目录
[1.1 AI Embedded产品架构](#1.1 AI Embedded产品架构)
[1.2 AI Copilot产品架构](#1.2 AI Copilot产品架构)
[1.3 AI Agent产品架构](#1.3 AI Agent产品架构)
[2.1 纯Prompt](#2.1 纯Prompt)
[2.2 Agent + Function Calling](#2.2 Agent + Function Calling)
[2.3 RAG (Retrieval-Augmented Generation 检索增强生成)](#2.3 RAG (Retrieval-Augmented Generation 检索增强生成))
[2.4 Fine-tuning(微调)](#2.4 Fine-tuning(微调))
大模型应用的产品架构随着技术发展和场景需求不断演进,在演进的过程中人们提出了不同的应用产品架构和技术架构
一,产品架构
1.1 AI Embedded产品架构
在早期,深度学习初步成熟,但大模型技术还没有出现。
人们将AI能力深度集成到现有产品或流程中,作为后台功能增强用户体验。例如电商平台的个性化推荐(如淘宝猜你喜欢);手机相册的智能分类(如人脸识别分组)。
也就是AI作为模块化功能嵌入产品。
这种模式下,人类的干预还是占主导,而AI模型只是作为很小的一部分,嵌入到我们的产品当中,提高产品的服务和体验。
这种产品架构下,用户无需主动调用,AI自动在后台处理任务(如推荐算法、语音识别)。甚至用户可能意识不到AI的存在,只是能感受到功能优化。
