作者:来自 Elastic JINA

新的 2B 视觉语言模型在多语言 VQA(Visual Question Answering - 视觉问答)上达到 SOTA(state of the art - 最先进的水平),在仅文本任务中无灾难性遗忘。
更多阅读:Elastic 与 Jina AI 联手推动 AI 应用的开源检索发展
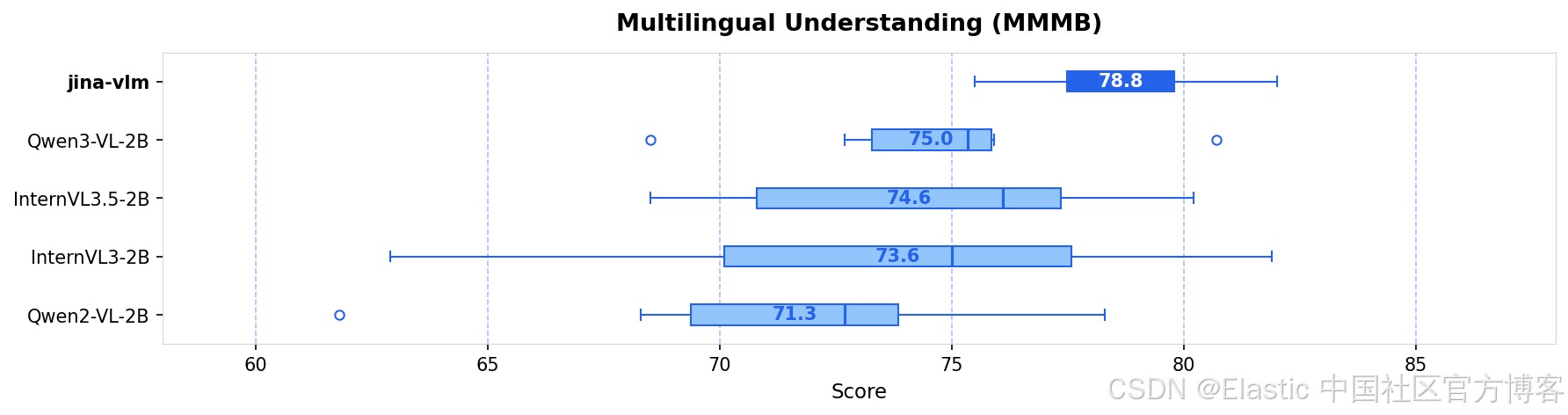
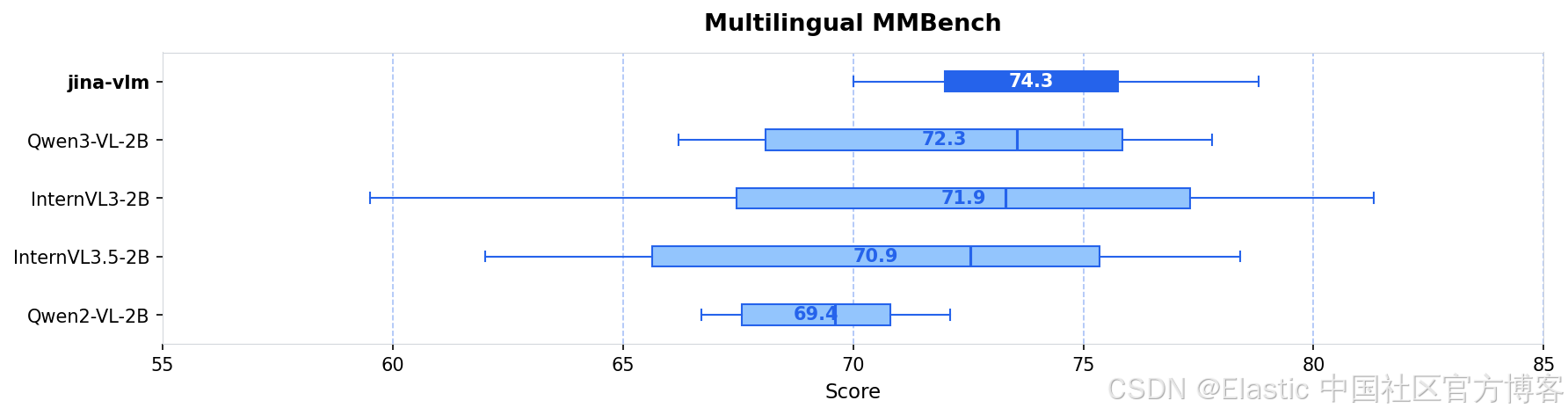
我们发布了jina-vlm,这是一款 2.4B 参数的视觉语言模型,在开放的 2B 级 VLM 中实现了多语言视觉问答的 SOTA。通过将 SigLIP2 视觉编码器与 Qwen3 语言骨干通过 attention-pooling 连接器结合,jina-vlm 在保持足够高效、可在消费级硬件上运行的同时,在 29 种语言中提供了强劲表现。
| Model | Size | VQA Avg | MMMB | Multi. MMB | DocVQA | OCRBench |
|---|---|---|---|---|---|---|
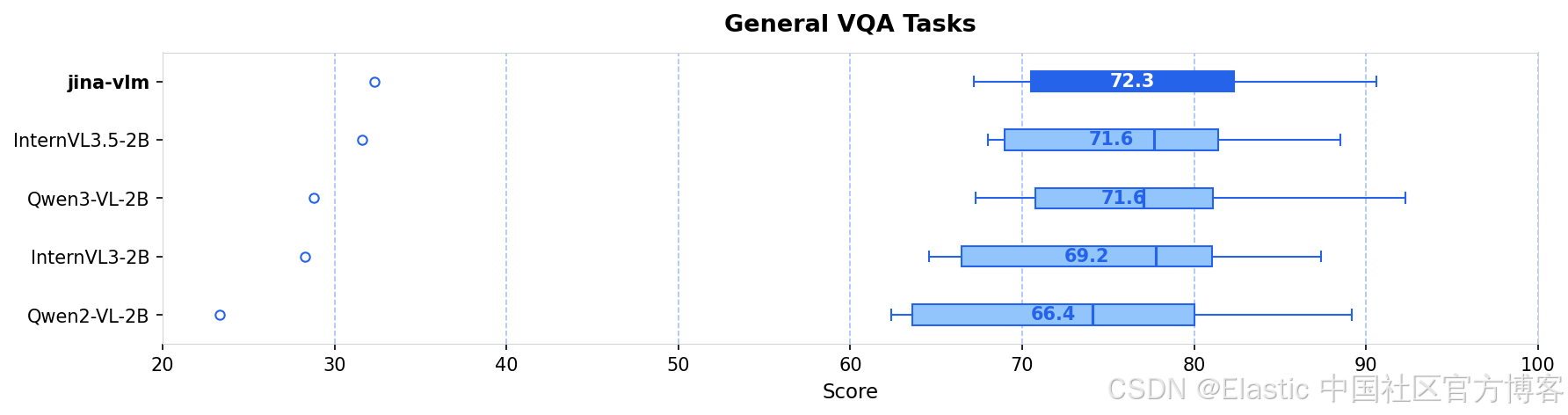
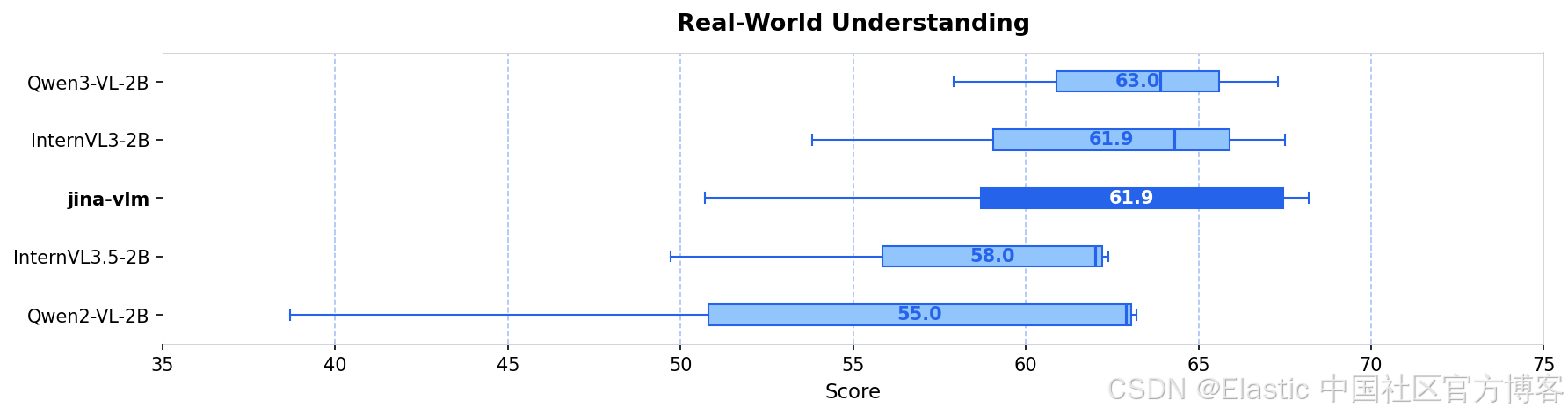
| jina-vlm | 2.4B | 72.3 | 78.8 | 74.3 | 90.6 | 778 |
| Qwen2-VL-2B | 2.1B | 66.4 | 71.3 | 69.4 | 89.2 | 809 |
| Qwen3-VL-2B | 2.8B | 71.6 | 75.0 | 72.3 | 92.3 | 858 |
| InternVL3-2B | 2.2B | 69.2 | 73.6 | 71.9 | 87.4 | 835 |
| InternVL3.5-2B | 2.2B | 71.6 | 74.6 | 70.9 | 88.5 | 836 |
架构
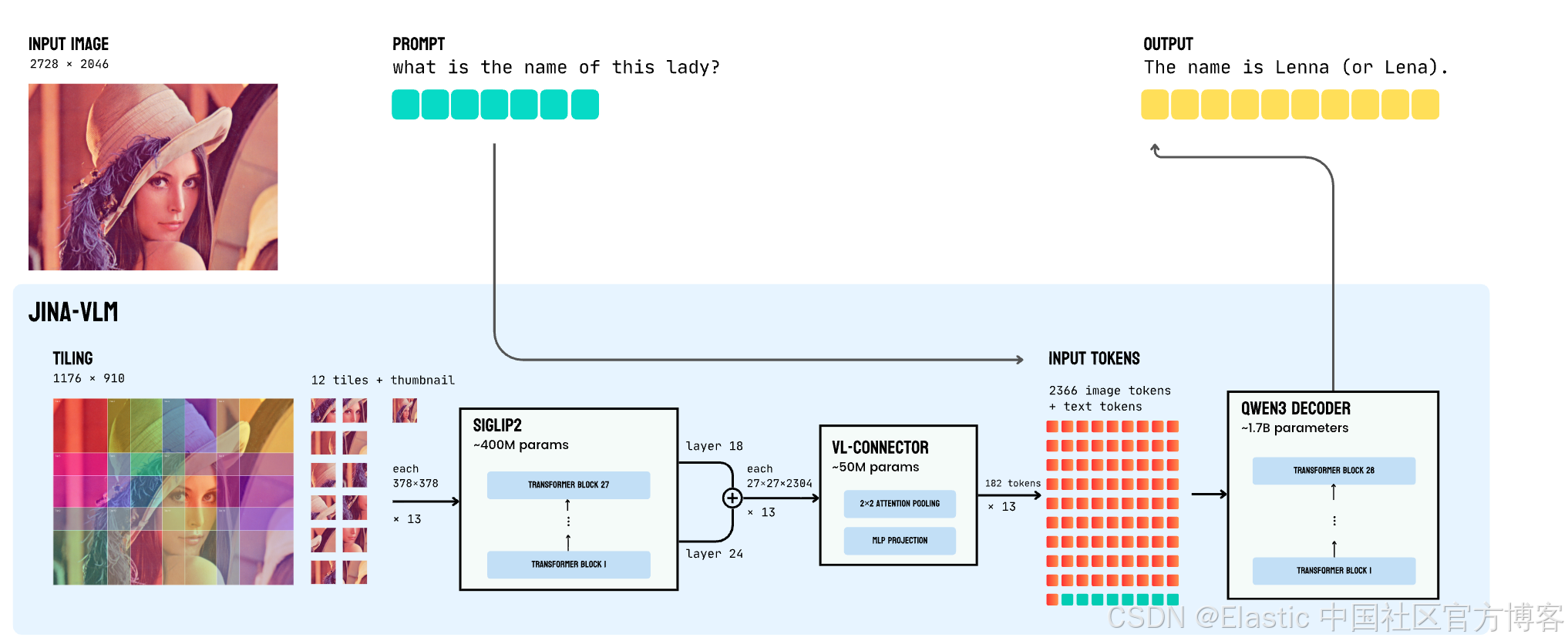
两个挑战限制了 VLM 的实际部署:多语言能力在视觉适配过程中通常会下降,高质量 VLM 仍然计算成本高。jina-vlm 通过谨慎的架构选择解决了这两个问题 ------ 我们的 attention-pooling connector 将视觉 tokens 减少了 4×,性能影响最小 ------ 以及显式保留多语言能力的训练方案。
关键的架构创新是我们的 vision-language connector。不是将每个 tile 的 729 个视觉 tokens 全部传给语言模型,而是应用 2×2 attention pooling,将其减少到 182 个 tokens ------ 4× 减少且信息损失最小。该 connector 工作方式如下:
- 多层特征融合:我们连接 ViT 层 18 和 24(倒数第三层和倒数第九层)的特征,同时捕捉精细空间细节和高层语义。
