04.数据预处理(与课程对应)
1、导入相关库
python
import os
import torch
import pandas as pd2、读取csv文件、对数据进行预处理,成为可以转成tensor张量的数据;下面创建一个人工数据集,并存储在csv(逗号分隔值)文件;创建目录为../data/house_tiny.csv(../代表上一级目录,即data/house_tiny.csv应该在此代码目录的上一级目录中会有data/目录)
python
os.makedirs(os.path.join('..', 'data'), exist_ok=True) # 使用 os.makedirs 函数创建目录,os.path.join('..', 'data') 用于拼接路径,这里是在当前目录的上一级目录中创建名为 data 的目录,exist_ok=True 表示如果该目录已经存在,不会抛出异常。
data_file = os.path.join('..', 'data', 'house_tiny.csv') # data_file = os.path.join('..', 'data', 'house_tiny.csv'):拼接文件路径,确定要操作的 CSV 文件的路径,该文件位于上一级目录的 data 目录下,文件名为 house_tiny.csv
with open(data_file, 'w') as f: # 以写入模式打开指定的 CSV 文件,with 语句确保文件在使用完后会正确关闭。
# 在 with 语句块中,通过 f.write 方法写入了 CSV 文件的表头 NumRooms, Alley, Price 以及几行数据,每行数据用逗号分隔不同的字段值,其中 NA 表示缺失值。
f.write('NumRooms, Alley, Price\n') # 列名
f.write('NA, Pave, 127500\n')
f.write('2, NA, 106000\n')
f.write('4, NA, 178100\n')
f.write('NA, NA, 140000\n')3、读取 csv 文件一般用 pandas库
python
data = pd.read_csv(data_file)
print("data:", data)运行结果:
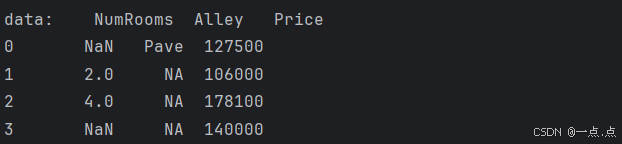
4、为了处理缺失的数据,典型的方法包括 插值 和 删除,这里,使用插值
python
inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2] # 用iloc把所有行、第0与1列拿出来放到inputs;用iloc把所有行、第2列拿出来放到outputs
inputs = inputs.fillna(inputs.mean()) # 用fillna对inputs中所有NA填一个值,填mean均值;NumRooms中的 NA 填为均值3.0;Alley是字符串,没有均值所以NA没变
print("inputs:", inputs)运行结果:

5、 对于inputs中的类别值或离散值,我们将"NAN"视为一个类别;缺失值也是一种值,把它变为数值;以及对于字符串的处理;把这一列里面所有出现的不同种类的数值都变成一个特征(Alley有两类值Pave、NA,那就创建2类)
python
inputs = pd.get_dummies(inputs, dummy_na=True) # 创建两类后对应复制1、0
print("inputs:", inputs)运行结果:
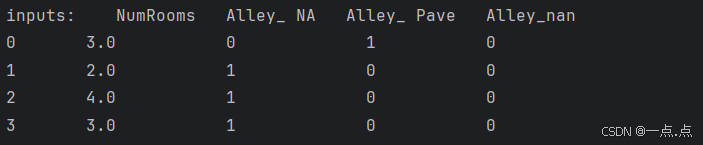
6、现在 inputs 和 outputs 中的所有条目都是数值类型,它们可以转换为tensor张量格式
python
x, y = torch.tensor(inputs.values), torch.tensor(outputs.values)
print("x:", x, "\ny:", y)运行结果:

7、完整代码:
python
import os
import torch
import pandas as pd
# 读取csv文件、对数据进行预处理,成为可以转成tensor张量的数据
# 创建一个人工数据集,并存储在csv(逗号分隔值)文件
os.makedirs(os.path.join('..', 'data'), exist_ok=True) # 使用 os.makedirs 函数创建目录,os.path.join('..', 'data') 用于拼接路径,这里是在当前目录的上一级目录中创建名为 data 的目录,exist_ok=True 表示如果该目录已经存在,不会抛出异常。
data_file = os.path.join('..', 'data', 'house_tiny.csv') # data_file = os.path.join('..', 'data', 'house_tiny.csv'):拼接文件路径,确定要操作的 CSV 文件的路径,该文件位于上一级目录的 data 目录下,文件名为 house_tiny.csv
with open(data_file, 'w') as f: # 以写入模式打开指定的 CSV 文件,with 语句确保文件在使用完后会正确关闭。
# 在 with 语句块中,通过 f.write 方法写入了 CSV 文件的表头 NumRooms, Alley, Price 以及几行数据,每行数据用逗号分隔不同的字段值,其中 NA 表示缺失值。
f.write('NumRooms, Alley, Price\n') # 列名
f.write('NA, Pave, 127500\n')
f.write('2, NA, 106000\n')
f.write('4, NA, 178100\n')
f.write('NA, NA, 140000\n')
# 读取 csv 文件一般用 pandas库
data = pd.read_csv(data_file)
print("--------------------data--------------------")
print("data:", data)
# 为了处理缺失的数据,典型的方法包括 插值 和 删除,这里,使用插值
inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2] # 用iloc把所有行、第0与1列拿出来放到inputs;用iloc把所有行、第2列拿出来放到outputs
inputs = inputs.fillna(inputs.mean()) # 用fillna对inputs中所有NA填一个值,填mean均值;NumRooms中的 NA 填为均值3.0;Alley是字符串,没有均值所以NA没变
print("--------------------inputs1--------------------")
print("inputs:", inputs)
# 对于inputs中的类别值或离散值,我们将"NAN"视为一个类别;缺失值也是一种值,把它变为数值;以及对于字符串的处理;把这一列里面所有出现的不同种类的数值都变成一个特征(Alley有两类值Pave、NA,那就创建2类)
inputs = pd.get_dummies(inputs, dummy_na=True) # 创建两类后对应复制1、0
print("--------------------inputs2--------------------")
print("inputs:", inputs)
# 现在 inputs 和 outputs 中的所有条目都是数值类型,它们可以转换为tensor张量格式
x, y = torch.tensor(inputs.values), torch.tensor(outputs.values)
print("--------------------x、y--------------------")
print("x:", x, "\ny:", y)如果此文章对您有所帮助,那就请点个赞吧,收藏+关注 那就更棒啦,十分感谢!!!