在AI代理系统的开发过程中,上下文工程已成为决定系统性能的关键技术。上下文工程本质上是在为AI系统分配任务之前建立合适的执行环境,这个环境需要包含明确的行为指令(如配置AI充当专业的预算旅行顾问)、来自数据库、文档或实时数据源的有用信息访问权限、对历史对话的记忆能力以避免信息重复或遗忘、可供AI调用的工具集(计算器、搜索引擎等功能组件),以及用户的个性化信息(偏好设置、地理位置等关键细节)。
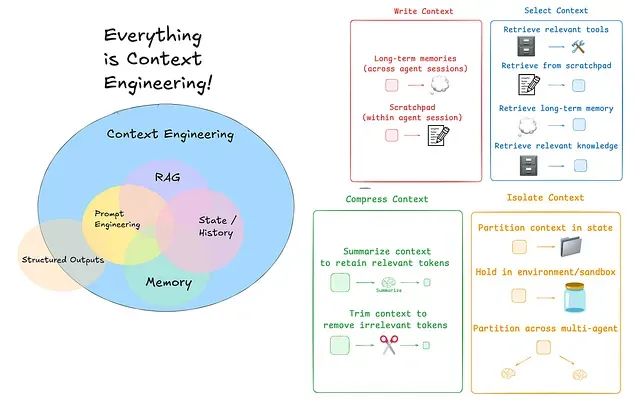
当前AI工程领域正在经历从提示工程向上下文工程的重要转变,这种转变的核心驱动力在于上下文工程能够为AI系统提供更恰当的背景信息和工具支持,从而显著提升其回应的智能化程度和实用价值。
本文将深入探讨如何运用LangChain和LangGraph这两个构建AI代理、RAG应用和LLM应用的核心工具,系统性地实现上下文工程技术,以实现AI代理性能的全面优化。
上下文工程的理论基础
从系统架构的角度来看,大语言模型(LLM)可以被理解为一种新型的操作系统架构。在这种架构中,LLM承担着类似于中央处理器(CPU)的核心计算职责,而其上下文窗口则发挥着类似于随机存取内存(RAM)的作用,作为系统的短期记忆存储组件。然而,正如物理内存存在容量限制一样,上下文窗口对于不同类型信息的存储空间同样存在约束。
正如操作系统需要决策哪些数据应当载入内存一样,上下文工程的核心任务是确定LLM应当在其上下文空间中保留哪些关键信息。
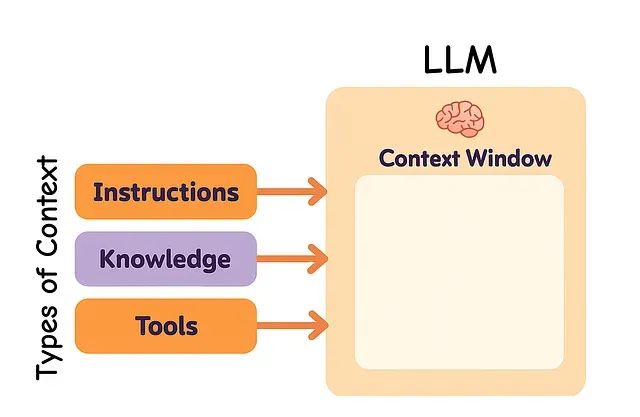
在构建LLM应用系统的过程中,需要对多种类型的上下文信息进行有效管理。上下文工程主要涵盖三个核心类别:指令类上下文(包括提示信息、示例数据、记忆内容和工具描述)、知识类上下文(涵盖事实信息、存储数据和历史记忆)以及工具类上下文(包含工具调用的反馈信息和执行结果)。
近年来,AI代理技术受到广泛关注的原因在于LLM在推理能力和工具使用方面的显著提升。AI代理通过整合LLM的认知能力与外部工具的执行能力来处理复杂的长期任务,并根据工具反馈信息动态调整后续行动策略。
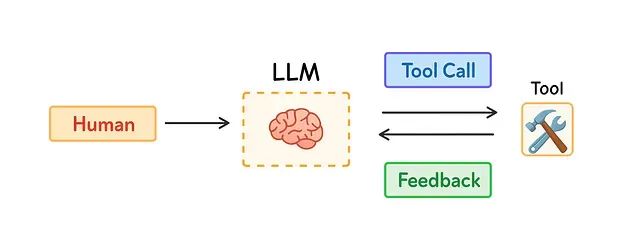
长期任务执行和大量工具反馈信息的收集会导致显著的令牌消耗问题。这种情况可能引发多种技术挑战:上下文窗口溢出、系统运行成本增加、响应延迟加剧,以及代理整体性能下降。
Drew Breunig在其研究中详细阐述了过量上下文信息对系统性能的负面影响,包括上下文污染(错误信息或幻觉内容被引入上下文)、上下文干扰(过量信息导致模型混乱)、上下文混淆(冗余细节影响响应质量)以及上下文冲突(不同上下文片段提供相互矛盾的信息)。
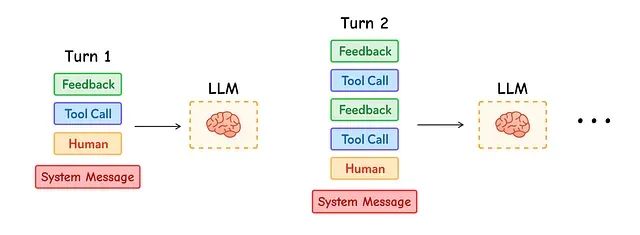
Anthropic在其研究报告中强调了上下文管理的重要性,指出代理系统经常需要进行数百轮的对话交互,因此精确的上下文管理成为系统成功的关键要素。
针对这些挑战,当前主流的代理上下文工程策略可以归纳为四个核心类别:写入策略(创建清晰有效的上下文内容)、选择策略(仅保留最相关的信息)、压缩策略(通过缩短上下文来节省存储空间)以及隔离策略(将不同类型的上下文信息分离管理)。
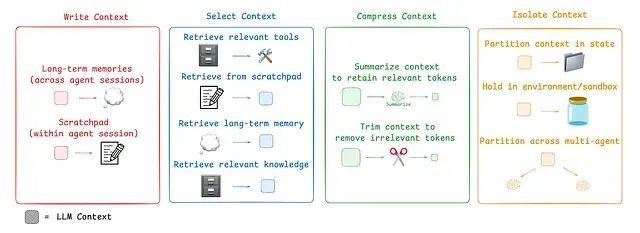
LangGraph框架的设计充分考虑了对这些策略的全面支持。接下来,我们将逐一深入分析LangGraph中这些组件的实现方法,并探讨它们如何协同工作以提升AI代理的整体性能。
基于LangGraph的Scratchpad实现机制
在AI代理系统中,正如人类需要记录笔记以备后续任务参考一样,代理同样需要一个临时记录机制来存储关键信息。Scratchpad技术通过在上下文窗口外部存储信息,使代理能够在需要时随时访问这些数据。
Anthropic的多代理研究系统提供了一个典型的应用案例:LeadResearcher会制定详细的研究计划并将其保存到内存中,这样做的目的是防止当上下文窗口超过200,000个令牌时发生信息截断,确保重要的规划信息不会丢失。
Scratchpad的实现方式主要有两种:一种是通过工具调用将信息写入文件系统,另一种是作为会话期间持续存在的运行时状态对象中的字段。简而言之,Scratchpad技术帮助代理在整个会话过程中维护重要的工作记录,从而高效地完成复杂任务。
就LangGraph框架而言,它提供了对短期内存(线程作用域)和长期内存的全面支持。短期内存通过检查点机制在会话期间保存代理状态,其工作原理类似于Scratchpad,允许在代理运行过程中存储信息并在稍后进行检索。
状态对象是在图节点之间传递的核心数据结构。开发者可以自定义其格式(通常采用Python字典结构),它充当共享的Scratchpad,每个节点都可以读取和更新特定字段的内容。
为了确保学习过程的清晰性,我们采用按需导入的方式引入所需模块。为了获得更优质的输出效果,我们将使用Python的
pprint模块进行格式化打印,以及来自
rich库的
Console模块。首先进行这些模块的导入和初始化:
# Import necessary libraries
from typing import TypedDict # For defining the state schema with type hints
from rich.console import Console # 用于美化输出显示
from rich.pretty import pprint # 用于美化Python对象的打印输出
# 为notebook环境初始化丰富格式化输出的控制台实例
console = Console()接下来,我们将为状态对象创建一个
TypedDict类型定义:
# 使用TypedDict定义图状态的数据模式
# 该类作为在图节点间传递的数据结构
# 确保状态具有一致的数据结构并提供类型提示功能
class State(TypedDict):
"""
定义笑话生成器工作流的状态结构
属性说明:
topic: 用于生成笑话的输入主题
joke: 存储生成笑话内容的输出字段
"""
topic: str
joke: str该状态对象将存储主题信息以及代理基于给定主题生成的笑话内容。
在定义状态对象之后,我们可以通过StateGraph向其写入上下文信息。StateGraph是LangGraph框架用于构建有状态代理或工作流的核心工具,可以将其理解为一个有向图结构:节点代表工作流中的执行步骤,每个节点接收当前状态作为输入,对其进行更新,并返回修改结果;边用于连接节点,定义执行流程的路径,这种路径可以是线性的、条件性的,甚至是循环性的。
接下来的实现步骤包括:通过选择Anthropic模型来创建聊天模型,并将其集成到LangGraph工作流中。
# 导入环境管理、显示功能和LangGraph相关的必要库
import getpass
import os
from IPython.display import Image, display
from langchain.chat_models import init_chat_model
from langgraph.graph import END, START, StateGraph
# --- 环境配置和模型初始化 ---
# 设置Anthropic API密钥用于请求认证
from dotenv import load_dotenv
api_key = os.getenv("ANTHROPIC_API_KEY")
if not api_key:
raise ValueError("Missing ANTHROPIC_API_KEY in environment")
# 初始化工作流中使用的聊天模型
# 使用特定的Claude模型,temperature=0确保输出的确定性
llm = init_chat_model("anthropic:claude-sonnet-4-20250514", temperature=0)我们已经成功初始化了Sonnet模型。LangChain框架通过其API接口支持众多开源和商业模型,因此开发者可以根据需求选择合适的模型。
现在需要创建一个使用该Sonnet模型生成响应的函数:
# --- 定义工作流节点函数 ---
def generate_joke(state: State) -> dict[str, str]:
"""
基于当前状态中的主题信息生成笑话的节点函数
该函数从状态中读取'topic'字段,使用LLM生成相应的笑话内容,
并返回用于更新状态中'joke'字段的字典
参数:
