一、进程
进程,什么是进程?
在课本,教材中是这样描述的:程序的一个执行示例,正在执行的程序;
从内核角度来说,进程就是担当分配系统资源(CPU时间,内存)的实体。
这样说还是太抽象的,还是不能理解到底什么才是进程。
我们现在来想一下,程序要想运行,就要加载到内存,那在内存到底有多少等待执行程序呢?
很显然有很多,在内存当中有很多个等待执行的程序的代码和数据,那操作系统是不是要管理这些代码和数据?
那操作系统是如何管理的呢?还记得上篇文章理解管理中的:先描述、再组织
先描述 ,如何去描述:记录这些代码和数据的详细信息,记录在PCB中(也称为进程控制块)。
再组织 ,将每一个代码和数据对于的PCB通过数据结构(链表)组织管理起来。
这里我们先不管PCB和内核数据结构是什么;我们的进程在这里其实就是PCB+数据。
这里我们的进程就是:内核的数据结构对象 + 自己的代码和数据。
说简单一点就是:
PCB+ 代码和数据(在linux操作系统中,PCB就是task_struct结构体)
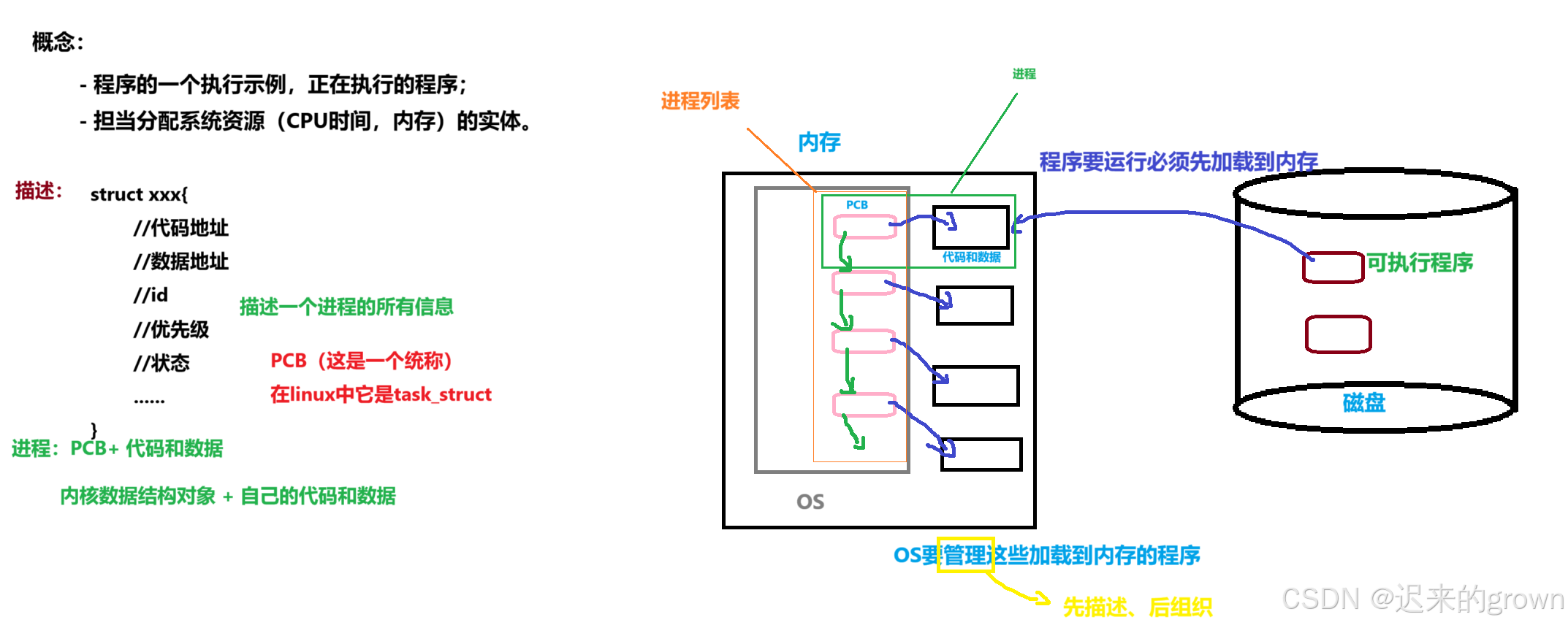
描述 - PCB
PCB,博主在计算机操作系统这门课程中学习到过PCB,在学校中老师讲述的PCB就是描述一个进程的各种详细信息。
虽然说学习过PCB,但还是不懂这是什么啊?
简单来说
PCB就是进程属性的集合,因为进程的信息都被放在进程控制块(PCB)中。
PCB是操作系统中对进程控制块的统称,linux下PCB是task_struct。
那我们老是说PCB是描述进程的属性,那到底有哪些属性呢?
- 标识符:描述进程的唯一标识符,区别其他进程。
- 状态:进程当前所处的状态。
- 优先级:相对于其他进程当前进程的优先级。
- 程序计数器:程序即将被执行的下一条指令的地址。
- 内存指针:包括程序代码和进程相关数据的指针,还用其他进程共享的内存块的指针。
- 上下文数据:程序执行时处理器的寄存器中的数据
I/O状态信息:包括显示的I/O请求,分配给进程的I/O设备的进程使用的文件列表- 记账信息:可能包括处理器时间综合,使用的时钟数综合,时间限制等。
- 其他信息...
不看不知道,一看吓一跳啊,进程属性居然这么多;不过不用着急,我们一点点的来看进程这些属性。
组织
描述了进程PCB,那如何将进程PCB组织起来呢?
所有运行在系统中的进程都以
task_struct链表的形式存储在内核中
简单来说就是在操作系统中存在一个全局链表,我们所有加载到内存中的程序对应的PCB都在这个全局链表中。
二、查看进程
有了对进程的了解之后,这里有一个疑问,我们在linux下使用的指令,它是不是进程?
是的,我们执行的所有指令、工具、我们自己的程序,运行起来它都是进程。
说了这么多,我们在linux操作系统下,能不能查看进程呢?
