一.基本结构
1.目标:处理序列数据(时间序列,文本,语音等),捕捉时间维度上的依赖关系
核心机制:通过隐藏状态(hidden State)传递历史信息,每个时间步的输入包含当前数据和前一步的隐藏状态
前向传播的公式:
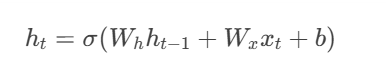
-
ht:当前时间步的隐藏状态
-
xtxt:当前输入
-
Wh,WxWh,Wx:权重矩阵
-
σσ:激活函数(通常为
tanh或ReLU)
2.输入与输出形式
单输入单输出(如时间序列预测):每个时间步接收一个输入,最后一步输出预测结果
多输入,多输出(如机器翻译): 每个时间步接收输入并生成输出(如逐词翻译)。
Seq2Seq(如文本生成):编码器-解码器结构,编码器处理输入序列,解码器生成输出序列。
二.RNN的变体
1.双向RNN
-
特点 :同时捕捉过去和未来的上下文信息。
-
结构:包含正向和反向两个隐藏层,最终输出由两者拼接而成。
2.深层RNN
-
特点:堆叠多个RNN层,增强模型表达能力。
-
结构:每层的隐藏状态作为下一层的输入。
3.LSTM(长短时记忆网络)
-
核心机制 :通过**细胞状态(Cell State)**和门控机制(输入门、遗忘门、输出门)解决梯度消失问题。
-
门控公式:
-
遗忘门:决定保留多少旧信息
-
输入门:决定新增多少新信息
-
输出门:决定当前隐藏状态输出
-
4.GRU(门控循环单元)
-
简化版LSTM:合并细胞状态和隐藏状态,参数更少。
-
门控公式:
-
更新门:控制新旧信息的融合比例
-
重置门:决定忽略多少旧信息
-
三.RNN的梯度问题与优化
梯度消失与爆炸的原因
-
反向传播:通过时间展开(BPTT)计算梯度时,梯度涉及权重矩阵的连乘。
-
梯度消失:若权重矩阵特征值 ∣λ∣<1∣λ∣<1,梯度指数级衰减,深层参数无法更新。
-
梯度爆炸:若 ∣λ∣>1∣λ∣>1,梯度指数级增长,导致数值溢出或模型震荡。
解决方案
-
梯度裁剪(Gradient Clipping):限制梯度最大值,防止爆炸。
-
参数初始化:使用正交初始化(保持矩阵乘法后的范数稳定)。
-
改进结构:LSTM/GRU通过门控机制缓解梯度消失。
-
残差连接:跨时间步跳跃连接(如 ht=ht−1+f(xt,ht−1)ht=ht−1+f(xt,ht−1)),直接传递梯度。