state: 包含主题信息的图当前状态
返回值:
包含'joke'键的字典,用于更新状态
"""
# 从状态中提取主题信息
topic = state["topic"]
print(f"正在生成关于{topic}的笑话")
# 调用语言模型生成笑话内容
msg = llm.invoke(f"Write a short joke about {topic}")
# 返回生成的笑话用于状态更新
return {"joke": msg.content}该函数的核心功能是返回包含生成响应(笑话内容)的字典结构。
现在,利用StateGraph可以便捷地构建和编译图结构。让我们继续实现这一过程:
# --- 图结构的构建与编译 ---
# 使用预定义的State模式初始化StateGraph实例
workflow = StateGraph(State)
# 将'generate_joke'函数作为节点添加到图中
workflow.add_node("generate_joke", generate_joke)
# 定义工作流的执行路径:
# 图从START入口点开始,流向'generate_joke'节点
workflow.add_edge(START, "generate_joke")
# 'generate_joke'节点完成后,图执行结束
workflow.add_edge("generate_joke", END)
# 将工作流编译为可执行的链式结构
chain = workflow.compile()
# --- 图结构可视化 ---
# 显示编译后工作流图的可视化表示
display(Image(chain.get_graph().draw_mermaid_png()))
现在可以执行这个工作流程:
# --- 工作流执行 ---
# 使用包含主题的初始状态调用编译后的图
# `invoke`方法执行从START节点到END节点的完整流程
joke_generator_state = chain.invoke({"topic": "cats"})
# --- 最终状态显示 ---
# 打印执行后图的最终状态
# 将显示输入的'topic'和写入状态的输出'joke'
console.print("\n[bold blue]笑话生成器状态:[/bold blue]")
pprint(joke_generator_state)
#### 输出结果 ####
{
'topic': 'cats',
'joke': 'Why did the cat join a band?\n\nBecause it wanted to be the purr-cussionist!'
}执行结果返回的字典实际上代表了代理的笑话生成状态。这个简单的示例演示了如何向状态写入上下文信息的基本机制。
开发者可以进一步了解检查点技术用于保存和恢复图状态,以及人机交互循环技术用于在继续执行之前暂停工作流以获取人工输入。
LangGraph中的内存写入机制
虽然Scratchpad技术有助于代理在单个会话内进行工作,但在某些场景下,代理需要跨多个会话保持信息记忆。Reflexion技术引入了代理在每次交互后进行反思并重用自生成提示的概念,而Generative Agents则通过总结历史代理反馈来创建长期记忆机制。
这些创新理念已被应用于ChatGPT、Cursor和Windsurf等主流产品中,这些系统能够从用户交互中自动创建长期记忆。
LangGraph框架的内存机制包含两个关键组件:检查点技术在线程的每个步骤中保存图的状态,其中线程具有唯一标识符,通常代表一次完整的交互(类似ChatGPT中的单次对话);长期内存技术允许跨线程保持特定上下文,可以保存单个文件(如用户配置文件)或记忆集合。该系统基于BaseStore接口实现,这是一个键值存储系统,可以在内存中使用(如本示例所示)或与LangGraph平台部署配合使用。
现在让我们创建一个
InMemoryStore实例,用于在本notebook的多个会话中使用:
from langgraph.store.memory import InMemoryStore
# --- 长期内存存储初始化 ---
# 创建InMemoryStore实例,提供简单的非持久化键值存储系统
# 用于当前会话内的数据管理
store = InMemoryStore()
# --- 命名空间定义 ---
# 命名空间用于在存储中逻辑性地分组相关数据
# 这里使用元组表示分层命名空间结构
# 可能对应用户ID和应用程序上下文
namespace = ("rlm", "joke_generator")
# --- 向内存存储写入数据 ---
# 使用`put`方法将键值对保存到指定命名空间
# 该操作持久化前一步生成的笑话,使其可在不同会话或线程中检索
store.put(
namespace, # 写入目标命名空间
"last_joke", # 数据条目的键标识符
{"joke": joke_generator_state["joke"]}, # 待存储的值
)我们将在后续部分讨论如何从命名空间中选择上下文。目前可以使用search方法查看命名空间内的项目,以确认数据写入操作的成功:
# 搜索命名空间以查看所有存储项目
stored_items = list(store.search(namespace))
# 使用丰富格式显示存储的项目
console.print("\n[bold green]内存中存储的项目:[/bold green]")
pprint(stored_items)
#### 输出结果 ####
[
Item(namespace=['rlm', 'joke_generator'], key='last_joke',
value={'joke': 'Why did the cat join a band?\n\nBecause it wanted to be the purr-cussionist!'},
created_at='2025-07-24T02:12:25.936238+00:00',
updated_at='2025-07-24T02:12:25.936238+00:00', score=None)
]现在,让我们将前面实现的所有功能集成到LangGraph工作流中。
工作流编译需要两个关键参数:
checkpointer用于在线程的每个步骤保存图状态,
store用于跨不同线程维护上下文。
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.store.base import BaseStore
from langgraph.store.memory import InMemoryStore
# 存储组件初始化
checkpointer = InMemorySaver() # 线程级状态持久化
memory_store = InMemoryStore() # 跨线程内存存储
def generate_joke(state: State, store: BaseStore) -> dict[str, str]:
"""生成具有内存感知能力的笑话
该增强版本在生成新笑话之前检查内存中的现有笑话
参数:
state: 包含主题的当前状态
store: 用于持久化上下文的内存存储
返回值:
包含生成笑话的字典
"""
# 检查内存中是否存在现有笑话
existing_jokes = list(store.search(namespace))
if existing_jokes:
existing_joke = existing_jokes[0].value
print(f"现有笑话: {existing_joke}")
else:
print("现有笑话: 无")
# 基于主题生成新笑话
msg = llm.invoke(f"Write a short joke about {state['topic']}")
# 将新笑话存储到长期内存中
store.put(namespace, "last_joke", {"joke": msg.content})
# 返回待添加到状态的笑话
return {"joke": msg.content}
# 构建具有内存功能的工作流
workflow = StateGraph(State)
# 添加内存感知的笑话生成节点
workflow.add_node("generate_joke", generate_joke)
# 连接工作流组件
workflow.add_edge(START, "generate_joke")