1.2 AI Copilot产品架构
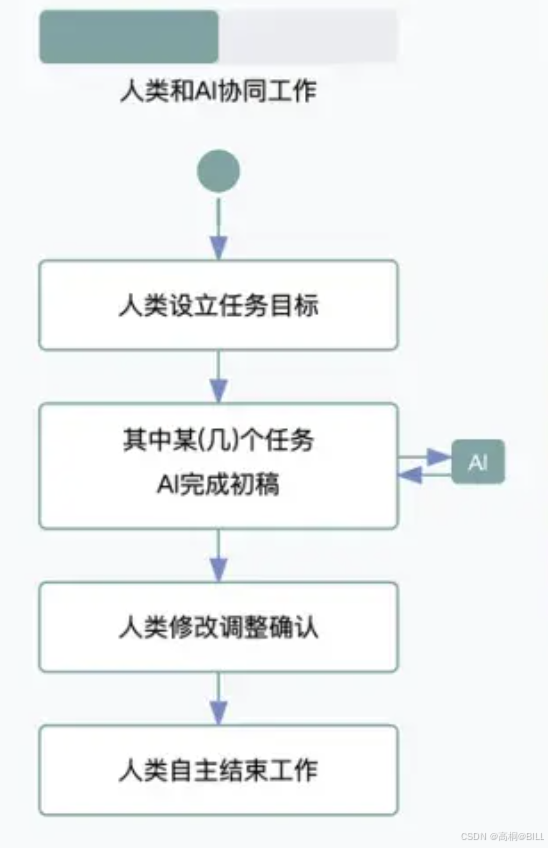
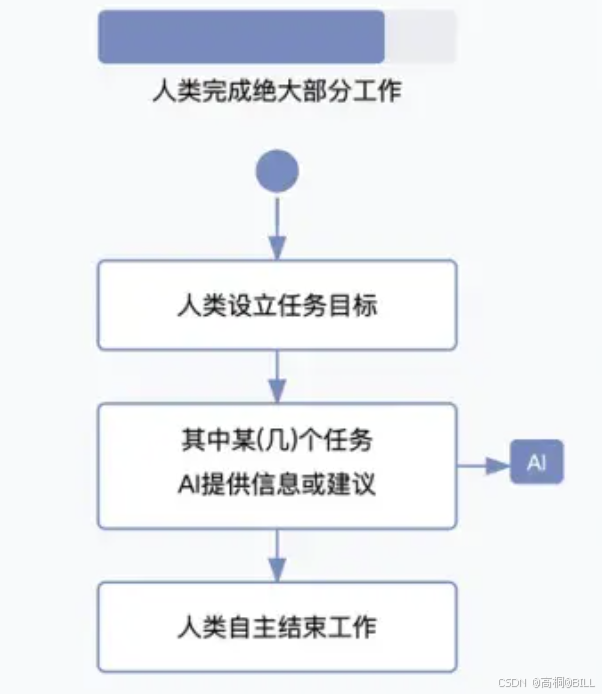
随着GPT-3等大模型突破,理解上下文能力得到跃升。 人们提出了AI Copilot架构,这也是目前的主流架构,其核心是多Agent工作流。
在这种架构下,AI作为用户实时助手,如代码编写、文档润色。甚至可以完成复杂任务,如提供建议、补全或错误修正(如GitHub Copilot),不过决策权依然在用户。
当人类设立了工作目标之后,目标会被拆解成一个个的子任务,或者流水线。在这个流水线上有多个Agent,每个Agent负责这个任务流水线的一部分,所有Agent共同协作达成任务目标。
1.3 AI Agent产品架构
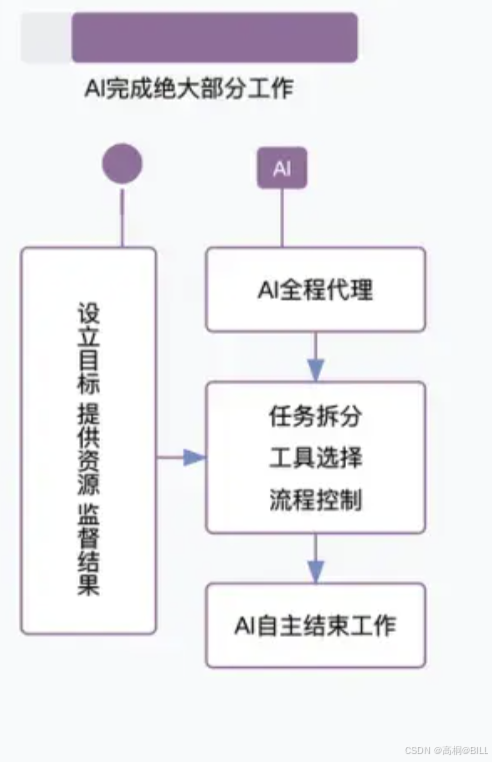
随着大模型+强化学习的发展,人们提出AI Agent产品架构。 AI Agent可以自主规划任务,自主决策。
AI Agent核心思想是构建具有自主性、反应性和社会性的实体,能够在动态环境中独立或协作完成任务。
在这种模式下,人为干预占一小部分,绝大部分任务,都有AI来完成。
二,技术架构
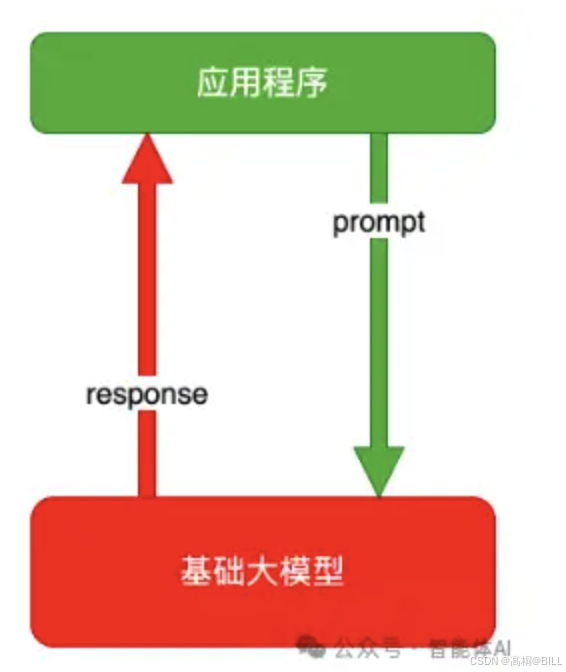
2.1 纯Prompt