- Attention pooling:对于每个 2×2 patch 邻域,我们将邻域特征取均值作为 query,然后应用 cross-attention 生成单一池化表示。
- SwiGLU 投影:池化特征通过 gated linear unit 投影到语言模型维度。
这种效率提升如下所述:
| Metric | No Pooling | With Pooling | Reduction |
|---|---|---|---|
| Visual tokens (12 tiles + thumbnail) | 9,477 | 2,366 | 4.0× |
| LLM prefill FLOPs | 27.2 TFLOPs | 6.9 TFLOPs | 3.9× |
| KV-cache memory | 2.12 GB | 0.53 GB | 4.0× |
由于 ViT 对每个 tile 的处理不受 pooling 影响,这些节省仅适用于语言模型,而语言模型在推理过程中是主要开销。
训练流程
VLM 训练中的一个常见失败模式是灾难性遗忘:语言模型在适应视觉输入时丧失纯文本能力。对于多语言模型尤其明显,因为视觉适配可能降低非英语语言的性能。
我们通过两阶段训练流程,并结合显式多语言数据和纯文本保留来解决这一问题。
阶段 1:对齐训练
第一阶段专注于跨语言语义对齐,使用覆盖多样视觉领域的 caption 数据集:自然场景、文档、信息图表和图示。关键是包括 15% 的纯文本数据以保持 backbone 的语言理解能力。connector 使用比 encoder 和 decoder 更高的学习率 (2e-4) 和更短的 warmup,使其快速适应,而预训练组件变化较慢。
阶段 2:指令微调
第二阶段训练 VQA 和推理任务的指令跟随能力。我们结合了涵盖学术 VQA、文档理解、OCR、数学和推理的公开数据集,以及纯文本指令数据以保持语言能力。
组合数据约包括 500 万多模态样本和 120 亿文本 tokens,覆盖 29 种语言,其中约一半为英语,其余包括中文、阿拉伯语、德语、西班牙语、法语、意大利语、日语、韩语、葡萄牙语、俄语、土耳其语、越南语、泰语、印尼语、印地语、孟加拉语等。
入门
通过 Jina API
我们提供一个 OpenAI 兼容的 API,地址为 https://api-beta-vlm.jina.ai。你可以在如下的地址申请 JINA API key:
从 URL 获取图片
| Format | Example |
|---|---|
| HTTP/HTTPS URL | https://example.com/image.jpg |
| Base64 data URI | data:image/jpeg;base64,/9j/4AAQ... |
curl https://api-beta-vlm.jina.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $JINA_API_KEY" \
-d '{
"model": "jina-vlm",
"messages": [{
"role": "user",
"content": [
{"type": "text", "text": "Describe this image"},