当然是可以的;
查看进程信息
1. 在linux操作系统中,我们所有的进程信息都存放在/proc这个系统文件夹中
一眼看去眼花缭乱的,没关系,我们接着往下看,在有一定了解之后再回来看;
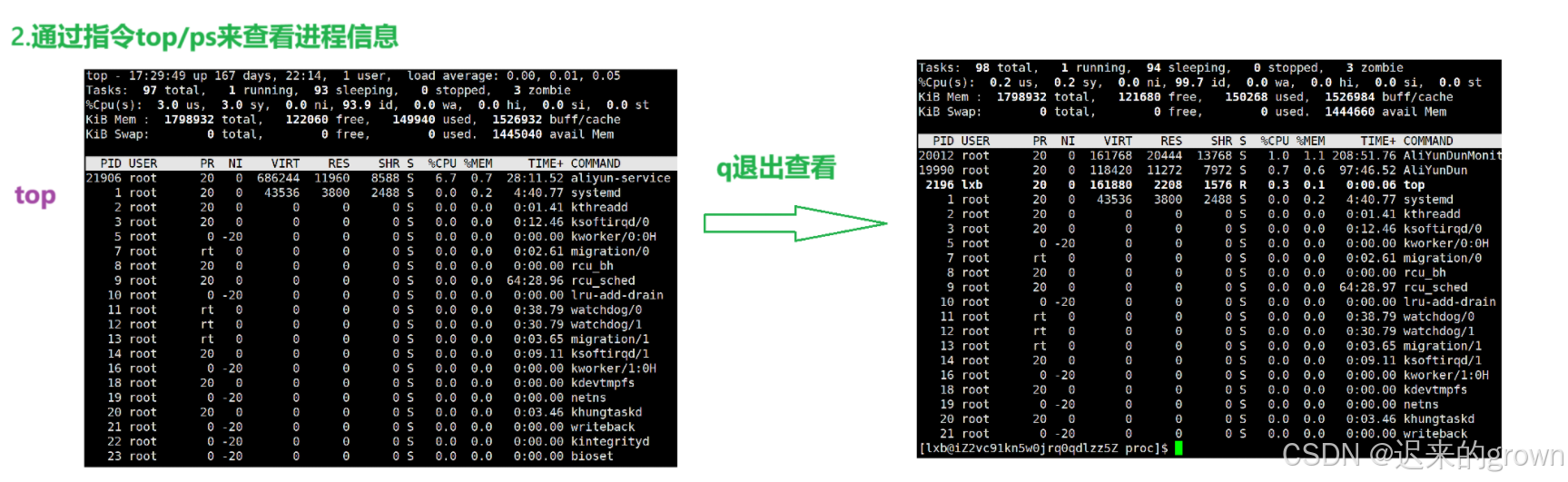
2. 我们可以通过指令top和ps来查看进程信息
top
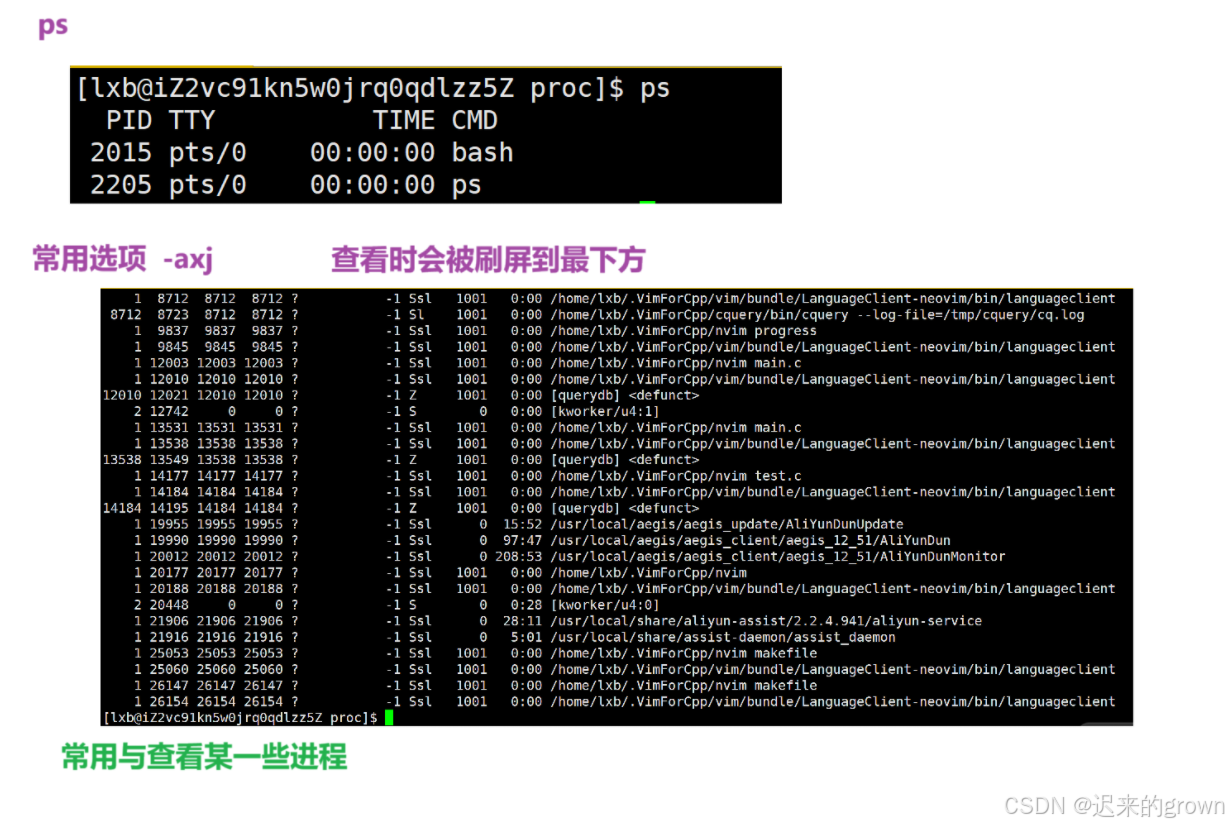
ps/ps -axj
这里我们写一个程序,写成死循环,否则运行时间太短查看不到。
c
//process.c
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
int main()
{
while(1){
sleep(1);
}
return 0;
}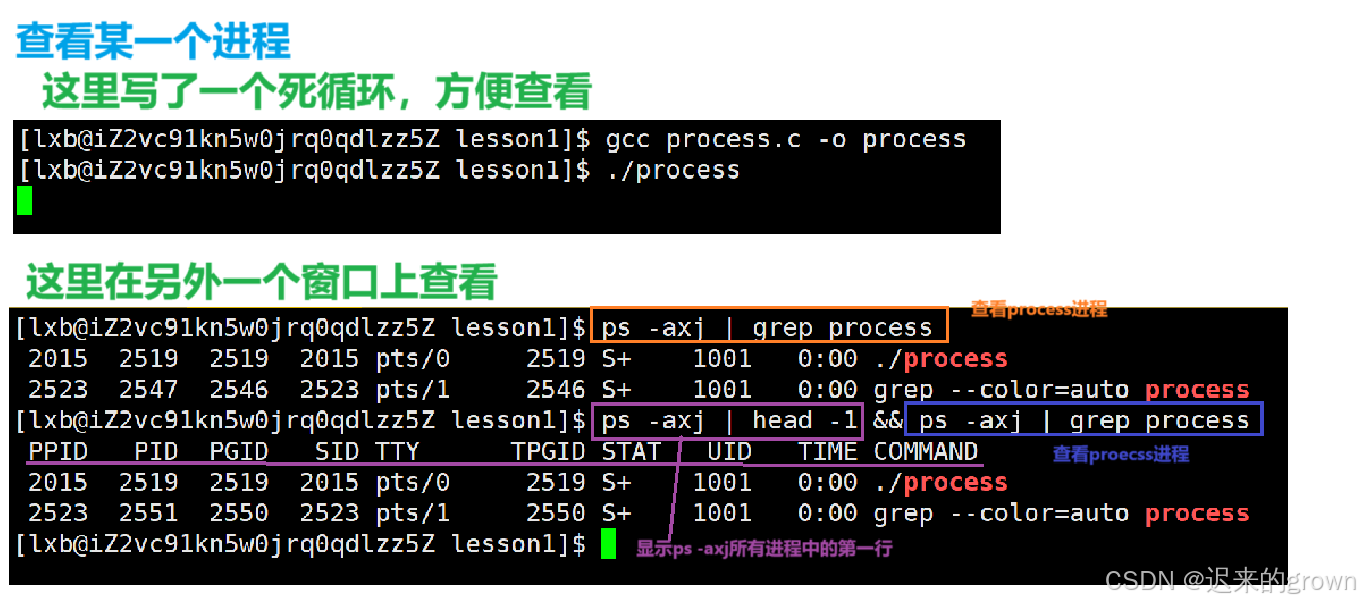
这里用到的指令
ps -axj:查看所有进程信息;
ps - axj | head -1:查看第一行信息(第一行是显示每一列指的是什么)
ps - axj | grep process:在ps - axj查看的所有进程信息中,搜索process。
&&:使用&&可以依次执行多个指令。
补充:
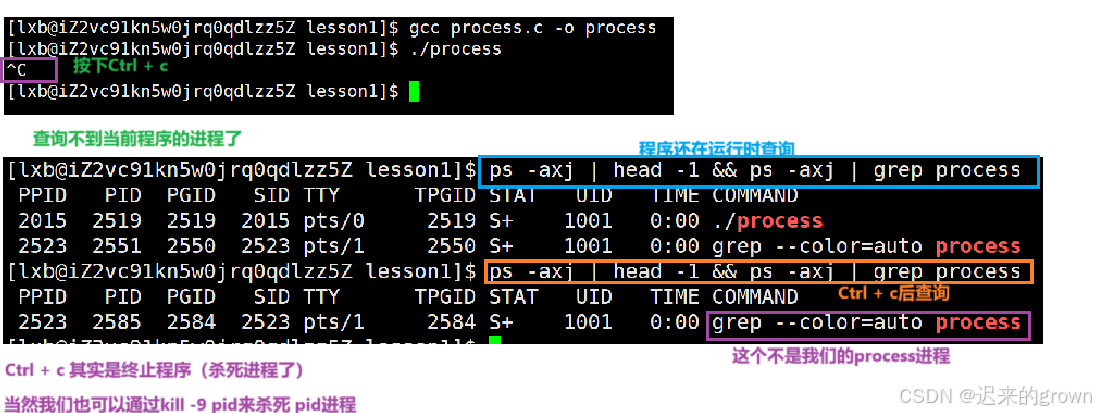
我们对于一个正在运行中的程序,如果不想让它继续运行,按下
Ctrl + c即可;
Ctrl + c终止程序其实就是杀死进程。我们也可以使用
kill指令来终止一个进程
进程标识符pid
通过查看我们进程可以发现进行有非常多的属性,现在来看进程标识符pid;
进程标识符是描述进程唯一的,和其他进程区别的;也就是说每一个进程它的pid都不相同;
getpid(),获取当前进程的pid
我们可以通过man getpid来查看man手册中 的getpid。
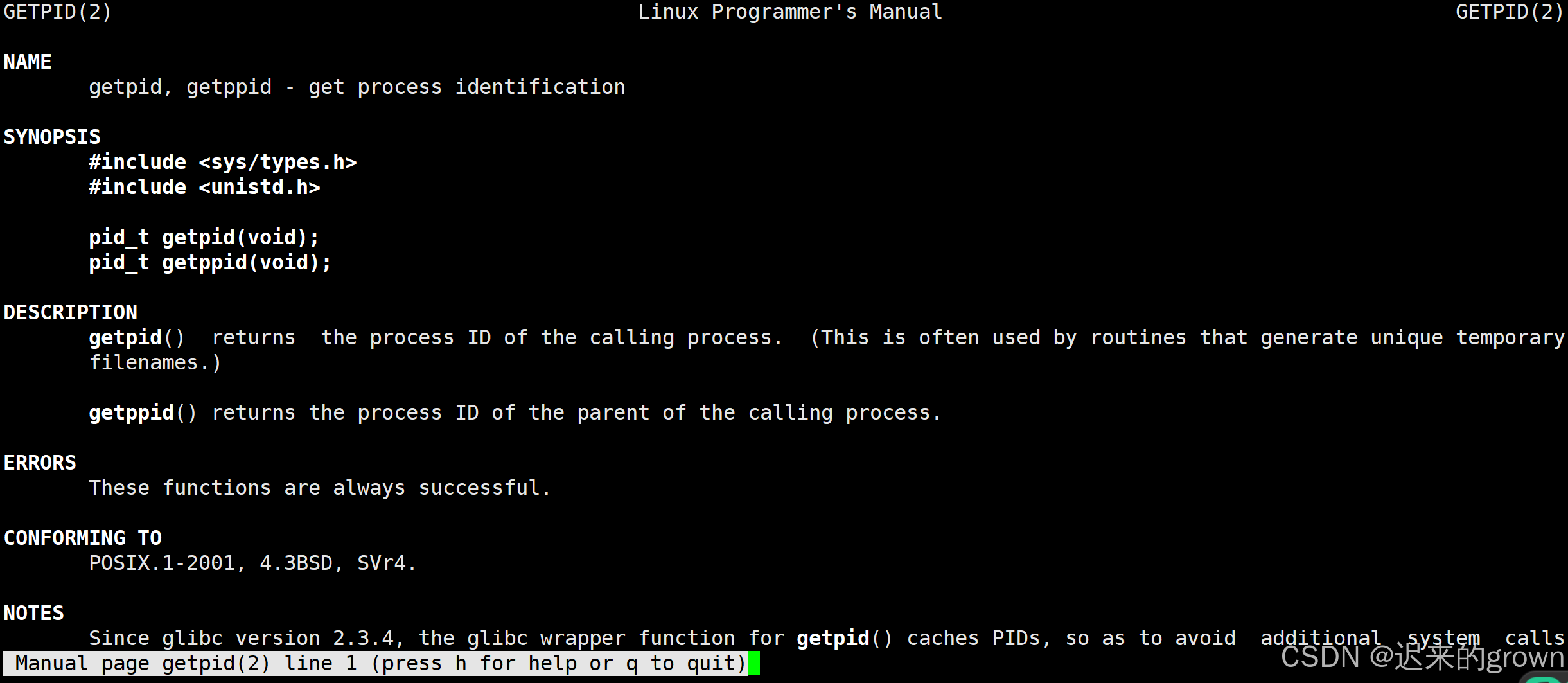
可以看到查询的是
2号手册,这表明这里的getpid是一个系统调用。使用时需要包含头文件
<sys/types.h>和<unistd.h>。
这里我们修改一下我们的代码:
c
//process.c
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
int main()
{
while(1){
printf("I am a process, my pid : %d\n",getpid());
sleep(1);
}
