
| 算法 | 相关知识点 | 可以通过点击 | 以下链接进行学习 | 一起加油! |
|---|---|---|---|---|
| 双指针 |
在本篇文章中,我们将深入剖析滑动窗口算法的核心原理。从基础概念到实战应用,带你了解如何利用滑动窗口高效解决连续子数组和子串等问题。无论你是算法入门的新手,还是希望提升代码效率的高手,滑动窗口都将成为你优化算法的重要武器!


🌈个人主页:是店小二呀
🌈Linux专栏: Linux
🌈算法专栏:算法
🌈Mysql专栏:Mysql
🌈你可知:无人扶我青云志 我自踏雪至山巅
文章目录
-
- 209.长度最小的子数组
- 3.无重复字符的最长子串
- [1004.最大连续1的个数 |||](#1004.最大连续1的个数 |||)
- [1658.将 x 减到0的最小操作数](#1658.将 x 减到0的最小操作数)
- 904.水果成篮
- [438. 找到字符串中所有字母异位词](#438. 找到字符串中所有字母异位词)
- [30. 串联所有单词的子串](#30. 串联所有单词的子串)
- 76.最小覆盖子串
209.长度最小的子数组
【题目 】:209.长度最小的子数组
cpp
输入:target = 7, nums = [2,3,1,2,4,3]
输出:2
解释:子数组 [4,3] 是该条件下的长度最小的子数组【算法思路】
首先,我们需要明确,子数组和子字符串都指的是数组中一段连续的部分,而子序列则不具有连续性。
1.解法一:暴力枚举
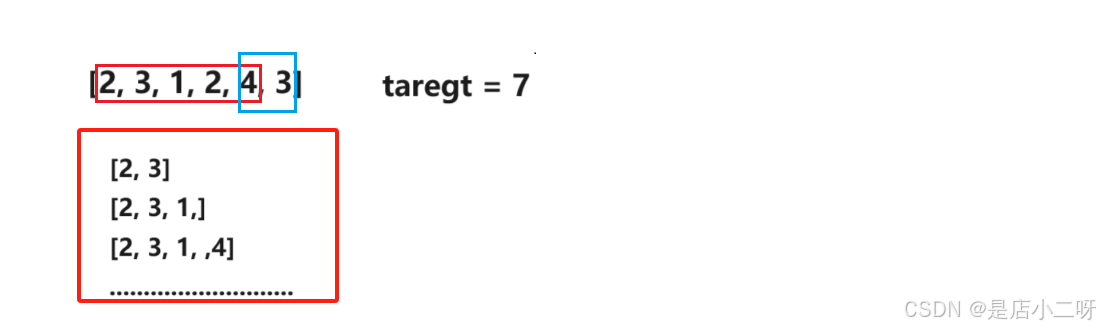
通过两层循环枚举所有可能的情况,再通过一层循环求和进行判断,初步的时间复杂度为O(N^3)。
【优化方案】
1.为了优化,可以引入一个变量 sum 来记录当前的和,从而将时间复杂度优化到O(N^2)。
2.在暴力解法的思路大致明确后,不要急于编写代码。可以先通过模拟过程发现规律,然后逐步进行优化。

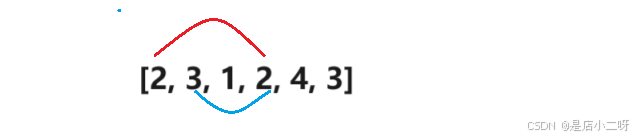
第一个优化点 :利用加法的性质,加入一个正数总是会增大结果。题目要求的是最小的序列,当sum >= target时,right继续向右移动没有意义,这部分属于无效枚举。
第二个优化点 :每当统计出满足条件的子序列后,left++后,right不需要回到left位置。根据加法性质,减少范围时,总和必然会减少,因此无需回到left,这可以进一步优化算法。
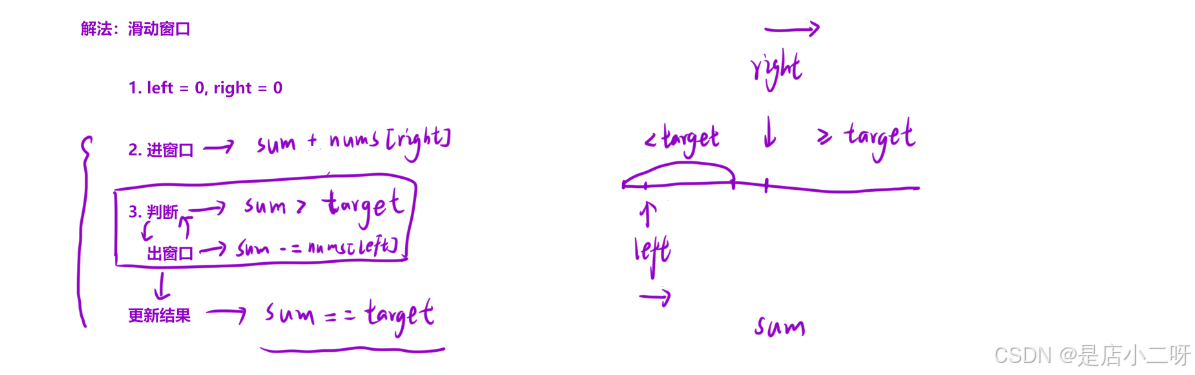
2.解法二:同向双指针
同向双指针实际上就是滑动窗口,通过两个指针维护一个区间的数值,类似一个窗口。当我们利用单调性时,可以有效地使用滑动窗口技术。
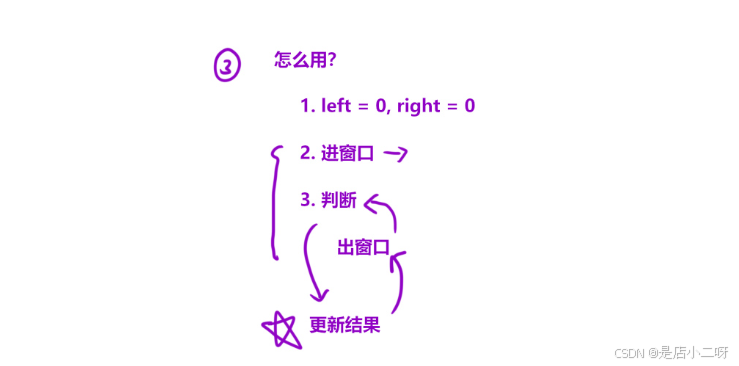