workflow.add_edge("generate_joke", END)
# 使用检查点和内存存储进行编译
chain = workflow.compile(checkpointer=checkpointer, store=memory_store)现在可以执行更新后的工作流,测试启用内存功能后的运行效果:
# 使用基于线程的配置执行工作流
config = {"configurable": {"thread_id": "1"}}
joke_generator_state = chain.invoke({"topic": "cats"}, config)
# 使用丰富格式显示工作流结果
console.print("\n[bold cyan]工作流结果 (线程 1):[/bold cyan]")
pprint(joke_generator_state)
#### 输出结果 ####
现有笑话: 无
工作流结果 (线程 1):
{'topic': 'cats',
'joke': 'Why did the cat join a band?\n\nBecause it wanted to be the purr-cussionist!'}由于这是线程1的首次执行,AI代理的内存中没有存储现有笑话,这完全符合新线程的预期行为。
由于工作流使用检查点进行编译,现在可以查看图的最新状态:
# --- 检索和检查图状态 ---
# 使用`get_state`方法检索配置中指定线程的最新状态快照
# (在此案例中为线程"1")。由于使用检查点编译了图,该操作成为可能
latest_state = chain.get_state(config)
# --- 状态快照显示 ---
# 将检索到的状态输出到控制台。StateSnapshot不仅包含数据('topic','joke')
# 还包含执行元数据
console.print("\n[bold magenta]最新图状态 (线程 1):[/bold magenta]")
pprint(latest_state)观察输出结果:
### 最新状态输出 ###
最新图状态:
StateSnapshot(
values={
'topic': 'cats',
'joke': 'Why did the cat join a band?\n\nBecause it wanted to be the purr-cussionist!'
},
next=(),
config={
'configurable': {
'thread_id': '1',
'checkpoint_ns': '',
'checkpoint_id': '1f06833a-53a7-65a8-8001-548e412001c4'
}
},
metadata={'source': 'loop', 'step': 1, 'parents': {}},
created_at='2025-07-24T02:12:27.317802+00:00',
parent_config={
'configurable': {
'thread_id': '1',
'checkpoint_ns': '',
'checkpoint_id': '1f06833a-4a50-6108-8000-245cde0c2411'
}
},
tasks=(),
interrupts=()
)可以看到状态中记录了与代理的最后一次对话内容,即我们请求它讲述关于猫的笑话。
现在使用不同的线程ID重新运行工作流:
# 使用不同线程ID执行工作流
config = {"configurable": {"thread_id": "2"}}
joke_generator_state = chain.invoke({"topic": "cats"}, config)
# 显示结果,展示跨线程的内存持久性
console.print("\n[bold yellow]工作流结果 (线程 2):[/bold yellow]")
pprint(joke_generator_state)
#### 输出结果 ####
现有笑话: {'joke': 'Why did the cat join a band?\n\nBecause it wanted to be the purr-cussionist!'}
工作流结果 (线程 2):
{'topic': 'cats', 'joke': 'Why did the cat join a band?\n\nBecause it wanted to be the purr-cussionist!'}可以验证来自第一个线程的笑话已成功保存到内存中。
开发者可以进一步了解LangMem内存抽象技术和Ambient Agents课程,以获得LangGraph代理中内存管理的深入概述。
Scratchpad上下文选择机制
从Scratchpad中选择上下文的具体方法取决于其实现架构:当Scratchpad作为工具实现时,代理可以通过工具调用直接读取其内容;当其作为代理运行时状态的组成部分时,开发者需要决定在每个执行步骤中与代理共享状态的哪些特定部分,这种方式提供了对暴露上下文内容的精细化控制能力。
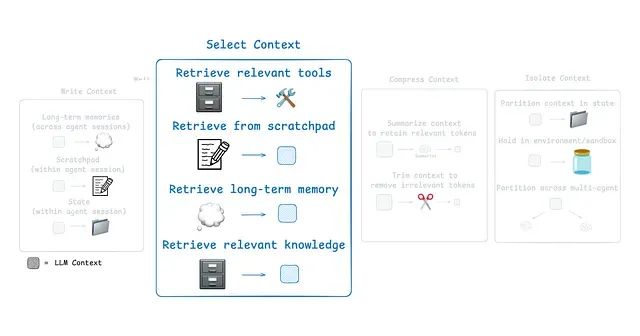
在前面的实现中,我们学习了如何向LangGraph状态对象写入数据。现在将探讨如何从状态中选择性地提取上下文信息,并将其传递给下游节点中的LLM调用。这种选择性方法使开发者能够精确控制LLM在执行过程中接收的上下文内容。
def generate_joke(state: State) -> dict[str, str]:
"""生成基于主题的初始笑话
参数:
state: 包含主题信息的当前状态
返回值:
包含生成笑话的字典
"""
msg = llm.invoke(f"Write a short joke about {state['topic']}")
return {"joke": msg.content}
def improve_joke(state: State) -> dict[str, str]:
"""通过添加文字游戏元素改进现有笑话
该函数演示了从状态中选择上下文的过程------从状态中读取现有笑话
并基于此生成改进版本
参数:
state: 包含原始笑话的当前状态
返回值:
包含改进笑话的字典
"""
print(f"初始笑话: {state['joke']}")
# 从状态中选择笑话内容呈现给LLM
msg = llm.invoke(f"Make this joke funnier by adding wordplay: {state['joke']}")
return {"improved_joke": msg.content}为了增加系统复杂性,我们现在向代理添加两个工作流程:第一个是笑话生成流程(与之前相同),第二个是笑话改进流程(获取生成的笑话并对其进行优化)。
这种配置将帮助我们理解Scratchpad选择机制在LangGraph中的运作方式。现在以与之前相同的方式编译此工作流并检查图结构:
# 构建包含两个顺序节点的工作流
workflow = StateGraph(State)
# 添加两个笑话处理节点
workflow.add_node("generate_joke", generate_joke)
workflow.add_node("improve_joke", improve_joke)
# 按顺序连接节点
workflow.add_edge(START, "generate_joke")
workflow.add_edge("generate_joke", "improve_joke")
workflow.add_edge("improve_joke", END)
# 编译工作流
chain = workflow.compile()
# 显示工作流可视化
display(Image(chain.get_graph().draw_mermaid_png()))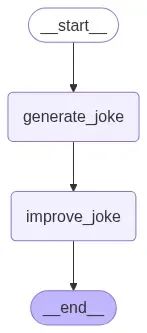
执行该工作流时的结果如下:
# 执行工作流以观察上下文选择的实际效果
joke_generator_state = chain.invoke({"topic": "cats"})
# 使用丰富格式显示最终状态
console.print("\n[bold blue]最终工作流状态:[/bold blue]")
pprint(joke_generator_state)
#### 输出结果 ####
初始笑话: Why did the cat join a band?
