今天凌晨,阿里通义团队正式发布了 Qwen3,涵盖六款 Dense 模型(0.6B、1.7B、4B、8B、14B、32B)和两款 MoE 模型(30B-A3B 和 235B-A22B)。其中的旗舰模型 Qwen3-235B-A22B 在代码、数学、通用能力等基准测试中,与 DeepSeek-R1、o1、o3-mini、Grok-3 和 Gemini-2.5-Pro 等顶级模型相比,表现出了强大的竞争力。小型 MoE 模型 Qwen3-30B-A3B 的激活参数是 QwQ-32B 的 10%,但表现更胜一筹,由于激活参数少,推理速度更快。甚至像 Qwen3-4B 这样的小模型也能匹敌 Qwen2.5-72B-Instruct 的性能。
GPUStack 在上周发布了 v0.6 版本,内置支持了 Qwen3。其中 NVIDIA 支持 vLLM 和 llama-box 运行,AMD、Apple Silicon、昇腾、海光、摩尔线程支持 llama-box 运行。今天一早,社区群的各位小伙伴已经开始在各种尝试 Qwen3,我们也带来一篇挑战 45 分钟从零搭建私有 MaaS 平台和生产级的 Qwen3 模型服务的文章,快速搭建和体验 Qwen3 模型。
GPUStack 是一个100%开源的模型服务平台 ,支持 Linux、Windows 和 macOS ,支持 NVIDIA、AMD、Apple Silicon、昇腾、海光、摩尔线程 等 GPU 构建异构 GPU 集群 ,支持 