return 0;
}这里我们每次循环打印一次,然后休眠一秒。
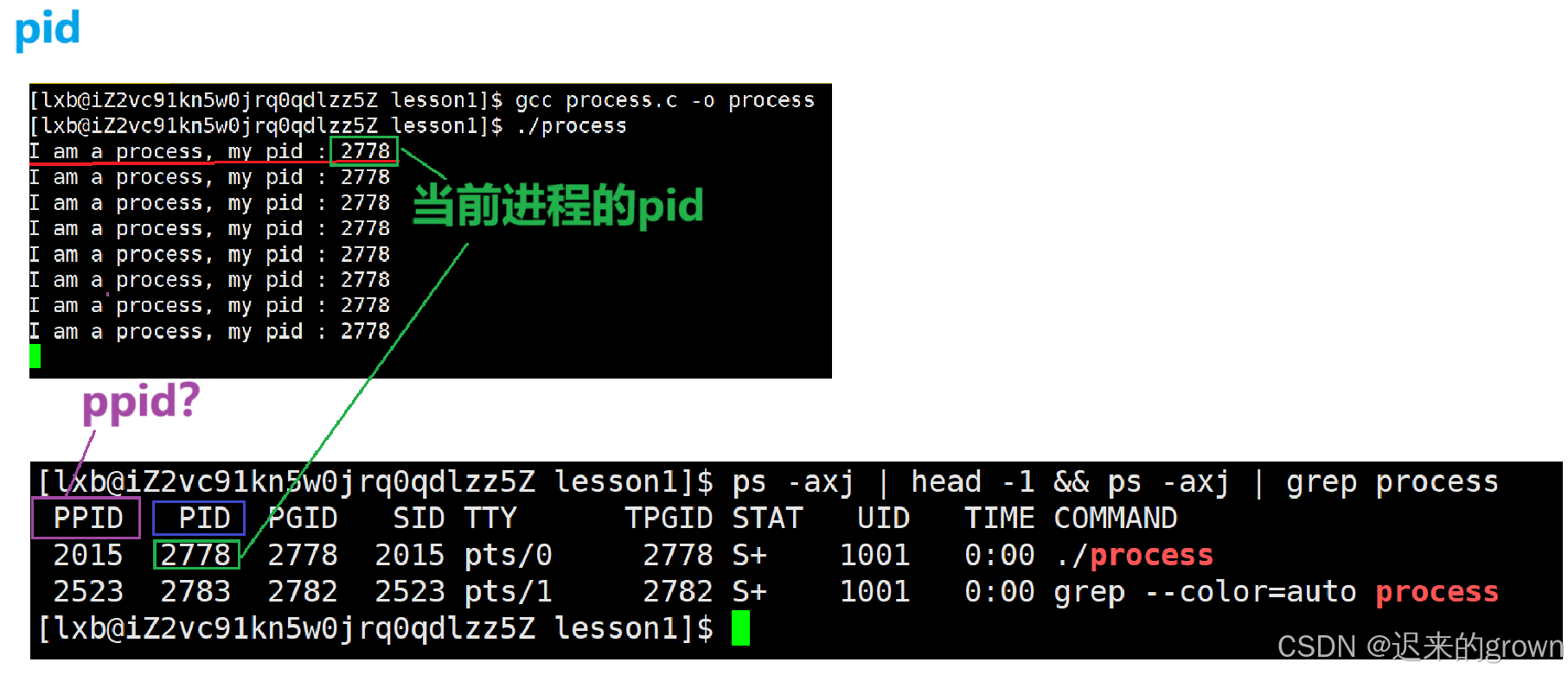
看到这里,我们知道了pid,那ppid又是什么东西?
父子进程
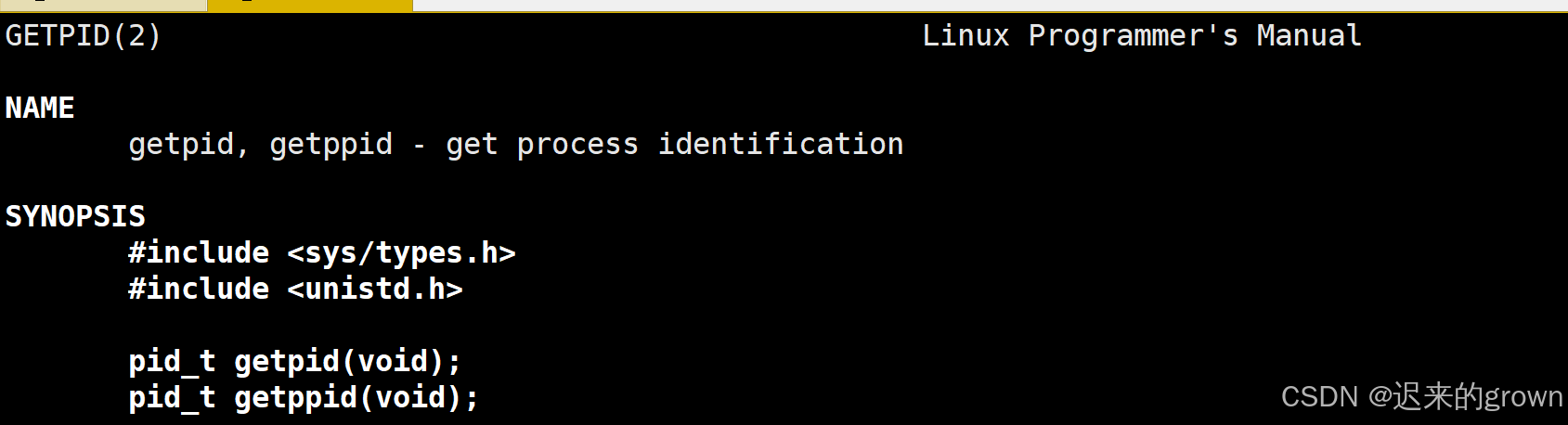
ppid就是父进程的pid;
当我们在一个进程
a中创建了一个新的进程b,那这个新的进程b就是我们旧进程a的子进程,a就是进程b的父进程有父进程可以有多个子进程,但是一个子进程只能有一个父进程
我们可以通过getppid来获得父进程的pid。
可以看到
getppid也是一个系统调用,它返回的是父进程的pid。
现在我们再修改一下代码,输出一个程序的父进程。
c
//process.c
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
int main()
{
printf("I am a process, my pid : %d\n",getpid());
return 0;
}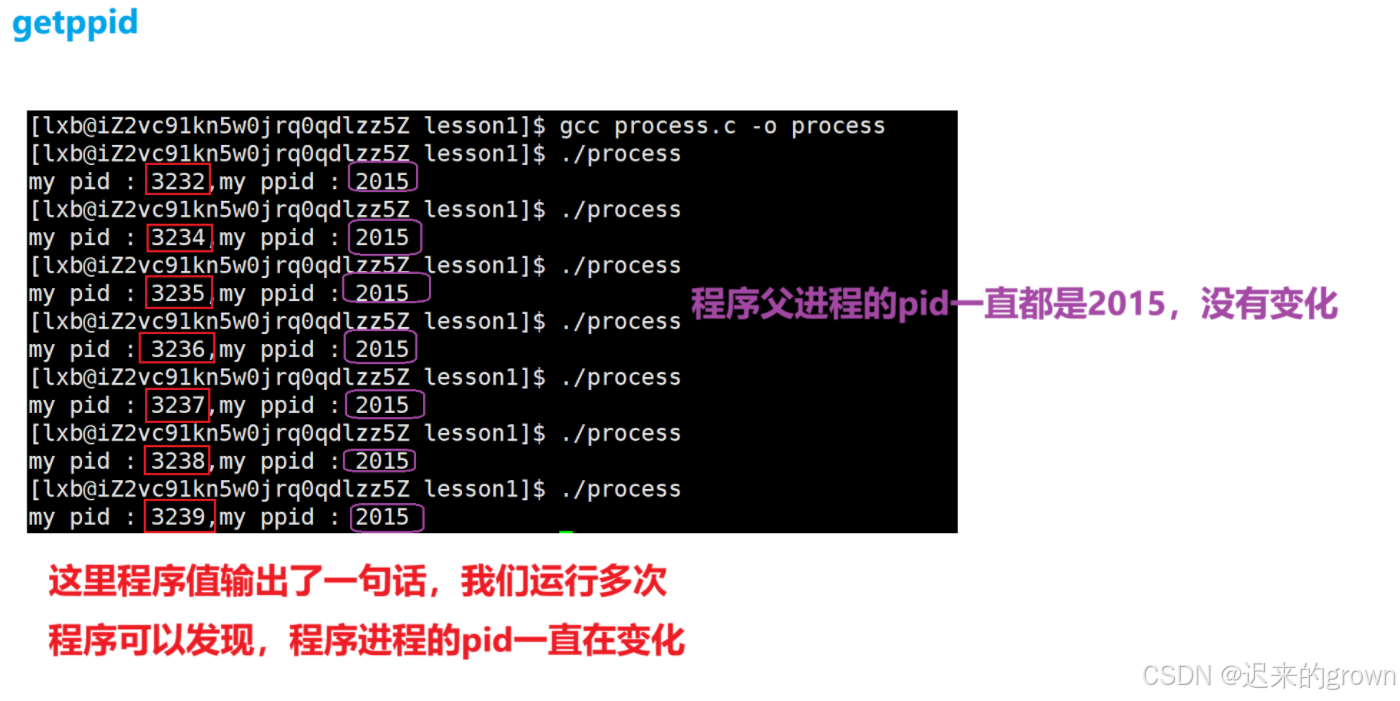
这里留一个小疑问上图中process的ppid是2015,那2015进程是什么?