在该技术架构下,Prompt使用户与大模型交流的唯一窗口。用户与大模型,一问一答的形式进行交流。
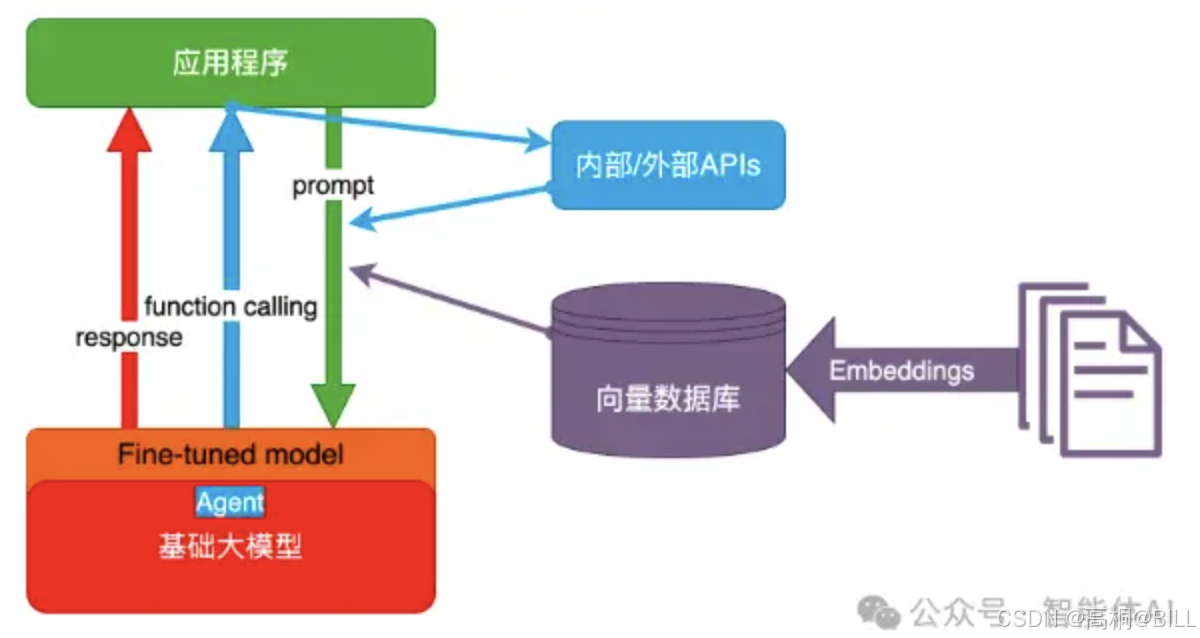
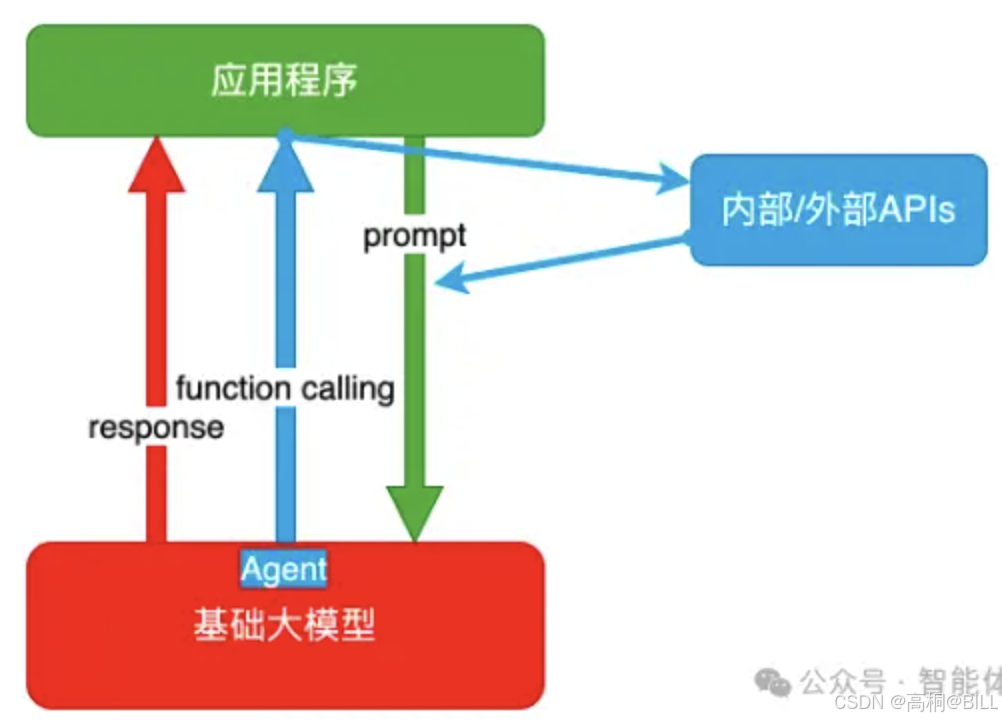
2.2 Agent + Function Calling
这种技术架构下,由AI主动提要求,例如AI需要通过执行某个函数,也就是通过调用其他的能力来完成最后的任务。
例如你的问题是去北京,要穿什么衣服,去故宫要提前几天预约等。那么通过外部接口的返回,来完成这个问题的解答。
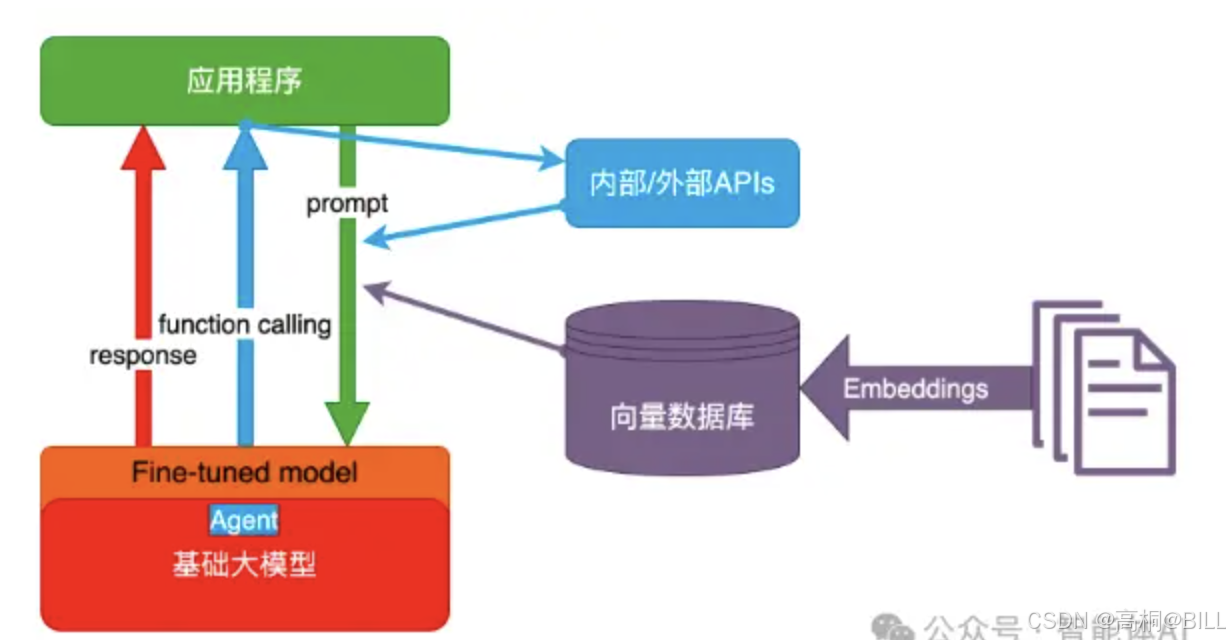
2.3 RAG (Retrieval-Augmented Generation 检索增强生成)
RAG的核心技术栈基于向量语义编码与向量检索引擎的协同运作。
-
语义向量化层
通过Embeddings模型(如BERT、Sentence-Transformer等)将非结构化文本转换为高维稠密向量,将语义相似性转化为数学可计算的向量空间距离(如余弦相似度、欧氏距离),解决传统关键词匹配的语义歧义问题。
-
向量存储与索引层
构建专用向量数据库(如Pinecone、Milvus、FAISS),利用近似最近邻搜索(ANN)算法(如HNSW、IVF-PQ)实现毫秒级检索,支持十亿级向量规模下的实时响应。
-
动态检索匹配层
用户输入的查询文本经Embeddings模型实时编码为向量后,在向量数据库中执行语义拓扑匹配,返回与查询向量空间距离最近的Top-K文档向量,同步返回原始文本片段及元数据(如来源、时间戳)。