LLM、多模态、Embedding、Reranker、图像生成、Speech-to-Text 和 Text-to-Speech 模型,支持 vLLM、MindIE、llama-box (基于 llama.cpp 与 stable-diffusion.cpp )等多种推理引擎与推理引擎多版本并行 ,支持资源自动调度分配、模型故障自动恢复、多机分布式推理、混合异构推理、推理请求负载均衡、资源与模型监控指标观测、国产化支持、用户管理与 API 认证授权等各种企业级特性 ,提供 OpenAI 兼容 API 无缝接入 Dify、RAGFlow、FastGPT、MaxKB 等各种上层应用框架,是企业建设模型服务平台的理想选择。
本篇文章将介绍在一节课 45 分钟内(包括安装和模型下载)搭建 GPUStack 模型服务平台并通过 GPUStack 运行生产级的 Qwen3 模型服务。
计时开始:

前置准备
以下操作环境为一台阿里云 ECS 云主机,操作系统为
Ubuntu 22.04,GPU 为 NVIDIA A10,操作依赖良好的网络条件。其他操作系统的安装参考每个章节的文档链接。
验证当前环境的 NVIDIA GPU 硬件:
shell
lspci | grep -i nvidia验证系统已安装 GCC:
shell
gcc --version安装 NVIDIA 驱动
参考:https://developer.nvidia.com/datacenter-driver-downloads
为当前内核安装内核头文件和开发包:
shell
sudo apt-get update && sudo apt-get install linux-headers-$(uname -r)安装 cuda-keyring 包:
shell
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb安装 NVIDIA 驱动:
shell
sudo apt-get update && sudo apt-get install nvidia-open -y重启系统:
shell
sudo reboot重新登录并检查 nvidia-smi 命令可用:
shell
nvidia-smi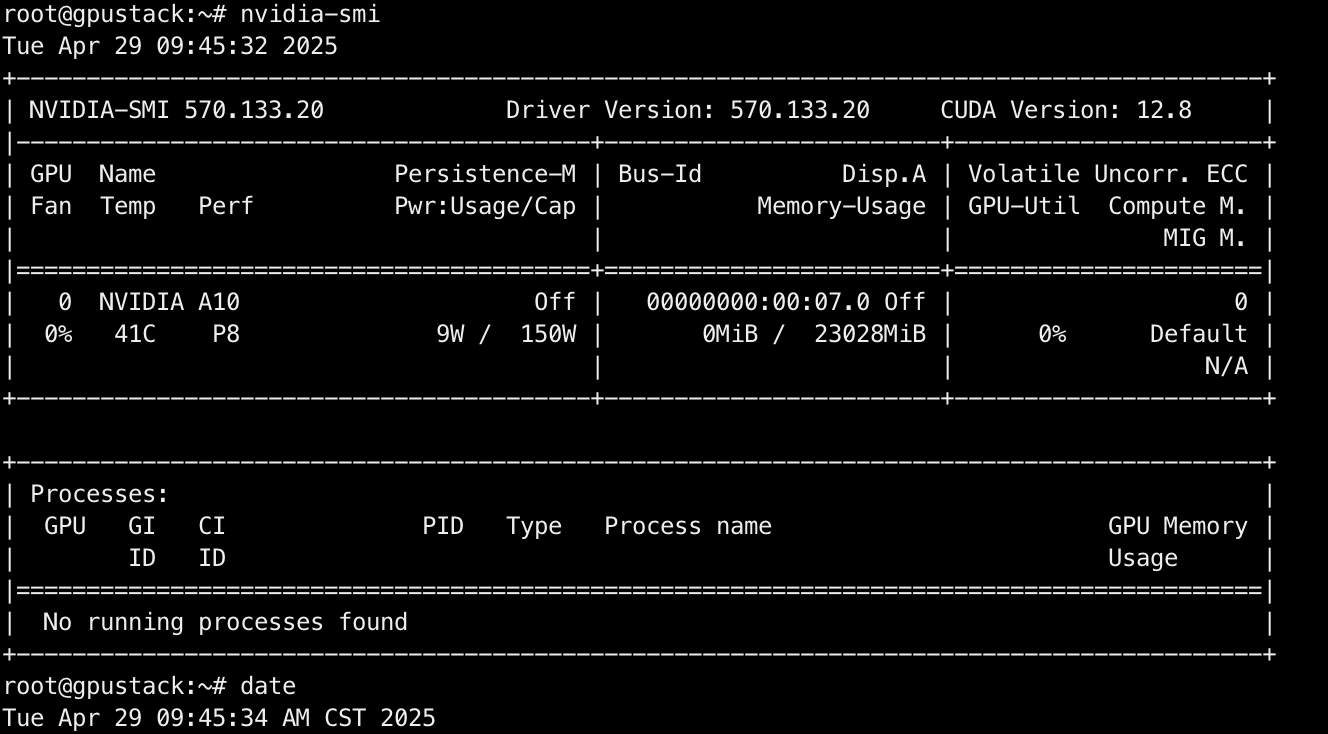
耗时:3m
安装 Docker Engine
参考:https://docs.docker.com/engine/install/ubuntu/
执行以下命令卸载所有冲突的包:
shell
for pkg in docker.io docker-doc docker-compose docker-compose-v2 podman-docker containerd runc; do sudo apt-get remove $pkg; done设置 Docker 的 apt 仓库:
shell
# Add Docker's official GPG key:
sudo apt-get update