Because it wanted to be the purr-cussionist!
最终工作流状态:
{
'topic': 'cats',
'joke': 'Why did the cat join a band?\n\nBecause it wanted to be the purr-cussionist!'
}完成工作流执行后,我们可以继续进行内存选择步骤的实现。
内存选择能力的实现
当代理具备保存记忆的能力时,同样需要为当前任务选择相关的记忆内容。这种能力在以下场景中特别有用:情节记忆(展示期望行为的few-shot示例)、程序记忆(指导行为执行的指令)以及语义记忆(提供任务相关上下文的事实或关系信息)。
一些代理系统使用预定义的文件来存储记忆内容:Claude Code使用
CLAUDE.md文件,而Cursor和Windsurf使用"规则"文件来存储指令或示例。然而,当需要存储大量事实集合(语义记忆)时,选择过程变得更加复杂。
ChatGPT有时会检索不相关的记忆内容,正如Simon Willison所演示的案例,当ChatGPT错误地获取他的位置信息并将其注入图像生成过程中时,导致上下文感觉"不再属于用户本人"。为了改进选择精度,系统通常采用嵌入技术或知识图谱进行索引。
在之前的部分中,我们在图节点中写入了
InMemoryStore。现在可以使用get方法从中选择上下文,将相关状态信息引入工作流:
from langgraph.store.memory import InMemoryStore
# 初始化内存存储
store = InMemoryStore()
# 定义用于组织记忆的命名空间
namespace = ("rlm", "joke_generator")
# 将生成的笑话存储在内存中
store.put(
namespace, # 组织用命名空间
"last_joke", # 键标识符
{"joke": joke_generator_state["joke"]} # 待存储的值
)
# 从内存中选择(检索)笑话内容
retrieved_joke = store.get(namespace, "last_joke").value
# 显示检索到的上下文
console.print("\n[bold green]从内存检索的上下文:[/bold green]")
pprint(retrieved_joke)
#### 输出结果 ####
从内存检索的上下文:
{'joke': 'Why did the cat join a band?\n\nBecause it wanted to be the purr-cussionist!'}系统成功地从内存中检索了正确的笑话内容。
现在需要编写一个完整的
generate_joke函数,该函数能够:获取当前状态(用于scratchpad上下文),利用内存(在执行笑话改进任务时获取历史笑话)。
让我们实现这一功能:
# 初始化存储组件
checkpointer = InMemorySaver()
memory_store = InMemoryStore()
def generate_joke(state: State, store: BaseStore) -> dict[str, str]:
"""生成具有内存感知上下文选择能力的笑话
该函数演示了在生成新内容之前从内存中选择上下文的过程,
确保内容一致性并避免重复
参数:
state: 包含主题的当前状态
store: 用于持久化上下文的内存存储
返回值:
包含生成笑话的字典
"""
# 从内存中选择先前的笑话(如果存在)
prior_joke = store.get(namespace, "last_joke")
if prior_joke:
prior_joke_text = prior_joke.value["joke"]
print(f"先前笑话: {prior_joke_text}")
else:
print("先前笑话: 无")
# 生成与先前笑话不同的新笑话
prompt = (
f"Write a short joke about {state['topic']}, "
f"but make it different from any prior joke you've written: {prior_joke_text if prior_joke else 'None'}"
)
msg = llm.invoke(prompt)
# 将新笑话存储在内存中供未来上下文选择使用
store.put(namespace, "last_joke", {"joke": msg.content})
return {"joke": msg.content}现在可以以与之前相同的方式执行这个内存感知工作流:
# 构建内存感知工作流
workflow = StateGraph(State)
workflow.add_node("generate_joke", generate_joke)
# 连接工作流
workflow.add_edge(START, "generate_joke")
workflow.add_edge("generate_joke", END)
# 使用检查点和内存存储进行编译
chain = workflow.compile(checkpointer=checkpointer, store=memory_store)
# 使用第一个线程执行工作流
config = {"configurable": {"thread_id": "1"}}
joke_generator_state = chain.invoke({"topic": "cats"}, config)
#### 输出结果 ####
先前笑话: 无没有检测到先前的笑话,现在可以打印最新的状态结构:
# 获取图的最新状态
latest_state = chain.get_state(config)
console.print("\n[bold magenta]最新图状态:[/bold magenta]")
pprint(latest_state)输出结果:
#### 最新状态输出 ####
StateSnapshot(
values={
'topic': 'cats',
'joke': "Here's a new one:\n\nWhy did the cat join a band?\n\nBecause it wanted to be the purr-cussionist!"
},
next=(),
config={
'configurable': {
'thread_id': '1',
'checkpoint_ns': '',
'checkpoint_id': '1f068357-cc8d-68cb-8001-31f64daf7bb6'
}
},
metadata={'source': 'loop', 'step': 1, 'parents': {}},
created_at='2025-07-24T02:25:38.457825+00:00',
parent_config={
'configurable': {
'thread_id': '1',
'checkpoint_ns': '',
'checkpoint_id': '1f068357-c459-6deb-8000-16ce383a5b6b'
}
},
tasks=(),
interrupts=()
)系统从内存中获取先前的笑话并将其传递给LLM进行改进:
# 使用第二个线程执行工作流以演示内存持久性
config = {"configurable": {"thread_id": "2"}}
joke_generator_state = chain.invoke({"topic": "cats"}, config)
#### 输出结果 ####
先前笑话: Here is a new one:
Why did the cat join a band?
Because it wanted to be the purr-cussionist!系统已成功从内存中获取正确的笑话并按预期对其进行了改进。
LangGraph BigTool调用的技术优势
在代理系统中,虽然工具的使用提高了功能性,但为代理提供过多工具可能导致选择困惑,特别是当工具描述存在重叠时。这种情况增加了模型选择正确工具的难度。
一个有效的解决方案是在工具描述上应用RAG(检索增强生成)技术,仅基于语义相似性获取最相关的工具。Drew Breunig将这种方法称为"工具装备"策略。
根据最新研究结果,这种方法能够将工具选择准确率提升3倍。
对于工具选择任务,LangGraph Bigtool库提供了理想的解决方案。该库在工具描述上应用语义相似性搜索来选择最适合执行任务的工具。它利用LangGraph的长期内存存储机制,使代理能够搜索并检索适合特定问题的正确工具。
让我们通过使用包含Python内置数学库所有函数的代理来理解
langgraph-bigtool的工作原理:
import math
# 从`math`内置库收集函数
all_tools = []
for function_name in dir(math):
function = getattr(math, function_name)
if not isinstance(
function, types.BuiltinFunctionType
):
continue
# 这是`math`库的特定要求
if tool := convert_positional_only_function_to_tool(
function
):
all_tools.append(tool)首先将Python数学模块的所有函数收集到列表中。接下来需要将这些工具描述转换为向量嵌入,以便代理能够执行语义相似性搜索。
为此,我们将使用嵌入模型,在本案例中采用OpenAI的文本嵌入模型:
# 创建工具注册表。这是一个将标识符映射到工具实例的字典
tool_registry = {
str(uuid.uuid4()): tool
for tool in all_tools
}
# 在LangGraph存储中索引工具名称和描述
# 此处使用简单的内存存储
embeddings = init_embeddings("openai:text-embedding-3-small")
store = InMemoryStore(
index={
"embed": embeddings,
"dims": 1536,
"fields": ["description"],
}
)
for tool_id, tool in tool_registry.items():
store.put(
("tools",),
tool_id,
{
"description": f"{tool.name}: {tool.description}",
},
)每个函数都被分配唯一标识符,并将这些函数结构化为标准格式。这种结构化格式确保函数能够轻松转换为嵌入向量,以支持语义搜索功能。
现在让我们可视化代理,观察在所有数学函数都已嵌入并准备进行语义搜索的情况下系统的表现:
# 初始化代理
builder = create_agent(llm, tool_registry)
agent = builder.compile(store=store)
agent
现在可以使用简单查询调用代理,观察工具调用代理如何选择和使用最相关的数学函数来回答问题:
# 导入格式化和显示消息的实用函数
from utils import format_messages
# 为代理定义查询
# 该查询要求代理使用其数学工具之一计算反余弦值
query = "Use available tools to calculate arc cosine of 0.5."