父子进程这里就不过多描述了,主要记住父子进程关系就行。
创建进程
上面程序是我们自己写的代码,通过编译链接形成可执行程序,我们可以通过运行程序来创建进程;那我们可不可以在程序执行的过程中创建进程呢?
当然是可以的,这里我们可以使用系统调用
fork来在程序运行过程中创建进程;
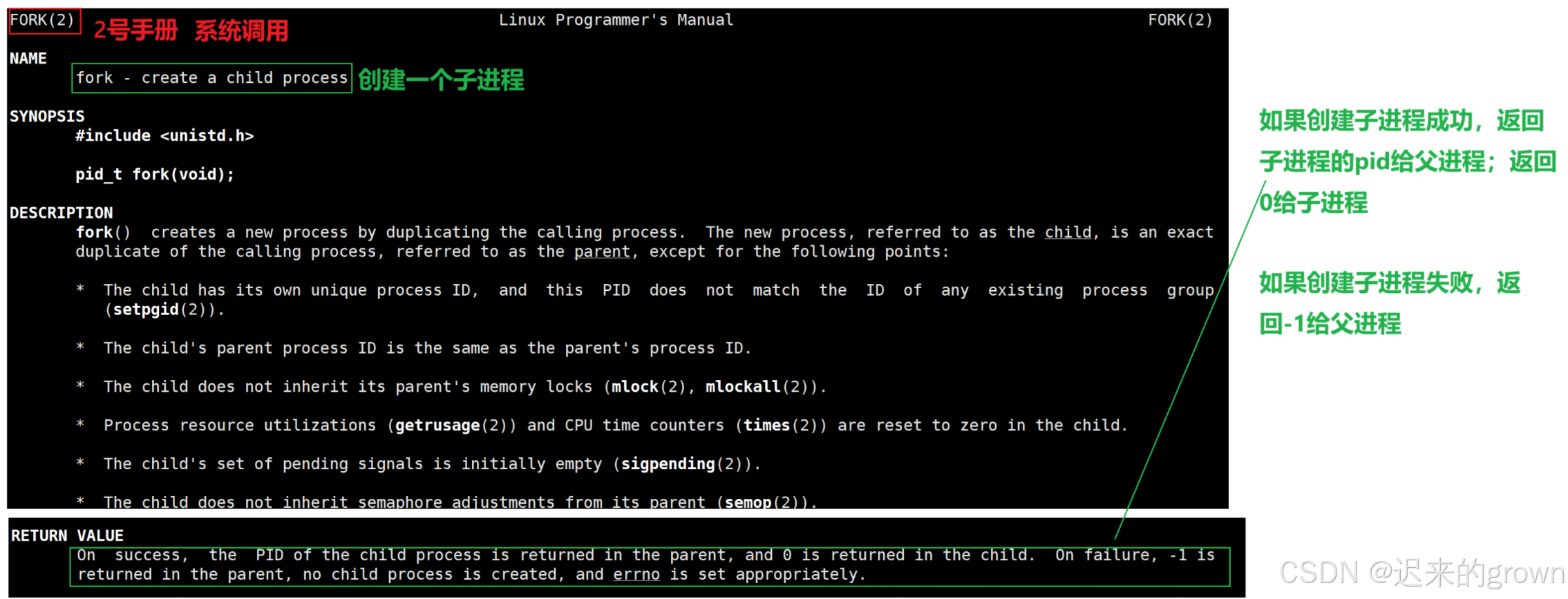
如果man手册查看fork可以发现,它是用来创建一个子进程的系统调用;
这里我们先不看返回值问题,我们先来看一下应该进程创建另外一个进程的现象
c
//process.c
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
int main()
{
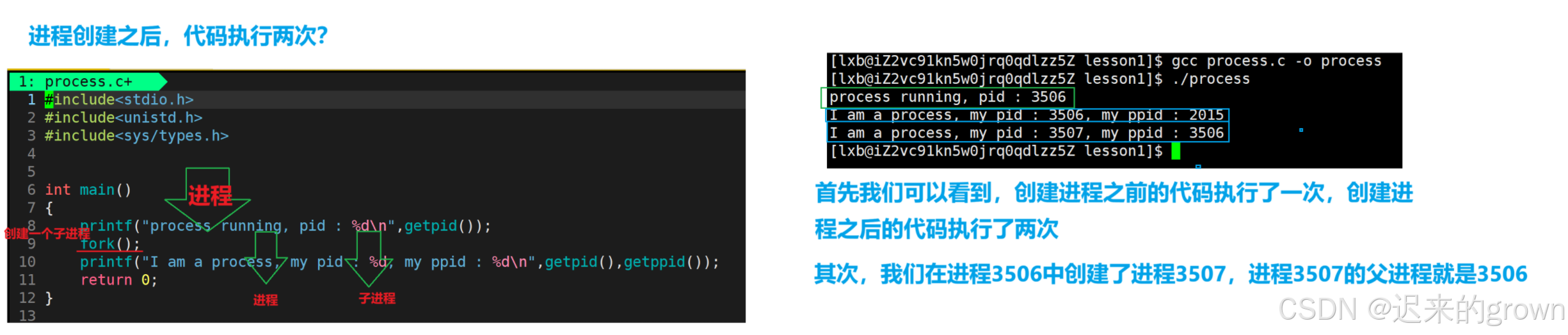
printf("prcess running, pid : %d\n",getpid());
fork();//创建进程
printf("I am a process, my pid : %d, my ppid : %d\n",getpid(),getppid());
return 0;
}
这里重点看这个系统调用的返回值:
如果创建子进程成功,就返回子进程的
pid给父进程,返回0给子进程;如果创建失败就返回-1给父进程,子进程未创建。
这里我们可以是不是就可以根据fork的返回值来判断,当前进程是父进程还是子进程;然后进行分流,让父进程和子进程执行不同的代码。
c
//process.c
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
int main()
{
pid_t id = fork();//也使用int类型接受返回值
if(id < 0){
//创建子进程失败
perror("fork");
return -1;
}
else if(id == 0){
//子进程
while(1){
printf("我是一个子进程, 我的pid: %d, 我的ppid: %d\n",getpid(),getppid());