从[判断 -> 更新结果 -> 出窗口 -> 判断],形成一个闭环,因此需要使用循环语句。同时,更新结果的位置是根据题目需求确定的,并非判断完后立刻更新。
【代码实现】
cpp
class Solution
{
public:
int minSubArrayLen(int target, vector<int>& nums)
{
int n =nums.size();
int len =INT_MAX;
int sum = 0;
//进窗口
for(int left = 0, right =0; right < n; right++)
{
//插入数据
sum += nums[right];
//判断
while(sum >= target )
{
//更新
len = min(len, right - left + 1);
sum -= nums[left++];
}
}
return len == INT_MAX ? 0 : len;
}
};【个人思考】
到 sum >= target。没有必要继续right++,而是改变left位置不断进行判断,这里在双指针算法篇章有所说明,用于规避没有必要的枚举行为。
滑动窗口的正确性:利用单调性,规避了很多没有必要的枚举行为。
虽然代码使用两层循环,但是时间复杂度优化为O(N),时间复杂度主要是看思想。这里就left和right滑动。N + N = 2N ~ N .
3.无重复字符的最长子串
【题目 】:3.无重复字符的最长子串

cpp
输入: s = "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
输入: s = "bbbbb"
输出: 1
解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。 【算法思路】
首先流程还是配合示例分析题目,尝试得到暴力解法的逻辑(这里一般为暴力枚举),模拟实现过程,得到规律,在此规律上进行优化,得知采用某一种算法
1.解法一:暴力枚举配合哈希表
暴力枚举和哈希表的时间复杂度:O(N²)

我们根据题目需求模拟实现流程,取一部分区间进行观察(pww)。从p出发向右枚举可能的情况,直到遇到pw时结束,然后将起点右移,而不是继续枚举。由于我们从全知视角进行观察,继续枚举pww不符合题目要求,因此选择停止。为了判断字符是否重复出现,我们使用哈希表。
2.解法二:滑动窗口
比起如何实现逻辑,更重要的是如何知道为什么需要使用滑动窗口思想,不然就是巧妇难为无米之炊。
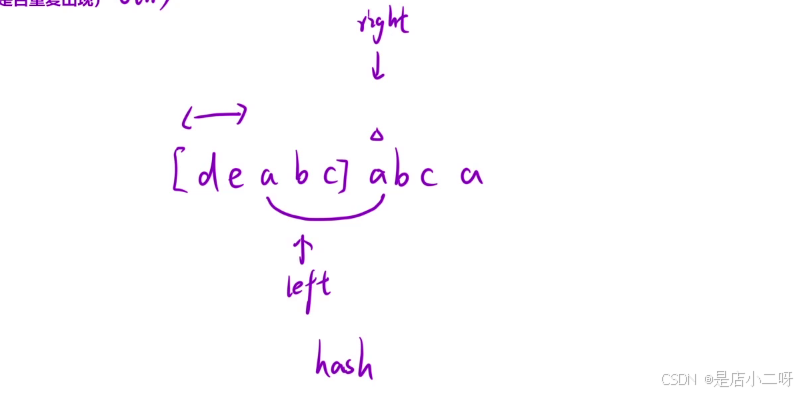
从图中可以看到,right指向元素a,导致哈希表中下标为a的元素值为2,出现了重复情况。此时需要移动left指针,重新计算子串长度,但left应该移动到哪里呢?