举个例子,
- 输入:请解析2023年高考数学全国卷I第20题三角函数综合应用
- 分析:
- 问题向量生成:通过Sentence-BERT编码为768维向量
- 向量数据库检索:在500万道题目向量库中匹配相似度>0.85的Top-5结果
- 上下文增强:关联检索到3篇历年真题解析、2篇教师评课记录、1篇官方评分标准
- 生成:生成包含详细解题步骤、易错点分析、评分细则的整合答案,较传统检索效率提升72%,答案准确率提升至94.6%(基于10万条测试数据)
2.4 Fine-tuning(微调)
微调的核心在于,在预训练模型的基础上,针对特定任务或领域开展进一步的训练,使模型能够深入学习并掌握该领域的知识和特征,从而在长期记忆的基础上灵活运用这些知识。
与传统的方法相比,Fine-Tuning具有显著的优势。它并非从零开始训练模型,而是充分利用预训练模型已经学习到的通用知识,通过微调使其快速适应特定场景。这种方法不仅能够节省大量的训练时间和计算资源,还能让模型在特定领域展现出更高的专业性和准确性。
例如在医学领域,疾病的诊断需要高度的专业知识和精确的判断。通过Fine-Tuning技术,可以对预训练模型进行医学影像数据(如X光、CT、MRI等)和临床病例数据的微调训练。经过训练后的模型能够识别各种疾病的特征模式,辅助医生进行更准确的诊断,提高诊断的效率和准确性,为患者的治疗争取宝贵的时间。