sleep(1);
}
}
else{
//父进程
while(1){
printf("我是一个父进程, 我的pid: %d, 我的ppid: %d\n",getpid(),getppid());
}
}
return 0;
}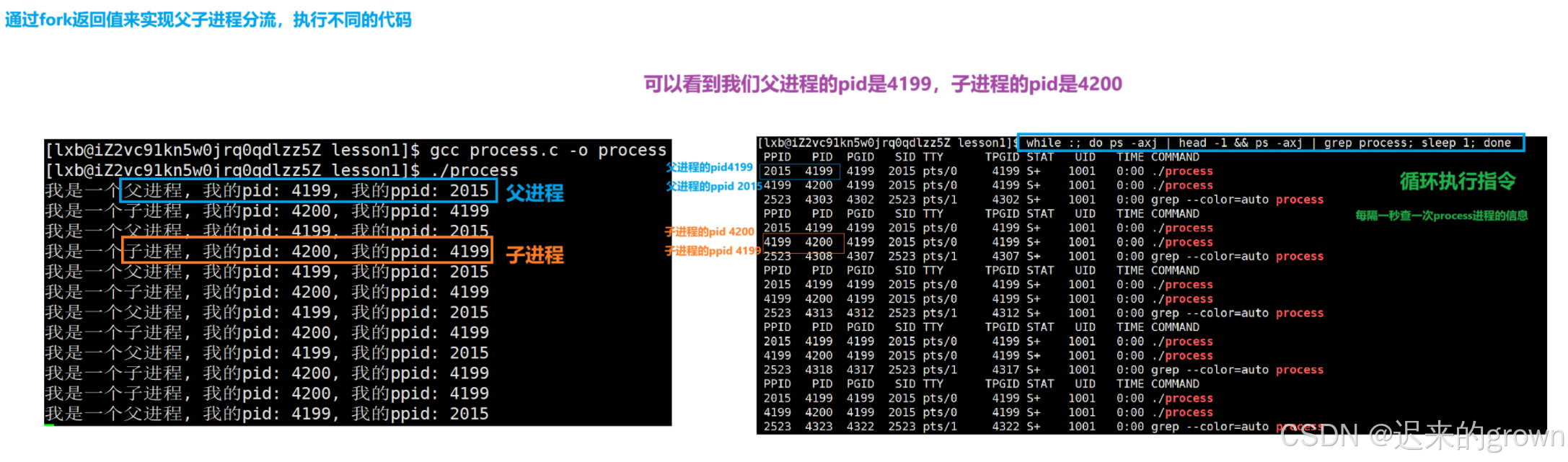
这里我们使用了循环执行指令
while :; do ps -axj | head -1 && ps -axj | grep process; sleep 1; done我们可以看到,我们父进程的pid是
4199,创建的子进程的ppid是4199也就是我们的父进程。
这里了解到了通过fork的返回值来进行父子进程分流,我们现在来思考几个问题:
fork为什么有两个返回值- 两个返回值是如何分别给父子进程返回的
首先,为什么要有两个返回值?
我们知道一个父进程它可以有多个子进程,而一个子进程只能有一个父进程;
那在父进程中,它怎么知道其子进程是哪一个进程呢?所以在父进程中要存储下来我们子进程的
pid;还用我们要实现父子进程的分流,那只能通过
fork的返回值来判断父子进程。
OK,这里有两个返回值理解,但是**fork是如何实现给父子进程返回不同的值的?**
在解释这个之前,我们先来看一个现象:
c
//process.c
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
int main()
{
int x = 0;
pid_t id = fork();//也使用int类型接受返回值
if(id < 0){
//创建子进程失败
perror("fork");
return -1;
}
else if(id == 0){
//子进程
while(1){
printf("我是一个子进程, 我的pid: %d, 我的ppid: %d; x = %d\n",getpid(),getppid(),x);
x+=10;
sleep(1);
}
}
else{
//父进程
while(1){