{"type": "image_url", "image_url": {"url": "https://example.com/photo.jpg"}}
]
}]
}'
$ export JINA_API_KEY=<Your JINA API KEY>
$ curl https://api-beta-vlm.jina.ai/v1/chat/completions \
> -H "Content-Type: application/json" \
> -H "Authorization: Bearer $JINA_API_KEY" \
> -d '{
> "model": "jina-vlm",
> "messages": [{
> "role": "user",
> "content": [
> {"type": "text", "text": "Describe this image"},
> {"type": "image_url", "image_url": {"url": "https://i-blog.csdnimg.cn/communtity/a710be2135c84754aaf0f82e2be7931b.png"}}
> ]
> }]
> }'
{"id":"chatcmpl-8345d8ba13ad43e8984bb5f6","object":"chat.completion","created":1765284603,"model":"jina-vlm","choices":[{"index":0,"message":{"role":"assistant","content":" The image depicts a large indoor event, likely a conference or seminar, taking place in a modern, spacious room. The room is well-lit, with natural light coming in through large windows on the right side, which are partially covered with white blinds. The ceiling is high and appears to be made of a light-colored material, possibly white or light gray, with a grid of fluorescent lights.\n\nThe seating arrangement consists of rows of chairs, which are metal with a simple design, and are organized in a way that allows for clear visibility of the audience. The chairs are evenly spaced, and the rows are staggered, creating a sense