sudo apt-get install ca-certificates curl -y
sudo install -m 0755 -d /etc/apt/keyrings
sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
sudo chmod a+r /etc/apt/keyrings/docker.asc
# Add the repository to Apt sources:
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update安装 Docker:
shell
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin -y检查 docker 命令可用:
shell
sudo docker info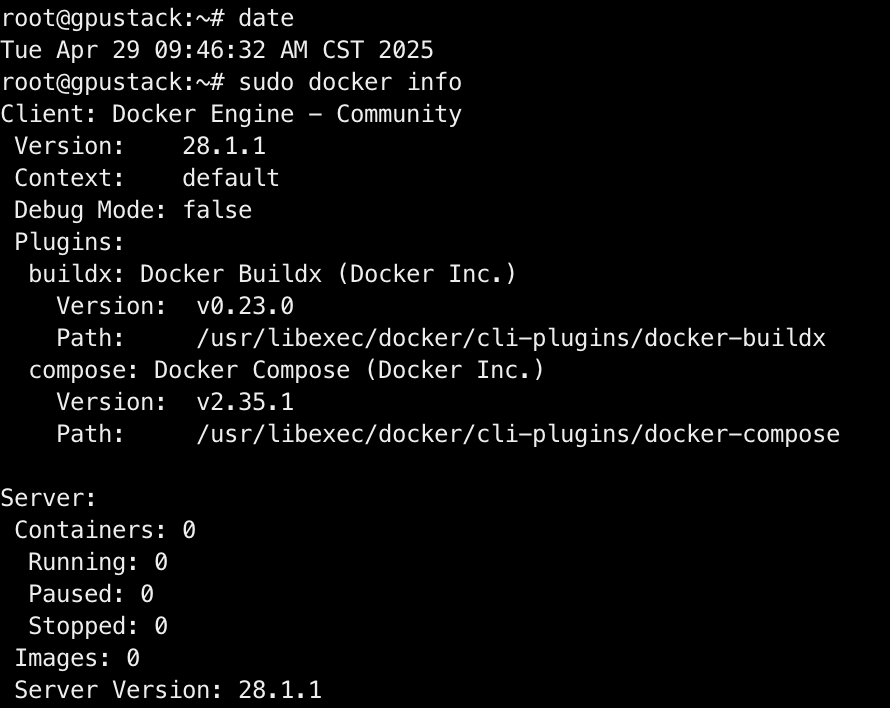
耗时:1m
安装 NVIDIA Container Toolkit
参考:https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html
配置 NVIDIA Container Toolkit 的生产仓库:
shell
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list安装 NVIDIA Container Toolkit:
shell
