Gradio全解20------Streaming:流式传输的多媒体应用(3)------实时语音识别技术
- 本篇摘要
- [20. Streaming:流式传输的多媒体应用](#20. Streaming:流式传输的多媒体应用)
-
- [20.3 实时语音识别技术](#20.3 实时语音识别技术)
-
- [20.3.1 环境准备和开发步骤](#20.3.1 环境准备和开发步骤)
-
- [1. 环境准备](#1. 环境准备)
- [2. ASR应用开发步骤(基于Transformers)](#2. ASR应用开发步骤(基于Transformers))
- [20.3.2 配置ASR模型](#20.3.2 配置ASR模型)
- [20.3.3 构建全上下文ASR演示系统](#20.3.3 构建全上下文ASR演示系统)
- [20.3.4 构建流式ASR演示系统](#20.3.4 构建流式ASR演示系统)
- 参考文献:
本章目录如下:
- 《Gradio全解20------Streaming:流式传输的多媒体应用(1)------流式传输音频:魔力8号球》;
- 《Gradio全解20------Streaming:流式传输的多媒体应用(2)------构建对话式聊天机器人》;
- 《Gradio全解20------Streaming:流式传输的多媒体应用(3)------实时语音识别技术》;
- 《Gradio全解20------Streaming:流式传输的多媒体应用(4)------基于Groq的带自动语音检测功能的多模态Gradio应用》;
- 《Gradio全解20------Streaming:流式传输的多媒体应用(5)------基于WebRTC的摄像头实时目标检测》;
- 《Gradio全解20------Streaming:流式传输的多媒体应用(6)------构建视频流目标检测系统》。
本篇摘要
本章讲述流式传输的应用,包括音频、图像和视频格式的流式传输。
20. Streaming:流式传输的多媒体应用
本章讲述流式传输的应用,包括音频、图像和视频格式的流式传输。音频应用包括流式传输音频、构建音频对话式聊天机器人、实时语音识别技术和自动语音检测功能;图像应用包括基于WebRTC的摄像头实时目标检测;视频应用包括构建视频流目标检测系统。
20.3 实时语音识别技术
自动语音识别技术(Automatic speech recognition:ASR)作为机器学习中将语音信号转换为文本的重要领域,正处于快速发展阶段。当前ASR算法已普遍应用于智能手机设备,并逐步渗透到专业工作流程中,如医护人员的数字助理系统。由于ASR算法直接面向终端用户,所以必须确保其能够实时准确处理各种语音特征(包括不同口音、音高及背景噪声环境)。
通过Gradio平台,开发者可快速构建ASR算法模型的演示系统,便于测试团队验证或通过麦克风等设备进行自主实时测试。本教程将通过两部分演示如何将预训练语音转文本模型部署至Gradio交互界面:第一部分采用全上下文模式,即用户完成整段录音后才执行预测;第二部分将演示改造为流式处理模式,实现语音实时转换功能。
20.3.1 环境准备和开发步骤
开始之前,先准备环境,比如安装gradio、Transformers及ffmpeg等python包,再按照应用开发步骤进行实战。
1. 环境准备
请确保已安装gradio的Python包,同时本教程需要预训练语音识别模型支持,我们还需要以下两个ASR库构建演示系统:Transformers(安装命令:pip install torch transformers torchaudio),我们使用Transformers中Whisper模型实现语音识别;FFmpeg处理麦克风输入文件,因为Transformers会自动安装ffmpeg,所以建议至少安装其中一个库以便跟进教程。FFmpeg是领先的多媒体框架,能够解码、编码、转码、复用、解复用、流式传输、过滤及播放几乎所有人类与机器创建的媒体内容。该框架支持从最冷门的古老格式到最前沿的技术标准------无论这些格式是由标准委员会、开源社区还是商业公司设计,详细信息请参阅:FFmpeg。
2. ASR应用开发步骤(基于Transformers)
实时语音识别(ASR)应用开发步骤全部基于Transformers,具体步骤如下:
- 配置ASR模型环境;
- 构建全上下文ASR演示系统;
- 构建流式ASR演示系统。
20.3.2 配置ASR模型
首先,需要准备一个ASR模型------可以是自行训练的模型,或是下载预训练模型。本教程将使用Whisper的预训练ASR模型作为示例,以下是加载Hugging Face Transformers中Whisper模型的代码:
python
from transformers import pipeline
pl = pipeline("automatic-speech-recognition", model="openai/whisper-base.en")配置完成!