# 使用查询调用代理。代理将搜索其工具,
# 根据查询的语义选择'acos'工具并执行
result = agent.invoke({"messages": query})
# 格式化并显示代理执行的最终消息
format_messages(result['messages'])
┌────────────── Human ───────────────┐
│ Use available tools to calculate │
│ arc cosine of 0.5. │
└──────────────────────────────────────┘
┌────────────── 📝 AI ─────────────────┐
│ I will search for a tool to calculate│
│ the arc cosine of 0.5. │
│ │
│ 🔧 Tool Call: retrieve_tools │
│ Args: { │
│ "query": "arc cosine arccos │
│ inverse cosine trig" │
│ } │
└──────────────────────────────────────┘
┌────────────── 🔧 Tool Output ────────┐
│ Available tools: ['acos', 'acosh'] │
└──────────────────────────────────────┘
┌────────────── 📝 AI ─────────────────┐
│ Perfect! I found the `acos` function │
│ which calculates the arc cosine. │
│ Now I will use it to calculate the │
│ arc │
│ cosine of 0.5. │
│ │
│ 🔧 Tool Call: acos │
│ Args: { "x": 0.5 } │
│ └──────────────────────────────────────┘
┌────────────── 🔧 Tool Output ────────┐
│ 1.0471975511965976 │
└──────────────────────────────────────┘
┌────────────── 📝 AI ─────────────────┐
│ The arc cosine of 0.5 is ≈**1.047** │
│ radians. │
│ │
│ ✔ Check: cos(π/3)=0.5, π/3≈1.047 rad │
│ (60°). │
└──────────────────────────────────────┘可以观察到AI代理如何高效地调用正确的工具。
基于上下文工程的RAG系统实现
RAG(检索增强生成)是一个复杂的技术领域,代码代理系统代表了生产环境中代理式RAG的最佳实践案例。
在实际应用中,RAG往往是上下文工程面临的核心技术挑战。正如Windsurf的Varun所指出的:索引处理不等同于上下文检索。基于抽象语法树(AST)分块的嵌入搜索在小规模代码库中表现良好,但随着代码库规模增长会出现性能衰减。我们需要混合检索策略:结合grep模式搜索、文件搜索、知识图谱链接以及基于相关性的重新排序技术。
LangGraph框架提供了丰富的教程和视频资源,帮助开发者将RAG技术集成到代理系统中。通常的做法是构建一个检索工具,该工具可以使用上述任何RAG技术组合。
为了演示这一过程,我们将使用Lilian Weng优秀技术博客中的最新文章为RAG系统获取文档数据。
首先使用
WebBaseLoader工具获取页面内容:
# 导入WebBaseLoader用于从URL获取文档
from langchain_community.document_loaders import WebBaseLoader
# 定义Lilian Weng博客文章的URL列表
urls = [
"https://lilianweng.github.io/posts/2025-05-01-thinking/",
"https://lilianweng.github.io/posts/2024-11-28-reward-hacking/",
"https://lilianweng.github.io/posts/2024-07-07-hallucination/",
"https://lilianweng.github.io/posts/2024-04-12-diffusion-video/",
]
# 使用列表推导式从指定URL加载文档
# 为每个URL创建WebBaseLoader实例并调用其load()方法
docs = [WebBaseLoader(url).load() for url in urls]RAG系统中存在多种数据分块策略,适当的分块技术对于实现有效检索至关重要。
在本实现中,我们将在索引获取的文档到向量存储之前,将其分割为较小的片段。我们采用递归分块技术配合重叠片段的直接方法,在保持片段可管理性的同时,在片段之间保留上下文连续性,以优化嵌入和检索效果:
# 导入用于文档分块的文本分割器
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 展平文档列表。WebBaseLoader为每个URL返回文档列表,
# 因此得到嵌套列表结构。此推导式将其合并为单一列表
docs_list = [item for sublist in docs for item in sublist]
# 初始化文本分割器。该工具将文档分割为指定大小的较小片段,
# 片段间保持一定重叠以维持上下文连续性
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=2000, chunk_overlap=50
)
# 将文档分割为片段
doc_splits = text_splitter.split_documents(docs_list)完成文档分割后,可以将其索引到向量存储中进行语义搜索:
# 导入创建内存向量存储所需的类
from langchain_core.vectorstores import InMemoryVectorStore
# 从文档片段创建内存向量存储
# 使用前面创建的'doc_splits'和之前初始化的'embeddings'模型
# 生成文本片段的向量表示
vectorstore = InMemoryVectorStore.from_documents(
documents=doc_splits, embedding=embeddings
)
# 从向量存储创建检索器
# 检索器提供基于查询搜索相关文档的接口
retriever = vectorstore.as_retriever()接下来需要创建一个可在代理中使用的检索器工具:
# 导入创建检索器工具的函数
from langchain.tools.retriever import create_retriever_tool
# 从向量存储检索器创建检索器工具
# 该工具使代理能够基于查询从博客文章中搜索和检索相关文档
retriever_tool = create_retriever_tool(
retriever,
"retrieve_blog_posts",
"Search and return information about Lilian Weng blog posts.",
)
# 以下代码演示了直接调用工具的方法
# 虽然对代理执行流程非必需,但对测试很有用
# retriever_tool.invoke({"query": "types of reward hacking"})现在可以实现一个能够从工具中选择上下文的代理系统:
# 使用工具增强LLM功能
tools = [retriever_tool]
tools_by_name = {tool.name: tool for tool in tools}
llm_with_tools = llm.bind_tools(tools)对于基于RAG的解决方案,需要创建清晰的系统提示来指导代理行为。该提示充当核心指令集:
from langgraph.graph import MessagesState
from langchain_core.messages import SystemMessage, ToolMessage
from typing_extensions import Literal
rag_prompt = """您是一个专门从Lilian Weng技术博客文章系列中检索信息的智能助手。
在使用检索工具收集上下文之前,请与用户明确研究范围。对获取的任何上下文内容进行分析,
并持续检索直到获得足够的上下文信息来回答用户的研究请求。"""接下来定义图的核心节点。需要两个主要节点:
llm_call作为代理的决策中心,接收当前对话历史(用户查询加先前工具输出),然后决定下一步行动------调用工具或生成最终答案;
tool_node作为代理的执行组件,执行
llm_call请求的工具调用,并将工具结果返回给代理。
# --- 定义代理节点 ---
def llm_call(state: MessagesState):
"""LLM决策是否调用工具或生成最终答案"""
# 将系统提示添加到当前消息状态
messages_with_prompt = [SystemMessage(content=rag_prompt)] + state["messages"]
# 使用增强消息列表调用LLM
response = llm_with_tools.invoke(messages_with_prompt)
# 返回LLM响应以添加到状态
return {"messages": [response]}
def tool_node(state: dict):
"""执行工具调用并返回观察结果"""
# 获取包含工具调用的最后一条消息
last_message = state["messages"][-1]
# 执行每个工具调用并收集结果
result = []
for tool_call in last_message.tool_calls:
tool = tools_by_name[tool_call["name"]]
