文章目录
现在说起服务端,经常听到的就是分布式、集群、微服务这类词汇,这些到底是什么呢?又是如何而来的呢?本篇博客记录相关学习

前景概念
在认识上述架构之前,需要有些前景知识
应用(Application) / 系统(System)
应用是为了完整一整套服务的一个程序,而系统是一组互相配合的程序群。
类比生活中的篮球队,中锋、后卫、自由人都是一个个应用,有各自的功能,而他们相互配合组成的队伍就是一个系统,有强大的功能
模块(Module) / 组件(Conponent)
当应用功能复杂时,可以从中分离职责,将其中具有清晰职责、内聚性强的部分抽离出来,单独为一部分
类比军队将人员分为突击小组、爆破小组、掩护小组、通信等
分布式(Distributed)
系统中的多个模块可以被部署在不同的服务器上,模块之前通过网络进行通信,这样的系统就被称为分布式系统。
常见的有Web服务器和数据库分别工作在不同的服务器上,或者多个Web服务器部署在不同的服务器之上
集群(Cluster)
部署在多台服务器上的,为了实现特定目标的一个或多个组件,被称为集群
如多个MySQL工作在不同的服务器上,共同提供数据库服务
主(Master) / 从(Slave)
集群中,一般有一个程序需要承担更多的职责,称为主;其他承担附属职责的被称为从
比如MySQL集群中,外界只对一台主服务器上的MySQL进行操作(增/删/改),其他从服务器的MySQL只对主服务器作数据同步。当主服务器挂掉了,再找个从服务器顶上,变成主服务器
中间件(Middleware)
常常说"没有什么是加一层中间层解决不了的,如果有就再加一层 "
中间件就是互通不同技术、工具和数据库之间的桥梁,用于相互通信
架构演进
单机架构
单机架构即业务处理,数据存储都在一台服务器上,甚至单线程。此时用户访问量不大,没有对性能、安全提出很高的要求,而且系统架构简单,运维起来成本不大
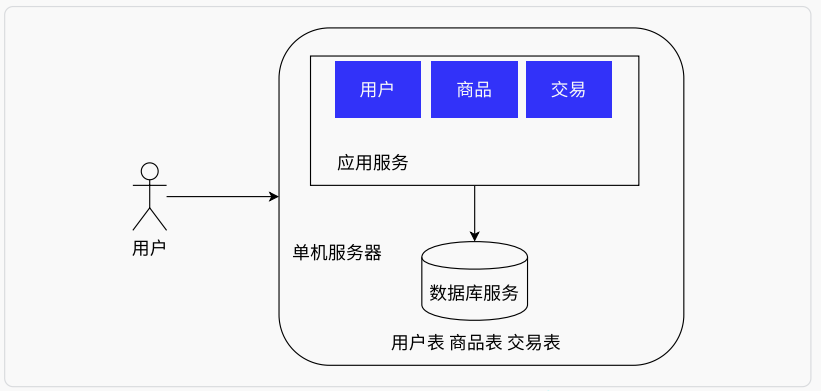
