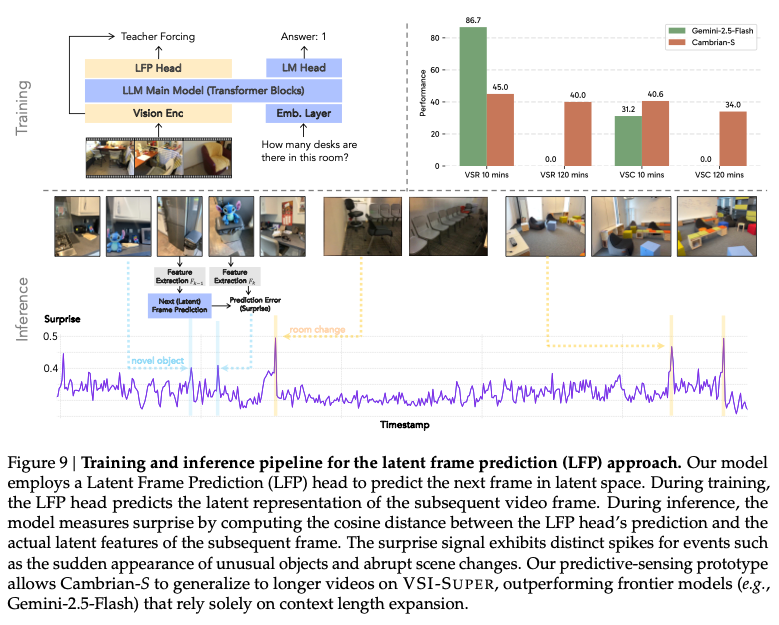
图9:潜在帧预测(LFP)训练与推理流程
-
潜在帧预测头(LFP Head) :
在模型的语言头旁并行引入一个两层的多层感知机(MLP),用于预测下一帧的潜在特征。其结构为:
LFPHead = Sequential( Linear(3584 → 3584), GELU(), Linear(3584 → 1152) )输出维度与视觉编码器(SigLIP2-So400M)保持一致。
-
损失函数 :
除了指令微调的语言损失外,引入两个辅助损失:均方误差(MSE)和余弦距离,用于衡量预测特征与真实特征之间的差异:
其中 是平衡系数,默认设为0.1。
-
惊喜驱动的记忆管理 :
在推理过程中,模型根据预测误差(余弦距离)判断每一帧的"惊喜"程度。低惊喜帧被压缩存储,高惊喜帧保留原样。当长期记忆超出预算时,系统会丢弃或合并最不惊喜的帧,以维持稳定的内存使用。
-
事件分割机制 :
在VSC任务中,模型将连续视频流按"惊喜"帧切分为多个事件段,每段独立计数后汇总结果,模拟人类分段处理复杂任务的方式。
五、实验设计与结果分析
5.1 基准评测分析(对应图2与表1)
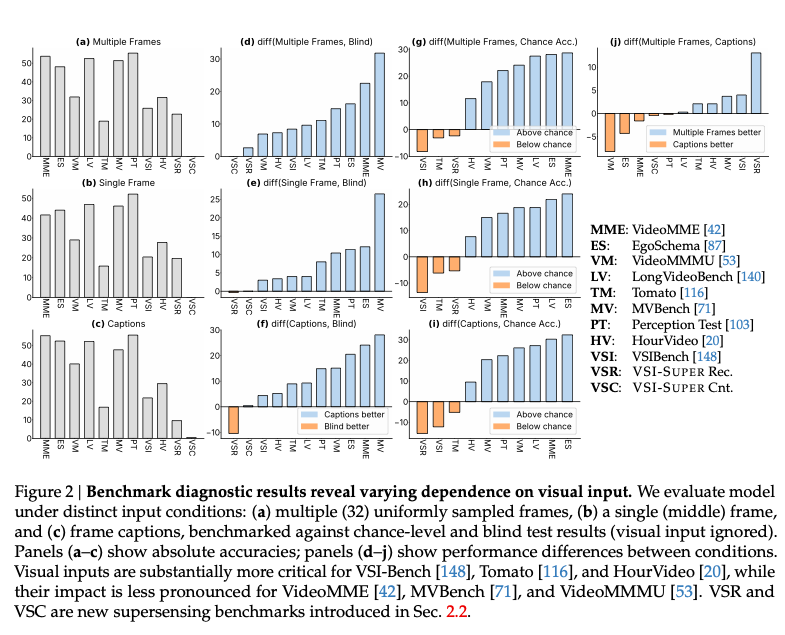

-