observation = tool.invoke(tool_call["args"])
result.append(ToolMessage(content=str(observation), tool_call_id=tool_call["id"]))
# 将工具输出作为消息返回
return {"messages": result}需要一种方法来控制代理流程,决定应该调用工具还是已完成任务。为此创建条件边函数
should_continue:该函数检查LLM的最后一条消息是否包含工具调用;如果包含,图路由到
tool_node;否则执行结束。
# --- 定义条件边 ---
def should_continue(state: MessagesState) -> Literal["Action", END]:
"""根据LLM是否进行工具调用决定下一步"""
last_message = state["messages"][-1]
# 如果LLM进行了工具调用,路由到tool_node
if last_message.tool_calls:
return "Action"
# 否则结束工作流
return END现在可以构建工作流并编译图:
# 构建工作流
agent_builder = StateGraph(MessagesState)
# 添加节点
agent_builder.add_node("llm_call", llm_call)
agent_builder.add_node("environment", tool_node)
# 添加连接节点的边
agent_builder.add_edge(START, "llm_call")
agent_builder.add_conditional_edges(
"llm_call",
should_continue,
{
# should_continue返回的名称 : 下一个访问节点的名称
"Action": "environment",
END: END,
},
)
agent_builder.add_edge("environment", "llm_call")
# 编译代理
agent = agent_builder.compile()
# 显示代理结构
display(Image(agent.get_graph(xray=True).draw_mermaid_png()))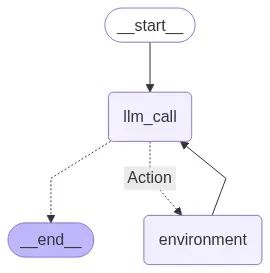
图结构显示了清晰的循环流程:代理启动并调用LLM;基于LLM的决策,系统要么执行动作(调用检索器工具)并循环回来,要么完成执行并提供答案。
让我们测试RAG代理。我们将询问关于"奖励破解"的具体问题,该问题只能通过从索引的博客文章中检索信息来回答:
# 定义用户查询
query = "What are the types of reward hacking discussed in the blogs?"
# 使用查询调用代理
result = agent.invoke({"messages": [("user", query)]})
# --- 显示最终消息 ---
# 格式化并打印对话流程
format_messages(result['messages'])
┌────────────── Human ───────────────┐
│ Clarify scope: I want types of │
│ reward hacking from Lilian Weng's │
│ blog on RL. │
└──────────────────────────────────────┘
┌────────────── 📝 AI ─────────────────┐
│ Fetching context from her posts... │
└──────────────────────────────────────┘
┌────────────── 🔧 Tool Output ────────┐
│ She lists 3 main types of reward │
│ hacking in RL: │
└──────────────────────────────────────┘
┌────────────── 📝 AI ─────────────────┐
│ 1. **Spec gaming** -- Exploit reward │
│ loopholes, not real goal. │
│ │
│ 2. **Reward tampering** -- Change or │
│ hack reward signals. │
│ │
│ 3. **Wireheading** -- Self-stimulate │
│ reward instead of task. │
└──────────────────────────────────────┘
┌────────────── 📝 AI ─────────────────┐
│ These can cause harmful, unintended │
│ behaviors in RL agents. │
└──────────────────────────────────────┘如结果所示,代理正确识别出需要使用检索工具,然后成功从博客文章中检索相关上下文,并基于该信息提供了详细而准确的答案。这完美展示了通过RAG实现的上下文工程如何创建强大而知识渊博的代理系统。
知识型代理的压缩策略优化
代理交互过程可能跨越数百轮对话并涉及令牌密集型工具调用。总结技术是管理这种复杂性的常用方法。
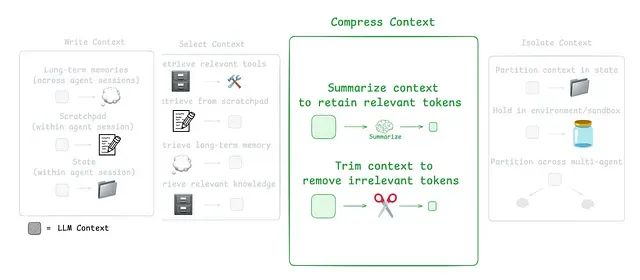
具体应用案例包括:Claude Code在上下文窗口超过95%容量时使用"自动压缩"功能,对整个用户-代理交互历史进行总结;总结技术可以使用递归或分层总结等策略来压缩代理执行轨迹。
开发者还可以在特定节点添加总结功能:在令牌密集型工具调用之后(例如搜索工具执行后);在代理间边界处进行知识转移,如Cognition在Devin中使用微调模型执行的操作。
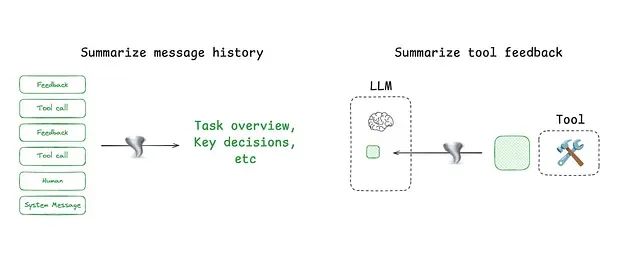
LangGraph作为低级编排框架,为开发者提供全面控制能力:将代理设计为节点集合;在每个节点内明确定义逻辑;在节点间传递共享状态对象。
这种架构使得以不同方式压缩上下文变得简单直接。例如,开发者可以使用消息列表作为代理状态,并利用内置工具对其进行总结。
我们将基于之前编码的RAG工具调用代理,添加对话历史总结功能。
首先需要扩展图状态以包含最终总结字段:
# 定义包含总结字段的扩展状态
class State(MessagesState):
"""包含用于上下文压缩的总结字段的扩展状态类"""
summary: str接下来定义专门用于总结的提示,同时保留之前的RAG提示:
# 定义总结提示
summarization_prompt = """请总结完整的聊天历史和所有工具反馈信息,
提供用户询问内容和代理执行操作的概要描述。"""现在创建
summary_node节点:该节点将在代理工作完成时被触发,生成整个交互过程的简洁总结;
llm_call和
tool_node保持不变。
def summary_node(state: MessagesState) -> dict:
"""
生成对话和工具交互的总结
参数:
state: 包含消息历史的图当前状态
返回值:
包含键"summary"和生成总结字符串的字典,用于更新状态
"""
# 将总结系统提示添加到消息历史前端
messages = [SystemMessage(content=summarization_prompt)] + state["messages"]
# 调用语言模型生成总结
result = llm.invoke(messages)
# 返回存储在状态'summary'字段中的总结
return {"summary": result.content}条件边
should_continue现在需要决定是调用工具还是继续到新的
summary_node:
def should_continue(state: MessagesState) -> Literal["Action", "summary_node"]:
"""根据LLM是否进行工具调用确定下一步骤"""
last_message = state["messages"][-1]
# 如果LLM进行了工具调用,执行工具
if last_message.tool_calls:
return "Action"
# 否则进行总结
return "summary_node"构建在末尾包含总结步骤的图结构:
# 构建RAG代理工作流
agent_builder = StateGraph(State)
# 向工作流添加节点
agent_builder.add_node("llm_call", llm_call)
agent_builder.add_node("Action", tool_node)
agent_builder.add_node("summary_node", summary_node)
# 定义工作流边
agent_builder.add_edge(START, "llm_call")
agent_builder.add_conditional_edges(
"llm_call",
should_continue,
{
"Action": "Action",
"summary_node": "summary_node",
},
)
agent_builder.add_edge("Action", "llm_call")
agent_builder.add_edge("summary_node", END)
# 编译代理
agent = agent_builder.compile()
# 显示代理工作流
display(Image(agent.get_graph(xray=True).draw_mermaid_png()))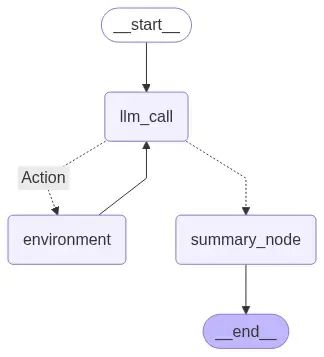
现在使用需要获取大量上下文的查询来测试系统:
from rich.markdown import Markdown
query = "Why does RL improve LLM reasoning according to the blogs?"