20.3.3 构建全上下文ASR演示系统
然后,创建全上下文ASR演示,即用户需完整录制音频后,系统才会调用ASR模型进行推理。利用Gradio实现这一功能非常简单------只需基于上述pipeline对象创建处理函数即可。
具体实现将采用Gradio内置的Audio组件:输入组件将接收用户麦克风输入并返回录音文件路径,输出组件将使用标准Textbox组件显示识别结果。代码如下:
python
import gradio as gr
from transformers import pipeline
import numpy as np
transcriber = pipeline("automatic-speech-recognition", model="openai/whisper-base.en")
def transcribe(audio):
sr, y = audio
# Convert to mono if stereo
if y.ndim > 1:
y = y.mean(axis=1)
y = y.astype(np.float32)
y /= np.max(np.abs(y))
return transcriber({"sampling_rate": sr, "raw": y})["text"]
demo = gr.Interface(
transcribe,
gr.Audio(sources="microphone"),
"text",
)
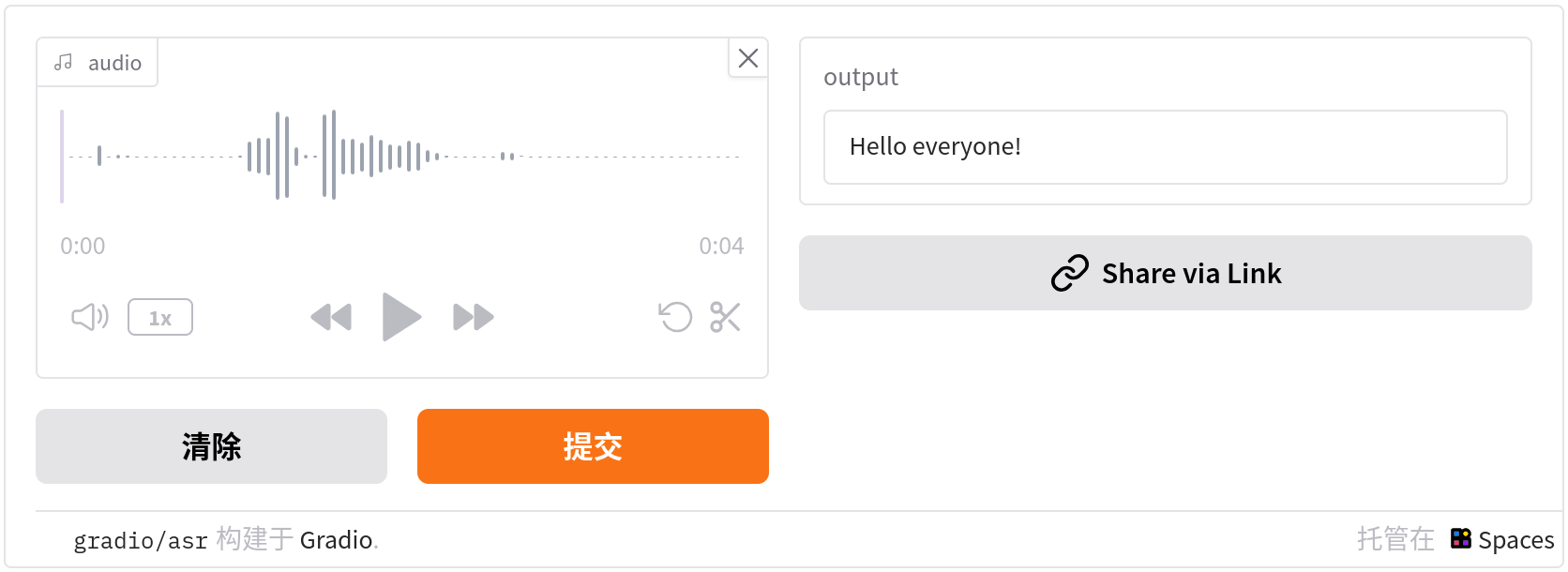
demo.launch()transcribe函数接受单一参数audio,这是一个用户录制的音频numpy数组。管道对象期望音频为float32格式,因此我们首先将其转换为float32,然后使用transcriber提取转录文本。
此程序在Hugging Face的地址为:gradio/asr,演示截图如下:
20.3.4 构建流式ASR演示系统
要实现流式处理,需进行以下配置调整:
- 在Audio组件中设置streaming=True以支持流式传输;
- 在Interface中启用live=True参数以支持实时传输;