相关软件
Web服务器:Tomcat、Netty、Nginx、Apache等
数据库:MySQL、Oracle、PostgreSQL、SQL Server等
应用数据分离架构
数据持久化往往是比较耗时的,因为磁盘IO速度较慢,当系统的访问量逐步上升后,在业务处理的时候,不希望因为数据持久而拖慢了系统的性能,此时就可以把数据库服务独立出去,成为存储服务器,将业务和存储分离
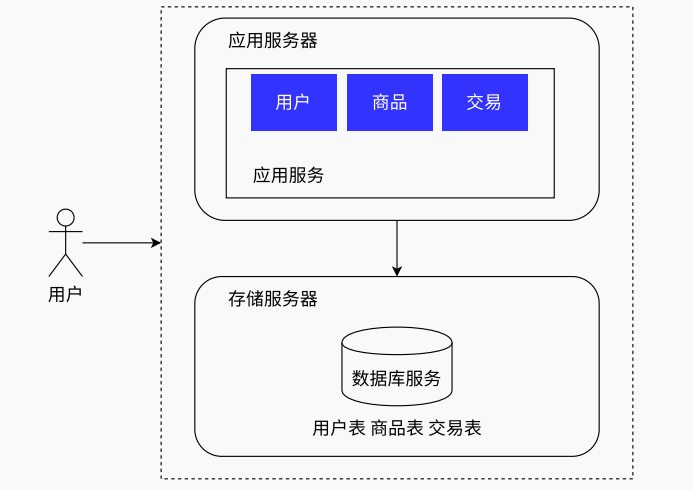
应用服务器通过网络访问存储服务器,虽然网络通信也比较慢,但比磁盘IO还是要快一些的,而且分离后,数据存储并不会影响应用服务器的业务处理
应用服务集群架构
当系统访问量再次上升后,可能单台应用服务器已经无法满足需求,此时有两种方案:
垂直扩展/ 纵向扩展 Scale Up:购买性能更优、价格更高的服务器水平扩展/ 横向扩展 Scale Out:调整软件架构,增加应用服务器,将用户流量分摊到不同的应用服务器
集群就是水平扩展的产物,有了多台服务器,还需要对用户流量进行分流,常见的方法有:
- Round-Robin 轮询算法:公平地将请求依次分给不同的应用服务器。优点是不会出现有服务器没有分摊到流量的情况;缺点就是性能好的服务器没有完全发挥性能,因为是公平分配给差的和好的
- Weight-Round-Robin 轮询算法:为不同的服务器(比如性能不同) 赋予不同的权重(weight),解决方法1的缺点。但新的缺点是同一用户的多个请求可能分配到不同的服务器
- 一致哈希散列算法 :通过计算用户的特征值(如IP地址)得到哈希值,根据哈希值做分发,这样同个用户的请求就可以被分配给同一个服务器。这就是专项客户经理服务
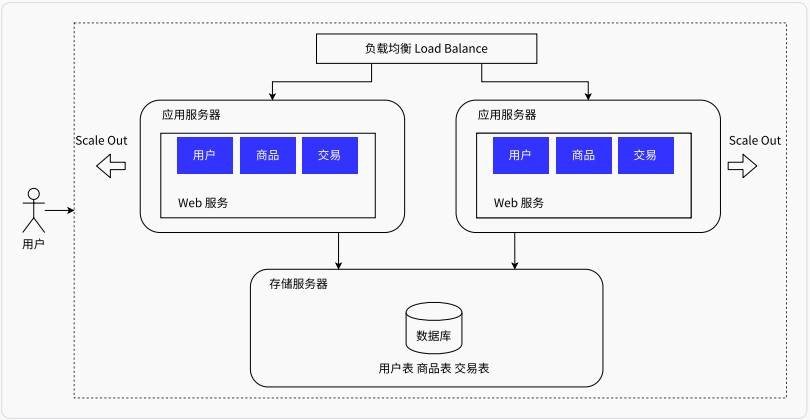
相关软件
负载均衡软件:Nginx、HAProxy、LVS、F5等
读写分离 / 主从分离架构