result = agent.invoke({"messages": [("user", query)]})
# 打印给用户的最终消息
format_message(result['messages'][-1])
# 打印生成的总结
Markdown(result["summary"])
#### 输出结果 ####
用户询问了为什么强化学习(RL)能够改进LLM推理...该实现效果良好,但消耗了115k个令牌!这是具有令牌密集型工具调用的代理系统面临的常见挑战。
更高效的方法是在上下文进入代理主要scratchpad之前进行压缩。让我们更新RAG代理以实时总结工具调用输出。
首先为这个特定任务创建新提示:
tool_summarization_prompt = """您将收到来自RAG系统的文档内容。
请总结这些文档,确保保留所有相关和关键信息。
您的目标是将文档大小(令牌数量)减少到更易管理的规模。"""接下来修改
tool_node以包含总结步骤:
def tool_node_with_summarization(state: dict):
"""执行工具调用然后总结输出"""
result = []
for tool_call in state["messages"][-1].tool_calls:
tool = tools_by_name[tool_call["name"]]
observation = tool.invoke(tool_call["args"])
# 总结文档内容
summary_msg = llm.invoke([
SystemMessage(content=tool_summarization_prompt),
("user", str(observation))
])
result.append(ToolMessage(content=summary_msg.content, tool_call_id=tool_call["id"]))
return {"messages": result}现在
should_continue边可以简化,因为不再需要最终的
summary_node:
def should_continue(state: MessagesState) -> Literal["Action", END]:
"""决定应该继续循环还是停止"""
if state["messages"][-1].tool_calls:
return "Action"
return END构建和编译这个更高效的代理:
# 构建工作流
agent_builder = StateGraph(MessagesState)
# 添加节点
agent_builder.add_node("llm_call", llm_call)
agent_builder.add_node("Action", tool_node_with_summarization)
# 添加连接节点的边
agent_builder.add_edge(START, "llm_call")
agent_builder.add_conditional_edges(
"llm_call",
should_continue,
{
"Action": "Action",
END: END,
},
)
agent_builder.add_edge("Action", "llm_call")
# 编译代理
agent = agent_builder.compile()
# 显示代理结构
display(Image(agent.get_graph(xray=True).draw_mermaid_png()))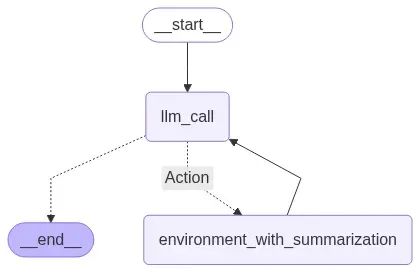
使用相同查询测试并观察差异:
query = "Why does RL improve LLM reasoning according to the blogs?"
result = agent.invoke({"messages": [("user", query)]})
format_messages(result['messages'])
┌────────────── user ───────────────┐
│ Why does RL improve LLM reasoning?│
│ According to the blogs? │
└───────────────────────────────────┘
┌────────────── 📝 AI ──────────────┐
│ Searching Lilian Weng's blog for │
│ how RL improves LLM reasoning... │
│ │
│ 🔧 Tool Call: retrieve_blog_posts │
│ Args: { │
│ "query": "Reinforcement Learning │
│ for LLM reasoning" │
│ } │
└───────────────────────────────────┘
┌────────────── 🔧 Tool Output ─────┐
│ Lilian Weng explains RL helps LLM │
│ reasoning by training on rewards │
│ for each reasoning step (Process- │
│ based Reward Models). This guides │
│ the model to think step-by-step, │
│ improving coherence and logic. │
└───────────────────────────────────┘
┌────────────── 📝 AI ──────────────┐
│ RL improves LLM reasoning by │
│ rewarding stepwise thinking via │
│ PRMs, encouraging coherent, │
│ logical argumentation over final │
│ answers. It helps the model self- │
│ correct and explore better paths. │
└───────────────────────────────────┘这次代理仅使用了60k个令牌。
这个简单的改进将令牌使用量减少了近一半,使代理系统更加高效和经济。
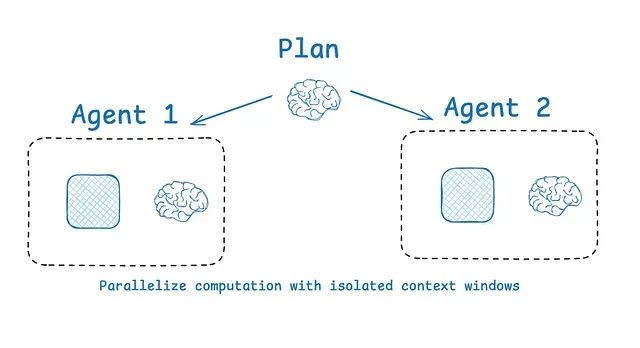
基于子代理架构的上下文隔离技术
隔离上下文的常见策略是将其分布到多个子代理中。OpenAI Swarm库专门为这种"关注点分离"架构设计,每个代理使用专属的工具、指令和上下文窗口来管理特定的子任务。
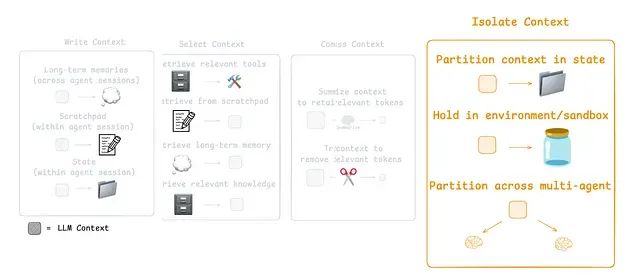
Anthropic的多代理研究系统显示,具有隔离上下文的多代理架构相比单代理系统性能提升90.2%,这是因为每个子代理专注于更窄的特定子任务。
子代理使用独立的上下文窗口并行操作,同时探索问题的不同方面。
然而,多代理系统面临一些技术挑战:令牌使用量显著增加(有时比单代理聊天多15倍的令牌消耗);需要精心设计的提示工程来规划子代理工作;协调子代理可能变得复杂。
LangGraph框架对多代理配置提供全面支持。常见的实现方法是监督者架构,这也是Anthropic多代理研究员采用的方案。监督者将任务委托给子代理,每个子代理在独立的上下文窗口中运行。
让我们构建一个管理两个专门代理的简单监督者系统:
math_expert处理数学计算任务,
research_expert负责搜索和提供研究信息。
监督者将根据查询内容决定调用哪个专家,并在LangGraph工作流中协调他们的响应:
from langgraph.prebuilt import create_react_agent
from langgraph_supervisor import create_supervisor
# --- 为每个代理定义专用工具 ---
def add(a: float, b: float) -> float:
"""执行两个数字的加法运算"""
return a + b
def multiply(a: float, b: float) -> float:
"""执行两个数字的乘法运算"""
return a * b
def web_search(query: str) -> str:
"""模拟网络搜索函数,返回FAANG公司员工数据"""
return (
"Here are the headcounts for each of the FAANG companies in 2024:\n"
"1. **Facebook (Meta)**: 67,317 employees.\n"
"2. **Apple**: 164,000 employees.\n"
"3. **Amazon**: 1,551,000 employees.\n"
"4. **Netflix**: 14,000 employees.\n"
"5. **Google (Alphabet)**: 181,269 employees."