- 添加状态存储机制state以保存用户音频流。
具体实现代码如下:
python
import gradio as gr
from transformers import pipeline
import numpy as np
transcriber = pipeline("automatic-speech-recognition", model="openai/whisper-base.en")
def transcribe(stream, new_chunk):
sr, y = new_chunk
# Convert to mono if stereo
if y.ndim > 1:
y = y.mean(axis=1)
y = y.astype(np.float32)
y /= np.max(np.abs(y))
if stream is not None:
stream = np.concatenate([stream, y])
else:
stream = y
return stream, transcriber({"sampling_rate": sr, "raw": stream})["text"]
demo = gr.Interface(
transcribe,
["state", gr.Audio(sources=["microphone"], streaming=True)],
["state", "text"],
live=True,
)
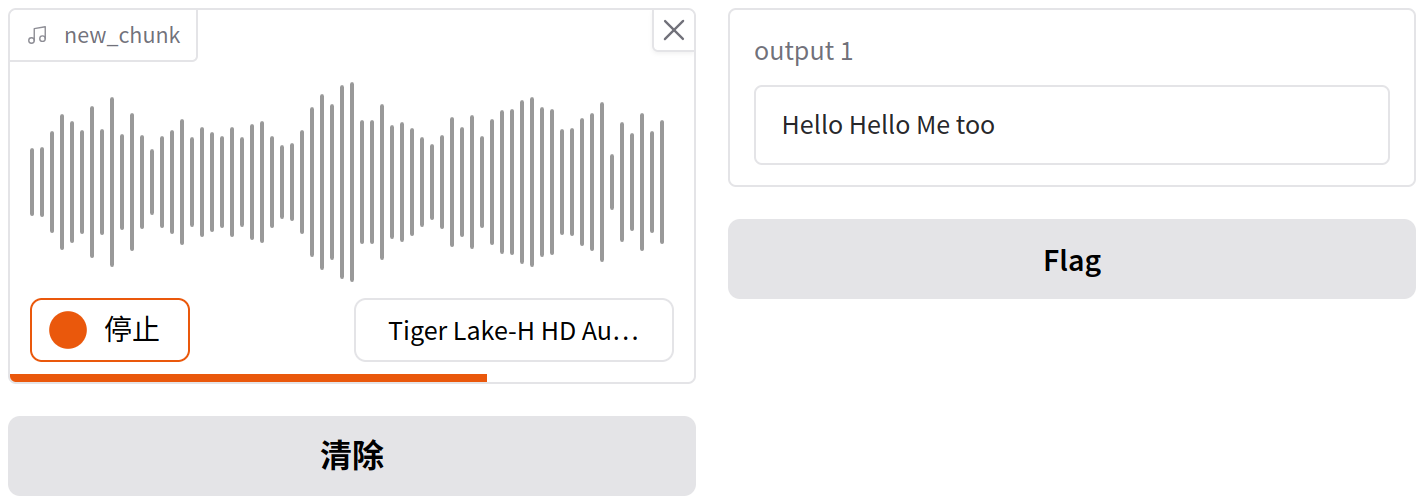
demo.launch()请注意,我们现在有一个状态变量,因为我们需要跟踪所有音频历史。随着接口运行,每次有新的小段音频时,transcribe函数将会被调用,在状态中跟踪迄今为止所有的音频记录并将新音频片段作为new_chunk;new_chunk经过处理后,将返回新的完整音频并存储回当前状态,同时也返回转录文本。整个过程中,我们只需要简单地将音频拼接在一起,并对整个音频调用转录器对象;也可以优化为其它更有效率的处理方式,比如每次接收到新音频片段时,仅重新处理最后5秒的音频。
现在,ASR模型将在用户说话时进行推理!注意在进度条开始后录音,运行截图如下: