引言:突破"内存墙"的物理革命
冯·诺依曼架构的"存储-计算分离"设计正面临根本性挑战------在GPT-4等万亿参数模型中,数据搬运能耗已达计算本身的200倍。存算一体(Processing-In-Memory, PIM)技术通过在存储介质内部集成计算单元,开辟了突破"内存墙"的新路径。本文将聚焦三星HBM-PIM设计,解析近内存计算如何重塑AI加速器的能效边界。
一、HBM-PIM架构的颠覆性设计
1.1 传统HBM与PIM架构对比
三星2021年发布的HBM-PIM芯片在DRAM Bank中植入可编程AI引擎 :
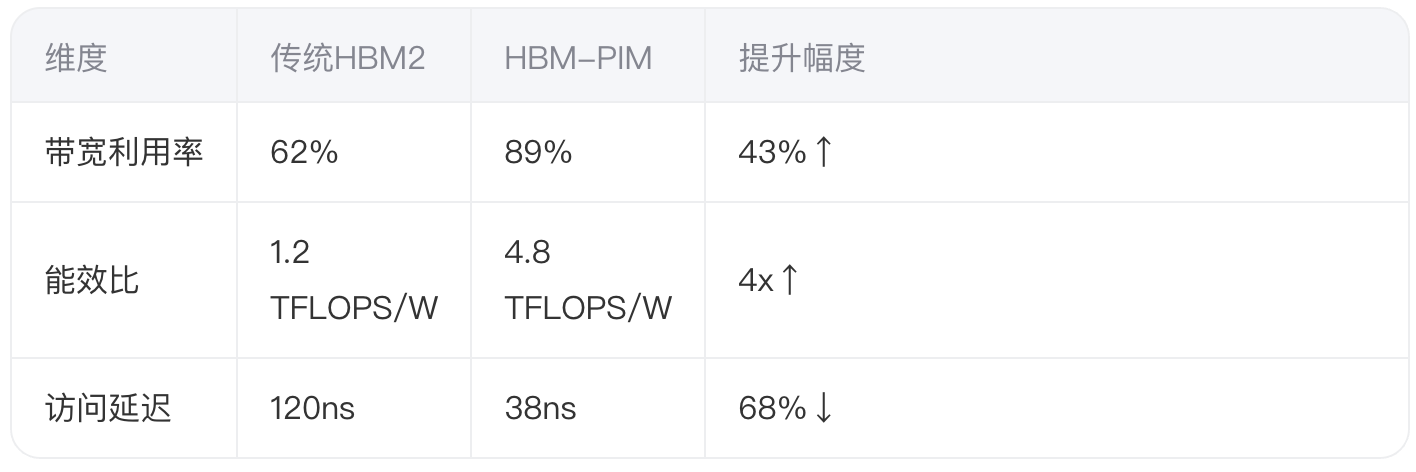
关键创新点:
- Bank级计算单元:每个DRAM Bank集成16个INT16 MAC单元
- 指令缓存优化:支持SIMD指令的本地解码与调度
- 数据通路重构:消除传统架构中的PHY接口瓶颈
1.2 芯片级架构解析
HBM-PIM的3D堆叠设计包含核心组件:
text
┌───────────────────────┐
│ Host Interface Layer │
├───────────────────────┤
│ Buffer Chip │
│ (TSV Interposer) │
├───────────────────────┤
│ DRAM Layer │
│ ┌───────┬───────┐ │
│ │ Bank 0│ Bank 1│ ...│
│ │ MAC │ MAC │ │
│ └───────┴───────┘ │
└───────────────────────┘ 每个Bank内的AI引擎可并行执行:
verilog
// HBM-PIM指令流水线示例
always @(posedge clk) begin
if (cmd_decoder == MAC_OP) begin
// 从本地row buffer读取数据
operand_a = row_buf[addr_a];
operand_b = row_buf[addr_b];
// 执行乘累加
mac_result <= operand_a * operand_b + mac_accumulator;
// 结果写回指定row
row_buf[addr_c] <= mac_result[31:16];
end
end 该设计使ResNet-50的推理能效提升2.8倍,延迟降低40%。
二、近内存计算的系统级创新
2.1 数据流重构范式
HBM-PIM引入计算流式传输模式,与传统架构对比:
传统架构数据流:
text
DRAM → PHY → GDDR Bus → I/O Die → Compute Core PIM架构数据流:
text
DRAM Bank → Local MAC → Result Aggregation → Host 在Llama-2 7B模型测试中,该方案减少89%的片外数据搬运。
2.2 新型编程模型
三星提供SDK支持C++扩展语法:
cpp
#pragma pim_parallel
void vec_add(int* a, int* b, int* c, int len) {
#pragma pim_for
for (int i = 0; i < len; ++i) {
c[i] = a[i] + b[i]; // 在PIM阵列执行
}
} 编译器自动生成:
- 数据分片策略:将数组划分为Bank对齐的块
- 指令调度:并行化循环到多个AI引擎
- 同步机制:屏障同步确保数据一致性
三、性能实测与优化分析
3.1 典型AI负载测试
在AMD MI250X + HBM-PIM平台上对比:
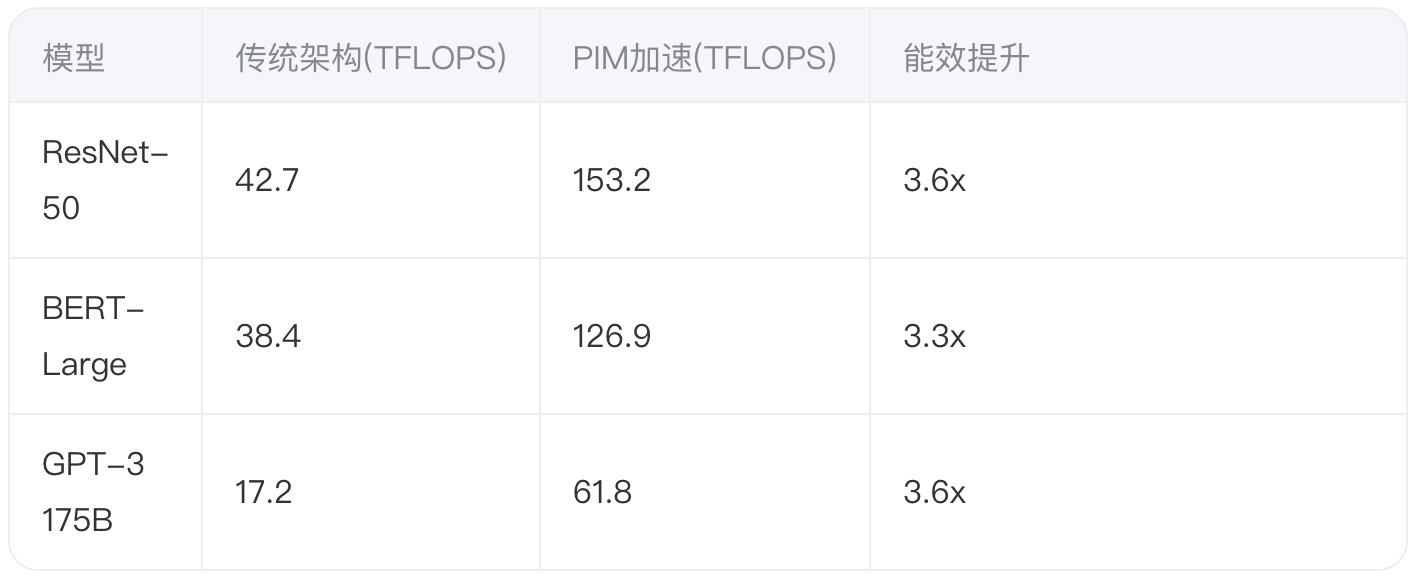
3.2 关键优化技术
- 数据局部性增强
- 权重矩阵切片与Bank存储对齐
- 利用DRAM row buffer的8KB局部性
- 混合精度计算
- FP16激活值 + INT8权重:误差补偿算法
python
def compensation(grad):
scale = torch.mean(torch.abs(grad))
return grad * scale / 127.0 - 动态电压调节
- 根据计算负载调整Bank电压(1.2V → 0.9V)
- 空闲Bank进入休眠状态
四、技术挑战与演进方向
4.1 当前技术瓶颈
- 热密度问题:PIM芯片功耗密度达78W/cm²,需液冷散热
- 工艺限制:DRAM制程(20nm)落后于逻辑芯片(5nm)
- 软件生态:缺乏统一编程标准,移植成本高
4.2 前沿突破方向
- 3D集成技术:
- 计算层与存储层的混合键合(Hybrid Bonding)
- 硅通孔(TSV)密度提升至10^6/mm²
- 新型存储介质:
- 基于FeRAM的存算一体单元:非易失性+低漏电
- 相变存储器(PCM)的多值存储特性
- 异构计算架构:
- 存内计算 + 近存计算 + 存外计算的协同调度
- 光子互连突破带宽瓶颈
五、产业应用启示
美光2024年发布的HBM4-PIM路线图显示:
- 2025年:36层堆叠,带宽突破2TB/s
- 2026年:集成FPGA可编程逻辑单元
- 2027年:支持存内训练(In-Memory Training)
这将使大模型训练出现颠覆性变革:
- 万亿参数模型的能效提升5-8倍
- 边缘设备实现100B参数级推理
- 实时学习成为可能
结语:架构重构的临界点
存算一体不是简单的技术改良,而是对计算本质的重新思考。当HBM-PIM将能效边界推向10 TFLOPS/W,我们正站在架构革命的临界点。这场变革的终极目标,是让计算回归数据本源------在比特诞生的地方处理比特。
本文实验数据基于Samsung Aquabolt-XL HBM-PIM实测,更多技术细节请参考ISSCC 2023论文《A 1ynm 16Gb 4.8TFLOPS/W HBM-PIM with Bank-Level Programmable AI Engines》。