printf("我是一个父进程, 我的pid: %d, 我的ppid: %d; x = %d\n",getpid(),getppid(),x);
}
}
return 0;
}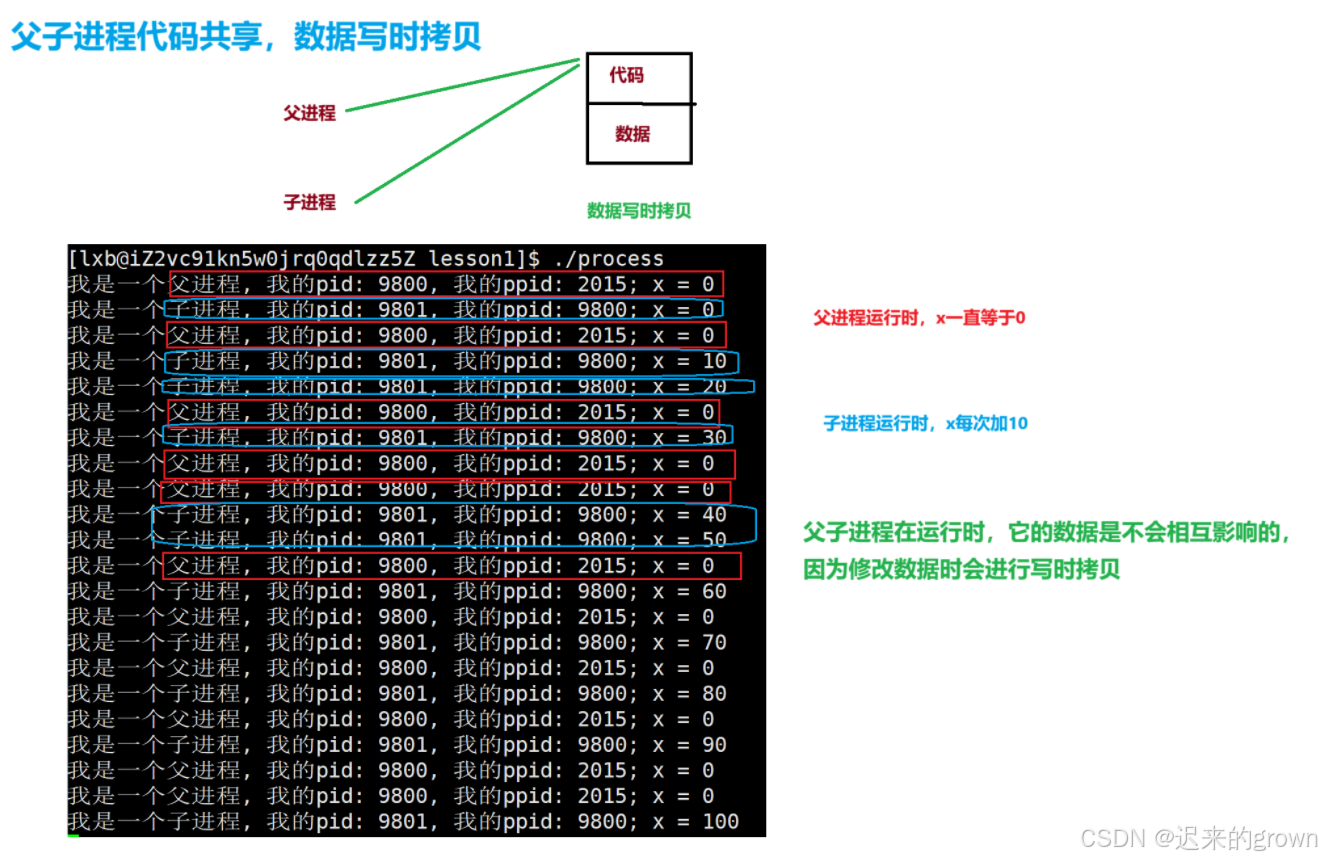
可以看到,我们子进程修改
x时,是不影响父进程的x的数据的;这是因为父子进程共享代码,数据在修改的时候是会进行写时拷贝的。
那我们现在来看,fork是如何实现给父子进程返回不同的返回值的。
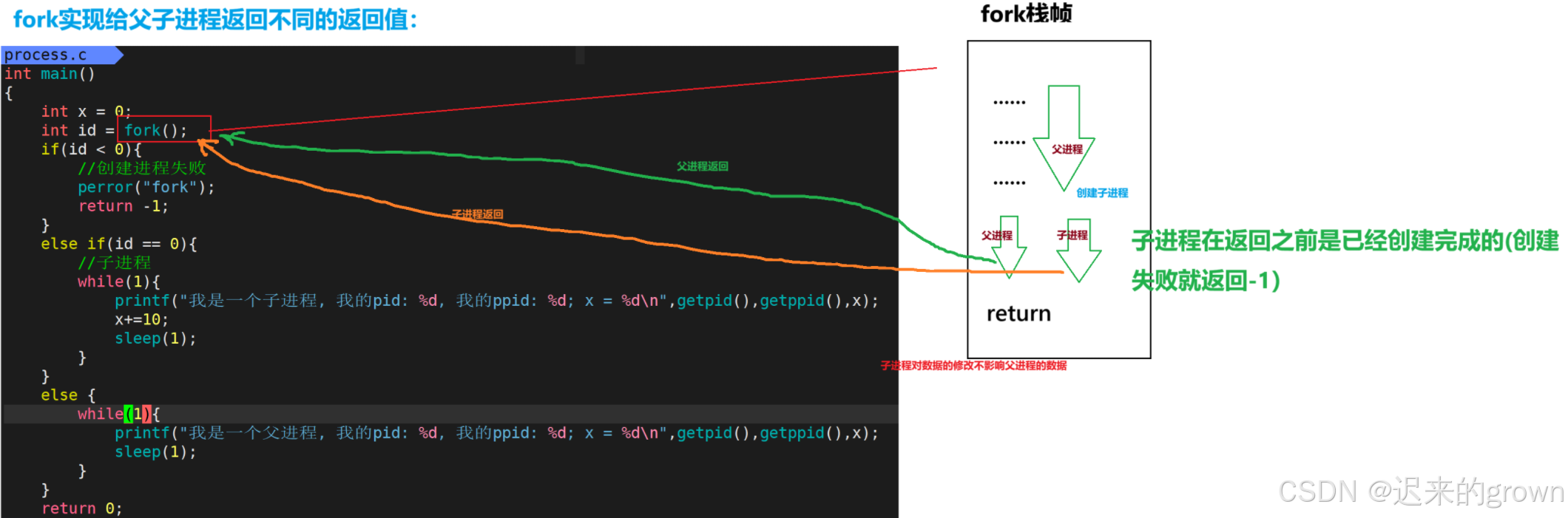
简单来说,就是在
fork函数返回之前,子进程已经创建完成了(如果创建失败就只有父进程执行,返回-1);那在
fork中已经有了父子进程的分流,而子进程修改数据不影响父进程的数据;所以子进程返回给子进程,父进程返回给父进程,这样实现
fork返回给父子进程不同的返回值。
程序进程的父进程是什么?
在上面留了一个疑问,我们程序执行是进程的父进程2015它是什么?(这里博主测试时是2015,其他时候可能不是)
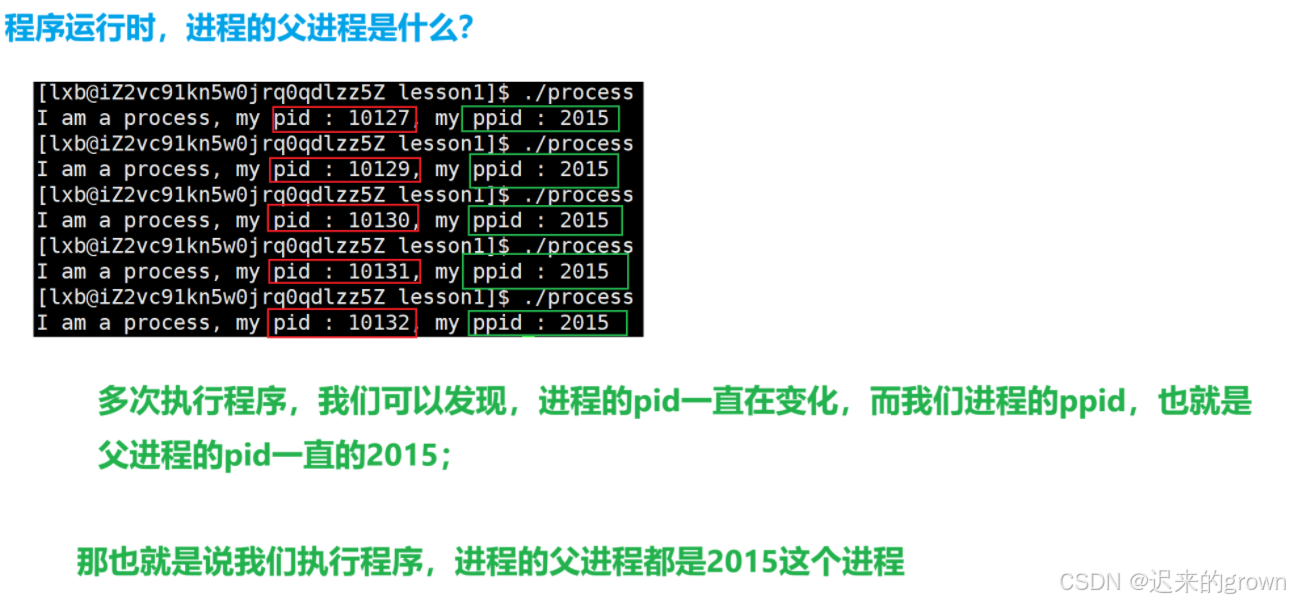
我们不妨来看一下,
2015这个进程是什么?

可以看到2015这个进程是-bash,那bash是什么呢?
在
Linux系统中,bash是最常用的命令行解释器(shell);还记得在学习
Linux系统中的权限时,提到过shell,它是用户与操作系统之间的接口,负责将我们的指令翻译成内核理解的指令。
bash是shell的一种实现,简单来说bash就是LInux中的命令行解释器;
我们再来想一想,我们在执行程序时,只是简单的让程序运行起来,那谁为我们创建这一个进程呢?显而易见的就是-bash了。
-bash是 登录Shell当用户通过系统级登录(
ssh、本地终端邓丽、su - username切换用户)时,系统会启动一个登录Shell;这里可以简单理解为系统为我们创建一个
-hash进程
三、查看系统文件/proc
我们在上面提到了系统文件/proc,这里面存放了所有进程信息;
那在我们自己的程序运行时,我们的进程会不会也在这个里面?