很明显,right停下是因为遇到了重复字符。如果没有重复字符,right就可以继续向右移动。因此,left需要跳过重复字符,之后right才能继续向右扩展,重新计算长度。
问题在于,left应该跳到什么位置?由于right停下是因为遇到重复字符,left应该跳过重复字符,否则无论left移动到哪里,在[left, right]区间内,right都不会再前进,因为该区间内仍然有重复字符。完成这一步后,right不需要回到left位置,继续向右移动即可。
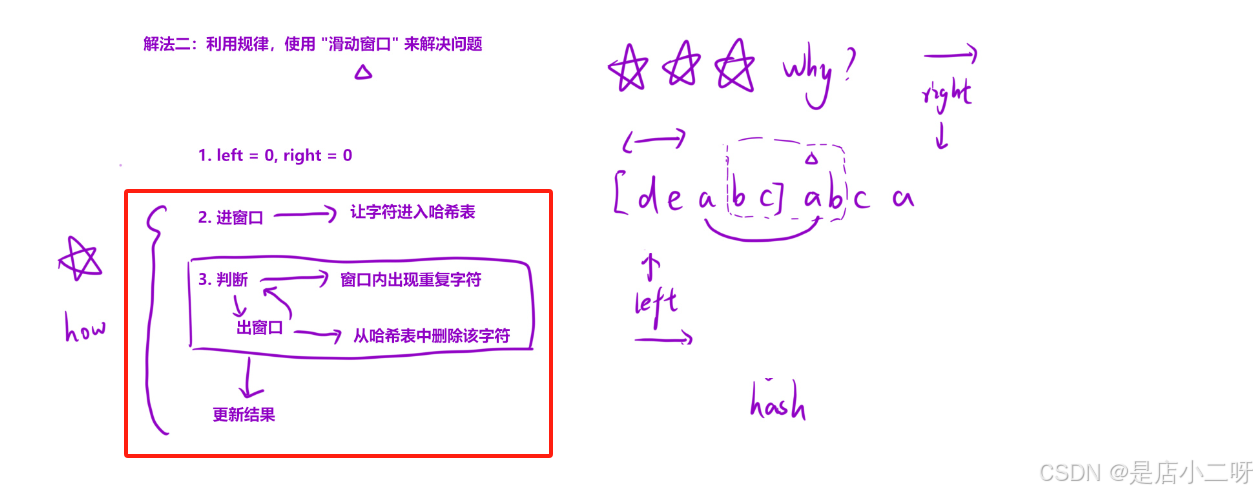
判断条件就是hash是否出现重复字符,如果出现重复需要不断移除字符次数和移动left位置,直到left达到重复字符的下一个位置。
【代码实现】
cpp
class Solution
{
public:
int lengthOfLongestSubstring(string s)
{
int hash[128]={0};
int n = s.length();
int ret = 0;
for(int left = 0, right = 0; right < n; right++)
{
hash[s[right]]++;
while(hash[s[right]] > 1)
hash[s[left++]]--;
ret = max(ret, right - left + 1);
}
return ret;
}
};1004.最大连续1的个数 |||
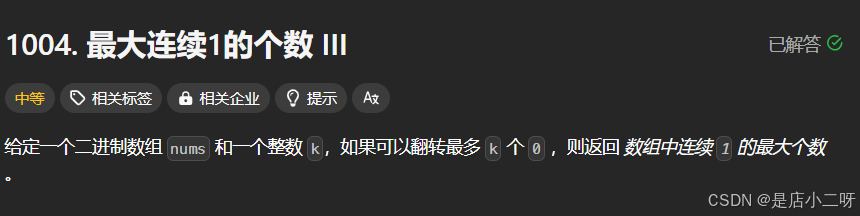
【题目 】: 1004. 最大连续1的个数 III
cpp
输入:nums = [1,1,1,0,0,0,1,1,1,1,0], K = 2
输出:6
解释:[1,1,1,0,0,1,1,1,1,1,1]
粗体数字从 0 翻转到 1,最长的子数组长度为 6。【算法思路】
首先,通过示例分析题目的含义。简单来说,这道题目要求找到最长的子数组,通常我们会使用滑动窗口的方法。但为了更好地理解,我们可以先从暴力解法入手,通过模拟实现过程发现其中的规律,然后再对其进行优化,形成更高效的算法思路。
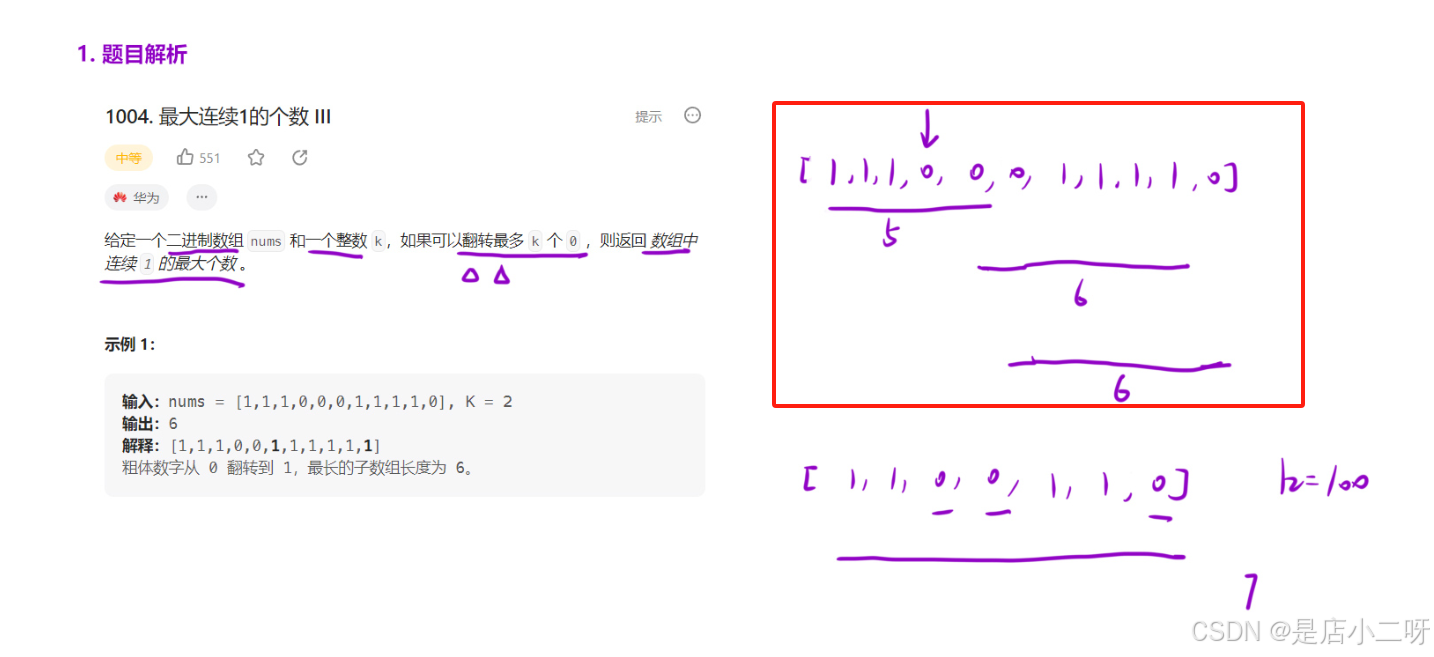
通过分析,'最多翻转k个零'的意思是对于数值为零的部分,我们最多可以翻转0, k个零,而目标是将所有零都翻转成一的状态。同时,我们需要返回连续1的最大个数,即找到最长的连续1子数组。从红色部分可以看到,当零的个数超过k时,翻转就会停止。这道题与上一道题非常相似,因此我们可以引入一个变量count来统计当前子数组中零的个数,以便满足题目的要求。
1.解法一:暴力枚举 + zero计数器
如果使用暴力枚举法来处理所有情况,针对每个零进行翻转操作,最后还需要再将其翻转回去,这种做法既繁琐又容易出错。此时,我们应该思考,既然翻转不能超过k个零,是否真的需要执行复杂的翻转操作呢?