of depth in the room. The audience is composed of a diverse group of individuals, primarily young adults, with a mix of genders. They are dressed in casual to semi-formal attire, suggesting that the event is not a formal business meeting but rather a more relaxed, educational or professional gathering.\n\nIn the foreground, there are several attendees who are more prominently visible. They are seated in the front rows, and their attention is directed towards the front of the room, likely towards a speaker or presentation. The individuals in the foreground are wearing a variety of clothing, including jackets, sweaters, and casual shirts, with some wearing glasses. The expressions on their faces are attentive and focused, indicating that they are engaged in the event.\n\nThe room itself has a modern aesthetic, with a neutral color palette that includes shades of gray, white, and black. The walls are a light color, and the floor appears to be a polished concrete or a similar material. There are no visible decorations or personal items on the walls, which gives the room a clean and professional appearance.\n\nThe overall atmosphere of the room is one of concentration and engagement, with the audience members appearing to be actively listening to the speaker or presentation. The room is well-organized and designed to facilitate an effective learning or discussion environment."},"finish_reason":"stop"}],"usage":{"prompt_tokens":1303,"completion_tokens":386,"total_tokens":1689}}$ 该图片展示了一个大型室内活动,很可能是会议或研讨会,地点在一个现代、宽敞的房间内。房间光线充足,右侧的大窗户透入自然光,窗户部分装有白色百叶窗。天花板很高,颜色较浅,可能是白色或浅灰色,配有荧光灯格栅。
座位排列为多排椅子,椅子为金属材质,设计简洁,排列方式保证观众视线清晰。椅子间距均匀,排与排错开,形成空间深度感。观众由多样化群体组成,主要是年轻成年人,性别混合,着装从休闲到半正式,表明活动不是正式商务会议,而是较轻松的教育或专业聚会。
前景中有几位观众更为明显,他们坐在前排,注意力集中在房间前方,可能是讲者或演示。前景人物穿着各类服饰,包括夹克、毛衣和休闲衬衫,有些佩戴眼镜。表情专注,显示出他们正在积极参与活动。
房间整体现代,色彩中性,包括灰色、白色和黑色。墙面浅色,地面可能是抛光混凝土或类似材料。墙上没有可见装饰或个人物品,使房间显得干净、专业。
整体氛围专注而投入,观众似乎在认真听讲。房间布局合理,有利于有效的学习或讨论环境。

本地图片 (base64)
curl https://api-beta-vlm.jina.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $JINA_API_KEY" \
-d '{
"model": "jina-vlm",
"messages": [{
"role": "user",
"content": [
{"type": "text", "text": "What is in this image?"},
{"type": "image_url", "image_url": {"url": "data:image/jpeg;base64,'$(base64 -i image.jpg)'"}}
]
}]
}'我在地址找到如下的这个图片:

$ pwd
/Users/liuxg/python/jina
$ ls
musk.png
$ curl https://api-beta-vlm.jina.ai/v1/chat/completions \
> -H "Content-Type: application/json" \
> -H "Authorization: Bearer $JINA_API_KEY" \
> -d '{
> "model": "jina-vlm",
> "messages": [{
> "role": "user",
> "content": [
> {"type": "text", "text": "What is in this image?"},
> {"type": "image_url", "image_url": {"url": "data:image/jpeg;base64,'$(base64 -i musk.png)'"}}
> ]
> }]
> }'