)现在创建专门的代理和管理它们的监督者:
# --- 创建具有隔离上下文的专门代理 ---
math_agent = create_react_agent(
model=llm,
tools=[add, multiply],
name="math_expert",
prompt="您是数学专家。每次只使用一个工具执行计算。"
)
research_agent = create_react_agent(
model=llm,
tools=[web_search],
name="research_expert",
prompt="您是具有网络搜索能力的世界级研究专家。请不要执行数学运算。"
)
# --- 创建用于协调代理的监督者工作流 ---
workflow = create_supervisor(
[research_agent, math_agent],
model=llm,
prompt=(
"您是团队监督者,负责管理一个研究专家和一个数学专家。"
"请将任务委托给适当的代理来回答用户查询。"
"对于时事或事实性问题,使用research_agent。"
"对于数学问题,使用math_agent。"
)
)
# 编译多代理应用程序
app = workflow.compile()执行工作流并观察监督者如何委托任务:
# --- 执行多代理工作流 ---
result = app.invoke({
"messages": [
{
"role": "user",
"content": "what's the combined headcount of the FAANG companies in 2024?"
}
]
})
# 格式化并显示结果
format_messages(result['messages'])
┌────────────── user ───────────────┐
│ Learn more about LangGraph Swarm │
│ and multi-agent systems. │
└───────────────────────────────────┘
┌────────────── 📝 AI ──────────────┐
│ Fetching details on LangGraph │
│ Swarm and related resources... │
└───────────────────────────────────┘
┌────────────── 🔧 Tool Output ─────┐
│ **LangGraph Swarm** │
│ Repo: │
│ https://github.com/langchain-ai/ │
│ langgraph-swarm-py │
│ │
│ • Python library for multi-agent │
│ AI with dynamic collaboration. │
│ • Agents hand off control based │
│ on specialization, keeping │
│ conversation context. │
│ • Supports custom handoffs, │
│ streaming, memory, and human- │
│ in-the-loop. │
│ • Install: │
│ `pip install langgraph-swarm` │
└───────────────────────────────────┘
┌────────────── 🔧 Tool Output ─────┐
│ **Videos on multi-agent systems** │
│ 1. https://youtu.be/4nZl32FwU-o │
│ 2. https://youtu.be/JeyDrn1dSUQ │
│ 3. https://youtu.be/B_0TNuYi56w │
└───────────────────────────────────┘
┌────────────── 📝 AI ──────────────┐
│ LangGraph Swarm makes it easy to │
│ build context-aware multi-agent │
│ systems. Check videos for deeper │
│ insights on multi-agent behavior. │
└───────────────────────────────────┘在此案例中,监督者正确地为每个任务隔离了上下文------将研究查询分配给研究专家,将数学问题分配给数学专家------展示了有效的上下文隔离机制。
基于沙盒环境的隔离技术
HuggingFace的深度研究员展示了一种创新的上下文隔离方法。大多数代理使用工具调用API,这些API返回JSON格式的参数来运行搜索API等工具并获取结果。
HuggingFace采用CodeAgent技术,编写代码来调用工具。这些代码在安全沙盒中执行,代码运行结果被发送回LLM。
这种方法将大容量数据(如图像或音频)保持在LLM令牌限制之外。HuggingFace解释道:
代码代理允许更好的状态处理...需要稍后存储这个图像/音频/其他内容?只需将其保存为状态中的变量并稍后使用。
在LangGraph中使用沙盒技术非常简单。LangChain沙盒使用Pyodide(编译为WebAssembly的Python)安全地运行不受信任的Python代码。开发者可以将其作为工具添加到任何LangGraph代理中。
注意:需要安装Deno。安装地址:https://docs.deno.com/runtime/getting_started/installation/
from langchain_sandbox import PyodideSandboxTool
from langgraph.prebuilt import create_react_agent
# 创建具有网络访问权限的沙盒工具以支持包安装
tool = PyodideSandboxTool(allow_net=True)
# 使用沙盒工具创建ReAct代理
agent = create_react_agent(llm, tools=[tool])
# 使用沙盒执行数学查询
result = await agent.ainvoke(
{"messages": [{"role": "user", "content": "what's 5 + 7?"}]},
)
# 格式化并显示结果
format_messages(result['messages'])
┌────────────── user ───────────────┐
│ what's 5 + 7? │
└──────────────────────────────────┘
┌────────────── 📝 AI ──────────────┐
│ I can solve this by executing │
│ Python code in the sandbox. │
│ │
│ 🔧 Tool Call: pyodide_sandbox │
│ Args: { │
│ "code": "print(5 + 7)" │
│ } │
└──────────────────────────────────┘
┌────────────── 🔧 Tool Output ─────┐
│ 12 │
└──────────────────────────────────┘
┌────────────── 📝 AI ──────────────┐
│ The answer is 12. │
└──────────────────────────────────┘LangGraph中的状态隔离机制
代理的运行时状态对象提供了另一种优秀的上下文隔离方式,其工作原理类似于沙盒技术。开发者可以使用数据模式(如Pydantic模型)设计状态结构,该模式具有用于存储上下文的不同字段。
例如,一个字段(如
messages)在每轮交互中都向LLM展示,而其他字段保持信息隔离状态,直到需要时才暴露。
LangGraph围绕状态对象构建,使开发者能够创建自定义状态模式并在代理工作流中访问其字段。
例如,开发者可以将工具调用结果存储在特定字段中,使其对LLM保持隐藏状态,直到必要时才暴露。在本文的notebook示例中已经展示了许多这样的实现案例。
总结
通过本文的深入分析,我们系统性地探讨了基于LangChain和LangGraph的AI代理上下文工程优化技术:
我们利用LangGraph的
StateGraph创建了短期内存的"scratchpad"机制和长期内存的
InMemoryStore系统,使代理能够有效存储和检索信息。我们演示了如何从代理状态和长期内存中选择性提取相关信息,包括使用检索增强生成(RAG)技术来查找特定知识,以及利用
langgraph-bigtool从众多选项中选择合适的工具。
为了管理长对话和令牌密集型工具输出,实现了总结技术。展示了如何实时压缩RAG结果,使代理更高效并减少令牌消耗。
通过构建具有监督者架构的多代理系统来探索上下文分离技术,该系统将任务委托给专门的子代理,以及通过使用沙盒环境来运行代码。
这些技术统称为"上下文工程"------一种通过精心管理AI代理的工作内存(上下文)来改进AI代理性能的策略,使它们能够更高效、更准确地处理复杂的长期运行任务。
随着AI代理技术的不断发展,上下文工程将成为构建高性能、可扩展AI系统的关键技术基础。
https://avoid.overfit.cn/post/a7215af495254072bbc60fa09a9b4ba4
作者:Fareed Khan