可以将问题转化为:寻找一个最长的子数组,其中零的个数不超过k个。
2.解法二:滑动窗口
当我们得到了暴力解法的逻辑,现在需要模拟实现发现规律,进行优化。
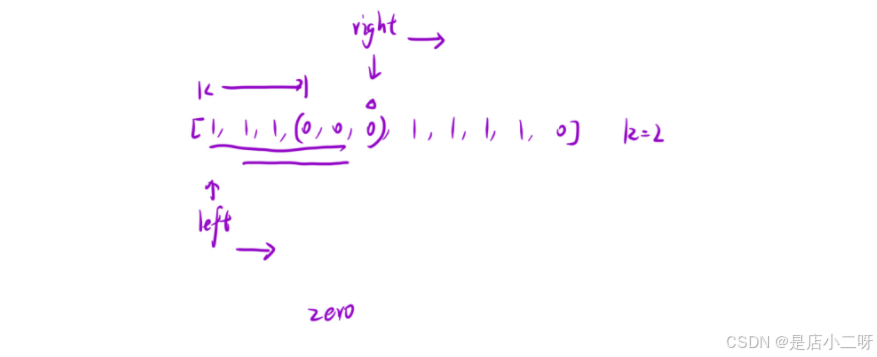
首先,当right指针停下时,left需要移动到下一个1的位置,这样right就无法继续移动了。这种情况的发生是由于count > 2,因此需要调整left指针的位置,直到count <= 2为止。通过这种方式,能够确保right继续向前推进,同时维护零的个数不超过2。
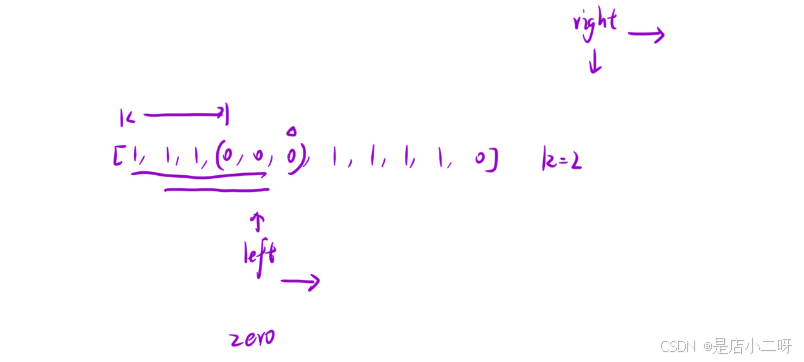
其次,当left移动到合适的位置后,right不需要重新回到left的位置重新移动,因为[left, right]已经是一个合法的区间。
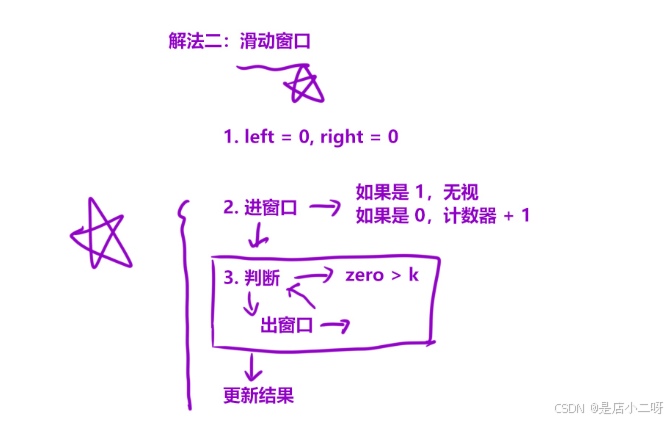
【代码实现】
CPP
class Solution {
public:
int longestOnes(vector<int>& nums, int k)
{
int n = nums.size();
int count = 0;
int len = 0;
for(int left = 0, right = 0; right < n; right++)
{
if(nums[right] == 0) count++;
while(count > k)
{
if(nums[left++] == 0) count--;
}
len = max(len, right - left + 1);
}
return len;
}
};1658.将 x 减到0的最小操作数
【题目 】:1658. 将 x 减到 0 的最小操作数
cpp
输入:nums = [1,1,4,2,3], x = 5
输出:2
解释:最佳解决方案是移除后两个元素,将 x 减到 0 【算法思路】
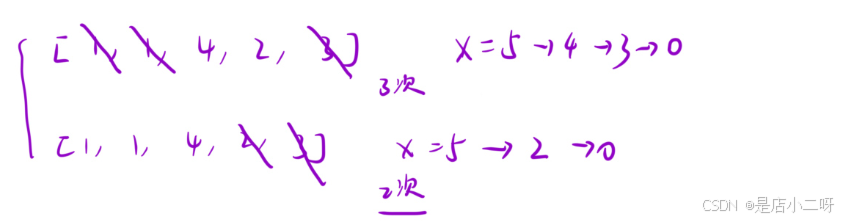
【难点分析】
在这个问题中,我们很难直接控制需要移除的数组nums最左边或最右边的元素数量。
为了解决这个问题,可以通过两个指针来控制左右两边的情况。例如,我们可以固定左边的数据,让右边的数据向右移动,并且逐步减去相应的数字。根据不同的情况进行处理,但不同的情况非常多,操作复杂且效率不高。
【正难则反】
考虑到题目提示中提到最小操作数与长度有关,可以尝试使用滑动窗口的思想。
实际上,我们可以将问题转化为:找出一个最长的子数组,其元素和正好等于 sum
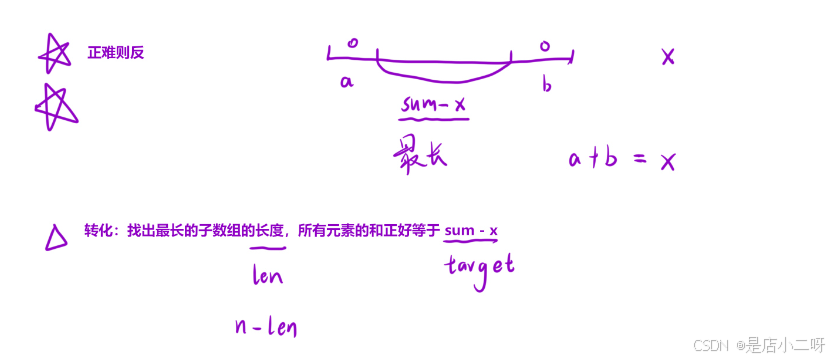
跟第一道题是类似的,我就不细说了,主要注意的是最后是求最小长度,需要数组总长度 - 中间部分最长的长度。
【代码实现】
cpp
class Solution {
public:
int minOperations(vector<int>& nums, int x){
int len = nums.size();
int sum = 0;