应用服务器扩展后,用户流量已经可以抗住了,但是数据库读写数据性能还不足以支撑,到一定程度后,数据的压力称为系统承载能力的瓶颈点。
如果像应用服务器一样进行纵向扩展,那么数据就会被分散,一致性无法保证。这就用到上述的主从思想了
保留一个主数据库作为写入数据库,其他从数据库同步主数据库数据。因为二八定律 :用户的操作20%是写,80%是读,写操作并不会那么频繁,所以可以将写数据请求全部交给主库处理 ,主库也一般是性能更强的服务器,读请求则分散到各个从库中,因为从库同步主库数据,所以也保证了一致性
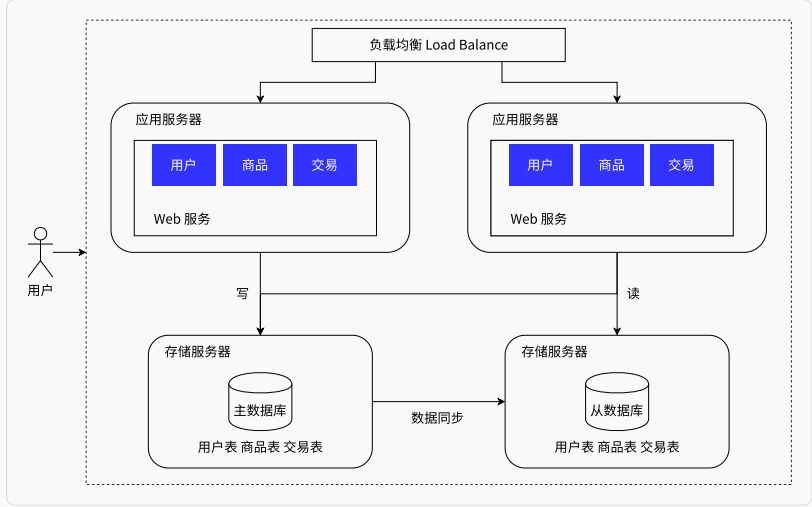
应用服务器需要对读写请求做分离处理,可以利用一些数据库中间件,将请求分离的职责托管出去
相关软件
MyCat、TDDL、Amoeba、Cobar等类似数据库中间件等
冷热分离架构
引入缓存
随着访问量继续增大,发现业务中一些数据的读取频率远大于其他数据的读取频率。这部分数据被称为热点数据,与之相对的是冷数据。
为了提取读取的响应时间,可以将这些数据缓存,如此还减少了磁盘的读取开销
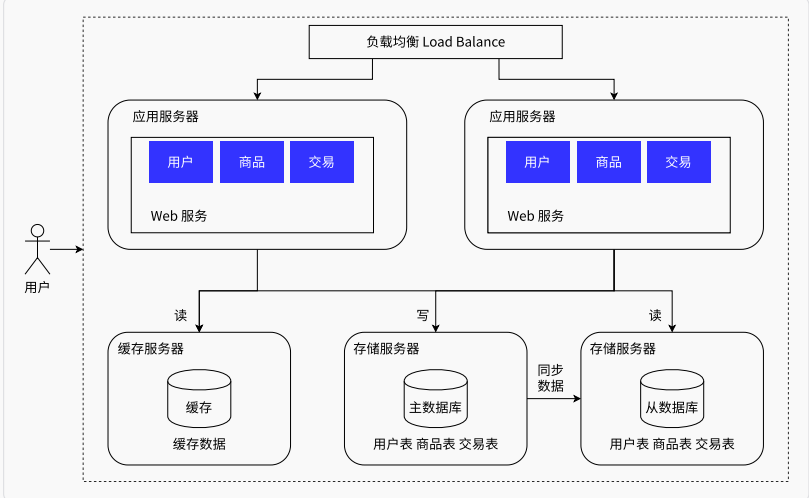
相关软件
Memcached、Redis等缓存软件
垂直分库
业务数据量再增大后,大量数据存储在同一个库中已经有些力不从心了,所以可以根据业务,对数据分别存储
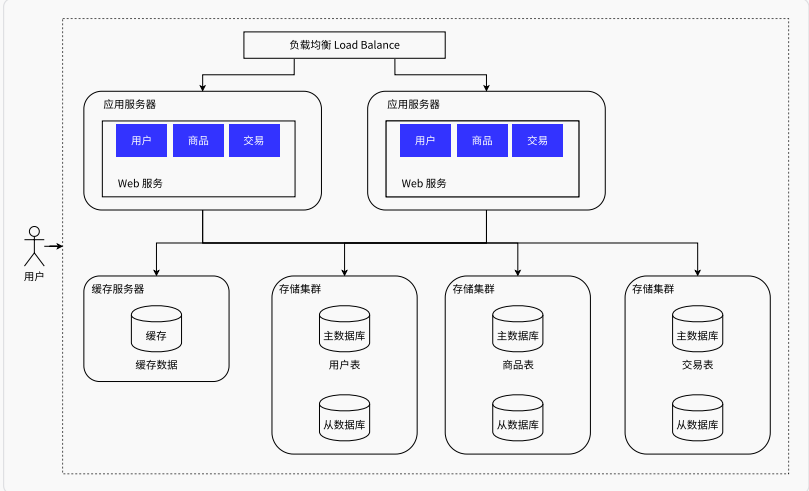
相关软件
Greenplum、TiDB、Postgresql XC、HAWQ等,商用的如南大通用的GBase、华为的LibrA
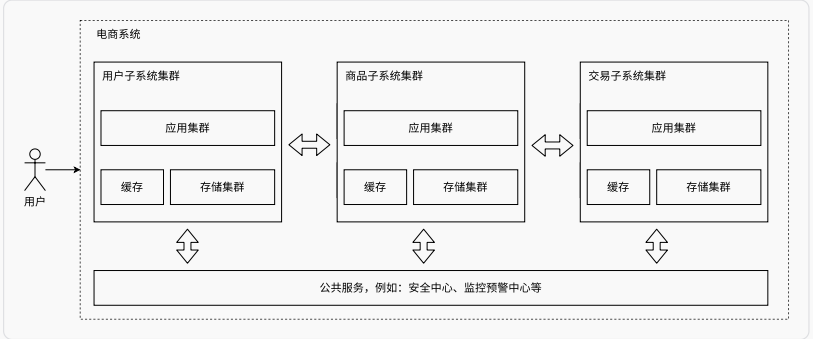
微服务
随着业务发展,可以将业务分给不同的开发团队去维护,每个团队独立实现自己的微服务,然后互相之间对数据的直接访问进行隔离
以上就是本篇博客的所有内容,感谢你的阅读
如果觉得本篇文章对你有所帮助的话,不妨点个赞支持一下博主,拜托啦,这对我真的很重要。
