作者:StormBlafe
在集群化 AI 算⼒设施的基础上,⼤模型的训练可以通过以下⼏种并⾏模式开展。
模型并⾏
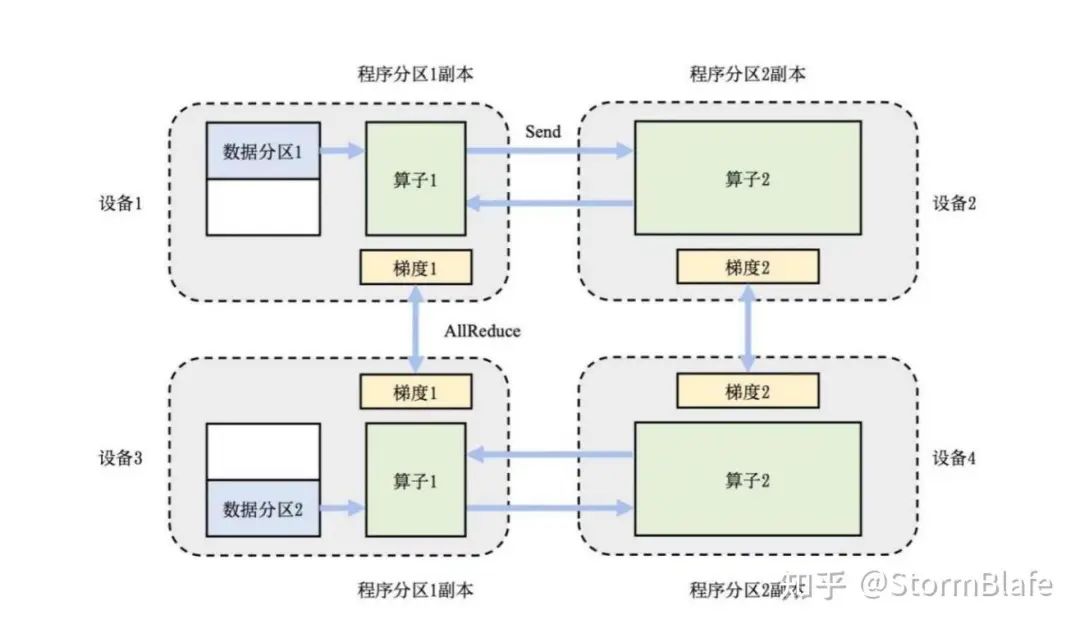
由于当前的⼤模型规模往往远超单个计算设备的内存容量,将⼤模型切分到多个设备上成为⼀种⾃然的选择。⼤模型从输⼊到输出由结构相似的算⼦层级连接堆叠⽽成,形成模型的深度;在每个层级上的计算通过众多并发的神经元节点运算实现,形成模型的宽度。相应的,模型可以在宽度和深度两个⽅向上进⾏切割。张量并⾏是宽度⽅向的切分,它基于矩阵运算分解的数学原理在模型的层内进⾏分割,形成的单个⼦模型跨越完整⼤模型的所有层级,但只包含每个层级的部分运算。流⽔线并⾏采取基于深度的切分,将⼤模型的不同层级拆解到各个计算设备并通过流⽔操作的⽅式形成各个层级运算的并发执⾏。相对于流⽔线并⾏中分布式数据交换主要发⽣在承载相邻层级的计算设备之间,张量并⾏中各个计算设备之间均产⽣⼤量的数据交换,对数据交换的带宽要求更⾼,所以主要应⽤在⼀机多卡的服务器节点内部的并发实现。
数据并⾏