{"id":"chatcmpl-4e7fe4b9b20c4cef999d206b","object":"chat.completion","created":1765285536,"model":"jina-vlm","choices":[{"index":0,"message":{"role":"assistant","content":" The image features Elon Musk, the CEO of SpaceX, giving a thumbs-up gesture. He is smiling and appears to be in a celebratory mood. In the background, there is a rocket launch taking place, with a large plume of smoke rising into the sky. The SpaceX logo is visible on the right side of the image, indicating the location or context of the event. The overall atmosphere suggests a successful launch or a significant achievement related to SpaceX's space explorati图片中是 Elon Musk(埃隆·马斯克),他竖起大拇指微笑,显得很开心。背景中有一次火箭发射,冒起巨大的烟雾。右侧可以看到 SpaceX 标志,表明这是 SpaceX 的活动现场。整体氛围像是在庆祝一次成功发射或重大成就。
$ curl https://api-beta-vlm.jina.ai/v1/chat/completions \
> -H "Content-Type: application/json" \
> -H "Authorization: Bearer $JINA_API_KEY" \
> -d '{
> "model": "jina-vlm",
> "messages": [{
> "role": "user",
> "content": [
> {"type": "text", "text": "国旗是哪个国家的?"},
> {"type": "image_url", "image_url": {"url": "data:image/jpeg;base64,'$(base64 -i musk.png)'"}}
> ]
> }]
> }'
{"id":"chatcmpl-5ce4565e70664e4f9f67415a","object":"chat.completion","created":1765285664,"model":"jina-vlm","choices":[{"index":0,"message":{"role":"assistant","content":" 美国"},"finish_reason":"stop"}],"usage":{"prompt_tokens":578,"completion_tokens":5,"total_tokens":583}}$ 美国
