文章目录
- 前言
- 一、正则化惩罚
-
- [1、权重正则化(Weight Regularization)](#1、权重正则化(Weight Regularization))
- [2、结构正则化(Structural Regularization)](#2、结构正则化(Structural Regularization))
- 3、其他正则化方法
- 二、梯度下降
-
- 1、基本原理
-
- (1)梯度下降的计算
- [(2) 算法步骤](#(2) 算法步骤)
- (3)梯度下降分为三类:
- 总结
前言
在深度学习技术迅猛发展的当下,神经网络凭借多层非线性变换的强大表征能力,在图像识别、自然语言处理、自动驾驶等领域实现了突破性应用。然而,随着模型复杂度的不断提升(如千亿参数的 Transformer、数百层的 ResNet),训练过程面临两大核心挑战:过拟合风险加剧与优化效率瓶颈。一方面,复杂模型对训练数据的记忆能力远超泛化能力,导致在未知数据上表现不佳;另一方面,非凸优化空间中梯度消失、局部最优等问题,使得传统优化算法难以高效收敛。正则化惩罚与梯度下降作为应对上述挑战的核心技术,二者的协同机制成为平衡模型容量与优化效率的关键。
一、正则化惩罚
在神经网络中,正则化惩罚是防止模型过拟合(Overfitting)的核心技术之一。过拟合表现为模型在训练数据上表现优异,但在未知数据(测试集)上泛化能力差,本质原因是模型复杂度太高,过度学习了训练数据中的噪声和细节。正则化通过向损失函数中添加 "惩罚项" 或引入约束条件,迫使模型参数更简单、更鲁棒,从而提升泛化能力。
1、权重正则化(Weight Regularization)
通过对网络权重矩阵施加 "惩罚",约束其取值范围,避免权重过大导致模型过度复杂。
(1) L2 正则化(权重衰减,Weight Decay)
原理:在损失函数中添加权重参数的平方和作为惩罚项,公式为:
其中,入是正则化超参数,N 是训练样本数, ∑ w 2 ∑w2 ∑w2是所有权重的平方和。
作用:迫使权重趋近于 0(但不会为 0),使模型对输入变化的敏感度降低,避免 "依赖" 个别特征,提升稳定性。直观上,权重越小,模型的决策边界越平滑。
(2)L1 正则化原理:惩罚项为权重的绝对值之和,公式为:
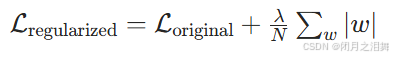
作用:产生稀疏解(大量权重为 0),相当于自动进行特征选择 ------ 剔除无关特征(对应权重为 0),保留关键特征。与 L2 相比,L1 更易导致模型稀疏化。
2、结构正则化(Structural Regularization)
通过修改网络结构或训练过程,增加模型的泛化能力。
(1)Dropout原理:在训练过程中,以一定概率(如 0.5)随机 "关闭" 神经元(使其输出为 0),测试时恢复所有神经元并将输出乘以保留概率(或训练时不关闭但缩放权重)。
作用:减少神经元之间的协同依赖("共适应"),迫使模型学习更鲁棒的特征。Dropout 等价于训练多个子网络的集成,每个子网络共享参数,测试时平均预测结果,从而降低过拟合。
(2)数据增强(Data Augmentation)
原理:对训练数据进行变换(如图像旋转、翻转、裁剪、加噪声等),生成新的训练样本,扩大数据集多样性。
作用:迫使模型学习不变性特征(如图像分类中对旋转、缩放的鲁棒性),避免记忆特定样本的噪声细节。
(3)早停(Early Stopping)
原理:在训练过程中监控验证集性能,当验证损失不再下降时提前终止训练,避免过度拟合训练数据。
作用:通过限制训练迭代次数,间接控制模型复杂度,本质是在 "欠拟合" 和 "过拟合" 之间找到平衡点。
3、其他正则化方法
最大范数约束(Max-Norm Regularization)限制每个神经元权重向量的范数不超过某个阈值(如 L2 范数≤K),通过投影操作保证权重不会过大,增强模型稳定性。
标签平滑(Label Smoothing)将硬标签(如独热编码的 1,0,0)转换为软标签(如 0.9,0.05,0.05),防止模型对某一类过于自信,提升泛化能力。
集成方法(Ensemble)通过训练多个不同模型(如不同初始化、结构的网络)并平均预测结果,利用 "集体智慧" 降低方差,本质是一种隐式正则化。
二、梯度下降
1、基本原理
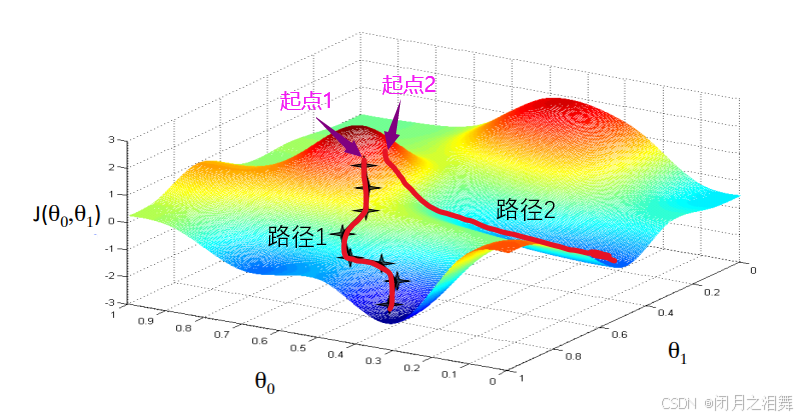