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit使用 nvidia-ctk 命令配置容器运行时:
shell
sudo nvidia-ctk runtime configure --runtime=docker检查 daemon.json 文件的配置:
shell
vim /etc/docker/daemon.json加入 "exec-opts": ["native.cgroupdriver=cgroupfs"] 配置,避免NVIDIA Container Toolkit 的 Failed to initialize NVML: Unknown Error 容器掉卡问题(参考:https://docs.gpustack.ai/latest/installation/nvidia-cuda/online-installation/#prerequisites_1):
json
{
"runtimes": {
"nvidia": {
"args": [],
"path": "nvidia-container-runtime"
}
},
"exec-opts": ["native.cgroupdriver=cgroupfs"]
}重启 Docker daemon:
shell
sudo systemctl restart docker检查 NVIDIA Container Runtime 配置是否生效:
shell
docker info | grep -i runtime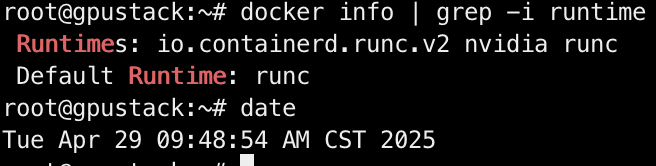
耗时:1.5m
安装 GPUStack
参考:https://docs.gpustack.ai/latest/installation/nvidia-cuda/online-installation/
通过 Docker 安装 GPUStack:
shell
docker run -d --name gpustack \
--restart=unless-stopped \
--gpus all \
--network=host \
--ipc=host \
-v gpustack-data:/var/lib/gpustack \
swr.cn-north-9.myhuaweicloud.com/gpustack/gpustack:v0.6.0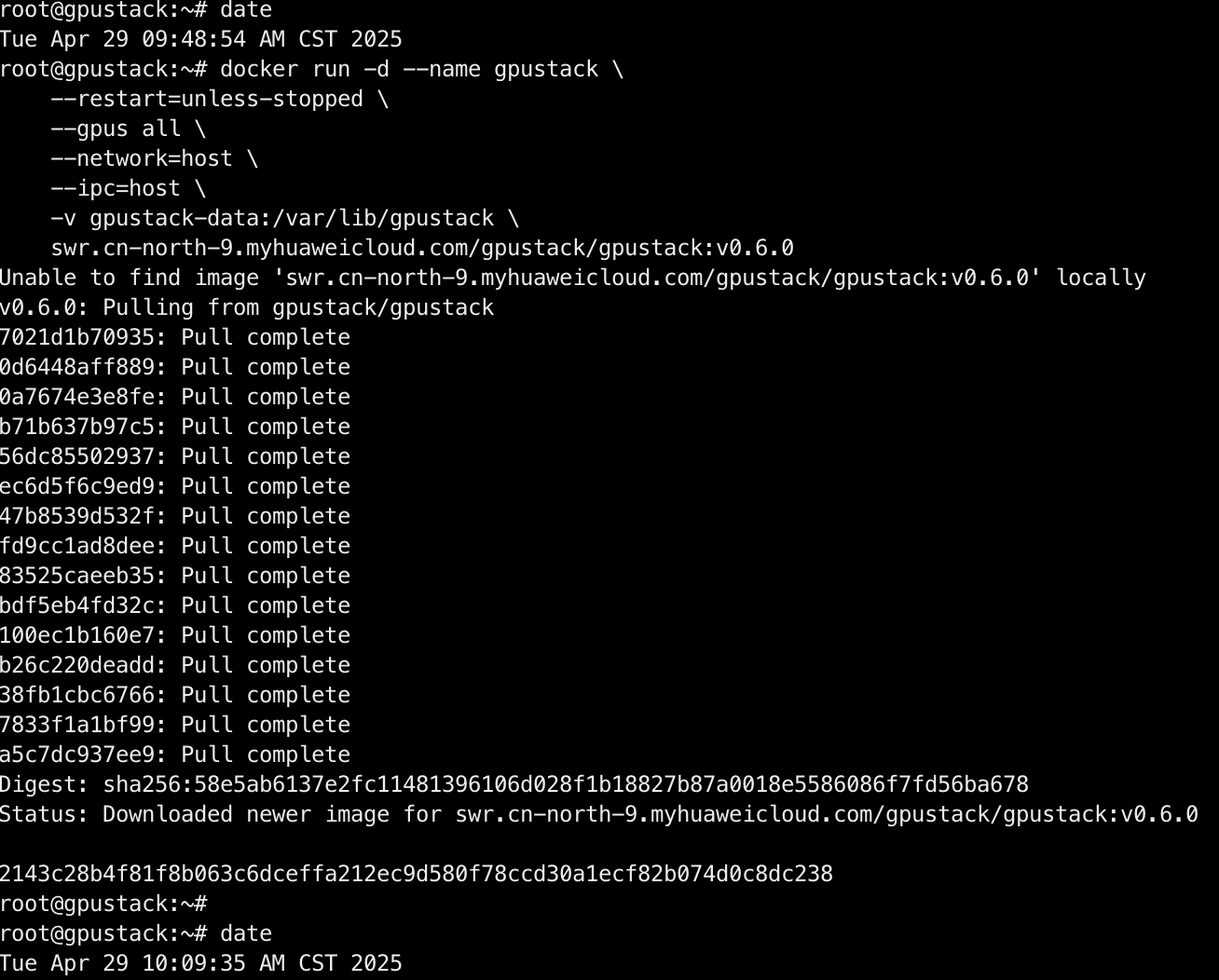
耗时:20m40s
检查服务启动:
shell
docker logs -f gpustack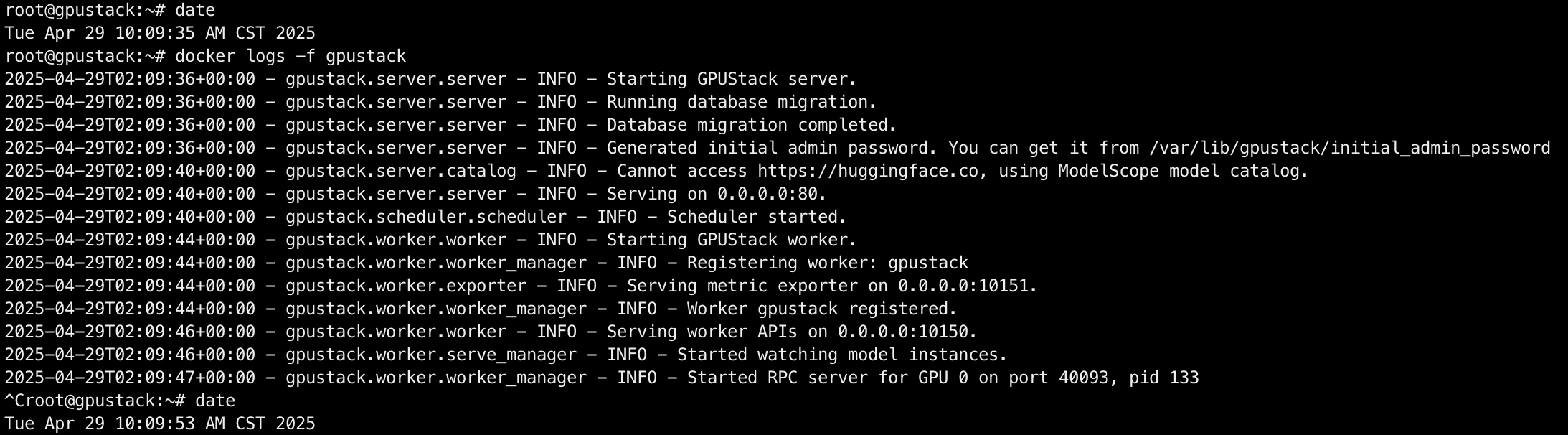
耗时:20s
使用以下命令查看登录密码:
shell
docker exec -it gpustack cat /var/lib/gpustack/initial_admin_password在浏览器访问 GPUStack( http://YOUR_HOST_IP )以用户名 admin 和密码登录。设置密码后,登录进 GPUStack,查看识别到的 GPU 资源:
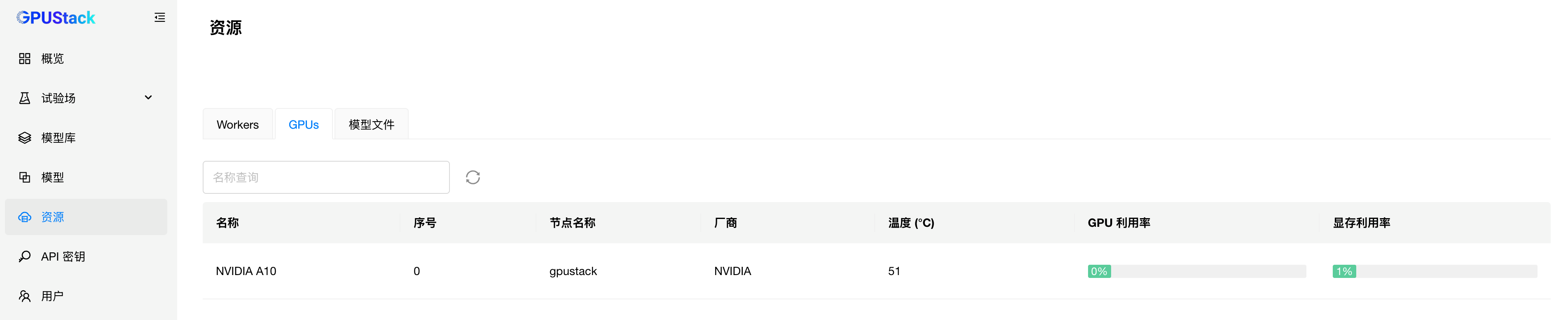
GPUStack 支持添加更多的 Worker 节点构建 GPU 集群,本文章不需要该部分,省略,有需要的参考上方的 GPUStack 官方安装文档。
部署 Qwen3
访问 模型 菜单,选择部署模型 - ModelScope,在 ModelScope 中搜索 Qwen 官方的 Qwen3 模型仓库,我们的 GPU 是 NVIDIA A10,24G显存。这里我们部署号称能匹敌 Qwen2.5-72B-Instruct 性能的 Qwen3-4B 模型:
考虑需要部署生产级的 Qwen3 模型服务,因此使用 vLLM 后端来运行 Qwen3 模型:
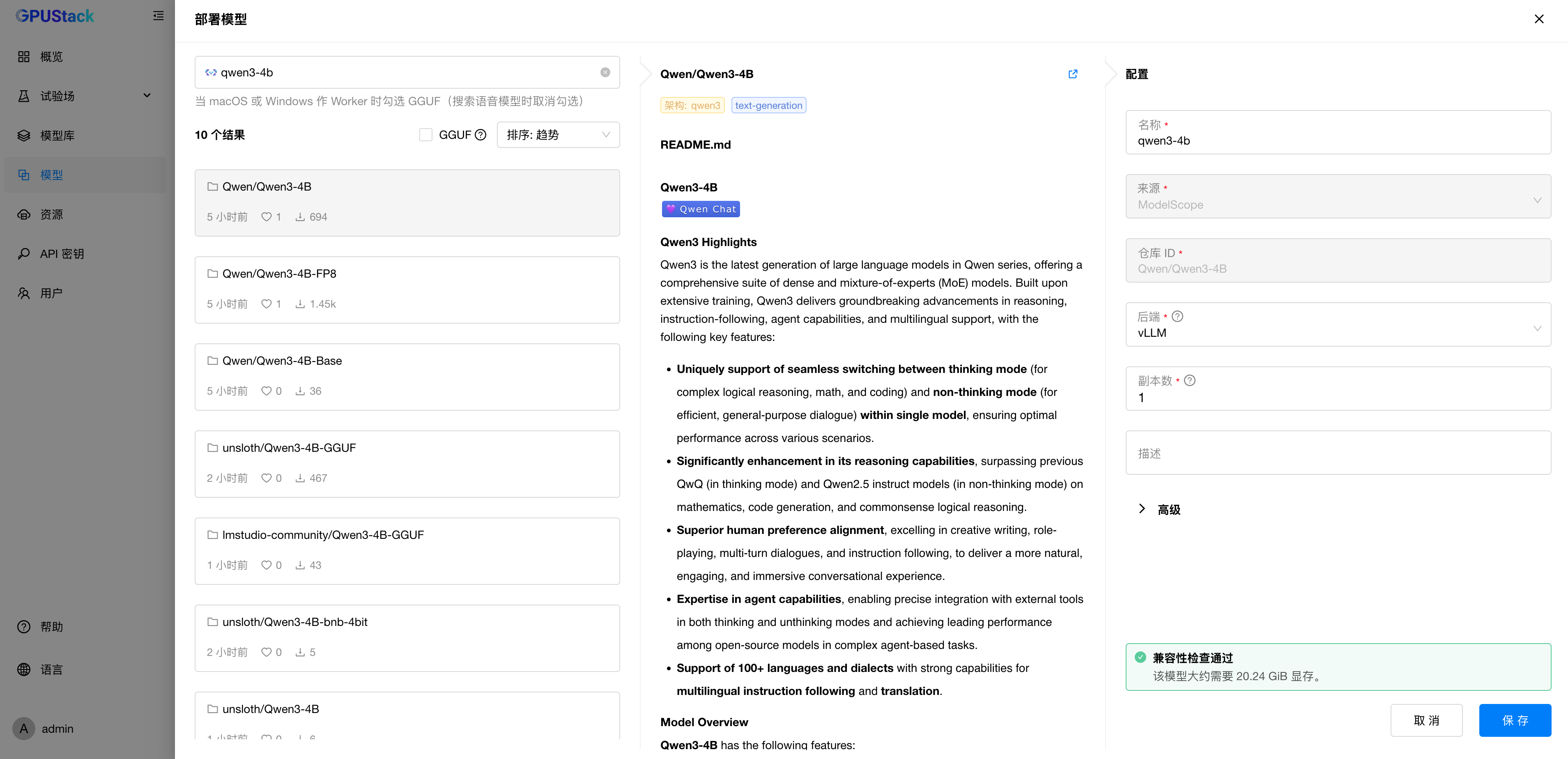
等待模型下载:
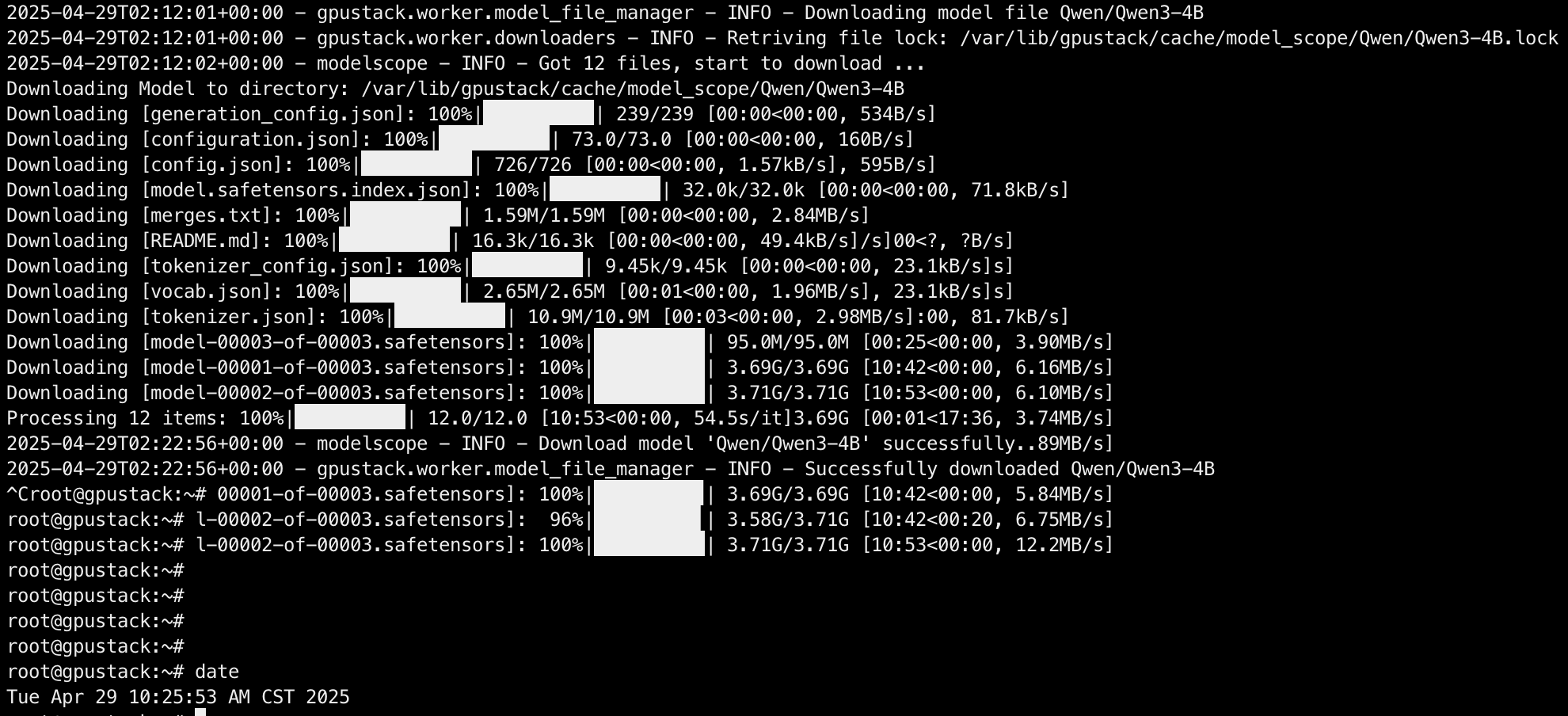
耗时:14m
等待模型启动完成:
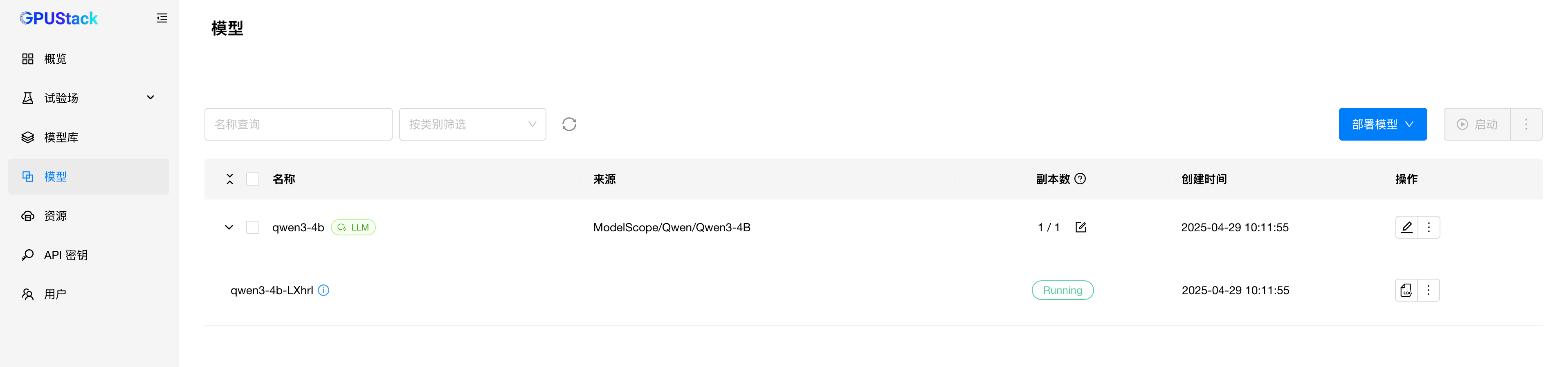
确认模型正常 Running 后,在试验场测试模型的生成效果:
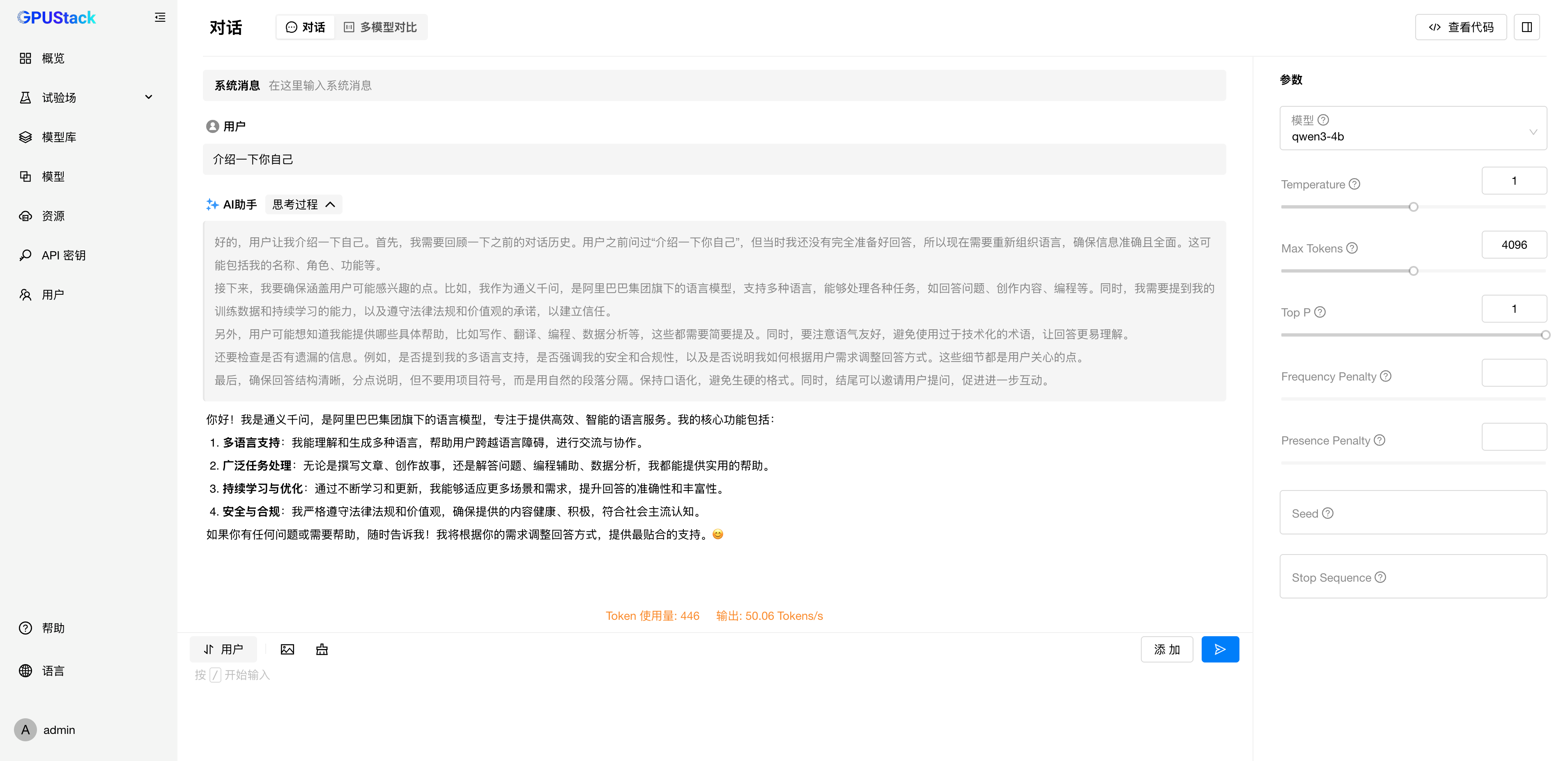
问题测试:

挑战完成,记录时间:

总耗时:43m25s,其中包括:
- 容器镜像下载耗时约 20m
- 模型文件下载耗时约 14m