curl https://api-beta-vlm.jina.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $JINA_API_KEY" \
-d '{
"model": "jina-vlm",
"messages": [{
"role": "user",
"content": [
{"type": "text", "text": "上面的文字是什么?"},
{"type": "image_url", "image_url": {"url": "data:image/jpeg;base64,'$(base64 -i musk.png)'"}}
]
}]
}'
纯文本查询
curl https://api-beta-vlm.jina.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $JINA_API_KEY" \
-d '{
"model": "jina-vlm",
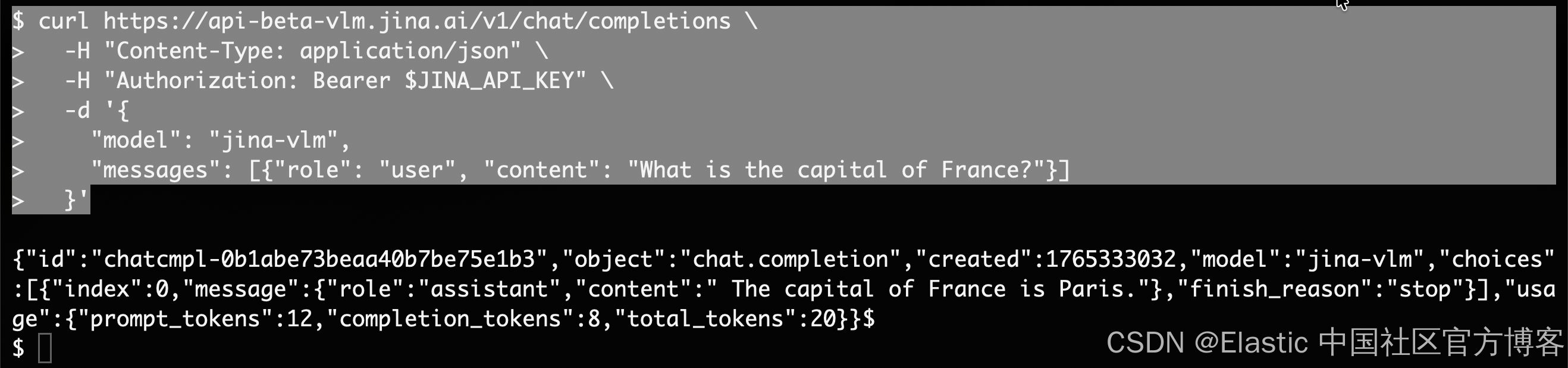
"messages": [{"role": "user", "content": "What is the capital of France?"}]
}'
流式响应
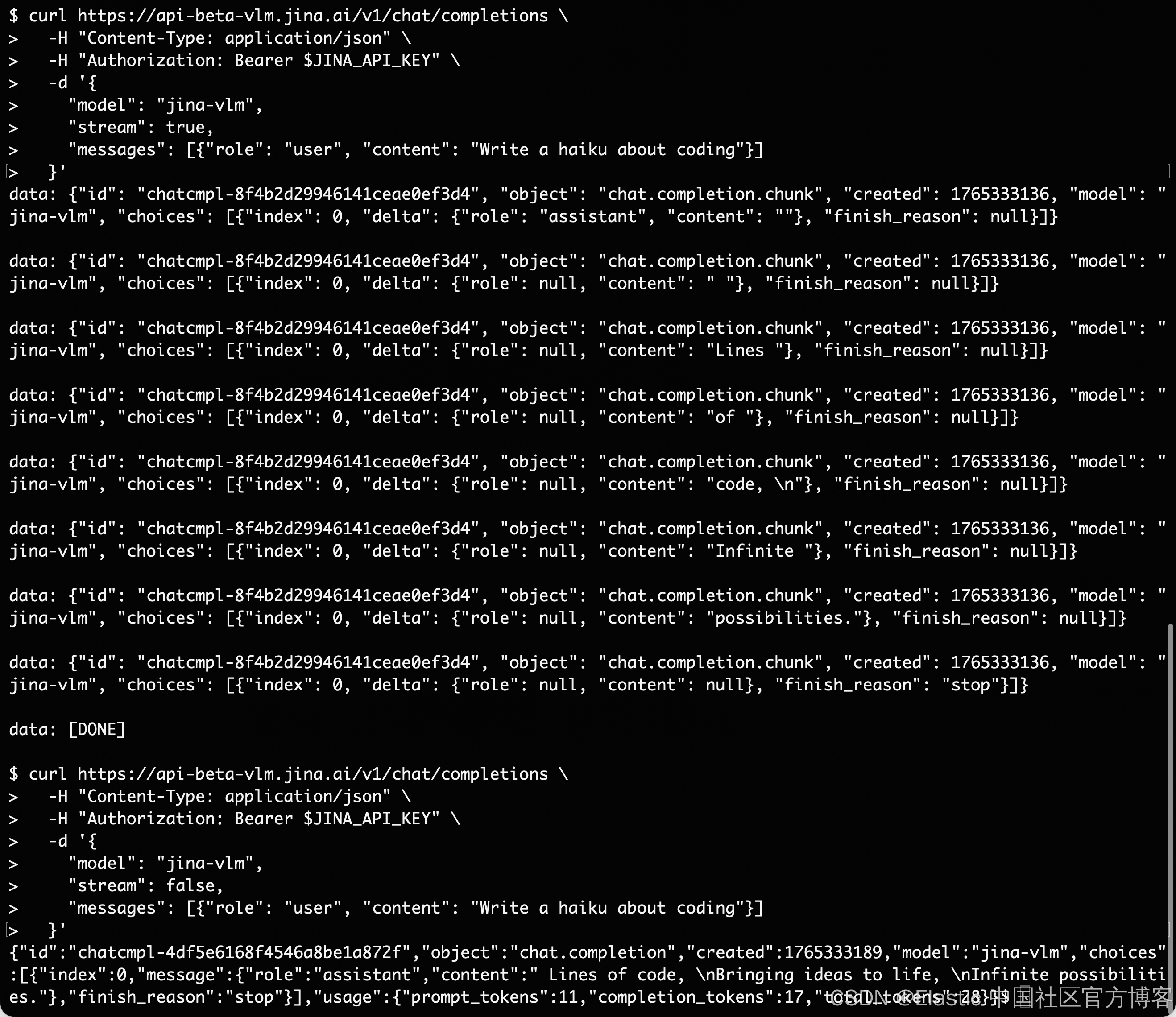
添加 "stream": true 以在生成 token 时接收输出:
curl https://api-beta-vlm.jina.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $JINA_API_KEY" \
-d '{
"model": "jina-vlm",
"stream": true,
"messages": [{"role": "user", "content": "Write a haiku about coding"}]
}'当服务冷启动时,你会收到:
{
"error": {
"message": "Model is loading, please retry in 30-60 seconds. Cold start takes ~30s after the service scales up.",
"code": 503
}
}等待后重试你的请求。
通过 CLI
HuggingFace 仓库包含一个 infer.py 脚本用于快速实验:
# Single image
python infer.py -i image.jpg -p "What's in this image?"
# Streaming output
python infer.py -i image.jpg -p "Describe this image" --stream
# Multiple images
python infer.py -i img1.jpg -i img2.jpg -p "Compare these images"