for(int a : nums) sum += a;
int target = sum - x; int ret = -1;
if(target < 0) return -1;
for(int left = 0, right = 0, tmp = 0; right < len; right++)
{
tmp += nums[right];//进窗口
while(tmp > target)
{
tmp -= nums[left++];
}
if(target == tmp) ret = max(ret, right - left + 1);
}
if(ret == -1) return ret;
else return len - ret;
}904.水果成篮
【题目 】:904. 水果成篮
CPP
输入:fruits = [0,1,2,2]
输出:3
解释:可以采摘 [1,2,2] 这三棵树。
如果从第一棵树开始采摘,则只能采摘 [0,1] 这两棵树。【算法思路】
这道题目较长,读完后可以总结为:找出一个最长的子数组,且该子数组中不超过两种类型的水果。题目要求返回可以收集的水果的最大数量。一般情况下,可以考虑使用滑动窗口算法来解决,但并非所有情况都适用,因此仍然需要通过暴力解法来找到最优的解决方案。
1.解法一:暴力枚举 + 哈希表
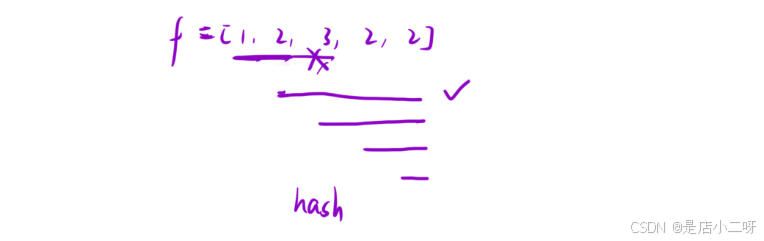
根据题目要求,当遇到不同类型的水果需要停下来,但是我们这里是通过肉眼很容易观察到,对此我们需要一个哈希表hash<int, int>来统计次数和类型。
2.解法二:滑动窗口
在暴力枚举过程中,left不断向右移动来更新起点,等待枚举操作,而right则从left的位置开始向右移动。但当right停下时,原因是水果种类超过了2种。这时,right如果重新回到left位置,水果种类不会变得更多,因此不需要再回到left位置。
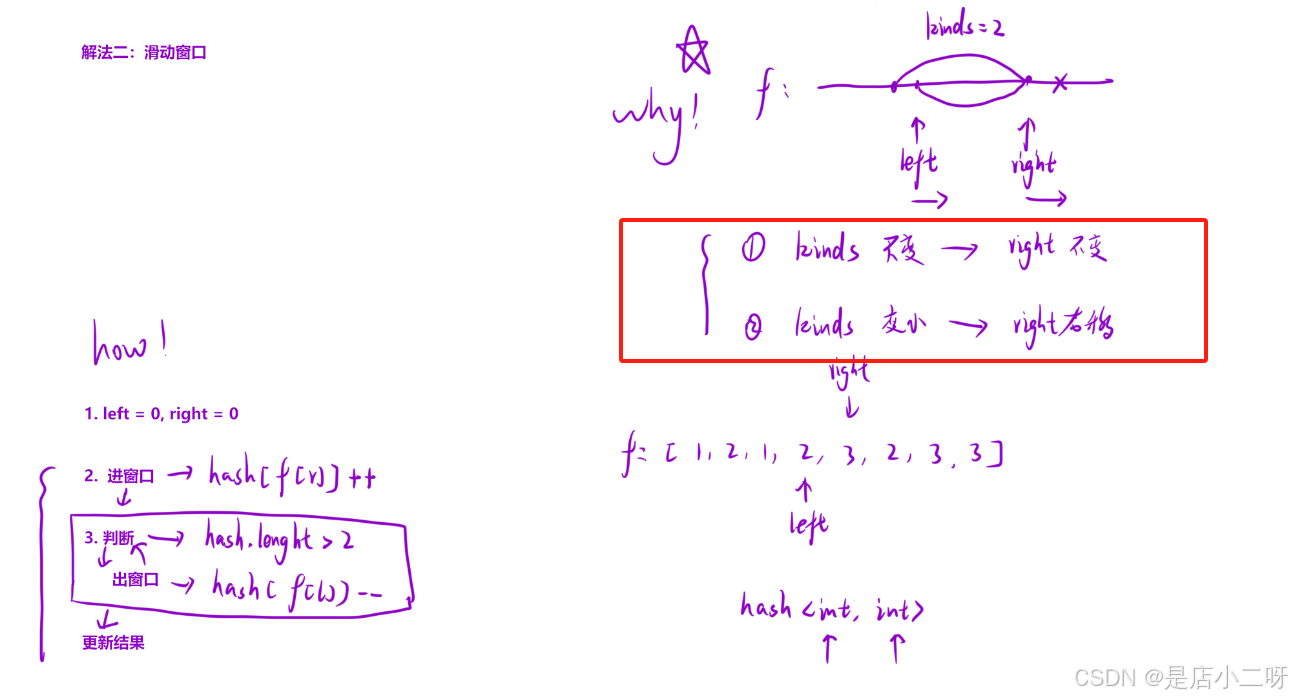
当水果种类超过2时,left需要向右移动,同时哈希表也需要同步更新,删除该水果的出现次数。当某种水果的出现次数为零时,应该从哈希表中删除该水果种类(这需要判断该水果的出现次数是否为零,才能决定是否删除)。问题的关键在于如何处理这种水果种类,并且它在循环中的作用是什么。
在这里,我们不使用hash容器,因为数据范围是有限的。通过使用一个定长数组来代替哈希表,可以提高效率。
【代码实现】
cpp
class Solution {
public:
int totalFruit(vector<int>& f)
{
int n = f.size();
int hash[100001] = {0};
int len = 0, kinds = 0;
for(int left = 0, right = 0; right < n; right++)
{
if(hash[f[right]] == 0) kinds++;
hash[f[right]]++;
while(kinds > 2)
{
hash[f[left]]--;