数据集:VideoMME、EgoSchema、VideoMMMU、VSI-Bench、VSI-Super等。
-
评测指标:准确率(Accuracy)、平均相对准确率(MRA)。
-
对比实验:

- 表1显示,Gemini-2.5-Flash在传统视频理解任务上表现优异(如VideoMME达81.5%),但在VSI-Super任务上表现不佳(VSR仅41.5%,VSC仅10.9%)。
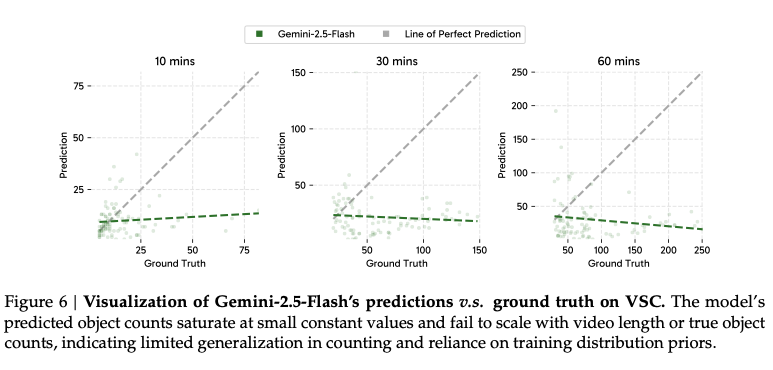
- 图6进一步揭示,Gemini在VSC任务中预测的物体数量不随视频长度增长,表明其缺乏真正的计数泛化能力。
5.2 Cambrian-S性能分析(对应表5、6、7)
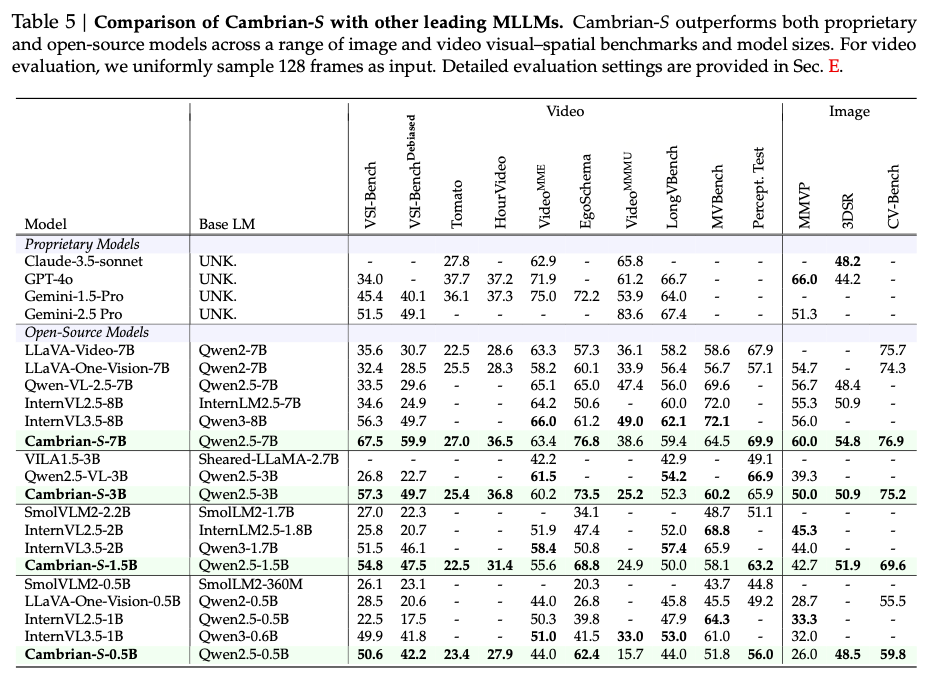
- 表5显示,Cambrian-S-7B在VSI-Bench上达到67.5%,显著超过所有开源模型和Gemini-2.5-Pro(51.5%)。
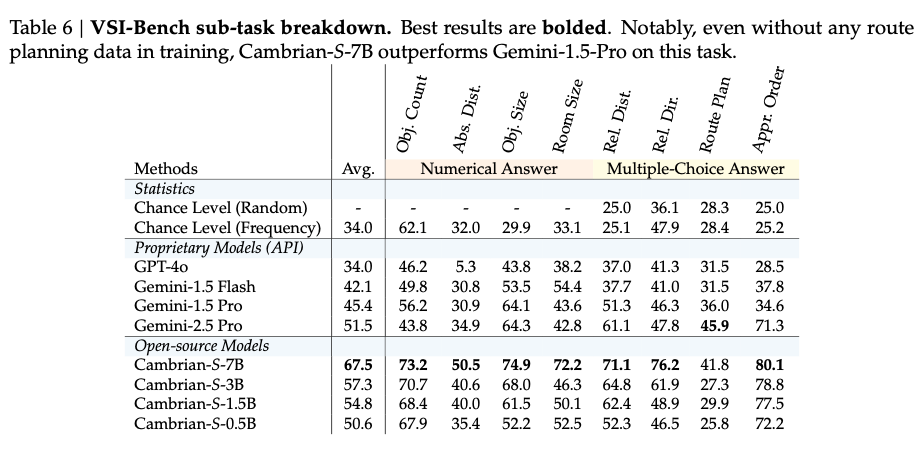
- 表6进一步分析各子任务表现,即使在未训练过的"路径规划"任务上,Cambrian-S-7B仍优于Gemini-1.5-Pro。

- 表7显示,Cambrian-S在VSI-Super任务中表现随视频长度增加而下降,尤其在60分钟以上视频中几乎失效,说明当前模型在持续感知方面仍有局限。