# Text-only
python infer.py -p "What is the capital of France?"通过 Transformers
from transformers import AutoModelForCausalLM, AutoProcessor
import torch
from PIL import Image
# Load model and processor
model = AutoModelForCausalLM.from_pretrained(
"jinaai/jina-vlm",
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto"
)
processor = AutoProcessor.from_pretrained(
"jinaai/jina-vlm",
trust_remote_code=True
)
# Load an image
image = Image.open("document.png")
# Create the conversation
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": image},
{"type": "text", "text": "What is the main topic of this document?"}
]
}
]
# Process and generate
inputs = processor.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt"
).to(model.device)
outputs = model.generate(**inputs, max_new_tokens=256, do_sample=False)
response = processor.decode(outputs[0], skip_special_tokens=True)
print(response)结论
jina-vlm 表明,小型 VLM 通过谨慎的架构和训练选择,也能实现强大的跨语言视觉理解。attention-pooling connector 提供 4× token 减少且性能影响最小,在多模态训练中加入纯文本数据可保留语言能力,否则这些能力会下降。
我们注意到当前方法的几个局限性:
- Tiling 开销:处理随 tile 数线性增加。对于超高分辨率图像,这可能变得显著。此外,tiling 可能影响需要整体场景理解的任务,如对象计数或跨 tile 边界的空间推理。全局缩略图可部分缓解,但原生分辨率方法可能更适合此类任务。
- 多图像推理:在多图像基准上的性能较弱,因为该场景下训练数据有限。优化简洁视觉响应似乎与多步推理冲突,如 MMLU-Pro 性能下降所示。
未来工作可探索更高效的分辨率处理、针对计数和空间任务的优化,并研究我们的多语言训练方案是否可迁移到更大规模模型。
原文:https://jina.ai/news/jina-vlm-small-multilingual-vision-language-model/