if(hash[f[left]] == 0) kinds--;
left++;
}
len = max(len, right - left + 1);
}
if(kinds == 1) return n;
else return len;
}
};438. 找到字符串中所有字母异位词
【题目 】:438. 找到字符串中所有字母异位词
解法一:暴力解法 + 哈希表
由题意可得,字母顺序不影响结果,那么可以将两边字符排序,再通过双指针遍历判断下两个字符串是否相等,但是这样子时间复杂度:O(nlogn + n)。
既然不考虑顺序,而在乎出现次数,可以借助哈希表辅助。
【题目 】:
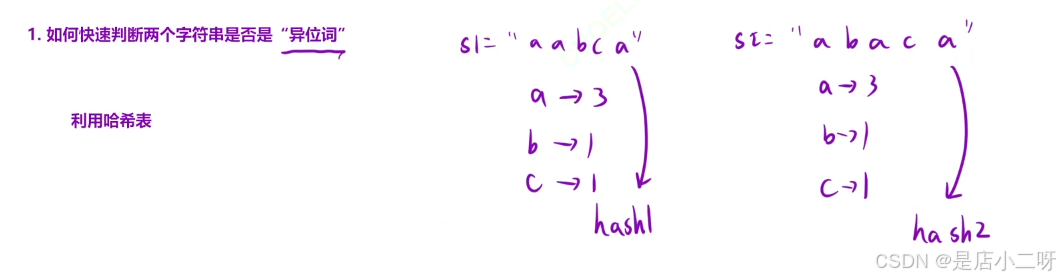
解法二:滑动窗口 + 哈希表
由于字符串 p 的异位词长度与 p 相同,我们可以利用滑动窗口来优化判断过程。在字符串 s 中,我们维护一个长度与 p 相同的滑动窗口,并在滑动过程中追踪窗口中每个字符的出现频率。
具体步骤如下:
- 使用两个长度为 26 的数组来模拟哈希表:一个记录窗口中字符的频率,另一个记录字符串
p中字符的频率。 - 每当窗口滑动时,更新这两个数组:移除窗口前一个字符,加入新的字符。
- 如果两个数组中的字符频率相同,则说明当前窗口中的子串是字符串
p的异位词。
【Cheek 机制优化】
在使用滑动窗口判断异位词时,通过指针遍历哈希表进行比较,每次最多比较 26 次(因为只有 26 个字母)。
但为了进一步优化,我们可以引入一个 count 变量,专门用来统计窗口中"有效字符"的数量。当窗口中的字符频率与目标字符串 p 的频率完全一致时,count 会反映出当前窗口是一个异位词。
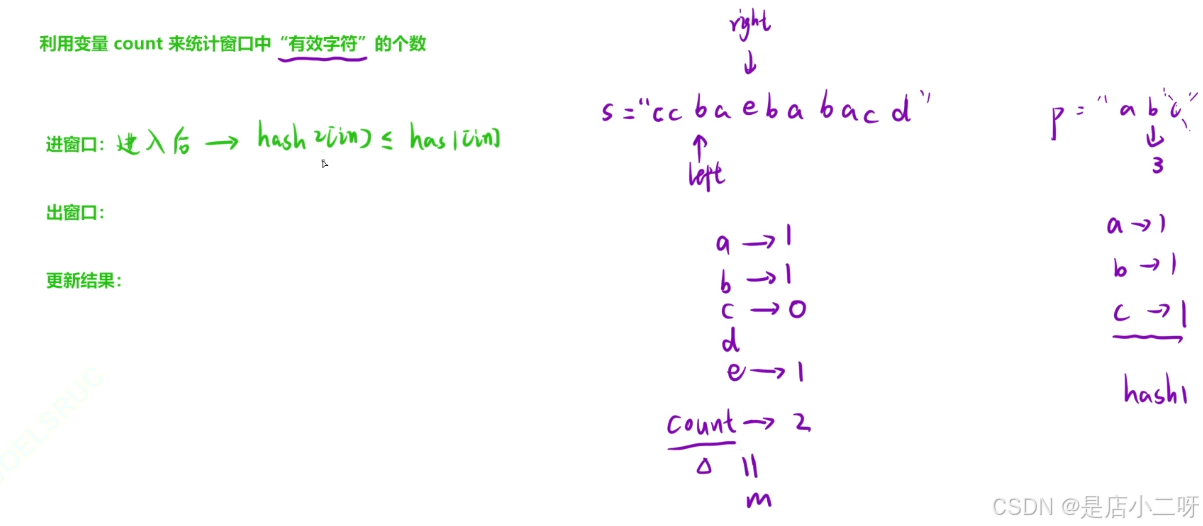
- 【进窗口 】:
if(++hash2[in - 'a'] <= hash1[in - 'a']) count++; - 【出窗口 】:
if(hash2[out - 'a']-- <= hash1[out - 'a']) count--;
cpp
class Solution {
public:
vector<int> findAnagrams(string s, string p)
{
vector<int> ret;
int hash1[26] = {0};
for(auto ch : p) hash1[ch - 'a']++;
int hash2[26] = {0};
int m = p.length();
int count = 0;
for(int left = 0, right = 0; right < s.length(); right++)
{
char in = s[right];
if(++hash2[in - 'a'] <= hash1[in - 'a']) count++;
if(right - left + 1 > m)
{
char out = s[left++];
if(hash2[out - 'a']-- <= hash1[out - 'a']) count--;
}