梯度下降(Gradient Descent, GD)是一种迭代优化算法,用于最小化(或最大化)目标函数,是训练机器学习模型(如线性回归、神经网络)的核心方法。其核心思想是:沿着目标函数梯度的反方向(最小化时)更新参数,使目标函数值逐步下降。
(1)梯度下降的计算
假设目标函数为L(θ),其中θ=θ1,θ2 ,...,θn 是待优化的参数向量。
梯度的计算公式:
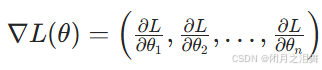
表示函数在当前点上升最快的方向。
参数更新方向:为了最小化 L(θ),参数更新方向应为梯度的反方向(负梯度)。
梯度更新公式:
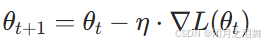
其中 η是学习率(步长),t 是迭代次数。
(2) 算法步骤
初始化参数:随机或手动设置初始参数 θ0。
计算梯度:对当前参数计算目标函数的梯度 。
更新参数:沿负梯度方向更新参数,步长由学习率决定。
重复迭代:直到目标函数收敛(梯度趋近于 0 或损失不再显著下降)。
梯度下降的两个调整角度:
1、梯度方向调整,每到一个新的位置,梯度更新的方向
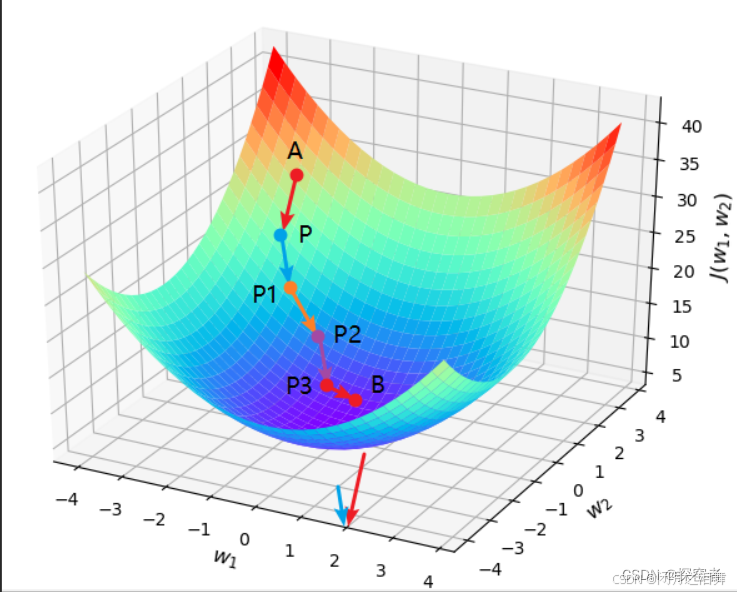
2、学习率调整,每一步更新的长度
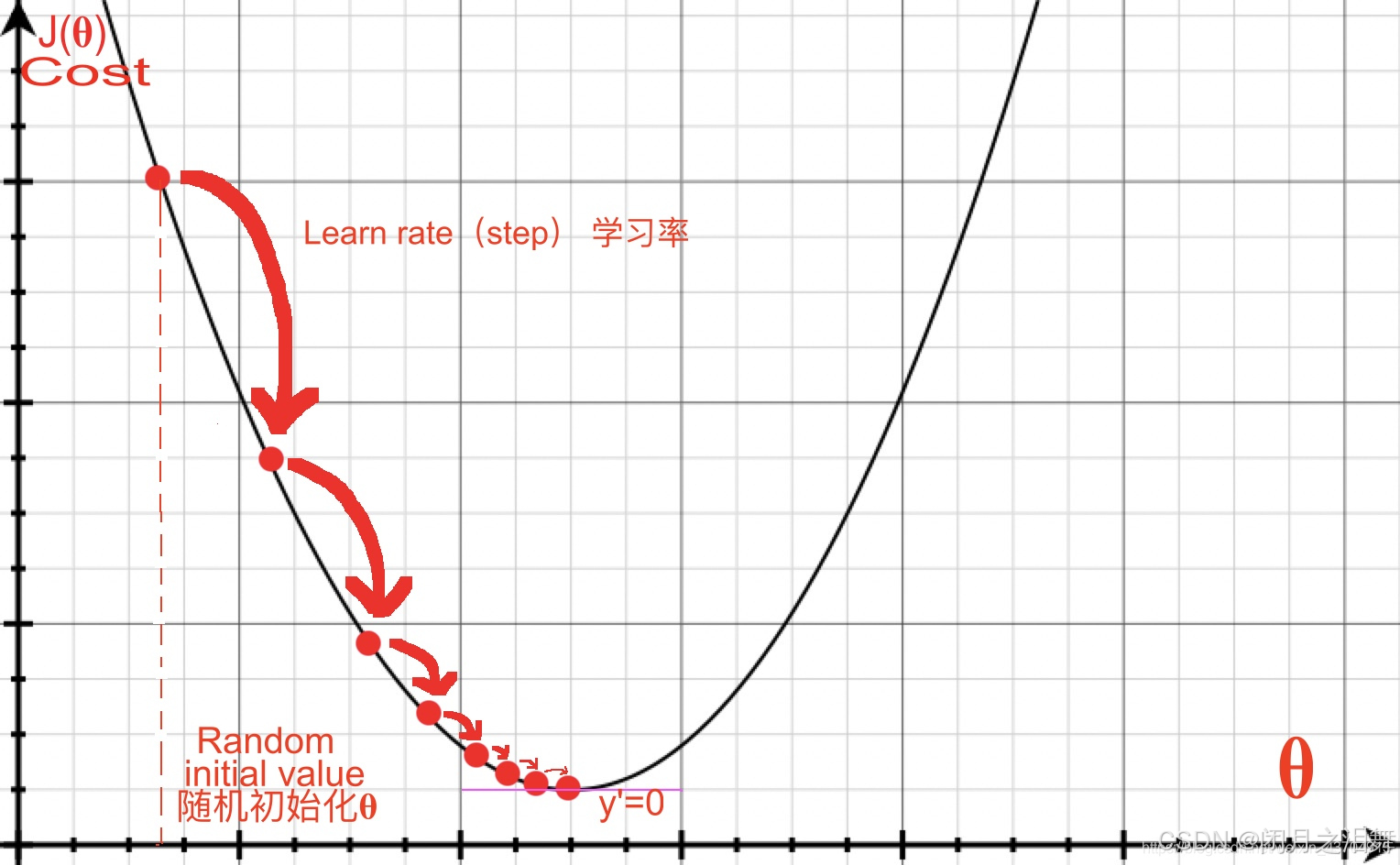
梯度方向决定更新方向:沿负梯度方向(下降最快方向)更新参数。
学习率控制步长:过小导致收敛慢,过大导致震荡或发散。
迭代逼近最优解:通过多次迭代,参数逐渐接近使目标函数最小化的最优值。
(3)梯度下降分为三类:
批量梯度下降(Batch GD):使用全部训练数据计算梯度,收敛稳定但速度慢(尤其数据量大时)。
随机梯度下降(SGD):每次仅用一个样本计算梯度,速度快但噪声大,可能震荡。
小批量梯度下降(Mini-Batch GD):折中方案,使用小批量数据(如 32/64/128 样本)计算梯度,兼顾速度和稳定性,是最常用的变种。
想了解梯度下降更详细的更新方法可以查看链接: http://zh.gluon.ai/chapter_optimization/gd-sgd.html。
总结
网络优化的核心目标是通过调整模型参数,使神经网络在训练数据上高效学习到有效的特征表示,从而提升模型在新数据上的预测性能与泛化能力。