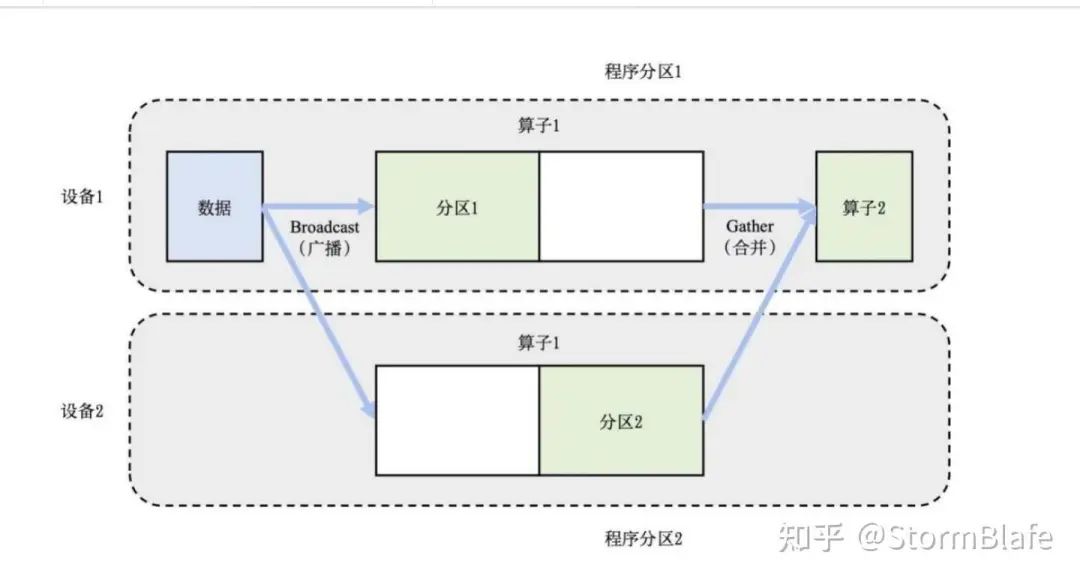
这种模式下,数据被拆散分配到位于不同计算设备上的模型实例来参加训练过程,设备相互之间定期地就训练所得的模型参数或者参数优化的梯度值进⾏同步,保证所有设备上的模型状态保持⼀致。数据并⾏⼀般要求每个设备上的训练实例储存和维护完整的模型参数和状态,所以并不能节省 AI 算⼒设备的内存开销。零冗余优化器(ZeRO - Zero Redundancy Optimizer)⽀持将模型的参数、梯度值和优化器状态划分到不同的进程,允许每个设备的训练实例只储存模型的⼀部分,在训练过程中每个训练实例动态地从其他设备通讯获取需要的模型参数和梯度值来完成本地的训练计算,从⽽极⼤提升数据并发模式下的内存使⽤效率。
混合并⾏
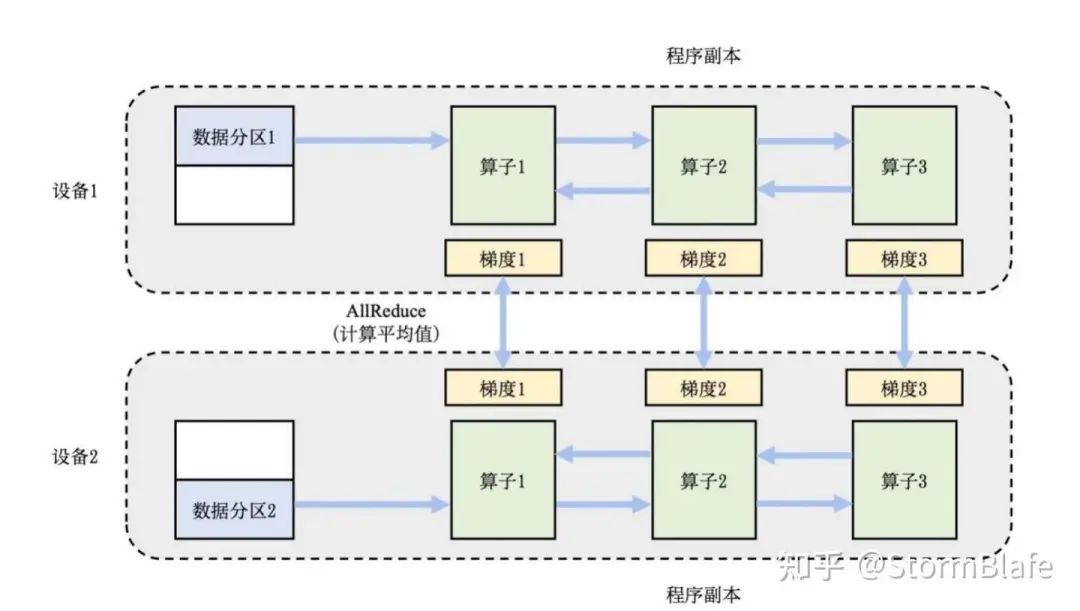
在实际应⽤中往往综合模型并⾏和数据并⾏等多种策略的组合,以充分利⽤多个维度的并⾏能⼒,实现取⻓补短。例如采取数据并⾏+流⽔线并⾏+张量并⾏的模式可以充分利⽤算⼒资源和通信带宽达到兼顾模型的内存扩展性和训练加速的⽬的。