if(m == count) ret.push_back(left);
}
return ret;
}
};30. 串联所有单词的子串
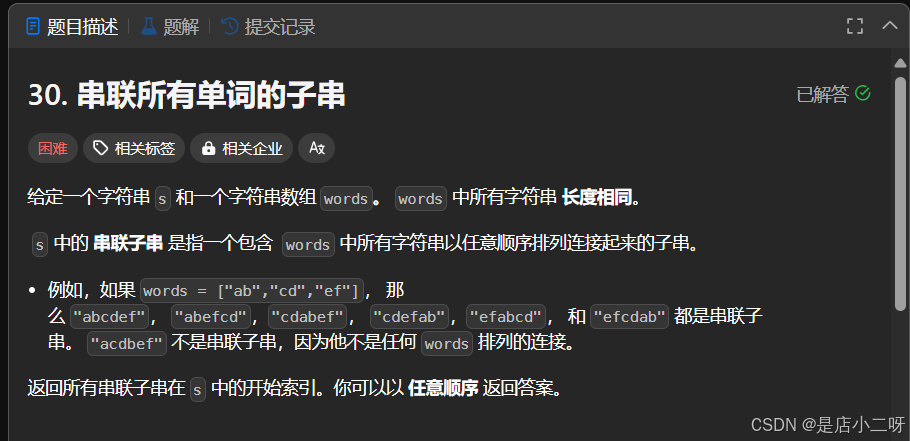
cpp
输入:s = "barfoothefoobarman", words = ["foo","bar"]
输出:[0,9]
解释:因为 words.length == 2 同时 words[i].length == 3,连接的子字符串的长度必须为 6。
子串 "barfoo" 开始位置是 0。它是 words 中以 ["bar","foo"] 顺序排列的连接。
子串 "foobar" 开始位置是 9。它是 words 中以 ["foo","bar"] 顺序排列的连接。
输出顺序无关紧要。返回 [9,0] 也是可以的。【算法思路】
1.解法一:暴力解法 + 哈希表
如果将每个单词看作由字母构成的字符串,那么问题就变成了「找到字符串中所有字母的异位词」。实际上,这与之前处理字符的异位词问题类似,只是这次我们处理的对象是单词而不是单个字符。
2.解法二:滑动窗口 + 哈希表
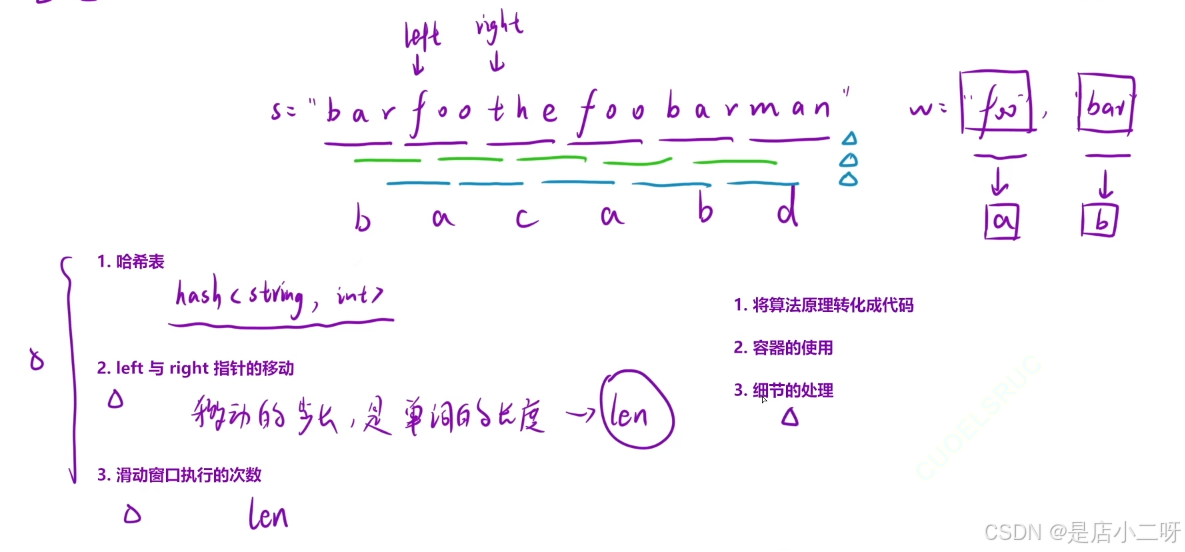
【细节问题】
通过图示划分,从不同单词位置为起点,会划分长度同为len的不同组合。所以我需要外嵌for循环为滑动窗口的次数,次数取决于单词长度。
移动的步长是单词的长度,其中我们以count变量统计"有效字符串"的长度,这里同样需要借助哈希表。其中在实际使用哈希表时,我们并不需要过多担心哈希碰撞或哈希算法的内部实现,因为它们是由库的实现提供的,已经经过优化和测试。

在模拟过程中,right 指针会移动 len 的位置,因此我们需要判断条件为 right + len <= s.size(),以确保窗口不会超出字符串 s 的边界
【代码实现】
cpp
class Solution {
public:
vector<int> findSubstring(string s, vector<string>& words)
{
vector<int> v;
unordered_map<string,int> hash1;
for(auto& str : words) hash1[str]++;
int len = words[0].size(),m = words.size();
//进行len次滑动窗口
for(int i = 0; i < len; i++)
{
unordered_map<string,int> hash2;
for(int left = i, right = i,count = 0; right + len <= s.size(); right += len)
{
//进窗口
string in = s.substr(right,len);
hash2[in]++;
if(hash1[in] && hash2[in] <= hash1[in]) count++;
if(right - left + 1 > len * m)
{
//出窗口