这里我们简单运行一个程序,查看一下pid:
c
//process.c
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
int main()
{
printf("I am a process, my pid: %d\n",getpid());
while(1){
sleep(1);
}
return 0;
}
当前进程pid是10596;
我们查看/proc系统文件:
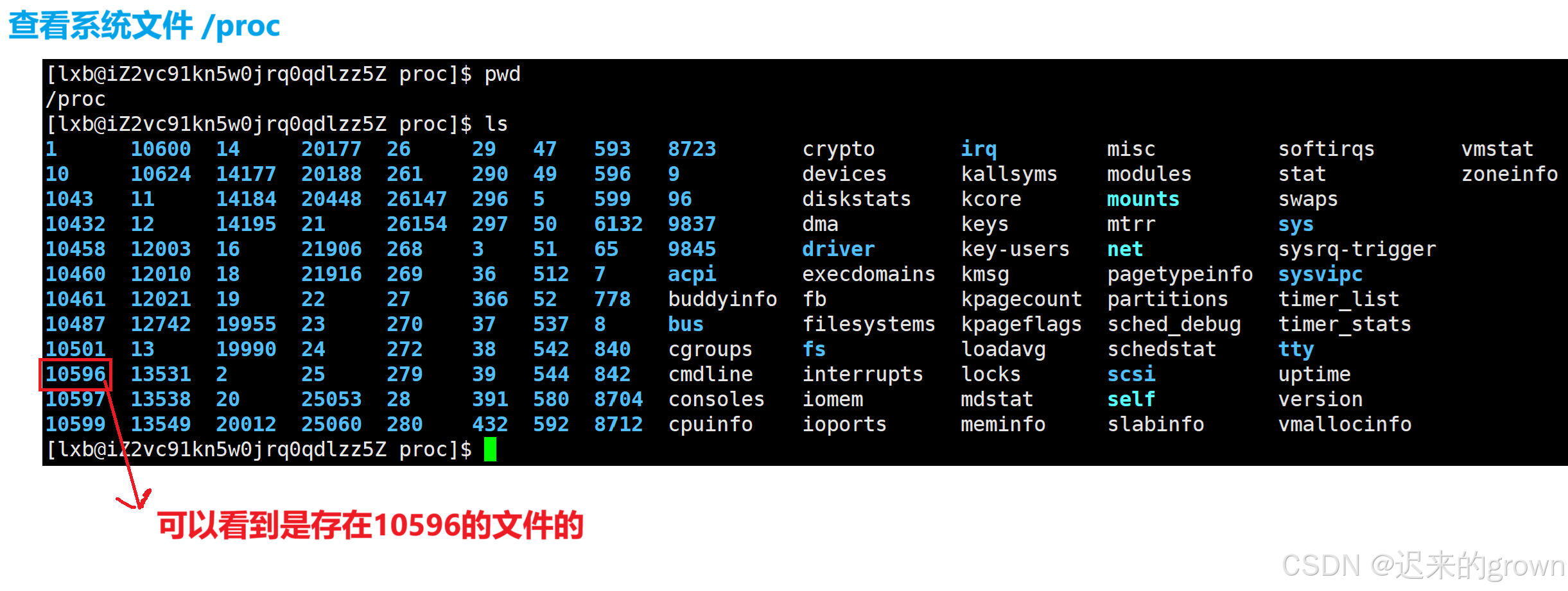
那这个文件中存储着哪些信息呢?

可以看到10596这个文件中存储着非常多的文件
这里我们就重点看一下cwd和exe这两个文件:

可以看到
cwd和exe中存储着这样的信息;那这些信息是什么呢?
cwd:存储当前可执行程序的绝对路径(指向进程的当前工作目录)exe:指向进程启动时使用的可执行文件的完整路径(进程由哪一个可执行程序启动)。
cwd
在之前,我们使用C语言中的文件操作函数fopen时,我们可以使用文件的绝对路径、也可以使用相对路径;
使用绝对路径我们可以理解,使用相对路径./test.txt时,程序是如何知道我们文件所在的位置呢?
所以
cwd存储的就是进程的当前工作目录,我们在进行文件操作时使用相对路径./test.txt时,会基于cwd进行解析路径。
这里就不过多演示了;
我们可以使用通过启动进程时指定工作目录、也可以通过chdir在程序在修改工作目录
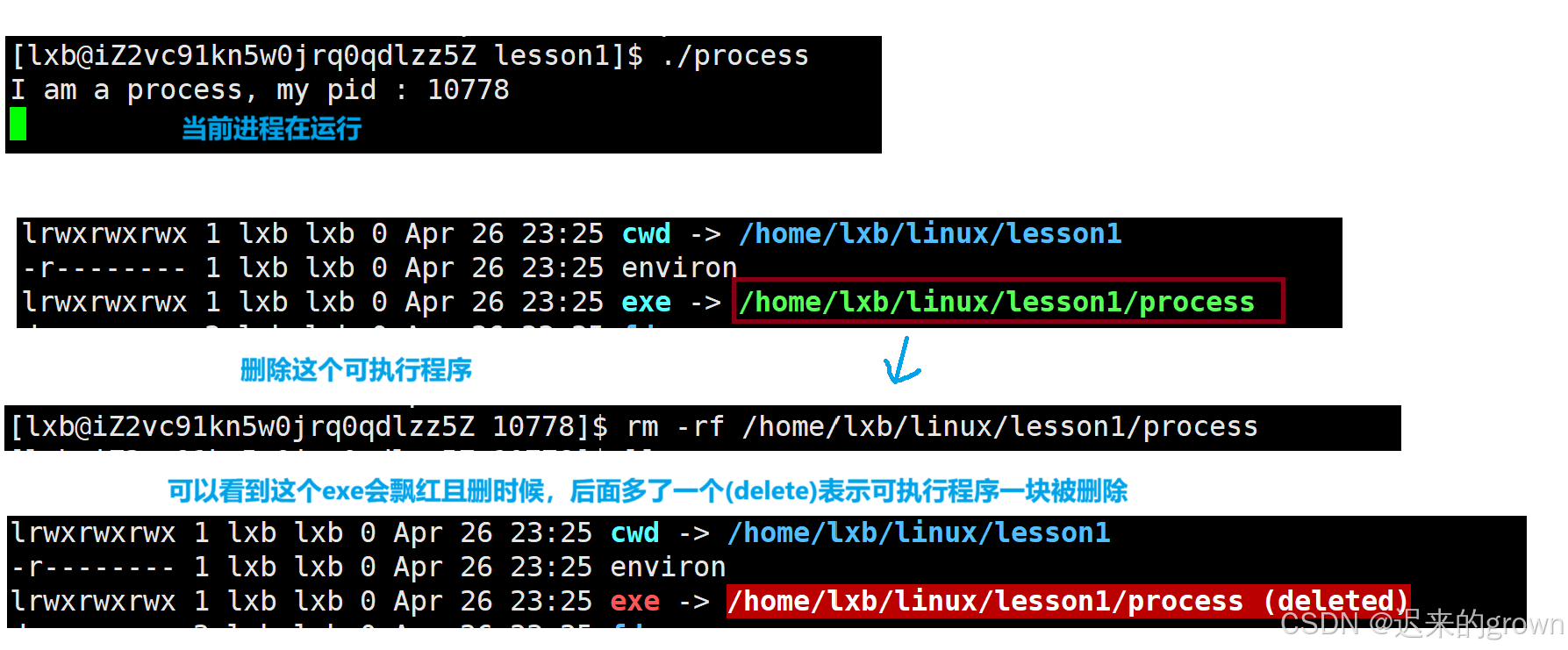
exe
exe中存储的是进程由哪一个可执行程序启动(进程启动时使用的可执行程序的完整路径)
那现在我们有一个疑问,如果进程在运行时,我们将exe指向的可执行程序删除了会怎么样?
到这里本篇文章大致内容就结束了
简单总结:
进程:内核的数据结构对象 + 自己的代码和数据
查看进程信息
top/ps指令进程的标识符
pid父子进程以及
fork创建进程补充:系统文件
/proc进程文件中的cwd和exe。