5.3 消融实验(对应表3、4、10)
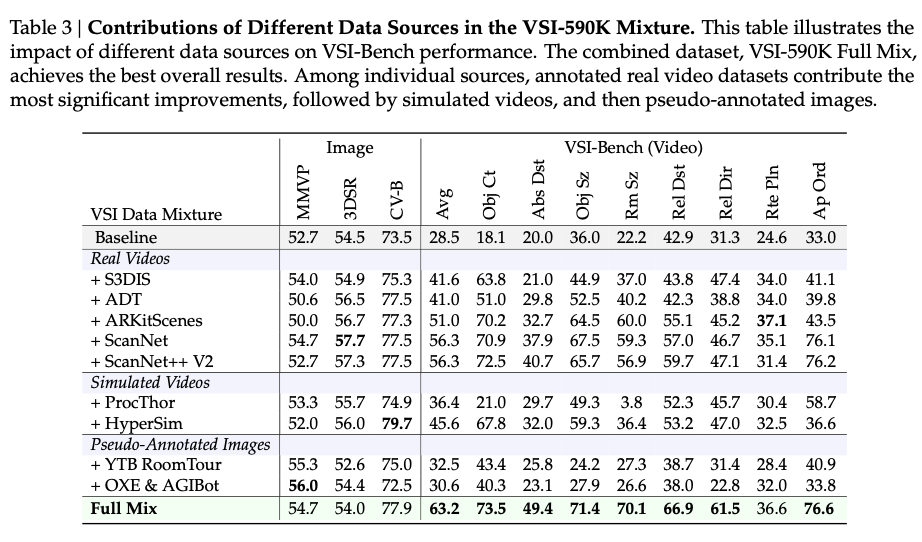
- 表3验证了VSI-590K中各数据源的有效性:真实标注视频 > 仿真数据 > 伪标注图像。
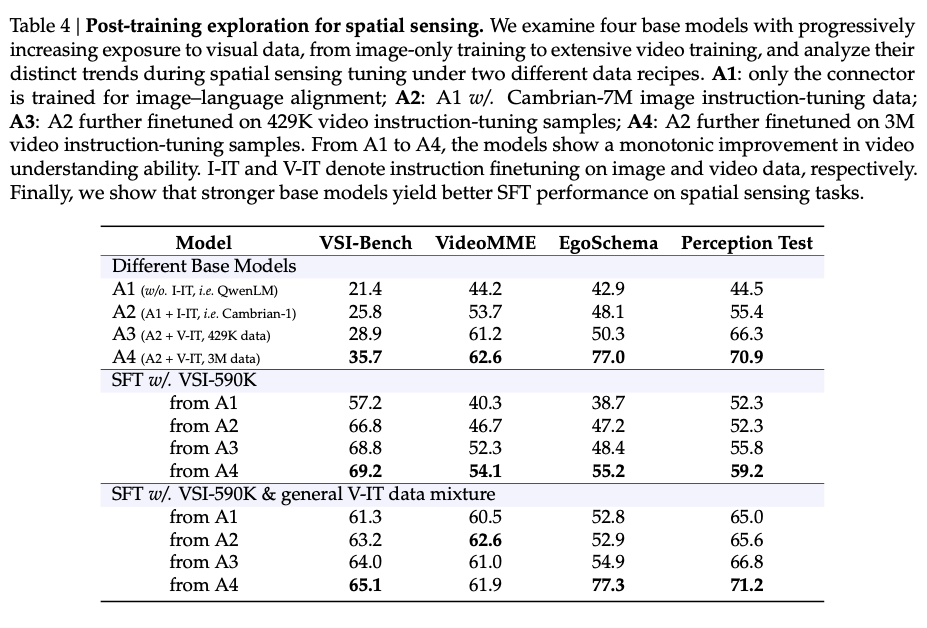
- 表4显示,更强的基模型(如A4)在空间感知任务上表现更优,且混合通用视频数据可缓解领域过拟合。
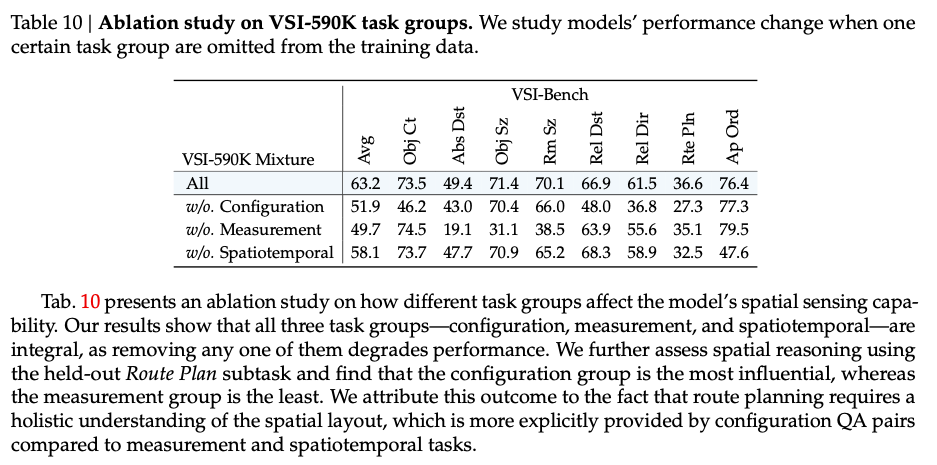
- 表10表明,配置类(Configuration)任务对空间推理能力贡献最大,测量类(Measurement)任务影响较小。
六、论文结论与评价
总结
本文系统性地提出了空间超感知 的概念,并构建了相应的评测集、数据集与模型框架。实验表明,Cambrian-S模型 在传统空间理解任务上表现优异,但在长视频持续感知任务中仍存在明显瓶颈。通过引入预测性感知机制,模型在VSI-Super任务上取得了显著提升,证明了"预测-惊喜"机制在视频理解中的潜力。
评价