string out = s.substr(left,len);
if(hash1[out] && hash2[out]-- <= hash1[out]) count--;
left += len;
}
if(count == m) v.push_back(left);
}
}
return v;
}
};【语法优化】:如果s不存在p中单词,直接短路。
76.最小覆盖子串
【题目 】:76. 最小覆盖子串
【算法思路】
1.解法一:暴力枚举 + 哈希表
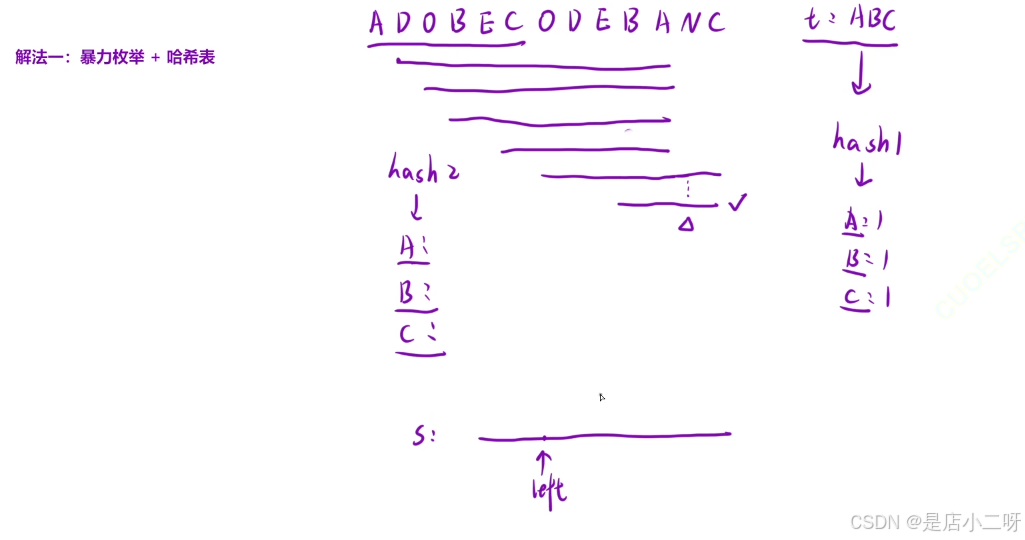
通过暴力解法绘制抽象图可以分析出,right 不需要重新遍历,因为区间 [left, right] 和 [left + 1, right] 之间存储的信息是相同的。只需移动 left,然后判断两个情况:是否符合需求,如果符合需求则继续,否则调整。由此可以推导出我们需要使用滑动窗口优化算法
2.解法二:滑动窗口 + 哈希表
【优化:判断条件】
这道题的算法思路与前面几道题相似,但优化哈希表遍历核对的判断条件有所不同。之前通过 count变量统计有效元素的次数,而这里不再单纯比较次数,而是比较元素的种类。
优化方式:使用 count 变量标记有效字符的种类,只有当所有种类的字符次数相等时,才认为满足条件并进行统计
【优化:数组模拟容器】
由于题目中字符全为小写字母,若使用容器,可能会带来较大的时间开销。因此,推荐使用数组来模拟哈希表,这样可以大幅提高效率。

【问题】:大于进行统计会导致重复

【代码实现】
cpp
class Solution {
public:
string minWindow(string s, string t)
{
int hash1[128] = {0};
int kind = 0;
for(auto&ch : t)
{
if(hash1[ch]++ == 0) kind++;
}
int hash2[128] = {0};
int count = 0;// 种类
int len = INT_MAX;
int begin = -1;
for(int left = 0, right = 0; right < s.size(); right++)
{
char in = s[right];
hash2[in]++;
if(hash2[in] == hash1[in]) count++;
while(count == kind)
{
//更新结果
if(right - left + 1 < len)
{
len = right - left +1;
begin = left;
}
char out = s[left++];
if(hash2[out] == hash1[out]) count--;
hash2[out]--;
}
}
if(begin == -1) return "";
else return s.substr(begin,len);
}
};
快和小二一起踏上精彩的算法之旅!关注我,我们将一起破解算法奥秘,探索更多实用且有趣的知识,开启属于你的编程冒险!