- 安装配置步骤耗时约 20m
按照以上步骤,我们已经完成在 45 分钟内搭建 GPUStack 模型服务平台并运行生产级的 Qwen3 模型服务。
目前 GPUStack 的 vLLM 后端和 llama-box 后端均已支持运行 Qwen3,在 Linux、Windows 和 macOS 上均可运行,欢迎体验。
旗舰模型 Qwen3-235B-A22B 由于参数量比较大,还在下载中,针对部分用户单机显存资源无法运行的场景,我们将在下篇文章带来通过多机分布式运行 Qwen3-235B-A22B 模型的教程。
通过以上步骤,我们已经演示了如何快速在 45 分钟内搭建 GPUStack 模型服务平台并通过 GPUStack 运行生产级的 Qwen3 模型服务,GPUStack 是一个100%开源的模型服务平台,目前用户遍布全球上百个国家 ,GPUStack 的目标是打造业界最好用的模型推理平台,欢迎使用与反馈。如果你有任何建议或想法,欢迎随时向我们提出,我们会认真评估并持续改进。
参与开源
想要了解更多关于 GPUStack 的信息,可以访问我们的仓库地址:https://github.com/gpustack/gpustack。如果你对 GPUStack 有任何建议,欢迎提交 GitHub issue 。在体验 GPUStack 或提交 issue 之前,请在我们的 GitHub 仓库上点亮 Star ⭐️关注我们,也非常欢迎大家一起参与到这个开源项目中!
如果觉得对你有帮助,欢迎点赞 、转发 、关注。