该研究为多模态模型从"被动感知"向"主动建模"转变提供了重要思路,尤其在长视频理解、机器人导航、虚拟现实等场景中具有应用前景。然而,当前方法仍依赖大量标注数据,且预测模块较为简单,未来需进一步探索更强大的世界模型与更高效的记忆机制。此外,VSI-Super任务的构建虽具挑战性,但其合成性质可能限制了其在真实场景中的泛化能力。建议后续研究引入更多真实长视频数据,并探索模型在开放环境中的自适应能力。
原、文指路👉更多大模型前沿资讯+资料![]() https://mp.weixin.qq.com/s/s5MQK4awaQ6S0dKRdB6dLg
https://mp.weixin.qq.com/s/s5MQK4awaQ6S0dKRdB6dLg
往期推荐
强烈推荐!多模态融合顶会新成果!CVPR/AAAI 高分成果,这波思路必须学!
OCR "去幻觉" 新纪元!通义点金 OCR-R1 搞定模糊盖章+跨页表格,攻克 OCR 三大痛点!
NeurIPS'2025高分入选!扩散模型+Transformer,效率与质量双线飙升!
杀疯了!2025 最新Agent Memory顶会论文,拿捏发文密码!
ICCV 2025|FrDiff:频域魔法+扩散模型暴力去雾,无监督性能刷爆榜单!
NeurIPS 2025 | 港科大&上交大HoloV:多模态大模型"瘦身"新突破,剪枝88.9%视觉Token,性能几乎无损
太牛了!北大:Unified-GRPO让理解生成正反馈,超 GPT-4o-Image